
Rust 教程
# Rust 简介
Rust是由Mozilla主导开发的高性能编译型编程语言, 遵循安全, 并发, 实用的设计原则, 首次发布于2010年, 其支持多种编程范式, 包括函数式, 并发式, 过程式和面向对象风格.
Rust速度惊人且内存利用率极高. 由于没有运行时和垃圾回收, 它能够胜任对性能要求特别高的服务, 可以在嵌入式设备上运行, 还能轻松和其他语言集成.
# Rust 语言的特点
- 内存安全: Rust的所有权系统在编译时防止空悬指针, 数据竞争等内存错误, 无需垃圾收集器.
- 并发编程: Rust提供了现代的语言特性来支持并发编程, 如线程和消息传递, 使得编写并发程序更加安全和容易.
- 性能: Rust编译为机器码, 没有运行时和垃圾收集器, 能够提供接近C和C++的性能.
- 类型系统: Rust的类型系统和模式匹配提供了强大的抽象能力, 有助于编写更安全, 更可预测的代码.
- 错误处理: Rust的错误处理模型鼓励显式处理所有可能的错误情况.
- 宏系统: Rust提供了一个强大的宏系统, 允许开发者在编译时编写和重用代码.
- 包管理: Rust的包管理器Cargo简化了依赖管理和构建过程.
- 跨平台: Rust支持多种操作系统和平台, 包括Windows, macOS, Linux, BSDs等.
- 社区支持: Rust有一个活跃的社区, 提供了大量的库和工具.
- 工具链: Rust拥有丰富的工具链, 包括编译器, 包管理器, 文档生成器等.
- 无段错误: Rust的所有权和生命周期规则保证了引用的有效性, 从而避免了段错误.
- 迭代器和闭包: Rust提供了强大的迭代器和闭包支持, 简化了集合的处理.
# Rust 的应用
Rust语言可以用于开发:
- 系统编程: 操作系统, 设备驱动程序, 嵌入式系统等.
- 网络编程: 网络服务器, Web服务, 分布式系统等.
- 游戏开发: 游戏引擎, 游戏工具, 游戏客户端和服务器.
- WebAssembly: 在Web浏览器中运行的高性能Web应用.
- 工具开发: 命令行工具, 自动化脚本, 系统管理工具.
- 区块链技术: 智能合约, 加密货币, 去中心化应用(DApps).
- 科学计算: 数值分析, 数据科学, 机器学习.
- 音视频处理: 媒体服务器, 流处理, 编解码器.
- 云计算: 云服务后端, 容器技术, 微服务架构.
- 嵌入式设备: IoT设备, 智能家居设备, 可穿戴设备.
# 第一个Rust程序
fn main() {
println!("Hello World!");
}
2
3
使用rustc命令编译runoob.rs文件:
rustc runoob.rs # 编译 runoob.rs 文件
编译后会生成runoob可执行文件:
./runoob # 执行 runoob
Hello World!
2
# 参考链接
# Rust 环境搭建
Rust支持很多的集成开发环境(IDE)或开发专用的文本编辑器. 官方网站公布支持的工具如下(https://www.rust-lang.org/zh-CN/tools):

本教程将使用Visual Studio Code作为开发环境(Eclipse有专用于Rust开发的版本, 对于初学者是不错的选择).
注意
IntelliJ IDEA 安装插件后难以调试, 所以推荐习惯使用IDEA的开发者使用CLion, 但CLion不是免费的.
# 搭建Visual Studio Code开发环境
首先, 需要安装最新版的Rust编译工具和Visual Studio Code. Rust编译工具: https://www.rust-lang.org/zh-CN/tools/install Visual Studio Code: https://code.visualstudio.com/Download Rust的编译工具依赖C语言的编译工具, 这意味着你的电脑上至少已经存在一个C语言的编译环境. 如果使用的是Linux系统, 往往已经具备了GCC或clang. 如果使用的是macOS, 需要安装Xcode, 如果用的是Windows操作系统, 需要安装Visual Studio 2013或以上的环境(需要C/C++支持)以使用MSVC或安装MinGW+GCC编译环境(Cygwin还没有测试).
# 安装Rust编译工具
Rust编译工具可以去官方网站下载: https://www.rust-lang.org/zh-CN/tools/install. macOS, Linux或其他类Unix系统要下载Rustup并安装Rust, 请在终端执行以下命令:
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh
Windows要下载rustup-init.exe可执行文件, 下载好的Rustup在Windows上是一个可执行程序rustup-init.exe. 执行rustup-init文件:
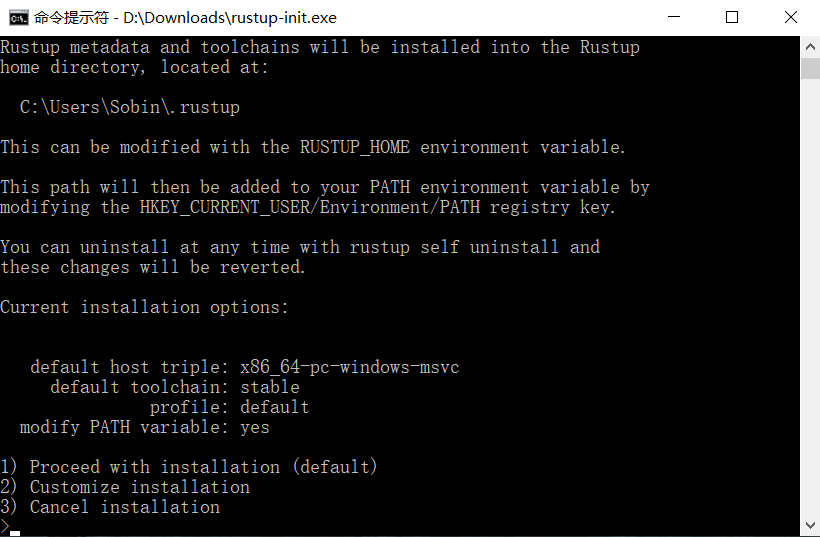
上图显示的是一个命令行安装向导. 如果你已经安装MSVC(推荐), 那么安装过程会非常简单, 输入1并回车, 直接进入第二步. 如果你安装的是MinGW, 那么需要输入2(自定义安装), 然后系统会询问你Default host triple?, 请将上图中default host triple的"msvc"改为"gnu"再输入安装程序:
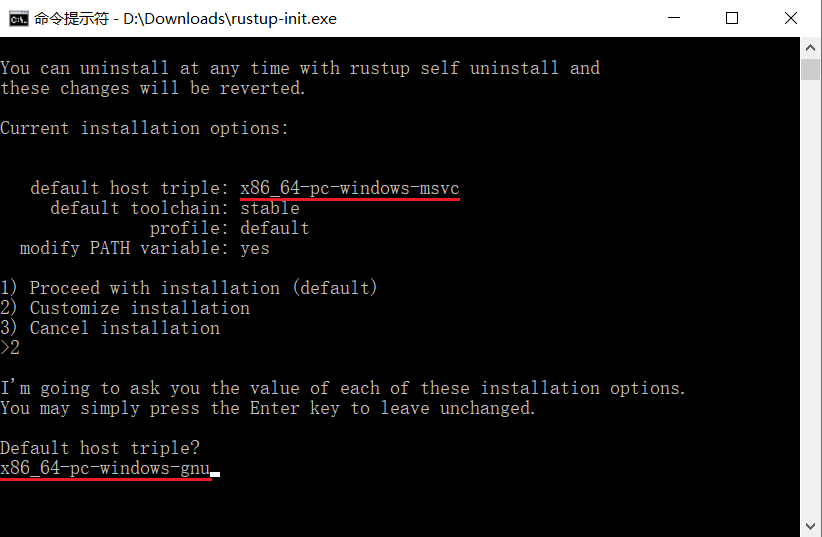
其他属性都默认. 设置完所有选项, 会回到安装向导界面(第一张图), 这时我们输入1回车即可.
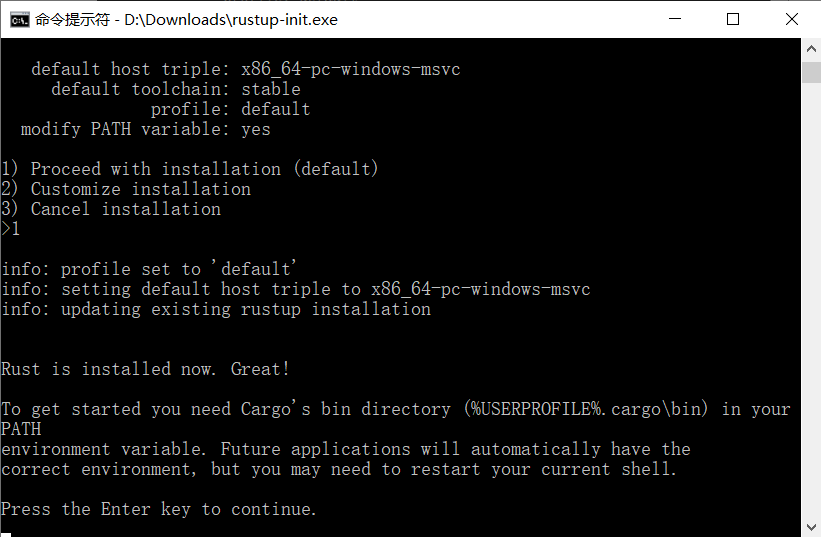
进行到这一步就完成了Rust的安装, 可以通过以下命令测试:
rustc -V # 注意大写的 V
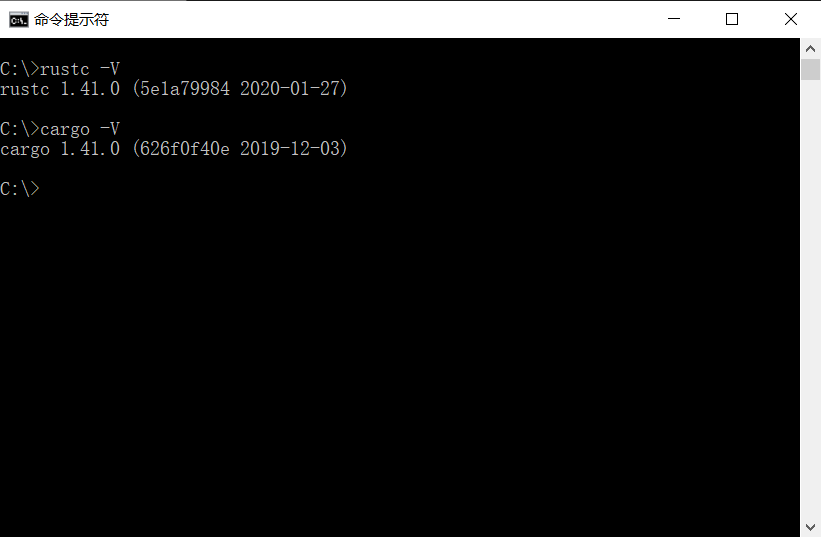
如果以上两个命令能够输出你安装的版本号, 就是安装成功了. 更多下载方式可以查阅: https://forge.rust-lang.org/infra/other-installation-methods.html.
# 搭建Visual Studio Code开发环境
下载完Visual Studio Code安装包之后启动安装向导安装, 安装完Visual Studio Code后运行.
安装简体中文扩展:
用同样的方法再安装rust-analyzer和Native Debug两个插件:
重新启动VSCode, Rust的开发环境就搭建好了. 新建一个文件夹, 如runoob-greeting. 在VSCode中打开新建的文件夹:
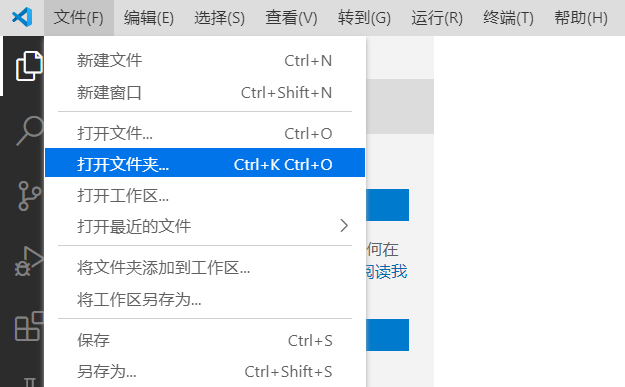
打开文件夹之后选择菜单栏中的"终端"-"新建终端", 会打开一个新的终端:
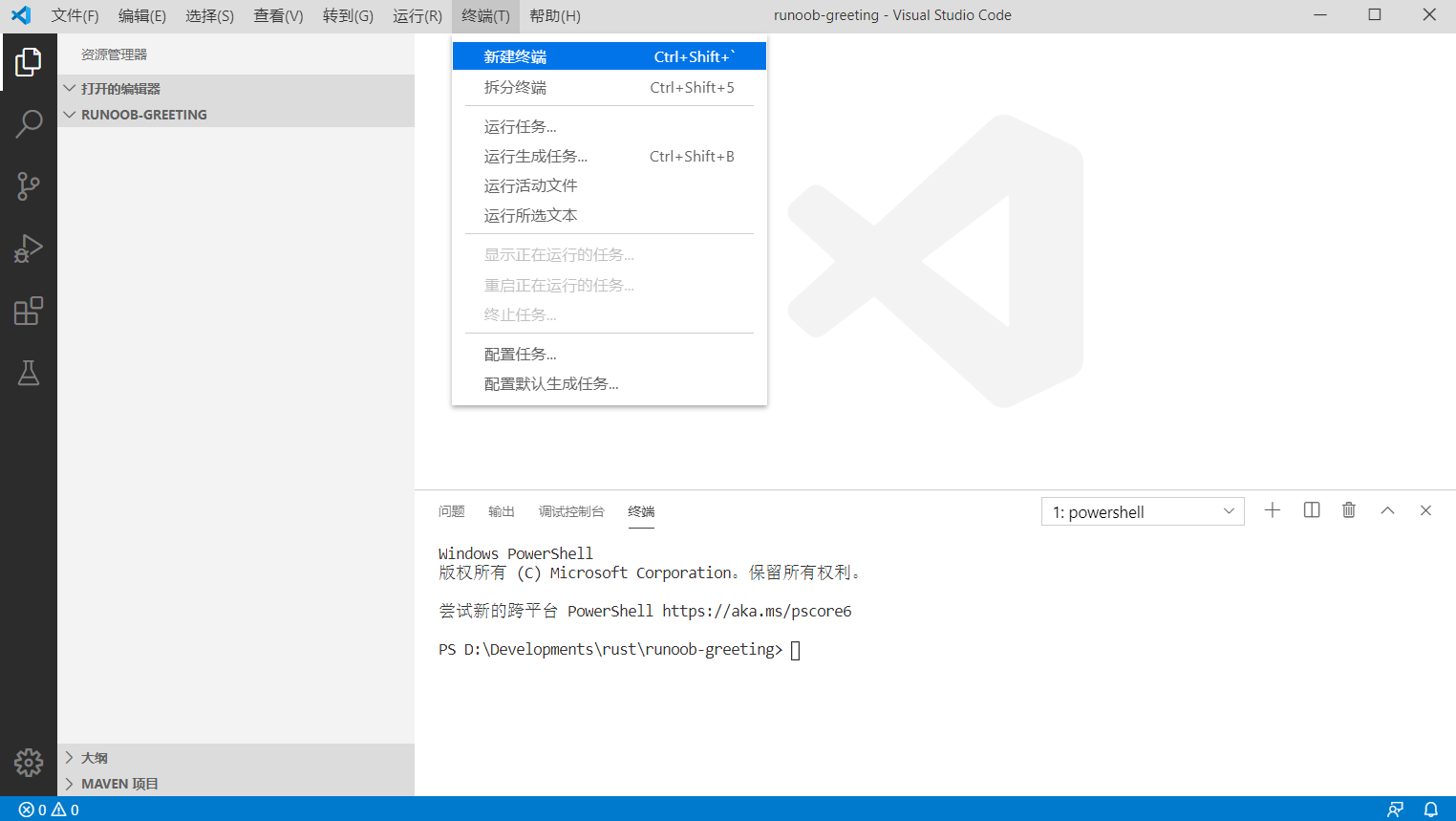
在终端中输入命令:
cargo new greeting
当前文件下会构建一个名叫greeting的Rust工程目录.
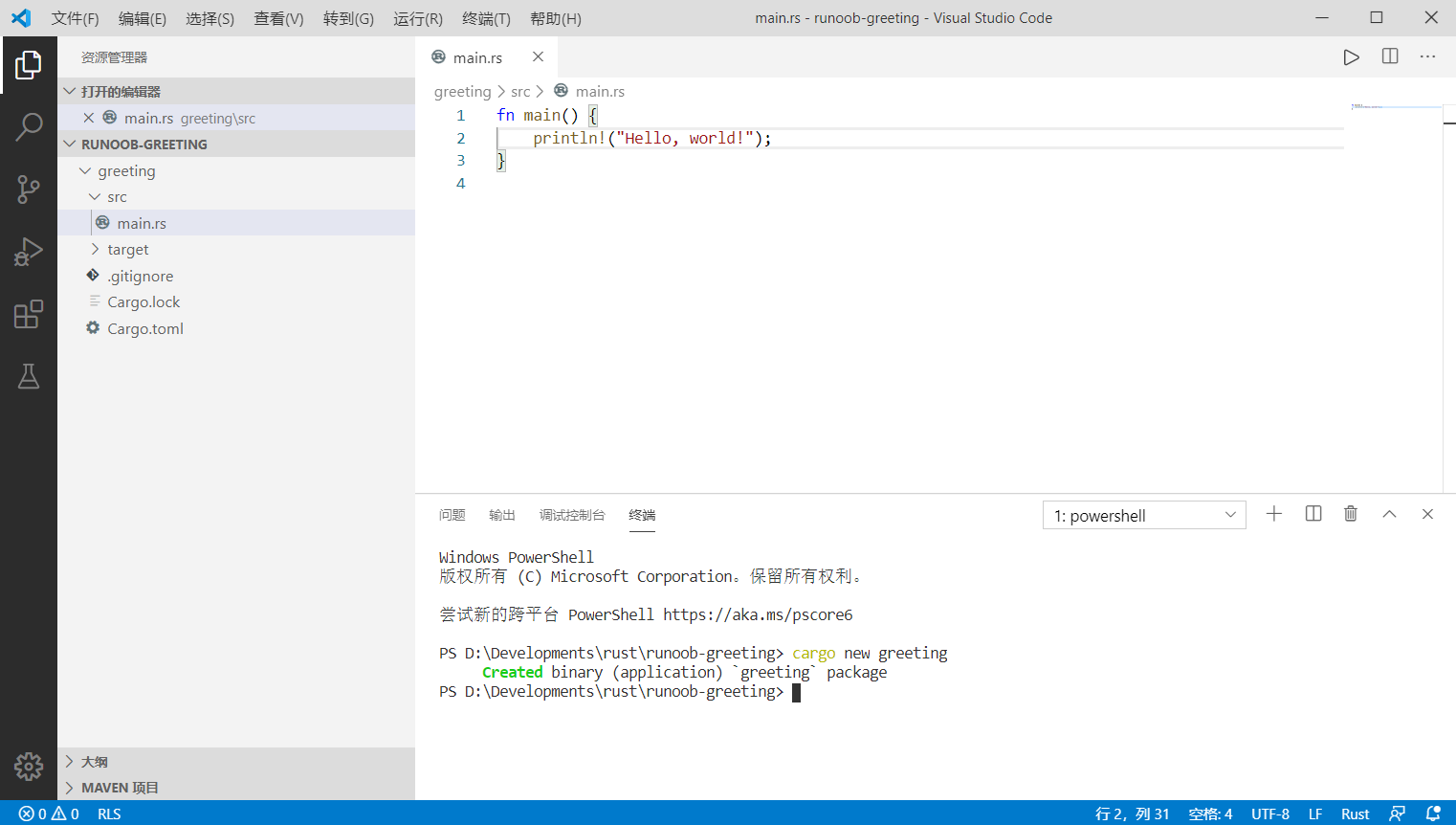
现在在终端里输入以下三个命令:
cd ./greeting
cargo build
cargo run
2
3
系统在创建工程时会生成一个Hello, world源程序main.rs, 这时会被编译并运行:

至此, 成功的构建了一个Rust命令行程序!
# Cargo 教程
在Rust开发中, 几乎所有的项目都是使用Cargo来进行管理和构建的, 因为它提供了便捷的工作流程和强大的功能, 使得Rust开发变得更加高效和可靠.
# Cargo 是什么
Cargo是Rust的官方构建系统和包管理器, 它主要有两个作用:
- 项目管理: Cargo用于创建, 构建和管理Rust项目. 通过Cargo, 可以轻松地创建新项目, 管理项目的依赖关系, 并执行项目的构建, 运行和测试等操作.
- 包管理器: Cargo还充当了Rust的包管理器. 它允许开发者在项目中引入和管理依赖项(如第三方库), 并确保这些依赖项的版本管理和兼容性.
# Cargo 主要特性和功能
- 依赖管理: Cargo通过Cargo.toml文件管理项目的依赖, 这个文件列出了项目所需的所有外部库以及它们的版本.
- 构建系统: Cargo使用Rust编译器(rustc)来构建项目, 它会自动处理依赖的编译和链接.
- 包注册表: Cargo与crates.io这个Rust社区的包注册表交互, 允许开发者搜索, 添加和管理第三方库.
- 构建配置: 通过Cargo.toml和Cargo.lock文件, Cargo允许开发者配置构建选项, 如编译器选项, 特性(features)和目标平台.
- 项目模板: Cargo提供了创建新项目的模板, 可以通过
cargo new命令快速启动新项目. - 测试: Cargo提供了一个简单的命令
cargo test来运行项目的单元测试. - 基准测试: Cargo支持使用
cargo bench命令进行基准测试. - 发布: 通过
cargo publish命令, 开发者可以将它们的库发布到crates.io上, 供其他开发者使用. - 自定义构建脚本: Cargo允许使用自定义的构建脚本来处理更复杂的构建需求.
- 多目标项目: Cargo支持在一个项目中定义多个目标, 如可执行文件, 库, 测试和基准测试.
- 跨平台构建: Cargo支持跨多个平台构建Rust程序, 包括Windows, macOS, Linux以及各种嵌入式系统.
- 构建缓存: 为了加快构建速度, Cargo使用构建缓存来存储编译后的依赖.
- 离线工作: Cargo支持在没有互联网连接的情况下工作, 它会自动使用本地缓存的依赖.
- 插件系统: Cargo允许开发者编写插件来扩展其功能.
- 环境变量: Cargo支持通过环境变量来覆盖默认的构建和运行行为.
# Cargo 功能
Cargo除了创建工程以外还具备构建(build)工程, 运行(run)工程等一系列功能, 构建和运行分别对应一下命令:
cargo new <project-name>: 创建一个新的Rust项目.cargo build: 编译当前项目.cargo run: 编译并运行当前项目.cargo check: 检查当前项目的语法和类型错误.cargo test: 运行当前项目的单元测试.cargo update: 更新Cargo.toml中指定的依赖项到最新版本.cargo --help: 查看Cargo的帮助信息.cargo publish: 将Rust项目发布到crates.io.cargo clean: 清理构建过程中生成的临时文件和目录.
# 在VSCode中配置Rust工程
Cargo是一个不错的构建工具, 如果使VSCode与它相配合那么VSCode将会是一个十分便捷的开发环境. 上一节中建立了greeting工程, 现在用VSCode打开greeting文件夹, (注意不是runoob-greeting). 打开之后, 在里面新建一个新的文件夹.vscode(注意vscode前面的点, 如果有就不需要创建). 在新建的.vscode文件夹里新建练个文件tasks.json和launch.json, 文件内容如下:
tasks.json:
{
"version": "2.0.0",
"tasks": [
{
"label": "build",
"type": "shell",
"command": "cargo",
"args": ["build"]
}
]
}
2
3
4
5
6
7
8
9
10
11
launch.json文件(适用在Windows系统上):
{
"version": "0.2.0",
"configurations": [
{
"name": "(Windows) 启动",
"preLaunchTask": "build",
"type": "cppvsdbg",
"request": "launch",
"program": "${workspaceFolder}/target/debug/${workspaceFolderBasename}.exe",
"args": [],
"stopAtEntry": false,
"cwd": "${workspaceFolder}",
"environment": [],
"externalConsole": false
},
{
"name": "(gdb) 启动",
"type": "cppdbg",
"request": "launch",
"program": "${workspaceFolder}/target/debug/${workspaceFolderBasename}.exe",
"args": [],
"stopAtEntry": false,
"cwd": "${workspaceFolder}",
"environment": [],
"externalConsole": false,
"MIMode": "gdb",
"miDebuggerPath": "这里填GDB所在的目录",
"setupCommands": [
{
"description": "为 gdb 启用整齐打印",
"text": "-enable-pretty-printing",
"ignoreFailures": true
}
]
}
]
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
launch.json文件(适用在Linux上):
{
"version": "0.2.0",
"configurations": [
{
"name": "Debug",
"type": "gdb",
"preLaunchTask": "build",
"request": "launch",
"target": "${workspaceFolder}/target/debug/${workspaceFolderBasename}",
"cwd": "${workspaceFolder}"
}
]
}
2
3
4
5
6
7
8
9
10
11
12
13
launch.json文件(适用在Mac OS系统上):
{
"version": "0.2.0",
"configurations": [
{
"name": "(lldb) 启动",
"type": "cppdbg",
"preLaunchTask": "build",
"request": "launch",
"program": "${workspaceFolder}/target/debug/${workspaceFolderBasename}",
"args": [],
"stopAtEntry": false,
"cwd": "${workspaceFolder}",
"environment": [],
"externalConsole": false,
"MIMode": "lldb"
}
]
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
然后点击VSCode左栏的"运行". 如果你使用的是MSVC选择"(Windows)启动". 如果使用的是MinGW且安装了GDB选择"(gdb)启动", gdb启动前请注意填写launch.json中的"miDebuggerPath".
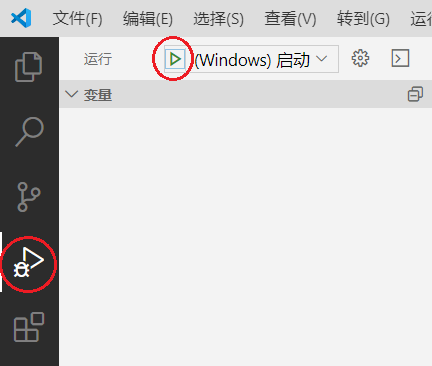
程序就会开始调试运行了, 运行输出将出现在"调试控制台"中:
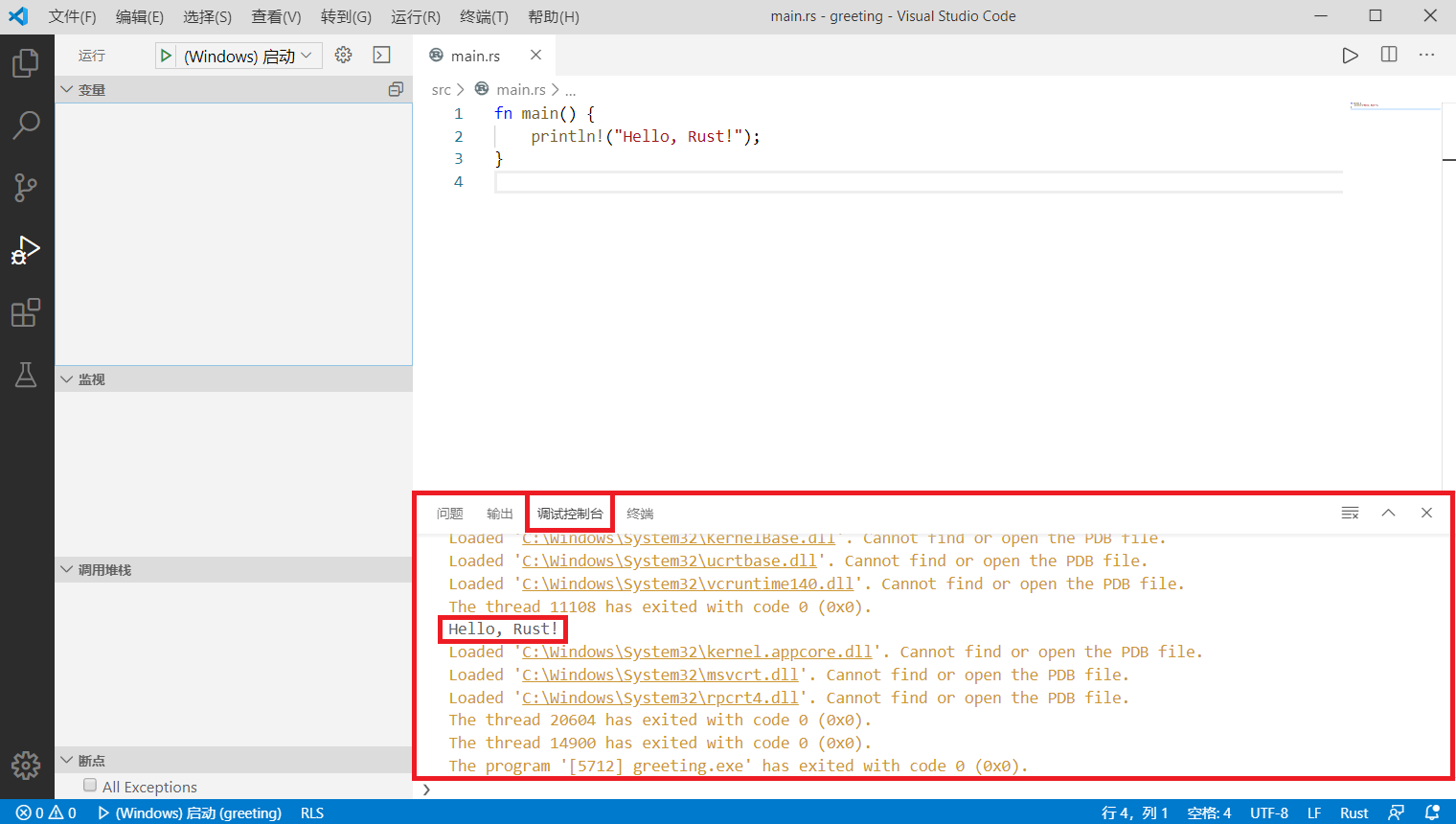
# 在VSCode中调试Rust
调试程序的方法与其它环境相似, 只需要在行号的左侧点击红点就可以设置断点, 在运行中遇到断点会暂停, 以供开发者监视实时变量的值.
# Rust 输出到命令行
在正式学习Rust语言以前, 需要先学会怎样输出一段文字到命令行, 这几乎是学习每一门语言之前必备的技能, 因为输出到命令行几乎是语言学习阶段程序表达结果的唯一方式.
在之前的Hello, World程序中大概已经告诉了大家输出字符串的方式, 但并不全面, 大家可能很疑惑为什么println!("Hello World")中的println后面还有一个!符号, 难道Rust函数之后都要加一个感叹号? 显然并不是这样, println不是一个函数, 而是一个宏规则. 这里不需要更深刻的挖掘宏规则是什么, 后面的章节会专门介绍, 并不影响下来的一段学习.
Rust输出文字的方式主要有两种: println!()和print!(). 这两个"函数"都是向命令行输出字符串的方法, 区别仅在于前者会在输出的最后附加输出一个换行符. 当用这两"函数"输出信息的时候, 第一个参数是格式字符串, 后面是一串可变参数, 对应着格式字符串中的"占位符", 这一点与C语言中的printf函数很相似. 但是, Rust中格式字符串中的占位符不是 "%+字母" 的形式, 而是一对 {}.
fn main() {
let a = 12;
println!("a is {}", a);
}
2
3
4
使用rustc命令编译runoob.rs文件:
rustc runoob.rs # 编译runoob.rs文件
编译后会生成runoob可执行文件:
./runoob # 执行runoob
以上程序的输出结果是:
a is 12
如果希望把a输出两遍, 那岂不是要写成:
println!("a is {}, a again is {}", a, a);
其实有更好的写法:
println!("a is {0}, a again is {0}", a);
在{}之间可以放一个数字, 它将把之后的可变参数当做一个数组来访问, 下标从0开始. 如果要输出{或}怎么办? 格式字符串中通过{{和}}分别转义代表{和}. 但是其他常用转义字符与C语言里的转义字符一样, 都是反斜杠开头的形式.
fun main() {
println!("{{}}")
}
2
3
以上程序的输出结果是:
{}
# Rust 基础语法
变量, 基本类型, 函数, 注释和控制流, 这些几乎是每种编程语言都具有的编程概念. 这些基础概念将存在于每个Rust程序中, 及早学习它们将使你以最快的速度学习Rust的使用.
# 变量
首先必须说明, Rust是强类型语言, 但具有自动判断变量类型的能力. 这很容易让人与弱类型语言产生混淆. 默认情况下, Rust中的变量是不可变的, 除非使用mut关键字声明为可变变量.
let a = 123; // 不可变变量
let mut b = 10; // 可变变量
2
如果要声明变量, 需要使用let关键字, 例如:
let a = 123;
只学习过JavaScript的开发者对这句话很敏感, 只学习过C语言的开发者对这句话很不理解. 在这句声明语句之后, 以下三行代码都是被禁止的:
a = "abc";
a = 4.56;
a = 456;
2
3
第一行的错误在于当声明a是123以后, a就被确定为整型数字, 不能把字符串类型的值赋给它.
第二行的错误在于自动转换数字精度有损失, Rust语言不允许精度有损失的自动数据类型转换.
第三行的错误在于a不是个可变变量.
前两种错误很容易理解, 但第三个是什么意思? 难道a不是个变量吗?
这就牵扯到了Rust语言为了高并发安全而做的设计: 在语言层面尽量少的让变量的值可以改变. 所以a的值不可变. 但这不意味着a不是"变量"(英文中的variable), 官方文档称a这种变量为"不可变变量".
如果我们编写的程序的一部分在假设值永远不会改变的情况下运行, 而我们代码的另一部分在改变该值, 那么代码的第一部分可能就不会按照设计的意图与运转. 由于这种原因造成的错误很难在事后找到. 这是Rust语言设计这种机制的原因.
当然, 使变量变得"可变"(mutable)只需一个mut关键字.
let mut a = 123;
a = 456;
2
# 常量与不可变变量的区别
既然不可变变量是不可变的, 那不就是常量吗? 为什么叫变量? 变量和常量还是有区别的. 在Rust中, 以下程序是合法的:
let a = 123; // 可以编译, 但可能有警告, 因为该变量没有被使用
let a = 456;
2
但如果a是常量就不合法:
const a: i32 = 123;
let a = 456;
2
变量的值可以"重新绑定", 但在"重新绑定"以前不能私自被改变, 这样可以确保在每一次"绑定"之后的区域里编译器可以充分的推理程序逻辑. 虽然Rust有自动判断类型的功能, 但有些情况下声明类型更加方便:
let a: u64 = 123;
这里声明了a为无符号64为整型变量, 如果没有声明类型, a将自动被判断为有符号32为整型变量, 这对于a的取值范围有很大的影响.
# 数据类型
Rust是静态类型语言, 在变量声明时可以显式指定类型, 但通常可以依赖类型推断.
基本类型: i32(32位有符号整数), u32(32位无符号整数), f64(64位浮点数), bool(布尔类型), char(字符)
let x: i32 = 42;
let y: f64 = 3.14;
let is_true: bool = true;
let letter: char = 'A';
2
3
4
# 函数
Rust函数通过fn关键字定义, 函数的返回类型通过箭头符号->指定:
fn add(a: i32, b: i32) -> i32 {
a + b
}
2
3
如果函数没有返回值, 类型默认为()(即空元组).
# 控制流
if 表达式:
let number = 7;
if number < 5 {
println!("小于 5");
} else {
println!("大于等于 5");
}
2
3
4
5
6
loop 循环: loop是Rust中的无限循环, 可以使用break退出循环.
let mut counter = 0;
loop {
counter += 1;
if counter == 10 {
break;
}
}
2
3
4
5
6
7
while 循环:
let mut number = 3;
while number != 0 {
println!("{}!", number);
number -= 1;
}
2
3
4
5
for 循环:
for number in 1..4 {
println!("{}!", number);
}
2
3
# 所有权(Ownership)
Rust中的所有权是独特的内存管理机制, 核心概念包括所有权(ownership), 借用(borrowing)和引用(reference).
所有权规则:
- Rust中的每个值都有一个所有者.
- 每个值在任意时刻只能有一个所有者.
- 当所有者超出作用域时, 值会被删除.
let s1 = String::from("hello");
let s2 = s1; // s1 的所有权被转移给了 s2
// println!("{}", s1); // 此处编译会报错, 因为 s1 已不再拥有该值
2
3
借用和引用: 借用允许引用数据而不获取所有权, 通过&符号实现.
fn main() {
let s = String::from("hello");
let len = calculate_length(&s); // 借用
println!("The length of '{}' is {}.", s, len);
}
fn calculate_length(s: &String) -> usize {
s.len()
}
2
3
4
5
6
7
8
9
# 结构体(Structs)
结构体用于创建自定义类型, 字段可以包含多种数据类型.
struct User {
username: String,
email: String,
sign_in_count: u64,
active: bool,
}
let user1 = User {
username: String::from("someusername"),
email: String::from("someone@example.com"),
sign_in_count: 1,
active: true,
};
2
3
4
5
6
7
8
9
10
11
12
13
# 枚举(Enums)
枚举允许定义可能的几种数据类型中的一种.
enum IpAddrKind {
V4,
V6,
}
let four = IpAddrKind::V4;
let six = IpAddrKind::V6;
2
3
4
5
6
7
# 模式匹配(match)
match是Rust中强大的控制流工具, 类似于switch语句:
enum Coin {
Penny,
Nickel,
Dime,
Quarter,
}
fn value_in_cents(coin: Coin) -> u8 {
match coin {
Coin::Penny => 1,
Coin::Nickel => 5,
Coin::Dime => 10,
Coin::Quarter => 25,
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 错误处理
Rust有两种主要的错误处理方式: Result<T, E>和Option<T>:
Result:
enum Result<T, E> {
Ok(T),
Err(E),
}
fn divide(a: i32, b: i32) -> Result<i32, String> {
if b == 0 {
Err(String::from("Division by zero"))
} else {
Ok(a / b)
}
}
2
3
4
5
6
7
8
9
10
11
12
Option:
fn get_element(index: usize, vec: &Vec<i32>) -> Option<i32> {
if index < vec.len() {
Some(vec[index])
} else {
None
}
}
2
3
4
5
6
7
# 所有权与借用的声明周期
Rust使用生命周期来确保引用的有效性. 生命周期标注用'a来表示, 但常见的情况下, 编译器会自动推导.
fn longest<'a>(x: &'a str, y: &'a str) -> &'a str {
if x.len() > y.len() {
x
} else {
y
}
}
2
3
4
5
6
7
# 重影(Shadowing)
重影的概念与其他面向对象语言里的"重写"(Override)或"重载"(Overload)是不一样的. 重影就是刚才讲述的所谓"重新绑定", 只所以加引号就是为了在没有介绍这个概念的时候代替一下概念. 重影就是指变量的名称可以被重新使用的机制:
fn main() {
let x = 5;
let x = x + 1;
let x = x * 2;
println!("The value of x is: {}", x);
}
2
3
4
5
6
这段程序的运行结果:
The value of x is: 12
重影与可变变量的赋值不是一个概念, 重影是指用同一个名字重新代表另一个变量实体, 其类型, 可变属性和值都可以变化. 但可变变量赋值仅能发生值的变化.
let mut s = "123";
s = s.len();
2
这段程序会出错: 不能给字符串变量赋值整型.
# Rust 运算符
在Rust中, 无论是简单的数值计算, 逻辑判断, 还是更复杂的模式匹配和位操作, 运算符都承担着核心的角色. Rust既支持我们熟悉的C系语言常见运算符, 也提供了一些独特的操作符号. 熟练掌握这些运算符, 不仅能让代码更简洁高效, 也能更好地理解Rust的语义.
# 算术运算符
| 运算符 | 说明 | 示例 | 结果 |
|---|---|---|---|
| + | 加法 | 5 + 2 | 7 |
| - | 减法 | 5 - 2 | 3 |
| * | 乘法 | 5 * 2 | 10 |
| / | 除法(整除) | 5 / 2 | 2 (整数) |
| % | 取余 | 5 % 2 | 1 |
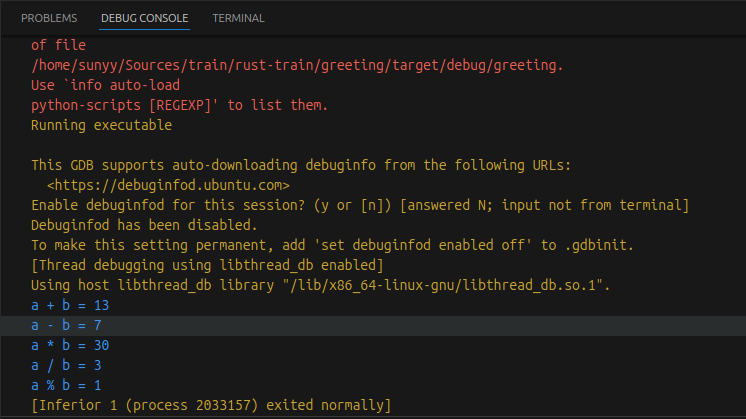
fn main() {
let a = 10;
let b = 3;
println!("a + b = {}", a + b);
println!("a - b = {}", a - b);
println!("a * b = {}", a * b);
println!("a / b = {}", a / b);
println!("a % b = {}", a % b);
}
2
3
4
5
6
7
8
9
10
Rust没有**或^这样的乘方运算符(注意: ^是按位异或), 如果要做乘方, 需要使用内置的pow或powf方法:
- 整数类型使用
.pow(exp: u32) - 浮点类型使用
.powf(exp: f64)
整数乘方:
fn main() {
let base: i32 = 2;
let result = base.pow(3); // 2^3
println!("2^3 = {}", result);
}
2
3
4
5
6
输出: 2^3 = 8
浮点数乘方:
fn main() {
let base: f64 = 2.0;
let result = base.powf(2.5): // 2^2.5
println!("2^2.5 = {}", result);
}
2
3
4
5
6
输出: 2^2.5 = 5.656854249492381
# 关系(比较)运算符
| 运算符 | 说明 | 示例 | 结果 |
|---|---|---|---|
| == | 相等 | 5 == 5 | true |
| != | 不相等 | 5 != 2 | true |
| > | 大于 | 5 > 2 | true |
| < | 小于 | 5 < 2 | false |
| >= | 大于等于 | 5 >= 5 | true |
| <= | 小于等于 | 2 <= 5 | true |
fn main() {
let x = 5;
let y = 10;
println!("x == y : {}", x == y); // false
println!("x != y : {}", x != y); // true
println!("x > y : {}", x > y); // false
println!("x < y : {}", x < y); // true
println!("x >= y : {}", x >= y); // false
println!("x <= y : {}", x <= y); // true
}
2
3
4
5
6
7
8
9
10
11
# 逻辑运算符
| 运算符 | 说明 | 示例 | 结果 |
|---|---|---|---|
| && | 逻辑与(AND) | true && false | false |
| || | 逻辑或(OR) | true || false | true |
| ! | 逻辑非(NOT) | !true | false |
fn main() {
let a = true;
let b = false;
println!("a && b = {}", a && b); // false
println!("a || b = {}", a || b); // true
println!("!a = {}", !a); // false
}
2
3
4
5
6
7
8
# 位运算符
| 运算符 | 说明 | 示例 | 结果 |
|---|---|---|---|
| & | 按位与 | 5 & 3 | 1 |
| | | 按位或 | 5 | 3 | 7 |
| ^ | 按位异或 | 5 ^ 3 | 6 |
| ! | 按位取反 | !5 | -6 |
| << | 左移 | 5 << 1 | 10 |
| >> | 右移 | 5 >> 1 | 2 |
fn main() {
let x: u8 = 0b1010; // 二进制表示的10
let y: u8 = 0b1100; // 二进制表示的12
println!("x & y = {:b}", x & y); // 按位与: 1000 (8)
println!("x | y = {:b}", x | y); // 按位或: 1110 (14)
println!("x ^ y = {:b}", x ^ y); // 按位异或: 0110 (6)
println!("!x = {:b}", !x); // 按位非: 11110101 (245)
println!("x << 1 = {:b}", x << 1); // 左移1位: 10100 (20)
println!("x >> 1 = {:b}", x >> 1); // 右移1位: 0101 (5)
}
2
3
4
5
6
7
8
9
10
11
# 赋值与复合赋值运算符
| 运算符 | 说明 | 示例 | 结果 |
|---|---|---|---|
| = | 赋值 | let mut x = 5; x = 3; | x = 3 |
| += | 加并赋值 | x += 2 | x = x + 2 |
| -= | 减并赋值 | x -= 2 | x = x - 2 |
| *= | 乘并赋值 | x *= 2 | x = x * 2 |
| /= | 除并赋值 | x /= 2 | x = x / 2 |
| %= | 取余并赋值 | x %= 2 | x = x % 2 |
| &= | = ^= <<= >>= | 位运算复合赋值 | x &= 2 |
fn main() {
let mut n = 5;
n += 3;
println!("n += 3 -> {}", n); // 8
n *= 2;
println!("n *= 2 -> {}", n); // 16
n >>= 1;
println!("n >>= 1 -> {}", n); // 8
}
2
3
4
5
6
7
8
9
10
11
12
# 其他常见运算符
| 运算符 | 说明 | 示例 | 结果 |
|---|---|---|---|
| .. | 范围(不含右端) | 0..5产生0到4 | |
| ..= | 范围(含右端) | 0..5=产生0到5 | |
| as | 类型转换 | 5 as f32 | |
| ? | 错误传播(在Result中) | some()?; | |
| * | 解引用 | *ptr | |
| & | 取引用 | &x | |
| ref | 绑定为引用 | let ref y = x; |
fn main() {
let x = 5;
let y = x as f64;
println!("y = {}", y); // 5.0
for i in 1..4 {
print!("{} ", i); // 1 2 3
}
println!();
for i in 1..=3 {
print!("{} ", i); // 1 2 3
}
println!();
let a = 10;
let b = &a;
println!("*b = {}", *b); // 10
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# Rust 数据类型
Rust 语言中的基础数据类型有以下几种:
# 整数型(Integer)
整数型简称整型, 按照比特位长度和有无符号分为以下种类:
| 位长度 | 有符号 | 无符号 |
|---|---|---|
| 8-bit | i8 | u8 |
| 16-bit | i16 | u16 |
| 32-bit | i32 | u32 |
| 64-bit | i64 | u64 |
| 128-bit | i128 | u128 |
| arch | isize | usize |
isize和usize两种整数类型是用来衡量数据大小的, 它们的位长度取决于所运行的目标平台, 如果是32为架构的处理器将使用32位位长度整型.
整数的表述方法有以下几种:
| 进制 | 例 |
|---|---|
| 十进制 | 98_222 |
| 十六进制 | 0xff |
| 八进制 | 0o77 |
| 二进制 | 0b1111_0000 |
| 字节(只能表示u8型) | b'A' |
很显然, 有的整数中间存在一个下划线, 这种设计可以让人们在输入一个很大的数字时更容易判断数值大概是多少.
# 浮点数型(Floating-Point)
Rust与其他语言一样支持32位浮点数(f32)和64位浮点数(f64). 默认情况下, 64.0将表示64位浮点数, 因为现代计算机处理器对两种浮点数计算的速度几乎相同, 但64位浮点数精度更高.
fn main() {
let x = 2.0; // f64
let y: f32 = 3.0; // f32
}
2
3
4
# 数学运算
用一段程序反映数学运算:
fn main() {
let sum = 5 + 10; // 加
let difference = 95.5 - 4.3; // 减
let product = 4 * 30; // 乘
let quotient = 56.7 / 32.2; // 除
let remainder = 43 % 5; // 求余
}
2
3
4
5
6
7
许多运算符号之后加上=号是自运算的意思, 例如: sum += 1等同于sum = sum + 1.
注意
Rust不支持++和--, 因为这两个运算符出现在变量的前后会影响代码的可读性, 减弱了开发者对变量改变的意识能力.
# 布尔型
布尔型用bool表示, 值只能为true或false.
# 字符型
字符型用char表示. Rust的char类型大小为4个字节, 代表Unicode标量值, 这意味着它可以支持中文, 日文和韩文字符等非英文字符甚至表情符号和零宽度空格在Rust中都是有效的char值.
Unicode值的范围从U+0000到U+D7FF和U+E000到U+10FFFF(包含两端). 但是, "字符"这个概念并不存在于Unicode中, 因此你对"字符"是什么的直觉可能与Rust中的字符概念不匹配. 所以一般推荐使用字符串储存UTF-8文字(非英文字符尽可能地出现在字符串中).
注意
由于中文文字编码有两种(GBK和UTF-8), 所以编程中使用中文字符串有可能导致乱码的出现, 这是因为源程序与命令行的文字编码不一致, 所以在Rust中字符串和字符都必须使用UTF-8编码, 否则编译器会报错.
# 复合类型
元组是用一对()包括的一组数据, 可以包含不同种类的数据:
let tup: (i32, f64, u8) = (500, 6.4, 1);
// tup.0 等于 500
// tup.1 等于 6.4
// tup.2 等于 1
let (x, y, z) = tup;
// y 等于 6.4
2
3
4
5
6
数组是用一对[]包括的同类型数据.
let a = [1, 2, 3, 4, 5];
// a 是一个长度为 5 的整型数组
let b = ["January", "February", "March"];
// b 是一个长度为 3 的字符串数组
let c: [i32; 5] = [1, 2, 3, 4, 5];
// c 是一个长度为 5 的 i32 数组
let d = [3; 5];
// 等同于 let d = [3, 3, 3, 3, 3];
let first = a[0];
let second = a[1];
// 数组访问
a[0] = 123; // 错误:数组 a 不可变
let mut a = [1, 2, 3];
a[0] = 4; // 正确
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# Rust 注释
Rust中的注释方式与其它语言(C, Java)一样, 支持两种注释方式:
// 这是第一种注释方式
/* 这是第二种注释方式 */
/*
* 多行注释
* 多行注释
* 多行注释
*/
2
3
4
5
6
7
8
9
# 用于说明文档的注释
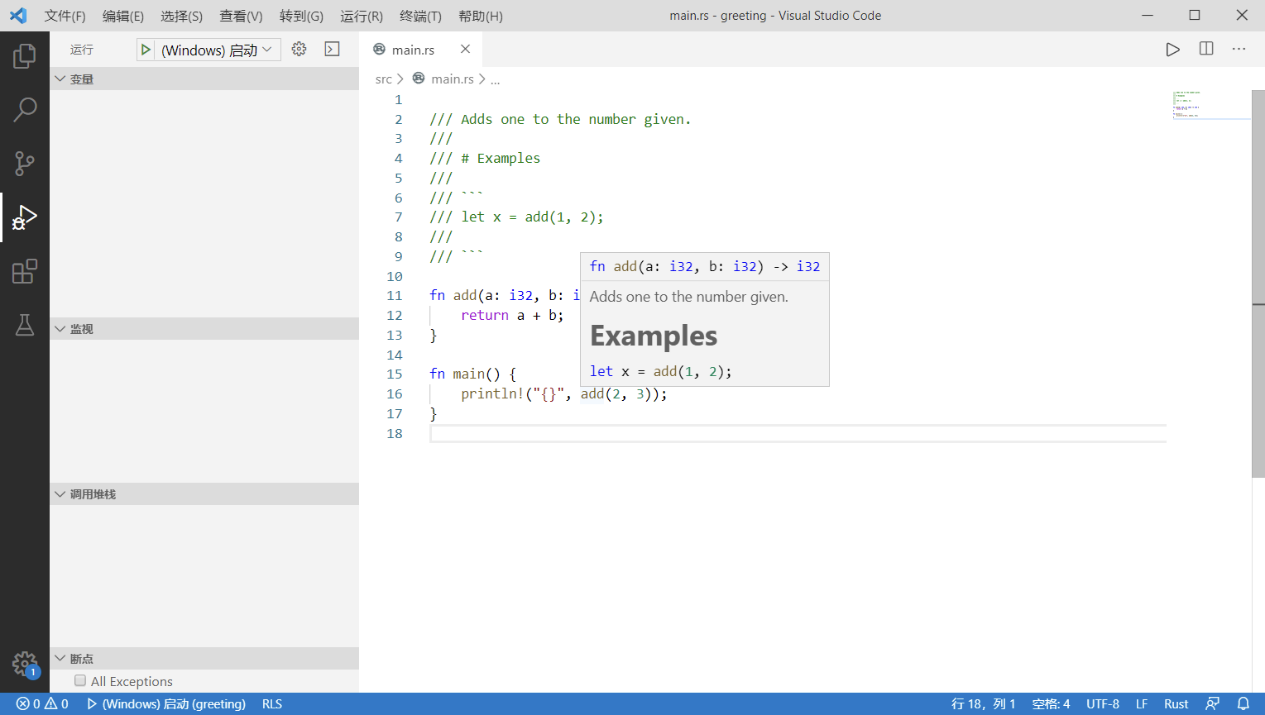
在Rust中使用//可以使其之后到第一个换行符的内容变成注释. 在这种规则下, 三个正斜杠///依然是合法的注释开始, 所以Rust可以用///作为说明文档注释的开头:
/// Adds one to the number given.
///
/// # Examples
///
/// ```
/// let x = add(1, 2);
///
/// ```
fn add(a: i32, b: i32) -> i32 {
return a + b;
}
fn main() {
println!("{}", add(2, 3));
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
程序中的函数add就会拥有一段优雅的注释, 并可以显示在IDE中:
TIP
Cargo具有cargo doc功能, 开发者可以通过这个命令将工程中的说明注释转换成HTML格式的说明文档.
# Rust 函数
函数在Rust语言中是普遍存在的. 通过之前的章节已经可以了解到Rust函数的基本形式:
fn <函数名> ( <参数> ) <函数体>
其中Rust函数名称的命名风格是小写字母以下划线分隔:
fn main() {
println!("Hello, world!");
another_function();
}
fn another_function() {
println!("Hello, runoob!");
}
2
3
4
5
6
7
8
注意, 我们在源代码中的main函数之后定义了another_function. Rust不在乎你在何处定义函数, 只需在某个地方定义它们即可.
# 函数参数
Rust中定义函数如果需要具备参数必须声明参数名称和类型:
fn main() {
another_function(5, 6);
}
fn another_function(x: i32, y: i32) {
println!("x 的值为: {}", x);
println!("y 的值为: {}", y);
}
2
3
4
5
6
7
8
# 函数体的语句和表达式
Rust函数体由一系列可以以表达式(Expression)结尾的语句(Statement)组成. 到目前为止, 我们仅见到了没有以表达式结尾的函数, 但已经将表达式用做语句的一部分. 语句是执行某些操作且没有返回值的步骤. 例如:
let a = 6;
这个步骤没有返回值, 所以以下语句不正确:
let a = (let b = 2);
表达式由计算步骤且有返回值, 以下是表达式(假设出现的标识符已经被定义):
a = 7
b + 2
c * (a + b)
2
3
Rust中可以在一个用{}包括的块里编写一个较为复杂的表达式:
fn main() {
let x = 5;
let y = {
let x = 3;
x + 1
};
println!("x 的值为: {}", x); // 5
println!("y 的值为: {}", y); // 4
}
2
3
4
5
6
7
8
9
10
11
很显然, 这段程序中包含了一个表达式块:
{
let x = 3;
x + 1
}
2
3
4
而且在块中可以使用函数语句, 最后一个步骤是表达式, 此表达式的结果值是整个表达式块所代表的值. 这种表达式叫做函数体表达式. 注意: x + 1之后没有分号, 否则它将变成一条语句! 这种表达式块是一个合法的函数体, 而且在Rust中, 函数定义可以嵌套:
fn main() {
fn five() -> i32 {
5
}
println!("five() 的值为: {}", five());
}
2
3
4
5
6
# 函数返回值
在上一个嵌套的例子中已经显示了Rust函数声明返回值类型的方式: 在参数声明之后用->来声明函数返回值的类型(不是:). 在函数体中, 随时都可以以return关键字结束函数运行并返回一个类型合适的值. 这也是最接近大多数开发者经验的做法:
fn add(a: i32, b: i32) -> i32 {
return a + b;
}
2
3
但是Rust不支持自动返回值类型判断! 如果没有明确函数返回值的类型, 函数将被认为是"纯过程", 不允许产生任何返回值, return后面不能有返回值表达式. 这样做的目的是为了让公开的函数能够形成可见的公报.
注意: 函数体表达式并不能等同于函数体, 它不能使用return 关键字.
# Rust 条件语句
在Rust语言中的条件语句是这种格式:
fn main() {
let number = 3;
if number < 5 {
println!("条件为 true");
} else {
println!("条件为 false");
}
}
2
3
4
5
6
7
8
在上述程序中有条件if语句, 这个语法在很多其他语言中很常见, 但也有一些区别: 首先, 条件表达式 number < 5 不需要用小括号包括(注意, 不需要而不是不允许); 但是Rust中的if不存在单语句不用加{}的规则, 不允许使用一个语句代替一个块. 尽管如此, Rust还是只是传统else-if语法的:
fn main() {
let a = 12;
let b;
if a > 0 {
b = 1;
}
else if a < 0 {
b = -1;
}
else {
b = 0;
}
println!("b is {}", b); // b is 1
}
2
3
4
5
6
7
8
9
10
11
12
13
14
Rust中的条件表达式必须是bool类型, 例如下面的程序是错误的:
fn main() {
let number = 3;
if number { // 报错, expected `bool`, found integerrustc(E0308)
println!("Yes");
}
}
2
3
4
5
6
虽然C/C++语言中的条件表达式用整数表示, 非0即真, 但这个规则在很多注重代码安全的语言中是被禁止的.
if <condition> { block 1 } else { block 2 }
这种语法中的{ block 1 }和{ block 2 }可不可以是函数体表达式呢? 答案是肯定的! 也就是说, 在Rust中可以使用if-else结构实现类似于三元条件运算表达式(A ? B : C)的效果:
fn main() {
let a = 3;
let number = if a > 0 { 1 } else { -1 };
println!("number 为 {}", number); // number 为 1
}
2
3
4
5
注意: 两个函数体表达式的类型必须一样! 且必须有一个else及其后的表达式块.
# Rust 循环
Rust除了灵活的条件语句以外, 循环结构的设计也十分成熟.
# while 循环
while循环是最典型的条件语句循环:
fn main() {
let mut number = 1;
while number != 4 {
println!("{}", number);
number += 1;
}
println!("EXIT");
}
2
3
4
5
6
7
8
Rust语言到此教程编撰之日还没有do-while的用法, 但是do被规定为保留字, 也许以后的版本中会用到. 在C语言中for循环使用三元语句控制循环, 但是Rust中没有这种用法, 需要用while循环来代替:
int i;
for (i = 0; i < 10; i++) {
// 循环体
}
2
3
4
let mut i = 0;
while i < 10 {
// 循环体
i += 1;
}
2
3
4
5
# for 循环
for循环是最常用的循环结构, 常用来遍历一个线性数据结构(比如数组). for循环遍历数组:
fn main() {
let a = [10, 20, 30, 40, 50];
for i in a.iter() {
println!("值为: {}", i);
}
}
2
3
4
5
6
这个程序中的for循环完成了对数组a的遍历. a.iter()代表a的迭代器(iterator), 在学习有关于对象的章节以前不做赘述. 当然, for循环其实是可以通过下标来访问数组的:
fn main() {
let a = [10, 20, 30, 40, 50];
for i in 0..5 {
println!("a[{}] = {}", i, a[i]);
}
}
2
3
4
5
6
# loop 循环
开发者一定遇到过这样的情况: 某个循环无法在开头和结尾判断是否继续进行循环, 必须在循环体中间某处控制循环的进行. 如果遇到这种情况, 我们经常会在一个while(true)循环体里实现中途退出循环的操作. Rust语言有原生的无限循环结构----loop:
fn main() {
let s = ['R', 'U', 'N', 'O', 'O', 'B'];
let mut i = 0;
loop {
let ch = s[i];
if ch == 'O' {
break;
}
println!("\'{}\'", ch);
i += 1;
}
}
2
3
4
5
6
7
8
9
10
11
12
loop循环可以通过break关键字类似于return一样使整个循环退出并给予外部一个返回值, 这是一个十分巧妙的设计, 因为loop这样的循环通常用来当做查找工具使用, 如果找到了某个东西当然要将这个结果交出去:
fn main() {
let s: [char; 6] = ['R', 'U', 'N', 'O', 'O', 'B'];
let mut i: usize = 0;
let location = loop {
let ch = s[i];
if ch == 'O' {
break i;
}
i += 1;
};
println!("\'O\' 的索引为: {}", location); // 'O' 的索引为: 3
}
2
3
4
5
6
7
8
9
10
11
12
# Rust 迭代器
Rust中的迭代器(Iterator)是一个强大且灵活的工具, 用于对集合(如数组, 向量, 链表等)进行逐步访问和操作. Rust的迭代器是惰性求值的, 这意味着迭代器本身不会立即执行操作, 而是在你需要时才会产生值. 迭代器允许你以一种声明式的方式来遍历序列, 如数组, 切片, 链表等集合类型的元素. 迭代器背后的核心思想是将数据处理过程与数据本身分离, 是代码更清晰, 更易读, 更易维护. 在Rust中, 迭代器通过实现Iterator trait来定义. 最基本的trait方法是next, 用于逐一返回迭代器中的下一个元素, 直到返回None表示结束.
pub trait Iterator {
type Item;
fn next(&mut self) -> Option<Self::Item>;
// 其他默认实现的方法如 map, filter 等.
}
2
3
4
5
6
7
迭代器遵循以下原则:
- 惰性求值(Laziness): Rust中的迭代器是惰性的, 意味着迭代器本身不会立即进行任何计算或操作, 直到你显式地请求数据. 这使得迭代器在性能上表现良好, 可以避免不必要的计算.
- 所有权和借用检查(Ownership and Borrowing Checks): Rust迭代器严格遵守所有权和借用规则, 避免数据竞争和内存错误. 迭代器的声明周期与底层数据相关联, 确保数据的安全访问.
- 链式调用(Chaining): Rust迭代器支持链式调用, 即可以将多个迭代器方法链接在一起进行组合操作, 这使得代码简洁且具有高度可读性. 例如, 通过使用 .map(), .filter(), .collect() 等方法, 可以创建复杂的数据处理流水线.
- 高效内存管理(Efficient Memory Management): 迭代器避免了不必要的内存分配, 因为大多数操作都是惰性求值的, 并且在使用时直接进行遍历操作. 这对于处理大数据集合尤其重要.
- 抽象和通用性(Abstraction and Generality): Rust的迭代器通过Iterator trait实现抽象和通用性, 任何实现了Iterator trait的类型都可以在不同的上下文中作为迭代器使用. 提高了代码的重用性和模块化.
# 创建迭代器
最常见的方式是通过集合的.iter(), .iter_mut()或.into_iter()方法来创建迭代器:
.iter(): 返回集合的不可变引用迭代器..iter_mut(): 返回集合的可变引用迭代器..into_iter(): 将集合转义所有权并生成值迭代器.
使用iter()方法创建借用迭代器:
let vec = vec![1, 2, 3, 4, 5];
let iter = vec.iter();
2
使用iter_mut()方法创建可变借用迭代器:
let mut vec = vec![1, 2, 3, 4, 5];
let iter_mut = vec.iter_mut();
2
使用into_iter()方法创建获取所有权迭代器:
let vec = vec![1, 2, 3, 4, 5];
let into_iter = vec.into_iter();
2
fn main() {
let v = vec![1, 2, 3];
let mut iter = v.iter();
assert_eq!(iter.next(), Some(&1));
assert_eq!(iter.next(), Some(&2));
assert_eq!(iter.next(), Some(&3));
assert_eq!(iter.next(), None); // 迭代结束
}
2
3
4
5
6
7
8
9
# 迭代器方法
Rust的迭代器提供了丰富的方法来处理集合中的元素, 其中一些常见的方法包括:
map(): 对每个元素应用给定的转换函数.filter(): 根据给定的条件过滤集合中的元素.fold(): 对集合中的元素进行累积处理.skip(): 跳过指定数量的元素.take(): 获取指定数量的元素.enumerate(): 为每个元素提供索引.- ...
使用map()方法对每个元素进行转换:
let vec = vec![1, 2, 3, 4, 5];
let squared_vec: Vec<i32> = vec.iter().map(|x| x * x).collect();
2
使用filter()方法根据条件过滤元素:
let vec = vec![1, 2, 3, 4, 5];
let filtered_vec: Vec<i32> = vec.into_iter().filter(|&x| x % 2 == 0).collect();
2
fn main() {
let vec = vec![1, 2, 3, 4, 5];
let squared_vec: Vec<i32> = vec.iter().map(|x| x * x).collect();
println!("{:?}", squared_vec); // 输出: [1, 4, 9, 16, 25]
let filtered_vec: Vec<i32> = vec.into_iter().filter(|&x| x % 2 == 0).collect();
println!("{:?}", filtered_vec); // 输出: [2, 4]
}
2
3
4
5
6
7
8
# 使用for循环遍历迭代器
Rust提供了for循环语法来遍历迭代器中的元素, 是一种更加简洁和直观的遍历方式. Rust的for循环底层实际上是使用迭代器的.
let vec = vec![1, 2, 3, 4, 5];
for &num in vec.iter() {
println!("{}", num);
}
2
3
4
在这个循环中, vec.iter()返回一个迭代器, for循环遍历这个迭代器, 并将每个元素赋值给num变量, 然后执行循环体中的代码.
# 消耗型适配器
使用迭代器直到它被完全消耗, 迭代器有许多可以消耗迭代器的方法, 它们会通过执行迭代来返回最终的结果(比如总和, 集合等), 这些方法会消耗迭代器本身.
collect(): 将迭代器转换为集合(如向量, 哈希集).sum(): 计算迭代器中所有元素的和.product(): 计算迭代器中所有元素的乘积.count(): 返回迭代器中元素的个数.
let v = vec![1, 2, 3];
let sum: i32 = v.iter().sum();
assert_eq!(sum, 6);
2
3
# 适配器
迭代器适配器允许你通过方法链来改变或过滤迭代器的内容, 而不会立刻消耗它.
map(): 对每个元素应用某个函数, 并返回一个新的迭代器.filter(): 过滤出满足条件的元素.take(n): 只返回前n个元素的迭代器.skip(n): 跳过前n个元素, 返回剩下的元素迭代器.
let v = vec![1, 2, 3, 4, 5];
let doubled: Vec<i32> = v.iter().map(|x| x * 2).collect();
assert_eq!(doubled, vec![2, 4, 6, 8, 10]);
2
3
# 迭代器链
可以将多个迭代器适配器链接在一起, 形成迭代器链.
// use std::iter::Peekable;
fn main() {
let arr = [1, 2, 3, 4, 5];
let mut iter = arr.into_iter().peekable();
while let Some(val) = iter.next() {
if val % 2 == 0 {
continue;
}
println!("{}", val);
}
}
2
3
4
5
6
7
8
9
10
11
12
# 收集器
使用collect方法将迭代器的元素收集到某种集合中.
let v = vec![1, 2, 3, 4, 5];
let doubled: Vec<i32> = v.iter().map(|x| x * 2).collect();
assert_eq!(doubled, vec![2, 4, 6, 8, 10]);
2
3
# 惰性求值
正如前面提到的, Rust迭代器是惰性的, 这意味着像map(), filter()等不会立刻执行操作, 直到调用像collect()这样的消耗性方法才会真正处理数据. 这使得迭代器处理更加高效, 因为避免了不必要的计算.
# 自定义迭代器
也可以为自己的类型实现Iterator trait, 只需要定义next()方法即可. 例如, 实现一个从1到5的简单迭代器:
struct Counter {
count: usize,
}
impl Counter {
fn new() -> Counter {
Counter { count: 0 }
}
}
impl Iterator for Counter {
type Item = usize;
fn next(&mut self) -> Option<Self::Item> {
self.count += 1;
if self.count <= 5 {
Some(self.count)
} else {
None
}
}
}
fn main() {
let mut counter = Counter::new();
while let Some(num) = counter.next() {
println!("{}", num); // 输出 1 到 5
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
# 并行迭代器
如果需要在多线程环境中并行化操作, rayon crate提供了并行迭代器的支持, 通过.par_iter()代替.iter(), 可以在多线程环境中加速迭代操作.
# 迭代器和声明周期
迭代器的生命周期与它所迭代的元素的生命周期相关联. 迭代器可以借用元素, 也可以取得元素的所有权. 这在迭代器的实现中通过生命周期参数来控制.
# 迭代器与闭包
迭代器适配器经常与闭包一起使用, 闭包允许你为迭代器操作提供定制逻辑.
# 迭代器和性能
迭代器通常是非常高效的, 因为它们允许编译器做出优化. 例如, 编译器可以内联迭代器适配器的调用, 并且可以利用迭代器的惰性求值特性.
# 实例
下面实例演示了如何使用迭代器对一个数组进行遍历, 并输出数组中的元素.
// 主函数
fn main() {
// 定义一个包含整数的数组
let numbers = vec![1, 2, 3, 4, 5];
// 使用迭代器遍历数组并打印每个元素
println!("Iterating through the array:");
for num in numbers.iter() {
println!("{}", num);
}
// 使用迭代器的 map 方法将每个元素平方并收集到一个新数组
let squared_numbers: Vec<i32> = numbers.iter().map(|x| x * x).collect();
// 输出平方后的数组
println!("Squared numbers: {:?}", squared_numbers);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
以上代码中, 我们首先定义了一个包含整数的数组numbers, 然后使用iter()方法获取数组的迭代器, 并通过for循环遍历迭代器, 输出数组中的每个元素. 接着使用迭代器的map()方法对数组中的每个元素进行平方运算, 并使用collect()方法将结果收集到一个新的数组squared_numbers中, 最后输出平方后的数组.
以下示例使用filter()方法对一个数组进行过滤, 并输出过滤后的结果:
// 主函数
fn main() {
// 定义一个包含整数的数组
let numbers = vec![1, 2, 3, 4, 5, 6, 7, 8, 9, 10];
// 使用迭代器的 filter 方法筛选出偶数并收集到一个新数组
let even_numbers: Vec<i32> = numbers.iter().filter(|&&x| x % 2 == 0).cloned().collect();
// 输出筛选后的数组
println!("Even numbers: {:?}", even_numbers);
}
2
3
4
5
6
7
8
9
10
11
以上代码中, 我们首先定义了一个包含整数的数组numbers, 然后使用迭代器的filter()方法对数组进行过滤, 筛选出其中的偶数. 在filter()方法的闭包中, 我们使用模运算来判断元素是否为偶数, 最后使用cloned()方法来克隆每个偶数的值, 并使用collect()方法将结果收集到一个新的数组even_numbers中, 最终输出了筛选结果.
# Rust迭代器方法
| 方法名 | 描述 | 示例 |
|---|---|---|
next() | 返回迭代器中的下一个元素. | let mut iter = (1..5).into_iter(); while let Some(val) = iter.next() { println!("{}", val); } |
size_hint() | 返回迭代器中剩余元素数量的下界和上界 | let iter = (1..10).into_iter(); println!("{:?}", iter.size_hint()); |
count() | 计算迭代器中的元素数量. | let count = (1..10).into_iter().count(); |
nth() | 返回迭代器中第n个元素. | let third = (0..10).into_iter().nth(2); |
last() | 返回迭代器中的最后一个元素. | let last = (1..5).into_iter().last(); |
all() | 如果迭代器中的所有元素都满足某个条件, 返回true. | let all_positive = (1..=5).into_iter().all(|x| x > 0); |
any() | 如果迭代器中至少一个元素满足某个条件, 返回true. | let any_negative = (1..5).into_iter().any(|x| x < 0); |
find() | 返回迭代器中第一个满足某个条件的元素. | let first_even = (1..10).into_iter().find(|x| x % 2 == 0); |
find_map() | 对迭代器中的元素应用某一个函数, 返回第一个返回Some的结果. | let first_letter = "hello".chars().find_map(|c| if c.is_alphabetic() { Some(c) } else { None }); |
map() | 对迭代器中的每一个元素应用一个函数. | let squares: Vec<i32> = (1..5).into_iter().map(|x| x * x).collect(); |
filter() | 保留迭代器中满足某个条件的元素. | let evens: Vec<i32> = (1..10).into_iter().filter(|x| x % 2 == 0).collect(); |
filter_map() | 对迭代器中的元素应用一个函数, 如果函数返回Some, 则保留结果. | let chars: Vec<char> = "hello".chars().filter_map(|c| if c.is_alphabetic() { Some(c.to_ascii_uppercase()) } else { None }).collect(); |
map_while() | 对迭代器中的元素应用一个函数, 直到函数返回None. | let first_three = (1..).into_iter().map_while(|x| if x <= 3 { Some(x) } else { None }); |
take_while() | 从迭代器中取出某个条件的元素, 直到不满足为止. | let first_five = (1..10).into_iter().take_while(|x| x <= 5).collect::<Vec<_>>(); |
skip_while() | 跳过迭代器中满足某个条件的元素, 直到不满足为止. | let odds: Vec<i32> = (1..10).into_iter().skip_while(|x| x % 2 == 0).collect(); |
for_each() | 对迭代器中的每个元素执行某种操作. | let mut counter = 0; (1..5).into_iter().for_each(|x| counter += x); |
fold() | 对迭代器中的元素进行折叠, 使用一个累加器. | let sum: i32 = (1..5).into_iter().fold(0, |acc, x| acc + x); |
try_fold() | 对迭代器中的元素进行折叠, 可能在遇到错误时提前返回. | let result: Result = (1..5).into_iter().try_fold(0, |acc, x| if x == 3 { Err("Found the number 3") } else { Ok(acc + x) }); |
scan() | 对迭代器中的元素进行状态化的折叠. | let sum: Vec<i32> = (1..5).into_iter().scan(0, |acc, x| { *acc += x; Some(*acc) }).collect(); |
take() | 从迭代器中取出最多n个元素. | let first_five = (1..10).into_iter().take(5).collect::<Vec<_>>(); |
skip() | 跳过迭代器中的前n格元素. | let after_five = (1..10).into_iter().skip(5).collect::<Vec<_>>(); |
zip() | 将两个迭代器中的元素打包成元组. | let zipped = (1..3).zip(&['a', 'b', 'c']).collect::<Vec<_>>(); |
cycle() | 重复迭代器中的元素, 直到无穷. | let repeated = (1..3).into_iter().cycle().take(7).collect::<Vec<_>>(); |
chain() | 连接多个迭代器. | let combined = (1..3).chain(4..6).collect::<Vec<_>>(); |
rev() | 反转迭代器中的元素顺序. | let reversed = (1..4).into_iter().rev().collect()::<Vec<_>>(); |
enumerate() | 为迭代器中的每个元素添加索引. | let enumerated = (1..4).into_iter().enumerate().collect::<Vec<_>>(); |
peeking_take_while() | 取出满足条件的元素, 同时保留迭代器的状态, 可以继续取出后续元素. | let (first, rest) = (1..10).into_iter().peeking_take_while(|&x| x < 5); |
step_by() | 按照指定的步长返回迭代器中的元素. | let even_numbers = (0..10).into_iter().step_by(2).collect::<Vec<_>>(); |
fuse() | 创建一个额外的迭代器, 它在迭代器耗尽后仍然可以调用next()方法. | let mut iter = (1..5).into_iter().fuse(); while iter.next().is_some() {} |
inspect() | 在取出每个元素时执行一个闭包, 但不改变元素. | let mut counter = 0; (1..5).into_iter().inspect(|x| println!("Inspecting: {}", x)).for_each(|x| println!("Processing: {}", x)); |
same_items() | 比较两个迭代器是否产生相同的元素序列. | let equal = (1..5).into_iter().same_items((1..5).into_iter()); |
# 总结
Rust的迭代器是一个功能强大且灵活的工具, 它允许以声明式的方式处理序列, 迭代器的设计考虑了安全性, 性能和表达力, 是Rust语言的核心特性之一. 通过迭代器, Rust程序员可以写出既安全又高效的代码.
# Rust 闭包
# Rust 闭包简介
Rust中的闭包是一种匿名函数, 它们可以捕获并存储其环境变量中的变量. 闭包允许在其定义的作用域之外访问变量, 并且可以在需要时将其移动或借用给闭包. 闭包在Rust中被广泛应用于函数式编程, 并发编程和事件驱动编程等领域. 闭包在Rust中非常有用, 因为它们提供了一种简洁的方式来编写和使用函数. 闭包在Rust中非常灵活, 可以存储在变量中, 作为参数传递, 甚至作为返回值. 闭包通常用于需要短小的自定义逻辑的场景, 例如迭代器, 回调函数等.
| 特性 | 闭包 | 函数 |
|---|---|---|
| 匿名性 | 是匿名的, 可存储为变量 | 有固定名称 |
| 环境捕获 | 可以捕获外部变量 | 不能捕获外部变量 |
| 定义方式 | 参数 | |
| 类型推导 | 参数和返回值类型可以推导 | 必须显式指定 |
| 存储于传递 | 可以作为变量, 参数, 返回值 | 同样支持 |
以下是Rust闭包的一些关键特性和用法:
# 闭包的声明
闭包的声明语法:
let closure_name = |参数列表| 表达式或语句块;
参数可以有类型注解, 也可以忽略, Rust编译器会根据上下文推导它们.
let add_one = |x: i32| x + 1;
闭包的参数和返回值: 闭包可以有零个或多个参数, 并且可以返回一个值.
let calculate = |a, b, c| a * b + c;
闭包的调用: 闭包可以像函数一样被调用.
let result = calculate(1, 2, 3);
# 匿名函数
闭包在Rust中类似于匿名函数, 可以在代码中以{}语法块的形式定义, 使用||符号来表示参数列表, 实例如下:
let add = |a, b| a + b;
println!("{}", add(2, 3)); // 输出 5
2
在这个示例中, add是一个闭包, 接受两个参数a和b, 返回它们的和.
# 捕获外部变量
闭包可以捕获周围环境中的变量, 这意味着它可以访问定义闭包时所在作用域中的变量, 例如:
let x = 5;
let square = |num| num * x;
println!("{}", square(3)); // 输出: 15
2
3
闭包可以通过三种方式捕获外部变量:
- 按引用捕获(默认行为, 类似
&T) - 按值捕获(类似
T) - 可变借用捕获(类似
&mut T)
fn main() {
let mut num = 5;
// 按引用捕获
let print_num = || println!("num = {}", num);
print_num(); // 输出: num = 5
// 按值捕获
let take_num = move || println!("num take = {}", num);
take_num(); // 输出: num take = 5
println!("{}", num); // 正常输出: 5 不会编译错误
// 可变借用捕获
let mut change_num = || num += 1;
change_num();
println!("num after closure = {}", num); // 输出: num after closure = 6
// 按值捕获
let s = String::from("hello");
let consume_s = move || println!("s = {}", s);
consume_s(); // 输出: s = hello
// println!("{}", s); // 编译错误: s 已被移动
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
说明:
- 闭包默认按引用捕获外部变量.
- 使用
move关键字可以强制按值捕获, 将外部变量的所有权转移到闭包内. - 如果闭包需要修改外部变量, 需显式声明为
mut闭包.
有关下面代码的解释:
// 按值捕获
let take_num = move || println!("num take = {}", num);
take_num(); // 输出: num take = 5
println!("{}", num); // 正常输出: 5 不会编译错误
2
3
4
num的类型是i32: 在Rust中, 基本数字类型(如i32)实现了Copytrait.Copytrait的行为: 当使用move关键字将一个实现了Copytrait的变量捕获到闭包中时, Rust会复制(copy)该变量的值, 而不是移动(move)所有权.- 结果: 原始的
num变量在闭包创建后仍然有效, 因此取消注释println!("{}", num);不会导致编译错误, 会正常打印5.
只有当num是一个没有实现Copy trait的类型(例如String或Vec)时, 才会出现编译错误, 验证代码如下:
fn main() {
// 情况 1: i32 (实现了 Copy) - 注释是错的
let num = 5;
let take_num = move || println!("num take = {}", num);
take_num();
println!("Original num is still here: {}", num); // 这行代码完全可以运行!
// 情况 2: String (未实现 Copy) - 注释是对的
let s = String::from("hello");
let take_string = move || println!("string take = {}", s);
take_string();
// println!("{}", s); // 这行代码确实会报错:value borrowed here after move
}
2
3
4
5
6
7
8
9
10
11
12
13
# 移动与借用
闭包可以通过move关键字获取外部变量的所有权, 或者通过借用的方式获取外部变量的引用. 例如:
借用变量: 默认情况下, 闭包会借用它捕获的环境中的变量, 这意味着闭包可以使用这些变量, 但不能改变它们的所有权. 这种情况下, 闭包和外部作用域都可以使用这些变量. 例如:
let x = 10;
let add_x = |y| x + y;
println!("{}", add_x(5)); // 输出 15
println!("{}", x); // 仍然可以使用 x
2
3
4
获取所有权: 通过在闭包前添加move关键字, 闭包会获取它捕获的环境变量的所有权. 这意味着这些变量的所有权会从外部作用域转移到闭包内部, 外部作用域将无法再使用这些变量. 例如:
let s = String:from("hello");
let print_s = move || println!("{}", s);
print_s(); // 输出 hello
// println!("{}", s); // 这行代码将会报错, 因为 s 的所有权已经被转移给了闭包.
2
3
4
通过这两种方式, Rust提供了灵活的机制来处理闭包与外部变量之间的关系, 使得在编写并发, 安全的代码时更加方便.
# 额外的知识
闭包可以通过三种方式捕获外部变量:
- 按引用捕获(默认行为, 类似
&T) - 按值捕获(类似
T) - 可变借用捕获(类似
&mut T)
这段话描述的是Rust闭包(Closure)最核心的特性之一: 它是如何处理"闭包外面的变量"的.
在其他语言(如JavaScript或Python)中, 闭包捕获变量通常只有一种方式(引用/指针). 但在Rust中, 由于**所有权(Ownership)**系统的存在, 闭包必须明确它对外部变量拥有什么权限. 可以把闭包想象成一个"借东西的人", 而外部变量是"物品", 这段话描述了三种"借"的方式:
- 按引用捕获(Immutable Borrow,
&T)- 通俗理解: "我只看看, 不改也不拿走".
- 行为: 闭包只读取外部变量的数据, 不修改它, 也不获取它的所有权.
- Rust内部: 闭包里存的是变量的不可变引用(
&T). - 场景: 当只在闭包里打印变量, 计算数据但不修改时.
let color = String::from("red");
// 这个闭包只读取了 color, 所以它是按引用捕获 (&color)
let print_color = || println!("Color: {}", color);
print_color();
print_color(); // 可以多次调用, 因为 color 还在外面
2
3
4
5
6
7
- 可变借用捕获(Mutable Borrow,
&mut T)- 通俗理解: "借我用一下, 我会修改它, 用完还给你."
- 行为: 闭包会修改外部变量的值.
- Rust内部: 闭包里存的是变量的可变引用(
&mut T). - 限制:
- 外部变量必须声明为
mut. - 在闭包借用期间, 其他人不能访问这个变量(遵循Rust的借用规则).
- 外部变量必须声明为
let mut count = 0;
// 这个闭包修改了 count, 所以它是可变借用捕获 (&mut count)
let mut inc = || {
count += 1;
};
2
3
4
5
6
- 按值捕获(Move / Take Ownership,
T)- 通俗理解: "这个东西归我了, 原来的主人不能再用了."
- 行为: 闭包获取了外部变量的所有权.
- Rust内部: 变量的数据**移动(Move)**进了闭包里面.
- 场景:
- 隐式: 闭包代码里把变量"消耗"掉了(比如把变量传给了另一个函数, 或者返回了它).
- 显式: 使用了
move关键字(常用于多线程, 强制把变量的所有权移交给新线程).
let haystack = String::from("needle");
// 这里的 move 关键字强制闭包获取 haystack 的所有权
let consume = move || {
println!("I have: {}", haystack);
};
consume();
// println!("{}", haystack); // 报错, haystack 的所有权已经移交给闭包了.
2
3
4
5
6
7
8
9
| 捕获方式 | 对应Rust类型 | 权限 | 现实类比 |
|---|---|---|---|
| 按引用 | &T | 只读 | 站在橱窗外看商品 |
| 可变借用 | &mut T | 读 + 写 | 接朋友的笔记并在上面写字 |
| 按值 | T | 拥有所有权 | 朋友把笔记送给你了(他没有了) |
# 闭包的特性
# 闭包可以作为函数参数
闭包经常作为参数传递给函数, 如迭代器的.map(), .filter()方法:
fn apply_to_value<F>(val: i32, f: F) -> i32
where
F: Fn(i32) -> i32,
{
f(val)
}
fn main() {
let double = |x| x * 2;
let result = apply_to_value(5, double);
println!("Result: {}", result); // 输出: Result: 10
}
2
3
4
5
6
7
8
9
10
11
12
这里的Fn是闭包的一个特性(trait), 用于表示闭包可以被调用.
# 闭包可以作为返回值
闭包还可以作为函数的返回值. 由于闭包是匿名的, 我们需要使用impl Trait或Box来描述其类型.
使用impl Fn返回闭包:
fn make_adder(x: i32) -> impl Fn(i32) -> i32 {
move |y| x + y
}
fn main() {
let add_five = make_adder(5);
println!("5 + 3 = {}", add_five(3)); // 输出: 5 + 3 = 8
}
2
3
4
5
6
7
8
使用Box<dyn Fn>返回闭包:
fn make_adder(x: i32) -> Box<dyn Fn(i32) -> i32> {
Box::new(move |y| x + y)
}
fn main() {
let add_ten = make_adder(10);
println!("10 + 5 = {}", add_ten(5)); // 输出: 10 + 5 = 15
}
2
3
4
5
6
7
8
闭包特性: 闭包根据其捕获方式实现了以下三个特性:
- Fn: 不需要修改捕获的变量, 闭包可以多次调用.
- FnMut: 需要修改捕获的变量, 闭包可以多次调用.
- FnOnce: 只需要捕获所有权, 闭包只能调用一次.
fn call_closure<F>(f: F)
where
F: FnOnce(),
{
f(); // 只调用一次
}
fn main() {
let name = String::from("Rust");
// 使用 move 关键字将 name 的所有权移动到闭包中
let print_name = move || println!("Hello, {}!", name);
call_closure(print_name);
// println!("{}", name); // 这里会报错,因为 name 的所有权已经被移动
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
这段话描述的是Rust编译器如何根据闭包对环境(捕获的变量)做了什么, 来自动给闭包打上的"标签"(Trait). 可以把这三个特性理解为闭包被调用时的"门槛"或"代价".
为了理解这段话, 需要从所有权和借用的角度来拆解:
- FnOnce: 代价最大, 只能用一次
- 字面意思: Function Once (只运行一次的函数).
- 核心行为: 吃掉(消耗)了捕获的变量.
- 为什么只能调用一次? 闭包在执行过程中, 把捕获的变量的所有权"转移(Move)"走了, (比如把变量传给了别的函数, 或者释放了它). 既然变量的所有权没了, 闭包第二次就没法运行了.
- 代码视角:
let s = String::from("hello");
// 这个闭包把 s 的所有权拿走并打印(drop)了
let c = || {
let _x = s; // s 被移动到了 _x, 然后随着闭包结束被销毁了
};
c(); // 第一次调用: OK, s 被消耗了
// c(); 第二次调用: 报错, 因为 s 已经没了, 闭包没法再干活了
2
3
4
5
6
7
8
- FnMut: 代价中等, 可以多次修改
- 字面意思: Function Mutable (可变的函数).
- 核心行为: 修改了捕获的变量.
- 为什么可以多次调用? 它没有把变量"吃掉", 只是"借来改改". 只要闭包还活着, 变量就还在, 所以可以反复调用.
- 限制: 因为要修改数据, 所以在调用它的时候, 必须保证它是独占的(可变借用
&mut). - 代码视角:
let mut count = 0;
// 这个闭包修改了 count
let mut c = || {
count += 1;
};
c(); // count 变成 1
c(); // count 变成 2
2
3
4
5
6
7
8
- Fn: 代价最小, 随便调用
- 字面意思: Function (最普通的函数)
- 核心行为: 只读(不修改也不消耗)捕获的变量.
- 为什么最灵活? 它只是"看一眼"数据(不可变借用
&). 因为它不破坏数据, 也不独占数据, 所以可以疯狂调用它, 甚至在多线程里并发调用它. - 代码视角:
let s = String::from("hello");
// 这个闭包只读取 s
let c = || {
println!("{}", s);
};
c();
c(); // 随便调用, s 完好无损
2
3
4
5
6
7
8
核心难点: 它们是"包含"关系, 理解这段话最关键的一点是: 这是一个层级关系(子集关系).
你可以把它们想象成对闭包能力的要求:
- Fn是最高的要求(要求闭包必须很"纯洁", 只读不动手).
- FnOnce是最低的要求(只要能跑就行, 哪怕跑完就挂).
包含链条:
- 如果一个闭包是
Fn(只读), 那它肯定也是FnMut(能读当然也能算作一种特俗的"操作"), 也肯定是FnOnce(能跑多次当然也能跑一次). - 如果一个闭包是
FnMut(能改), 那它肯定是FnOnce, 但不一定是Fn(因为它不纯洁, 修改了状态).
图解类比:
- FnOnce(一次性门票): 进门后票就撕了
- 适用场景: 所有闭包都能当一次性门票使用.
- FnMut(记事本): 可以反复在上面写字.
- 适用场景: 修改环境的闭包, 只读的闭包.
- Fn(教科书): 可以反复看, 但不能改.
- 适用场景: 只有那些只读的闭包.
总结这段话的逻辑: 当你看到一个函数参数要求是Fn, FnMut或FnOnce时, 它的潜台词是:
- 要求
FnOnce: "我只打算调用这个闭包一次". (所以你可以传任何闭包给我, 哪怕是会消耗变量的). - 要求
FnMut: "我会多次调用这个闭包, 而且可能会改变里面的状态". (你不能传消耗变量的闭包给我, 因为第二次我就没法用了). - 要求
Fn: "我会多次调用这个闭包, 而且我不希望它有副作用(修改状态)". (这是最严格的限制, 通常用于并发场景).
# 更多应用说明
# 迭代器中的闭包
闭包在Rust中经常与迭代器一起使用, 用于对集合中的元素进行处理. 例如, 使用 map() 方法对集合中的每个元素进行转换:
let vec = vec![1, 2, 3];
let squared_vec: Vec<i32> = vec.iter().map(|x| x * x).collect();
println!("{:?}", squared_vec); // 输出: [1, 4, 9]
2
3
在这个示例中, 闭包 |x| x * x 被传递给 map() 方法, 对集合中的每个元素进行平方操作.
# 闭包作为参数和返回值
闭包可以作为参数传递给函数, 也可以作为函数的返回值.
fn call_fn<F>(f: F) where F: Fn() {
f();
};
let add = |a, b| a + b;
call_fn(move || println!("Hello from a closure!"));
2
3
4
5
6
# 闭包和错误处理
闭包可以返回Result或Option类型, 并且可以处理错误.
fn find_first_positive(nums: &[i32], is_positive: impl Fn(i32) -> bool) -> Option<usize> {
nums.iter().position(|&x| is_positive(x))
}
2
3
# 闭包和多线程
闭包可以用于多线程编程, 因为它们可以捕获并持有必要的数据.
use std::thread;
let nums = vec![1, 2, 3, 4, 5];
let handles = nums.into_iter().map(|num| {
thread::spawn(move || {
num * 2
})
}).collect::<Vec<_>>();
for handle in handles {
let result = handle.join().unwrap();
println!("Result: {}", result);
}
2
3
4
5
6
7
8
9
10
11
12
13
# 闭包和性能
Rust的闭包是轻量级的, 并且Rust的编译器会进行优化, 使得闭包的调用接近于直接调用函数.
# 闭包和生命周期
闭包的生命周期与它们所捕获的变量的生命周期相关. Rust的生命周期系统确保闭包不会比它们捕获的任何变量活的更长.
# 闭包的类型
闭包在Rust中是一中特殊的类型, 称为Fn, FnMut或FnOnce, 它们分别表示不同的闭包特性:
Fn: 闭包不可变地借用其环境中的变量.FnMut: 闭包可变地借用其环境中的变量.FnOnce: 闭包获取其环境中的变量的所有权, 只能被调用一次.
# 实例
下面实例定义了一个闭包, 用于给特定数字进行平方运算, 并演示了闭包的使用方法.
// 定义一个函数, 接受一个闭包作为参数, 将闭包应用到给定的数字上
fn apply_operation<F>(num: i32, operation: F) -> i32
where
F: Fn(i32) -> i32,
{
operation(num)
}
// 主函数
fn main() {
// 定义一个数字
let num = 5;
// 定义一个闭包, 用于对数字进行平方运算
let square = |x| x * x;
// 调用函数, 并传入闭包作为参数, 对数字进行平方运算
let result = apply_operation(num, square);
// 输出结果
println!("Square of {} is {}", num, result); // 输出: Square of 5 is 25
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
以上代码中, 我们首先定义了一个函数apply_operation, 该函数接受一个闭包作为参数, 并将闭包应用到给定的数字上. 然后在main函数中定义了一个数字num和一个闭包square, 用于对数字进行平方运算. 最后调用了apply_operation函数, 并传入了数字和闭包作为参数, 得到了运算结果并输出.
# 总结
Rust的闭包是一种强大的抽象, 它们提供了一种灵活且表达力强的方式来编写函数. 闭包可以捕获环境变量, 并且可以作为参数传递或作为返回值. 闭包与迭代器结合使用, 可以方便地实现复杂的数据处理任务. Rust的闭包设计考虑了安全性, 性能和生命周期, 是Rust语言的重要组成部分.
# Rust 所有权
# Rust 所有权简介
计算机程序必须在运行时管理它们所使用的内存资源. 大多数的编程语言都有管理内存的功能: C/C++这样的语言主要通过手动方式管理内存, 开发者需要手动的申请和释放内存资源. 但为了提高开发效率, 只要不影响程序功能的实现, 许多开发者没有及时释放内存的习惯. 所以手动管理内存的方式常常造成资源浪费. Java语言编写的程序在虚拟机(JVM)中运行, JVM具备自动回收内存资源的功能. 但这种方式常常会降低运行时效率, 所以JVM会尽可能少的回收资源, 这样也会使程序占用较大的内存资源.
所有权对大多数开发者而言是一个新的概念, 它是Rust语言为高效使用内存而设计的语法机制. 所有权概念是为了让Rust在编译阶段更有效地分析内存资源的有用性以实现内存管理而诞生的概念.
# 所有权规则
所有权有以下三条规则:
- Rust中的每个值都有一个变量, 称为其所有者.
- 一次只能有一个所有者.
- 当所有者不在程序运行范围时, 该值将被删除.
这三条规则是所有权概念的基础.
# 变量范围
用下面这段程序描述变量范围的概念:
{
// 在声明以前, 变量 s 无效
let s = "runoob";
// 这里是变量 s 的可用范围
}
// 变量范围已经结束, 变量 s 无效
2
3
4
5
6
变量范围是变量的一个属性, 其代表变量的可行域, 默认从声明变量开始有效直到变量所在域结束.
# Rust 内存和分配
如果我们定义了一个变量并给它赋予一个值, 这个变量的值存在于内存中. 这种情况很普遍, 但如果我们需要储存的数据长度不确定(比如用户输入的一串字符串), 我们就无法再定义时期明确数据长度, 也就无法在编译阶段令程序分配固定长度的内存空间供数据储存使用. (有人说分配尽可能大的空间可以解决问题, 但这个方法很不文明). 这就需要提供一种在程序运行时程序自己申请使用内存的机制--堆. 本章所讲的所有"内存资源"都指的是堆所占用的内存空间.
有分配就有释放, 程序不能一直占用某个内存资源. 因此决定资源是否浪费的关键因素就是资源有没有及时的释放. 把字符串样例程序用C语言等价编写:
{
char *s = strdup("runoob");
free(s); // 释放 s 的资源
}
2
3
4
很显然, Rust中没有调用free函数来释放字符串s的资源(当然这样在C语言中是不正确的写法, 因为"runoob"不在堆中, 这里假设它在). Rust之所以没有明示释放的步骤是因为在变量范围结束的时候, Rust编译器自动添加了调用释放资源函数的步骤. 这种机制看似简单: 它不过是帮助程序员在适当的地方添加了一个释放资源的函数调用而已. 但这种简单的机制可以有效地解决一个史上最令程序员头疼的编程问题.
# Rust 变量与数据交互的方式
变量与数据交互方式主要有移动(Move)和克隆(Clone)两种:
# 移动
多个变量可以在Rust中以不同的方式与相同的数据交互:
let x = 5;
let y = x;
2
这个程序将值 5 绑定到变量 x, 然后将 x 的值复制并赋值给变量 y. 现在栈中将有两个值 5. 此情况中的数据是"基本数据"类型的数据, 不需要存储到堆中, 仅在栈中的数据的"移动"方式是直接复制, 这不会花费更长的时间或更多的存储空间. "基本类型"有这些:
- 所有整数类型, 例如 i32, u32, i64等.
- 布尔类型 bool, 值为 true 或 false.
- 所有浮点类型, f32 和 f64.
- 字符类型 char.
- 仅包含以上类型数据的元组 (Tuples).
但如果发生交互的数据在堆中就是另外一种情况:
let s1 = String::from("hello");
let s2 = s1;
2
第一步产生一个String对象, 值为"hello". 其中"hello"可以认为是类似于长度不确定的数据, 需要在堆中存储.
第二部的情况略有不同(这不是完全真的, 仅用来对比参考).
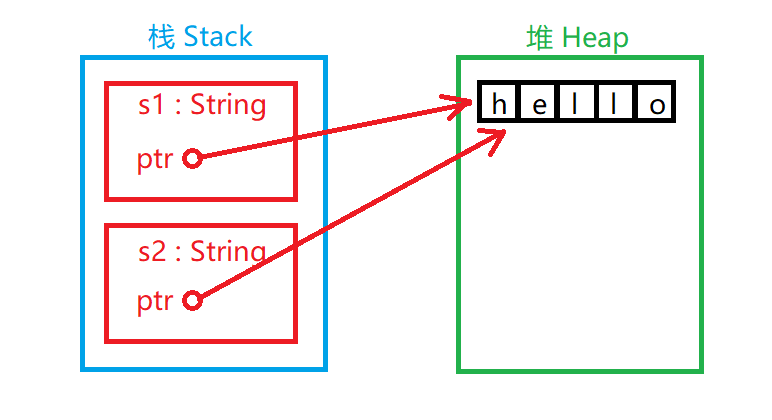
如图所示: 两个String对象在栈中, 每个String对象都有一个指针指向堆中的"hello"字符串. 在给s2赋值时, 只有栈中的数据被复制了, 堆中的字符串依然还是原来的字符串.
前面我们说过, 当变量超出范围时, Rust自动调用释放资源函数并清理该变量的堆内存. 但是 s1 和 s2 都被释放的话堆区中的 "hello" 被释放两次, 这是不被系统允许的. 为了确保安全, 在给s2赋值时s1已经无效了. 没错, 在把s1的值赋给s2以后s1将不可以再被使用. 下面这段程序是错的.
fn main() {
let s1 = String::from("hello");
let s2 = s1; // s1 的所有权被移动到 s2
println!("{}", s1); // 这里会报错,因为 s1 不再有效
}
2
3
4
5
所以实际情况是:
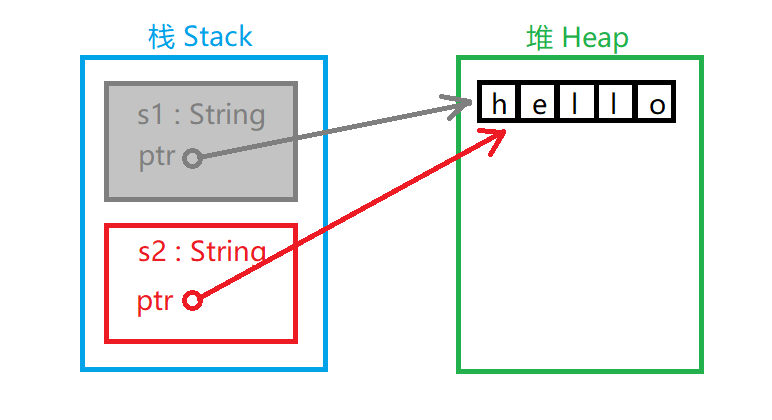
s1 名存实亡.
# 克隆
Rust会尽可能低降低程序的运行成本, 所以默认情况下, 长度较大的数据存放在堆中, 且采用移动的方式进行数据交互. 但如果需要将数据单纯的复制一份以供他用, 可以使用数据的第二种交互方式--克隆.
fn main() {
let s1 = String::from("hello");
let s2 = s1.clone();
println!("s1 = {}, s2 = {}", s1, s2); // 这里不会报错,因为我们使用了 clone(),s1 仍然有效
}
2
3
4
5
这里是真的将堆中的"hello"复制了一份, 所以s1和s2都分别绑定了一个值, 释放的时候也会被当作两个资源. 当然, 克隆仅在需要复制的情况下使用, 毕竟复制数据会花费更多的时间.
# 涉及函数的所有权机制
对于变量来说这是最复杂的情况了. 如果将一个变量当作函数的参数传递给其他函数, 怎样安全的处理所有权呢? 下面这段程序描述了这种情况下所有权机制的运行原理:
fn main() {
let s = String::from("hello");
// s 被声明有效
takes_ownership(s);
// s 的值被当作参数传入函数
// 所以可以当作 s 已经被移动, 从这里开始已经无效
let x = 5;
// x 被声明有效
makes_copy(x);
// x 的值被当作参数传入函数
// 但因为 i32 实现了 Copy trait,所以 x 仍然有效
// 在这里依然可以使用 x 却不能使用 s
} // 函数介绍, x 无效, 然后是 s. 但 s 已经被移动, 所以不用被释放
fn takes_ownership(some_string: String) {
// 一个 String 参数 some_string 传入, 有效
println!("{}", some_string);
} // 函数结束, 参数 some_string 在这里释放
fn makes_copy(some_integer: i32) {
// 一个 i32 参数 some_integer 传入, 有效
println!("{}", some_integer);
} // 函数结束, 参数 some_integer 在这里释放
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
如果将变量当作参数传入函数, 那么它和移动的效果是一样的.
# 函数返回值的所有权机制
fn main() {
let s1 = gives_ownership();
// give_ownership 移动它的返回值到 s1
let s2 = String::from("hello");
// s2 被声明有效
let s3 = takes_and_gives_back(s2);
// s2 被当作参数移动, s3 获得返回值所有权
} // s3 无效被释放, s2 被移动, s1 无效被释放
fn gives_ownership() -> String {
let some_string = String::from("hello");
// some_string 被声明有效
return some_string;
// some_string 被当作返回值移动出函数
}
fn takes_and_gives_back(a_string: String) -> String {
// a_string 被声明有效
return a_string;
// a_string 被当作返回值移动出函数
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
被当作函数返回值的变量所有权将会被移动出函数并返回到调用函数的地方, 而不会直接被无效释放.
# 引用与租借
引用(Reference)时C++开发者较为熟悉的概念. 如果你熟悉指针的概念, 可以把它看作一种指针. 实质上"引用"是变量的间接访问方式.
fn main() {
let s1 = String::from("hello");
let s2 = &s1;
println!("s1 is {}, s2 is {}", s1, s2);
}
2
3
4
5
&运算符可以取变量的"引用". 当一个变量的值被引用时, 变量本身不会被认定无效. 因为"引用"并没有在栈中复制变量的值:
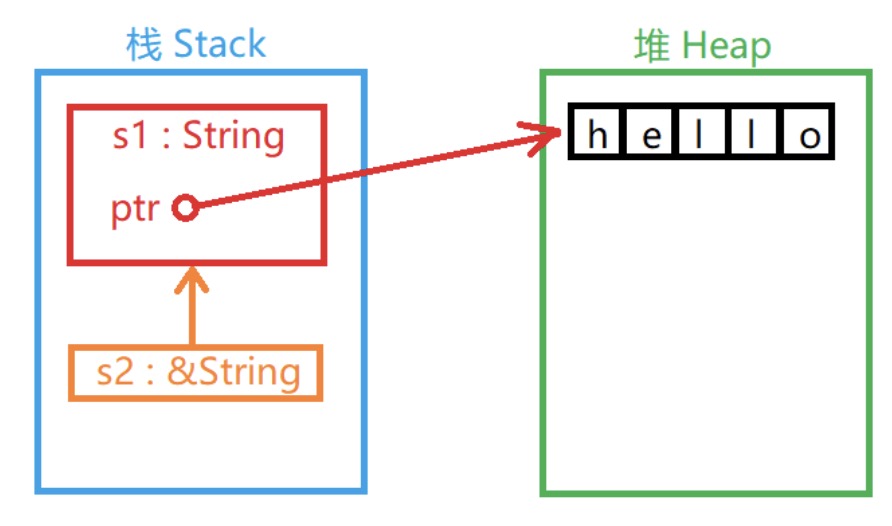
函数参数传递的道理一样:
fn main() {
let s1 = String::from("hello");
let len = calculate_length(&s1);
println!("The length of '{}' is {}.", s1, len);
}
fn calculate_length(s: &String) -> usize {
s.len()
}
2
3
4
5
6
7
8
9
10
11
引用不会获得值的所有权. 引用只能租借(Borrow)值的所有权. 引用本身也是一个类型并具有一个值, 这个值记录的是别的值所在的位置, 但引用不具有所指值的所有权:
fn main() {
let s1 = String::from("hello");
let s2 = &s1;
let s3 = s1;
println!("{}", s2);
}
2
3
4
5
6
这段程序不正确: 因为s2租借的s1已经将所有权移动到s3, 所以s2将无法继续租借使用s1的所有权. 如果需要使用s2使用该值, 必须重新租借:
fn main() {
let s1 = String::from("hello");
let mut s2 = &s1;
let s3 = s1;
s2 = &s3; // 重新从 s3 租借所有权
println!("{}", s2);
}
2
3
4
5
6
7
这段程序是正确的. 既然引用不具有所有权, 即使它租借了所有权, 它也只享有使用权(这跟租房子是一个道理). 如果尝试利用租借来的权利来修改数据会被阻止.
fn main() {
let s1 = String::from("run");
let s2 = &s1;
println!("{}", s2);
s2.push_str("oob"); // 错误, 禁止修改租借的值
println!("{}", s2);
}
2
3
4
5
6
7
这段程序中s2尝试修改s1的值被阻止, 租借的所有权不能修改所有者的值. 当然, 也存在一种可变的租借方式, 就像你租一个房子, 如果物业规定房主可以修改房子结构, 房主在租借时也在合同中声明赋予你这种权利, 也是可以重新装修房子的.
fn main() {
let mut s1 = String::from("hello");
// s1 是可变的
let s2 = &mut s1;
// s2 是可变的引用
s2.push_str("oob");
println!("{}", s2);
}
2
3
4
5
6
7
8
9
10
这段程序就没有问题了, 我们用&mut修饰可变的引用类型. 可变引用与不可变引用先比除了权限不同以外, 可变引用不允许多重引用, 但不可变引用可以:
let mut s = String::from("hello");
let r1 = &mut s;
let r2 = &mut s;
println!("{}, {}", r1, r2);
2
3
4
5
6
这段程序不正确, 因为多重可变引用了 s. Rust对可变引用的这种设计主要出于对并发状态下发生数据访问碰撞的考虑, 在编译阶段就避免了这种事情的发生. 由于发生数据访问碰撞的必要条件之一是数据被至少一个使用者写且同时被至少一个其他使用者读或写, 所以在一个值被可变引用时不允许再次被任何引用.
垂悬引用(Dangling References): 这是一个换了个名字的概念, 如果放在有指针概念的编程语言里它就指的是那种没有实际指向一个真正能访问的数据的指针(注意, 不一定是空指针, 还有可能是已经释放的资源). 它们就像失去悬挂物体的绳子, 所以叫"垂悬引用". "垂悬引用"在Rust语言里不允许出现, 如果有, 编译器就会发现它.
fn main() {
let referenc_to_nothing = dangle();
}
fn dangle() -> &String {
let s = String::from("hello");
&s
}
2
3
4
5
6
7
8
9
很显然, 伴随着 dangle 函数的结束, 其局部变量的值本身没有被当作返回值, 被释放了. 但它的引用却被返回, 这个引用所指向的值已经不能确定的存在, 故不允许其出现.
# Rust Slice (切片)类型
切片(Slice)是对数据值的部分引用. 切片这个名字往往出现在生物课上, 我们做样本切片的时候要从生物体上获取切片, 以供在显微镜上观察. 在Rust中, 切片的意思大致也是这样, 只不过它从数据取材引用.
# 字符串切片
最简单, 最常用的数据切片类型是字符串切片(String Slice).
fn main() {
let s = String::from("broadcast");
let part1 = &s[0..5];
let part2: &str = &s[5..9];
println!("part1 = {}, part2 = {}", part1, part2); // part1 = broad, part2 = cast
}
2
3
4
5
6
7
8
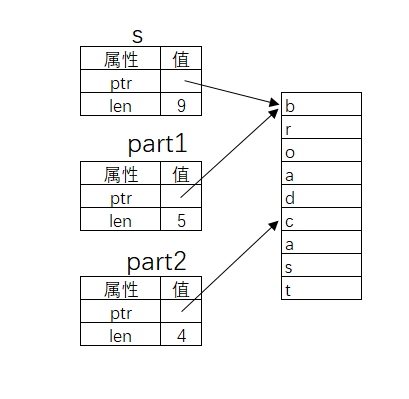
上图解释了字符串切片的原理(注: Rust中的字符串类型实质上记录了字符在内存中的起始位置和其长度, 我们暂时了解这一点). 使用..表示范围的语法在循环章节中出现过. x..y表示[x, y)的数学含义. ..两遍可以没有运算数:
..y // 等价于 0..y
x.. // 等价于 x 到数据结束
.. // 等价于位置 0 到 结束
2
3
注意: 到目前为止, 尽量不要在字符串中使用非英文字符, 因为编码问题. 具体原因会在"字符串"章节叙述. 被切片引用的字符串禁止更改其值:
fn main() {
let mut s = String::from("runoob");
let slice = &s[0..3];
s.push_str("yes!"); // 错误
println!("{}", slice);
}
2
3
4
5
6
这段程序不正确, s 被部分引用, 禁止更改其值. 实际上, 到目前为止你一定疑惑为什么每一次使用字符串都要这样写String::from("runoob"), 直接写"runoob"不行吗? 事已至此我们必须分辨这两者概念的区别了, 在Rust中有两种常用的字符串类型: str 和 String. str 是Rust核心语言类型, 就是本章一直在讲的字符串切片(String Slice), 常常以引用的形式出现(&str). 凡是用双引号包括的字符串常量整体的类型性质都是**&str**:
let s == "hello";
这里的 s 就是一个 &str 类型的变量. String 类型是Rust标准公共库提供的一种数据类型, 它的功能更完善--它支持字符串的追加, 清空等实用的操作. String 和 str 除了拥有一个字符开始位置属性和一个字符串长度属性以外还有一个容量 (capacity) 的属性.
String 和 str 都支持切片, 切片的结果是 &str 类型的数据.
注意: 切片结果必须是引用类型, 但开发者必须自己明示这一点: let slice = &s[0..3];
有一个快速的办法可以将String转换成&str:
let s1 = String::from("hello");
let s2 = &s1[..];
let s3 = &s1;
2
3
这三行代码展示了Rust中String(堆分配字符串)与&str(字符串切片/引用)之间的关系和转换方式.
以下是逐行详细解释:
let s1 = String::from("hello");- 类型: String
- 含义:
- 这行代码在**堆(Heap)**上分配了一块内存来存储"hello".
s1是一个拥有所有权的变量. 它存储在栈上, 包含指向堆内存的指针, 长度(len)和容量(capacity).s1对这块数据拥有生杀大权(负责释放内存).
let s2 = &s1[..];- 类型:
&str(字符串切片) - 含义:
[..]是全范围切片语法, 表示从开头到结尾.&表示借用(引用).s2是一个切片(Slice). 它是一个"胖指针**(Fat Pointer), 存储在栈上, 包含两个信息:- 指向
s1堆内存数据的起始指针. - 数据的长度(这里是 5).
- 指向
s2不拥有数据, 它只是s1数据的一个"视图"或"借用".
- 类型:
let s3 = &s1;- 类型:
&String(但在使用时通常被视为&str) - 含义:
- 这行代码创建了一个指向变量
s1的普通引用. - 关键点(Deref Coercion/解引用强制转换): 虽然
s3的字面类型是&String, 但Rust编译器非常智能, 因为String类型实现了Deref trait(能够解引用为str), 所以在绝大多数需要&str的地方(比如传参给函数), Rust会自动把&String转换为&str. - 因此, 在实际使用中,
s3和s2的效果几乎是一样的, 都是对字符串内容的引用.
- 这行代码创建了一个指向变量
- 类型:
# 非字符串切片
除了字符串以外, 其他一些线性数据结构也支持切片操作, 例如数组:
fn main() {
let arr = [1, 3, 5, 7, 9];
let part = &arr[0..3];
for i in part.iter() {
println!("{}", i);
}
}
2
3
4
5
6
7
# Rust 结构体
# 结构体简介
Rust中的结构体(Struct)与元组(Tuple)都可以将若干个类型不一定相同的数据捆绑在一起形成整体, 但结构体的每个成员和其本身都有一个名字, 这样访问它成员的时候就不用记住下标了. 元组常用于非定义的多值传递, 而结构体用于规范常用的数据结构. 结构体的每个成员叫做"字段".
# 结构体定义
这是一个结构体定义:
struct Site {
domain: String,
name: String,
nation: String,
found: u32
}
2
3
4
5
6
注意: 如果你常用C/C++, 请记住在Rust里struct语句仅用来定义, 不能声明实例, 结尾不需要;符号, 而且每个字段定义之后用,分隔.
# 结构体实例
Rust很多地方受JavaScript影响, 在实例化结构体的时候用JSON对象的key: value语法来实现定义:
let runoob = Site {
domain: String::from("www.runoob.com"),
name: String::from("RUNOOB"),
nation: String::from("China"),
found: 2013
};
2
3
4
5
6
这样的好处是不仅使程序更加直观, 还不需要按照定义的顺序来输入成员的值. 如果正在实例化的结构体有字段名和现存变量名称一样的, 可以简化书写:
let domain = String::from("www.runoob.com");
let name = String::from("RUNOOB");
let runoob = Site {
domain, // 等同于 domain: domain,
name, // 等同于 name: name,
nation: String::from("China"),
found: 2013
};
2
3
4
5
6
7
8
有这样一种情况: 你想要新建一个结构体实例, 其中大部分属性需要被设置成与现存的一个结构体属性一样, 仅需要改其中的一两个字段的值, 可以使用结构体更新语法:
let site = Site {
domain: String::from("www.runoob.com"),
name: String::from("RUNOOB"),
..runoob
};
2
3
4
5
注意: ..runoob后面不可以有逗号, 这种语法不允许一成不变的复制另一个结构体实例, 意思就是说至少重新设定一个字段的值才能引用其他实例的值.
这段话主要讲解了Rust中结构体更新语法(Struct Update Syntax)的两个关键细节: 语法格式限制和使用场景限制.
我们可以将其拆解为以下几点来理解:
- 什么是
..runoob?
这是一种语法糖(Syntactic Sugar). 它的意思是: "对于我没有显式设置的字段, 直接使用runoob实例中对应字段的值".
在上面的例子中:
domain和name: 使用了你提供的值.nation和found: 你没有写, 所以Rust会自动去runoob实例里把这两个字段的值拿过来.
- 为什么"后面不可以有逗号"?
在Rust的结构体初始化中, 通常字段之前是用逗号分隔的(例如name: ..., domain: ...,). 但是, ..runoob必须是结构体初始化块中的最后一部分, 它代表了"剩余的所有字段". 既然已经是"剩余的所有"了, 后面自然不能再有其他字段, 因此Rust语法规定它后面不能加逗号.
// 错误写法
let site = Site {
..runoob, // 报错: 这里不能有逗号
};
// 正确写法
let site = Site {
domain: String::from("..."),
..runoob // 正确, 没有逗号, 且在最后
};
2
3
4
5
6
7
8
9
10
- 为什么说"不允许一成不变的复制"?
文档中提到: "这种语法不允许一成不变的复制另一个结构体实例, 意思就是说至少重新设定一个字段的值才能引用其他实例的值."
这句话其实是在强调这个语法的用途, 但在技术细节上稍微有点绝对(在旧版本Rust或某些上下文中是为了避免歧义).
- 逻辑上的原因: 如果想完全复制
runoob的所有字段而不做任何修改, 应该直接使用let site = runoob.clone();(如果实现了Clone)或者let site = runoob;(所有权移动). 使用Site { ..runoob }这种写法虽然在某些情况下也能编译通过, 但它通常被视为一种反模式(Antipattern), 或者在某些严格的语法检查中被认为是不必要的复杂化. - 语法的目的: 这个语法的核心目的是 "更新(Update)", 即基于旧实例创建有变化的新实例, 如果没有变化, 就不是"更新"了.
- 极其重要的隐藏细节: 所有权转移(Move): 这段教程没有详细展开, 但这是新手最容易踩的坑: 结构体更新语法会发生所有权转移!
如果结构体中的字段是堆上分配的数据(比如String), 使用..runoob会把这些字段的所有权**移动(Move)**到新实例中. 后果: 旧的实例runoob可能会失效!
struct Site {
domain: String,
name: String,
nation: String, // String 类型, 没有实现 Copy trait
found: u32 // u32 类型, 实现了 Copy trait
}
fn main() {
let runoob = Site {
domain: String::from("runoob.com"),
name: String::from("runoob"),
nation: String::from("China"),
found: 2004
};
let site = Site {
domain: String::from("cainiao.com"), // 新值
name: String::from("菜鸟教程"), // 新值
..runoob // 这里会发生所有权转移 注意这里!
};
// 此时发生了什么?
// 1. runoob.nation 的所有权被移动到了 site.nation
// 2. runoob.found 的值被复制到了 site.found
println!("{}", runoob.found); // 2004, 可以访问, 因为是 Copy 类型
// println!("{}", runoob.nation); // 错误, nation 的所有权已经被移动
println!("{}", runoob.domain); // 正确, 输出runoob.com
// println!("{:?}", runoob); // 错误, 因为 runoob 的部分字段已经被移动
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
Rust编译器非常聪明, 它知道runoob这个结构体虽然作为一个整体"残废"了(因为nation被拿走了), 但它里面剩下的零件(domain和name)依然完好无损且还在原地. 只要你不尝试访问那个已经被拿走的字段(nation), 或者不尝试把runoob当作一个整体去使用, 编译器是允许访问剩下的字段的.
# 元组结构体
有一种更简单的定义和使用结构体的方式: 元组结构体. 元组结构体是一种形式是元组的结构体. 与元组的区别是它有名字和固定的类型格式. 它存在的意义是为了处理那些需要定义类型(经常使用)又不想太复杂的简单数据:
struct Color(u8, u8, u8);
struct Point(f64, f64);
let black = Color(0, 0, 0);
let origin = Point(0.0, 0.0);
2
3
4
5
"颜色"和"点坐标"是常用的两种数据类型, 但如果实例化时写个大括号再协商两个名字就为了可读性牺牲了便捷性, Rust不会遗留这个问题. 元组结构体对象的使用方式和元组一样, 通过.和下标来进行访问:
struct Color(u8, u8, u8);
struct Point(f64, f64);
fn main() {
let black = Color(0, 0, 0);
let origin = Point(0.0, 0.0);
println!("Black color RGB: ({}, {}, {})", black.0, black.1, black.2);
println!("Origin point coordinates: ({}, {})", origin.0, origin.1);
}
2
3
4
5
6
7
8
9
# 结构体所有权
结构体必须掌握字段值所有权, 因为结构体失效的时候会释放所有字段. 这就是为什么本章的案例中使用了String类型而不使用&str的原因. 但这不意味着结构体中不定义引用型字段, 这需要通过"生命周期"机制来实现. 但现在还难以说明"生命周期"概念, 只能在后面章节说明.
# 输出结构体
调试中, 完整地显示出一个结构体实例是非常有用的, 但如果手动的书写一个格式会非常的不方便. 所以Rust提供了一个方便地输出一整个结构体的方法:
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
fn main() {
let rect1 = Rectangle {
width: 30,
height: 50,
};
// println!("The area of the rectangle is {} square pixels.", rect1.width * rect1.height);
println!("rect1 is {:?}", rect1); // 普通输出
// rect1 is Rectangle { width: 30, height: 50 }
println!("rect1 is {:#?}", rect1); // 美化输出
// rect1 is Rectangle {
// width: 30,
// height: 50
// }
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# 结构体方法
方法(Method)和函数(Function)类似, 只不过它是用来操作结构体实例的. 如果你学习过一些面相对象的语言, 那你一定很清楚函数一般放在类定义里并在函数中用this表示所操作的实例. Rust语言不是面向对象的, 从它所有权机制的创新可以看出这一点. 但是面向对象的珍贵思想可以在Rust实现. 结构体方法的第一个参数必须是&self, 不需要声明类型, 因为self不是一种风格而是关键字.
计算一个矩形的面积, 以及多参数的例子:
struct Rectangle {
width: u32,
height: u32,
}
impl Rectangle {
fn area(&self) -> u32 {
self.width * self.height
}
fn wider(&self, other: &Rectangle) -> bool {
self.width > other.width
}
}
fn main() {
let rect1 = Rectangle {
width: 30,
height: 50,
};
let rect2 = Rectangle {
width: 40,
height: 60,
};
println!("The area of the rectangle is {} square pixels.", rect1.area()); // 使用 area 方法
println!("rect1 is wider than rect2: {}", rect1.wider(&rect2));
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
# 结构体关联函数
之所以"结构体方法"不叫"结构体函数"是因为"函数"这个名字留给了这种函数: 它在impl块中却没有&self参数. 这种函数不依赖实例, 但是使用它需要声明是在哪个impl块中. 一直使用的String::from函数就是一个"关联函数".
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
impl Rectangle {
fn create(width: u32, height: u32) -> Rectangle {
Rectangle { width, height }
}
}
fn main() {
let rect = Rectangle::create(30, 50);
println!("The rectangle is {:?}", rect);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
贴士: 结构体impl块可以写几次, 效果相当于它们内容的拼接!
# 单元结构体
结构体可以只作为一种象征而无需任何成员:
struct UnitStruct;
我们称这种没有身体的结构体为单元结构体(Unit Struct).
虽然单元结构体(Unit Struct)看起来空空如也(没有任何字段), 但在Rust的类型系统和设计模式中, 它非常有用. 简单来说, 当你需要一个类型来"占位"或者"实现行为", 但不需要它存储任何数据时, 就会用到单元结构体. 以下是它的几个主要用途:
- 实现
Trait(只有行为, 没有数据)
这是最常见的用法, 有时候你需要定义一个对象, 它不需要保存状态(不如不需要存名字, 年龄, 长度), 它只需要提供方法(行为). 例如, 你想定义一个"打印日志"的工具, 或者一个"计算器":
// 定义一个单元结构体
struct ConsoleLogger;
// 定义一个特征(接口)
trait Log {
fn log(&self, message: &str);
}
// 为单元结构体实现特征
impl Log for ConsoleLogger {
fn log(&self, message: &str) {
println!("[Log]: {}", message);
}
}
fn main() {
let logger = ConsoleLogger;
logger.log("系统启动中...");
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
为什么有用? 因为Rust的Trait必须依附于某个具体的类型来实现. 单元结构体提供了一个最轻量级的类型载体.
- 标记类型(Marker Types)
用于在编译时通过类型系统来控制逻辑, 而不需要在运行时检查. 这常用于状态机模式. 比如, 你有一个"火箭发射"的程序, 你想确保火箭只有在"准备好"的状态下才能发射.
// 定义两个单元结构体, 代表两种状态
struct Grounded;
struct Launched;
// 火箭结构体, 带有一个泛型参数 State
struct Rocket<State> {
state: std::marker::PhantomData<State>, // 幽灵数据, 只为了持有类型
}
impl Rocket<Grounded> {
// 创建一个处于 Grounded 状态的火箭
fn new() -> Self {
Rocket {
state: std::marker::PhantomData,
}
}
// 只有在 Grounded 状态下才能发射火箭, 并转换为 Launched 状态
fn launch(self) -> Rocket<Launched> {
println!("Rocket launched!");
Rocket {
state: std::marker::PhantomData,
}
}
}
impl Rocket<Launched> {
fn accelerate(&self) {
println!("加速中...");
}
}
fn main() {
let r = Rocket::new();
let r2 = r.launch();
r2.accelerate();
// r.accelerate(); // 这一行会报错, 因为 r 是 Grounded 状态, 没有 accelerate 方法
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
为什么有用? Grounded和Launched不需要占用任何内存, 它们存在的唯一意义就是告诉编译器当前处于什么状态, 从而在编译阶段就杜绝了"在地面上加速"这种逻辑错误.
- 作为集合中的占位符
有时候你使用HashMap<K, V>, 但你之关系Key, 不关心Value (即你想实现一个HashSet). 虽然Rust标准库有HashSet, 但在某些特定场景下, 你可能会用单元结构体作为Value. 因为单元结构体是零大小类型(Zero Sized Type, ZST), 它在内存中不占用任何空间.
use std::mem;
struct Empty;
fn main() {
// 打印结构体占用的大小
println!("Size of Empty: {}", mem::size_of::<Empty>()); // 输出: 0
}
2
3
4
5
6
7
8
这意味着如果你创建了一个包含1000个单元结构体的数组, 这个数组占用的内存大小也是0.
- 占位符与兼容性
有时候你使用的某个库或者API需要你传入一个实现了特定Trait的类型, 但你在这个场景下什么都不想做(Mock对象), 你可以传入一个单元结构体.
单元结构体就像是只有名, 没有实体的公司:
- 省内存: 不占空间
- 载体: 为了挂载函数(impl trait)
- 标签: 为了给编译器看(标记状态)
# Rust 枚举类
枚举类在Rust中并不像其他编程语言中的概念那样简单, 但依然可以十分简单的使用:
#[derive(Debug)]
enum Book {
Papery, Electronic
}
fn main() {
let book = Book::Papery;
println!("{:?}", book); // Output: Papery
}
2
3
4
5
6
7
8
9
10
书分为纸质书(Papery book)和电子书(Electronic book). 如果你现在正在开发一个图书管理系统, 你需要描述两种书的不同属性(纸质书有索引号, 电子书只有URL), 你可以为枚举类成员添加元组属性描述:
#[derive(Debug)]
// enum Book {
// Papery(u32),
// Electronic(String),
// }
// fn main() {
// let book = Book::Papery(1001);
// let ebook = Book::Electronic(String::from("url://..."));
// println!("{:?}", book); // Output: Papery(1001
// println!("{:?}", ebook); // Output: Electronic("url://...")
// }
// 如果你想为属性命名, 可以用结构体语法:
enum Book {
Papery { index: u32 },
Electronic { url: String },
}
fn main() {
let book = Book::Papery { index: 1001 };
let ebook = Book::Electronic { url: String::from("url://...") };
println!("{:?}", book); // Output: Papery { index: 1001 }
println!("{:?}", ebook); // Output: Electronic { url: "url://..." }
}
// 虽然可以如此命名, 但请注意, 并不能像访问结构体字段一样访问枚举类型绑定的属性. 访问的方法在 match 语法中
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
match 语法:
枚举的目的是对某一类事物的分类, 分类的目的是为了对不同的情况进行描述, 基于这个原理, 往往枚举类最终会被分支结构处理(许多语言中的switch). switch语法很经典, 但在Rust中并不支持, 很多语言摒弃switch的原因都是因为switch容易存在因忘记添加break而产生的串接运行问题, Java和C#这类语言通过安全检查杜绝这种情况出现.
Rust通过match语句来实现分支结构. 先认识一下如何使用match处理枚举类:
fn main() {
enum Book {
Papery { index: u32 },
Electronic { url: String },
}
let book = Book::Papery { index: 1001 };
let ebook = Book::Electronic { url: String::from("url://...") };
match book {
Book::Papery { index } => {
println!("Papery book with index: {}", index);
},
Book::Electronic { url } => {
println!("Electronic book with URL: {}", url);
},
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
match块也可以当做函数表达式来对待, 它也是可以有返回值的:
match 枚举类实例 {
分类1 => 返回值表达式,
分类2 => 返回值表达式,
...
}
2
3
4
5
在Rust中, match不仅仅是控制流语句, 它是一个表达式. 这意味着它可以计算出一个值, 并且你可以将这个值赋值给变量, 或者作为函数的返回值.
- 将match的结果赋值给变量
fn main() {
let condition = true;
// match 表达式的返回值赋给 number
let number = match condition {
true => 1,
false => 0,
};
println!("Number is: {}", number); // 输出: Number is: 1
}
2
3
4
5
6
7
8
9
10
11
- 结合枚举类使用
enum Book {
Papery { index: u32 },
Electronic { url: String },
}
fn main() {
let book = Book::Papery { index: 1001 };
// 两个分支都必须返回 String 类型
let description = match book {
Book::Papery { index } => {
format!("纸质书索引: {}", index)
},
Book::Electronic { url } => {
format!("电子书链接: {}", url)
},
};
println!("{}", description);
// 输出: 纸质书索引: 1001
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
- 作为函数的返回值: 由于Rust函数中最后一个表达式会自动作为返回值,
match经常直接放在函数末尾.
enum Coin {
Penny,
Nickel,
Dime,
}
fn value_in_cents(coin: Coin) -> u8 {
// match 表达式作为整个函数的返回值
match coin {
Coin::Penny => 1,
Coin::Nickel => 5,
Coin::Dime => 10,
}
}
fn main() {
let c = Coin::Nickel;
println!("Value: {}", value_in_cents(c)); // 输出: Value: 5
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
但是所有返回值表达式的类型必须一样! 如果吧枚举类附加属性定义成元组, 在match块中需要临时指定一个名字:
enum Book {
Papery(u32),
Electronic {url: String},
}
let book = Book::Papery(1001);
match book {
Book::Papery(i) => {
println!("{}", i);
},
Book::Electronic { url } => {
println!("{}", url);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
注意: match的所有分支(arm)返回的数据类型必须完全相同. 如果一个分支返回整数, 另一个分支返回字符串, 编译器会报错.
let condition = true;
let result = match condition {
true => 1, // 返回整数
false => "error", // ❌ 报错:返回字符串,let condition = true;
let result = match condition {
true => 1, // 返回整数
false => "error", // ❌ 报错:返回字符串,
2
3
4
5
6
7
8
9
# Option 枚举类
Option是Rust标准库中的枚举类, 这个类用于填补Rust不支持null引用的空白. 许多语言支持null的存在(C/C++, Java), 这样很方便, 但也制造了极大的问题, null的发明者也承认这一点, "一个方便的想法造成累积10亿美元的损失".
null经常在开发者把一切都当作不是null的时候给予程序致命一击: 毕竟只要出现一个这样的错误, 程序的运行就要彻底终止. 为了解决这个问题, 很多语言默认不允许null, 但在语言层面支持null的出现(常在类型前面用?符号修饰). Java默认支持null, 但可以通过@NotNull注解限制出现null, 这是一种应付的办法.
Rust在语言层面彻底不允许空值null的存在, 但无奈null可以高效地解决少量的问题, 所以Rust引入了Option枚举类:
enum Option<T> {
Some(T),
None,
}
2
3
4
如果你想定义一个可以为空值的类, 你可以这样: let opt = Option::Some("Hello");
如果你想针对opt执行某些操作, 你必须先判断它是否是Option::None:
fn main() {
let opt = Option::Some("Hello");
match opt {
Option::Some(something) => {
println!("{}", something);
},
Option::None => {
println!("opt is nothing");
}
}
}
2
3
4
5
6
7
8
9
10
11
如果你的变量刚开始时空值, 你体谅以下编译器, 它怎么知道值不为空的时候变量是什么类型的呢? 所以初始值为空的Option必须明确类型:
fn main() {
let opt: Option<&str> = Option::None;
match opt {
Option::Some(Something) => {
println!("{}", something);
},
Option::None => {
println!("opt is nothing");
}
}
}
2
3
4
5
6
7
8
9
10
11
这种设计会让空值编程变得不容易, 但这正是构建一个稳定高效的系统所需要的. 由于Option是Rust编译器默认引入的, 在使用时可以省略Option::直接写None或者Some().
Option是一种特殊的枚举类, 它可以含值分支选择:
fn main() {
let t = Some(64);
match t {
Some(64) => println!("yes"),
_ => println!("No"),
}
}
2
3
4
5
6
7
if let语法:
let i = 0;
match i {
0 => println!("zero"),
_ => {},
}
2
3
4
5
这段程序的目的是判断i是否是数字0, 如果是就打印zero. 现在用if let语法缩短这段代码:
let i = 0;
if let 0 = i {
println!("zero");
}
2
3
4
可以在之后添加一个else块来处理例外情况. if let语法可以认为是只区分两种情况的match语句的"语法糖"(语法糖指的是某种语法的原理相同的便捷替代品). 对于枚举类依然适用:
fn main() {
enum Book {
Papery(u32),
Electronic(String)
}
let book = Book::Electronic(String::from("url"));
if let Book::Papery(index) = book {
println!("Papery {}", index);
} else {
println!("Not papery book");
}
}
2
3
4
5
6
7
8
9
10
11
12
# Rust 组织管理
# Rust 组织管理简介
任何一门编程语言如果不能阻止代码都是难以深入的, 几乎没有一个软件是由一个源文件编译而成的. 本教程到目前为止所有的程序都是在一个文件中编写的, 主要是为了方便学习Rust语言的语法和概念. 对于一个工程来说, 组织代码是十分重要的.
Rust中有三个重要的组织概念: 箱, 包, 模块.
# 箱 (Crate)
"箱"是二进制程序文件或者库文件, 存在于"包"中. "箱"是树状结构的, 它的树根是编译器开始运行时编译的源文件所编译的程序.
注意: "二进制程序文件"不一定是"二进制可执行文件", 只能确定是包含目标机器语言的文件, 文件格式随编译环境的不同而不同.
# 包 (Package)
当我们使用Cargo执行new命令创建Rust工程时, 工程目录下会建立一个Cargo.toml文件, 工程的实质就是一个包, 包必须由一个Cargo.toml文件来管理, 该文件描述了包的基本信息以及依赖项.
一个包最多包含一个库"箱", 可以包含任意数量的二进制"箱", 但是至少包含一个"箱"(不管是库还是二进制"箱"). 当使用cargo new命令创建完包之后, src目录下会生成一个main.rs源文件, Cargo默认这个文件为二进制箱的根, 编译之后的二进制箱将与包名相同.
# 模块 (Module)
对于一个软件工程来说, 我们往往按照所使用的编程语言的组织规范来进行组织, 组织模块的主要结构往往是树. Java组织模块的主要单位是类, 而JavaScript组织模块的主要方式是function. 这些先进的语言的组织单位可以层层包含, 就像文件系统的目录结构一样. Rust中的组织单位是模块(Module). 在文件系统中, 目录结构往往以斜杠在路径字符串中表示对象的位置, Rust中的路径分隔符是::. 路径分为绝对路径和相对路径, 绝对路径从crate关键字开始描述, 相对路径从self或super关键字或一个标识符开始描述.
理解Rust的组织管理系统(Package, Crate, Module)是构建大型项目的关键, 这套系统初看有点复杂, 但如果用物流快递的类比来理解, 就会非常清晰.
我们可以把Rust的代码组织结构想象成一家物流公司:
- 包(Package) -- 快递包裹
- 地位: 最外层的物理容器, 项目的管理单元.
- 类比: 这是一个准备发货的大快递包裹.
- 核心标志: 必须包含一个
Cargo.toml文件, 这个文件就是"快递单", 上面写了包裹里有什么, 寄给谁(依赖项), 版本号等信息. - 规则:
- 一个Package可以包含多个二进制箱(Binary Crates, 即可以运行的工具)
- 一个Package最多只能包含一个库箱(Library Crate, 即提供给别人用的代码库).
- 这就是为什么当运行
cargo new my_project时, 它创建的是一个Package.
- 地位: 最外层的物理容器, 项目的管理单元.
- 箱(Crate) -- 产品/货物
- 类比: 这是包裹里装的具体产品.
- 二进制箱(Binary Crate): 就像是一个机器(比如一台榨汁机), 插上电(编译运行)就能动. 它的入口是
src/main.rs. - 库箱(Library Crate): 就像是一盒通用零件(螺丝, 齿轮), 它自己不能动, 是给别的机器组装用的. 它的入口是
src/lib.rs.
- 二进制箱(Binary Crate): 就像是一个机器(比如一台榨汁机), 插上电(编译运行)就能动. 它的入口是
- 树状结构: 每个Crate内部都有一个模块树,
main.rs或lib.rs是这棵树的根(Crate Root). - 关键点: 当你引用外部依赖(比如
rand)时, 你引用的是一个Crate.
- 类比: 这是包裹里装的具体产品.
- 模块(Module) -- 抽屉/收纳格
- 地位: 代码的逻辑分组, 控制可见性(私有/共有)
- 类比: 这是机器内部的收纳格或抽屉, 为了不让零件乱堆在一起, 你需要把相关的代码整理归类. 比如: 把处理"网络"的代码放在一个抽屉, 把处理"文件"的代码放在一个抽屉.
- 功能:
- 组织代码: 将复杂的代码拆分成易于管理的小块.
- 控制权限: 默认情况下, 抽屉里的东西是私有的(Private), 外面拿不到. 如果你想让别人用, 必须贴上
pub标签(Public).
- 实现: 可以通过
mod关键字定义, 既可以在同一个文件中定义, 也可以把模块拆分到不同的文件或文件夹中.
- 地位: 代码的逻辑分组, 控制可见性(私有/共有)
总结图解: 让我们看一个实际的目录结构, 来串联着三个概念:
my-project/ <-- 1. Package (包)
├── Cargo.toml <-- (快递单,定义了 Package)
├── src/
│ ├── main.rs <-- 2. Binary Crate Root (二进制箱的根)
│ │ (这是机器的主开关)
│ │
│ └── lib.rs <-- 2. Library Crate Root (库箱的根)
│ (这是零件盒的说明书)
│
└── src/bin/ <-- (Package 可以包含更多二进制箱)
└── another_tool.rs
2
3
4
5
6
7
8
9
10
11
而在main.rs或lib.rs内部, 我们使用Module(模块):
// src/main.rs (Crate Root)
// 定义一个模块 (相当于在机器里做了一个隔层)
mod network {
// 默认是私有的, 外面看不见
fn connect() { ... }
// 加了 pub, 相当于在这个隔层上开了个窗户, 外面可以用
pub fn fetch_data() { ... }
}
// 定义另一个模块
mod filesystem {
pub fn save_file() { ... }
}
fn main() {
// 使用模块中的功能
// 路径: Crate -> network模块 -> fetch_data函数
network::fetch_data();
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
一句话总结:
- Package(包): 是项目, 由
Cargo.toml管理, 包含一个或多个Crate. - Create(箱): 是产物, 是编译器生成的可执行文件或库.
- Module(模块): 是组织, 是Crate内部用来给代码分类和控制访问权限的格子.
Actix Web项目通常遵循Rust社区的标准惯例, 同时结合Web开发的分层架构(如MVC或Clean Architecture). 以下是一个生产级Actix Web项目的推荐目录结构:
my-actix-app/
├── Cargo.toml # 项目依赖和元数据
├── .env # 环境变量 (数据库连接串, 端口等)
├── src/
│ ├── main.rs # 应用程序入口 (启动 Server, 配置 App)
│ ├── lib.rs # 库入口 (导出模块, 方便集成测试)
│ │
│ ├── api/ # API 路由层 (Controller)
│ │ ├── mod.rs # 注册所有路由
│ │ ├── auth_api.rs # 认证相关路由 (Login, Register)
│ │ └── user_api.rs # 用户相关路由 (CRUD)
│ │
│ ├── models/ # 数据模型层 (Structs)
│ │ ├── mod.rs
│ │ ├── user.rs # User 结构体 (对应数据库表)
│ │ └── request.rs # 请求/响应的 DTO (Data Transfer Object)
│ │
│ ├── repository/ # 数据库访问层 (DAO/Repository)
│ │ ├── mod.rs
│ │ └── user_repo.rs # 具体的 SQL 查询或 ORM 操作
│ │
│ ├── services/ # 业务逻辑层 (Service)
│ │ ├── mod.rs
│ │ └── auth_service.rs # 处理复杂的业务逻辑 (如密码加密, Token生成)
│ │
│ ├── db/ # 数据库连接配置
│ │ └── mod.rs # 建立连接池 (Pool)
│ │
│ ├── middleware/ # 自定义中间件
│ │ ├── mod.rs
│ │ └── auth.rs # JWT 验证中间件
│ │
│ ├── utils/ # 工具函数
│ │ ├── mod.rs
│ │ └── error.rs # 统一错误处理 (自定义 Error 类型)
│ │
│ └── config/ # 配置加载
│ └── mod.rs # 加载 .env 或 config.toml
│
└── tests/ # 集成测试
└── health_check.rs
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
关键模块说明:
src/main.rs:- 负责初始化日志, 加载配置, 建立数据库连接池.
- 启动
HttpServer并主持App. - 代码示例:
// src/main.rs
use actix_web::{web, App, HttpServer};
use my_actix_app::api; // 引用 lib.rs 中导出的模块
#[actix_web::main]
async fn main() -> std::io::Result<()> {
HttpServer::new(|| {
App::new()
.configure(api::config) // 配置路由
})
.bind(("127.0.0.1", 8080))?
.run()
.await
}
2
3
4
5
6
7
8
9
10
11
12
13
14
src/api/(路由层)- 定义具体的Handler函数(处理HTTP请求).
- 解析请求参数(JSON, Path, Query).
- 调用
Service层处理业务. - 返回
HttpResponse.
src/models/(模型层)- 定义Rust结构体
- 通常使用
serde进行序列化/反序列化. - 包含数据库实体(Entity)和数据传输对象(DTO).
src/repository/(数据层)- 直接与数据库交互
- 使用
sqlx或diesel等库执行SQL. - 将数据库结果转换为
models中的结构体
src/services/(业务层)- 解耦核心: 将业务逻辑从API层剥离.
- 例如: 用户注册时, API层只负责接收参数, Service层负责"检查邮箱是否存在 -> 密码哈希 -> 调用Repository保存 -> 生成Token".
src/utils/error.rs(错误处理)- Actix Web允许自定义错误类型实现
ResponseErrortrait. - 这样可以在代码中直接返回
Result<T, MyError>, 框架自动将其转换为对应的HTTP状态码和JSON响应.
- Actix Web允许自定义错误类型实现
这种结构的优点:
- 关注点分离: 数据库操作, 业务逻辑和HTTP处理互不干扰.
- 可测试性: 业务逻辑层(Service)不依赖于HTTP请求, 更容易编写单元测试.
- 可扩展性: 随着项目变大, 只需在对应的文件夹下添加新文件即可, 不会导致
main.rs臃肿.
在Rust项目中, mod.rs文件的主要作用是作为一个目录(文件夹)形式的模块的入口文件. 它的作用非常类似于Python中的__init__.py或者Node.js/JavaScript中的index.js.
以下是详细的解释:
- 核心作用: 定义模块层级
Rust的模块系统不会自动把文件夹里的所有文件都编译进去. 你需要显式地构建模块树. 当你创建一个文件夹来组织代码时, Rust编译器默认不知道这个文件夹是一个模块. mod.rs就是用来告诉编译器: "这个文件夹是一个模块, 这里面的内容是..."
- 具体使用场景
假设你有一个名为network的模块, 里面包含server和client两个子功能.
文件结构:
src/
├── main.rs # Crate 根
└── network/ # network 模块目录
├── mod.rs # network 模块的入口/声明文件
├── server.rs # 子模块
└── client.rs # 子模块
2
3
4
5
6
代码内容:
- 在
src/main.rs中: 需要声明network模块的存在
mod network; // 编译器会去寻找 src/network.rs 或 src/network/mod.rs
fn main() {
network::server::connect();
}
2
3
4
5
- 在
src/network/mod.rs中: 需要把文件夹里的其他文件"挂载"到模块树上, 否则server.rs和client.rs会被忽略.
// 声明公开子模块, 这样外部才能访问 network::server
pub mod server;
pub mod client;
// 也可以在这里写属于 network 模块本身的逻辑
pub fn check_status() {
println!("Network is fine");
}
2
3
4
5
6
7
8
- Rust 2018 版本后的变化 (新写法)
虽然mod.rs依然被完全支持且广泛使用, 但Rust 2018版本引入了一种新的模块文件风格, 旨在解决"编辑器里打开全是mod.rs导致分不清是哪个"的问题.
新风格结构: 不需要mod.rs, 而是创建一个与文件夹同名的.rs文件放在文件夹外面.
src/
├── main.rs
├── network.rs # 替代了 network/mod.rs
└── network/ # 存放子模块的文件夹
├── server.rs
└── client.rs
2
3
4
5
6
在这种新风格下, src/network.rs的内容和之前的src/network/mod.rs是一模一样的:
// src/network.rs 的内容
pub mod server;
pub mod client;
2
3
总结:
- mod.rs是旧风格(但依然通用)的模块目录入口.
- 它负责**导出(pub mod)**同目录下的其他文件, 是它们成文当前模块的子模块.
- 它也可以包含属于当前模块的公共代码.
# 访问权限
Rust中有两种简单的访问权: 公共(public)和私有(Private). 默认情况下, 如果不加修饰符, 模块中的成员访问权将是私有的. 如果想使用公共权限, 需要使用pub关键字. 对于私有的模块, 只有在与其平级的位置或下级的位置才能访问, 不能从其外部访问.
mod nation {
pub mod government {
pub fn govern() {}
}
mod congress {
pub fn legislate() {}
}
mod court {
fu judicial() {
super::congress::legislate();
}
}
}
fn main() {
nation::government::govern();
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
这段程序是能通过编译的. 请注意观察court模块中super的访问方法. 如果模块中定义了结构体, 结构体除了其本身是私有的以外, 其字段也默认是私有的. 所以如果想使用模块中的结构体以及其字段, 需要pub声明:
mod back_of_house {
pub struct Breakfast {
pub toast: String,
seasonal_fruit: String,
}
impl Breakfast {
pub fn summer(toast: &str) -> Breakfast {
Breakfast {
toast: String::from(toast),
seasonal_fruit: String::from("peaches"),
}
}
}
}
pub fn eat_at_restaurant() {
let mut meal = back_of_house::Breakfast::summer("Rye");
meal.toast = String::from("Wheat");
println!("I'd like {} toast please", meal.toast);
}
fn main() {
eat_at_restaurant(); // I'd like Wheat toast please
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
枚举类枚举项可以内含字段, 但不具备类似的性质:
mod SomeModule {
pub enum Person {
King { name: String },
Queen,
}
}
fn main() {
let person = SomeModule::Person::King {
name: String::from("Blue"),
};
match person {
SomeModule::Person::King { name } => {
println!("{}", name);
}
_ => {}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
这句话是在对比**结构体(Struct)和枚举(Enum)**在可见性(访问权限)上的区别. 结合上下文, 这句话的完整含义是:
虽然枚举项(Enum Variants)可以想结构体一样包含字段(例如
{ name: String }), 但它们不需要像结构体字段那样显式声明pub. 只需枚举本身是公开的(pub), 它里面所有的枚举项以及枚举项包含的字段就自动变成公开的.
为了彻底理解, 我们需要对比一下结构体和枚举的默认行为:
- 结构体的性质(需要手动加
pub)
在Rust中, 即使你把结构体声明为pub, 它的字段默认依然是私有的, 如果想让外部访问某个字段, 必须给字段单独加pub.
mod my_mod {
pub struct User {
pub name: String, // 必须加 pub, 外部才能访问
age: u32, // 没加 pub, 默认私有, 外部无法访问
}
}
2
3
4
5
6
- 枚举的性质("不具备类似的性质")
这句话说的"不具备类似的性质", 指的是枚举不需要像结构体那样麻烦, 只要枚举是pub的, 里面的所有内容(变体, 变体里的字段)全都是pub的.
mod my_mod {
// 只要 enum 是 pub 的 ...
pub enum Message {
// 这个变体是 pub 的
Quit,
// 这个变体里的 x, y 字段自动也是 pub 的, 不需要协 pub x: i32
Move { x: i32, y : i32 },
// 这个 String 字段自动也是 pub 的
Write(String),
}
}
fn main() {
// 可以直接访问枚举内部的字段, 完全没有权限阻碍
let m = my_mod::Message::Move { x: 10, y: 20 };
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
总结:
- 结构体: 默认"外开内闭", (大门开了, 房间门还锁着, 需要一个个开锁).
- 枚举: 默认"全开", (只要大门开了, 里面的所有房间门自动全开).
为什么这样设计? 因为枚举的核心作用就是区分不同的状态. 如果我能访问这个枚举, 但我却不知道他里面存了什么数据(比如Move里的坐标), 那这个枚举通常就没法用了(没法进行模式匹配). 而结构体通常需要封装内部实现细节, 所以默认隐藏字段更合理.
# 难以发现的模块
使用过Java的开发者在编程时往往非常讨厌最外层的class块--它的名字与文件名一模一样, 因为它就表示文件容器, 尽管它很繁琐但我们不得不写一遍来强调"这个类是文件所包含的类". 不过这样有一个好处: 起码它让开发者明白的意识到了类包装的存在, 而且可以明确的描述类的继承关系.
在Rust中, 模块就是Java中的类包装, 但是文件一开头就可以写一个主函数, 这该如何解释呢? 每一个Rust文件的内容都是一个"难以发现"的模块. 让我们用两个文件来提示这一点:
// main.rs
mod second_module;
fn main() {
println!("This is the main module.");
println!("{}", second_module::message());
}
2
3
4
5
6
7
// second_module.rs
pub fn message() -> String {
String::from("This is an 2nd module.")
}
2
3
4
# use 关键字
use 关键字能够将模块标识符引入当前作用域:
mod nation {
pub mod government {
pub fn govern() {}
}
}
use crate::nation::government::govern;
fn main() {
govern();
}
2
3
4
5
6
7
8
9
10
11
这段程序能够通过编译. 因为use关键字把govern标识符导入到了当前的模块下, 可以直接使用. 这样就解决了局部模块路径过长的问题. 当然, 有些情况下存在两个相同的名称, 且同样需要导入, 我们可以使用as关键字为标识符添加别名:
mod nation {
pub mod goverment {
pub fn govern() {}
}
pub fn govern() {}
}
use crate::nation::government::govern;
use crate::nation::govern as nation_govern;
fn main() {
nation_govern();
govern();
}
2
3
4
5
6
7
8
9
10
11
12
13
14
这里有两个govern函数, 一个是nation下的, 一个是government下的, 我们用as将nation下的取别名nation_govern. 两个名称可以同时使用. use关键字可以与pub关键字配合使用:
mod nation {
pub mod government {
pub fn govern() {}
}
pub use government::govern;
}
fn main() {
nation::govern();
}
2
3
4
5
6
7
8
9
10
# 引用标准库
Rust官方标准库字典: https://doc.rust-lang.org/stable/std/all.html
use std::f64::consts::PI;
fn main() {
println!("{}", (PI / 2.0).sin());
}
2
3
4
5
`use network;` 和 `mod network;`
这是一个非常经典且容易混淆的问题. 简单来说: mod是用来"建房子"的, use是用来"开门"的. 或者更技术一点的说法: mod用于声明和挂载模块(让编译器编译它), use用于引入路径(让代码更短).
以下是详细的区别对比:
mod network;-- 声明与挂载
它的核心作用是告诉编译器: "嘿, 我有一个子模块 network, 请去把他找出来并编译."
- 动作: 定义/挂载.
- 发生什么: 编译器会寻找
src/network.rs或者src/network/mod.rs文件. 如果找到了, 就把这个文件的内容作为当前模块的一个子节点挂载到模块树上. - 必要性: 如果你写了
network.rs文件, 但在main.rs(或lib.rs)里没有写mod network;, 那么network.rs里的代码根本不会被编译, 编译器会完全忽略它. - 出现次数: 通常一个模块只会被
mod一次(在它的父模块里).
use network;-- 引入与简化
它的核心作用是告诉编译器: "我知道 network 模块已经存在了, 我想在当前作用域里创建一个快捷方式, 这样我就不用每次都写全路径了."
- 动作: 引入/起别名
- 发生什么: 它不会去寻找文件, 也不会触发编译, 它只是在当前代码块里创建一个"软链接".
- 必要性: 不是必须的, 你完全可以不写
use, 直接用绝对路径crate::network::server::connect()来调用函数, 但写use可以让你只写server::connect(). - 出现次数: 可以在任何地方使用, 想用多少次都行.
- 代码实例对比, 假设你的文件结构如下:
src/
├── main.rs
└── network.rs <-- 里面有一个函数 fn connect()
2
3
在main.rs中:
// 1. 必须先用 mod 声明!
// 如果没有这行, 编译器根本不知道 network.rs 的存在
mod network;
// 2. 然后使用 use 来简化路径 (可选)
// 这样下面就可以直接写 connect(), 而不是 `network::connect()`
use network::connect;
fn main() {
// 调用方式 A (使用了 use 之后):
connect();
// 调用方式 B (如果不写 use, 必须这样写):
// network::connect();
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
- 形象的比喻
mod network;:- 就像是生孩子, 你必须先生下来(声明), 这个孩子(模块)才存在于这个世界上(模块树).
- 就像是新建文件夹, 你在文件系统里实实在在地创建了一个存储空间.
use network;:- 就像是存电话号码, 还在已经生下来了, 你把他的联系方式存到手机通讯录里, 方便随时联系, 而不用每次都背诵他的身份证号(全路径).
- 就像是创建桌面快捷方式, 文件夹已经在那了, 你只是在桌面上放了个图标指向它.
- 特殊情况: 外部依赖(Crates)
如果你在Cargo.toml里添加了一个第三方库(比如rand):
- 你不需要写
mod rand;(因为Cargo已经帮你处理了编译). - 你只需要写
use rand::...;来使用它.
# Rust 错误处理
Rust有一套独特的处理异常情况的机制, 它并不像其他语言中的try机制那样简单. 首先, 程序中一般会出现两种错误: 可恢复错误和不可恢复错误. 可恢复错误的典型案例是文件访问错误, 如果访问一个文件失败, 有可能是因为它正在被占用, 是正常的, 我们可以通过等待来解决. 但还有一种错误是由编程中无法解决的逻辑错误导致的, 例如访问数组末尾以外的位置. 大多数编程语言不区分这两种错误, 并由Exception(异常)类来表示错误. 在Rust中没有Exception, 对于可恢复错误用Result<T, E>类来处理, 对于不可恢复错误用panic!宏来处理.
# 不可恢复错误
本章以前没有专门介绍过Rust宏的语法, 但已经使用过了println!宏, 因为这些宏的使用较为简单, 所以暂时不需要彻底掌握它, 我们可以用同样的方法先学会使用panic!宏的使用方法.
fn main() {
panic!("error occurred");
println!("Hello, Rust!");
}
2
3
4

很显然, 程序并不能如约运行到println!("Hello, Rust!"), 而是在panic!宏被调用时停止了运行. 不可恢复的错误一定会导致程序受到致命的打击而终止运行. 让我们注视错误输出的两行:
- 第一行输出了
panic!宏调用的位置以及输出的错误信息. - 第二行是一句提示, 翻译成中文就是"通过
RUST_BACKTRACE=1环境变量运行以显式回溯". 接下来我们将介绍回溯(backtrace).
紧接着刚才的例子, 我们在VSCode中新建一个终端:
在新建的终端里设置环境变量(不同的终端方法不同, 这里介绍两种主要的方法):
如果在Windows 7及以上的Windows系统版本中, 默认使用的终端命令行是Powershell, 请使用以下命令:
$env:RUST_BACKTRACE=1 ; cargo run
如果你使用的是Linux或macOS等UNIX系统, 一般情况下默认使用的是bash命令行, 请使用以下命令:
RUST_BACKTRACE=1 cargo run
然后, 你会看到以下文字:
回溯是不可恢复错误的另一种处理方式, 它会展开运行的栈并输出所有的信息, 然后程序依然会退出. 上面的省略号省略了大量的输出信息, 我们可以找到我们编写的panic!宏触发的错误.
# 可恢复错误
此概念十分类似于Java编程语言中的异常, 实际上在C语言中我们就常常将函数返回值设置成整数来表达函数遇到的错误, 在Rust中通过Result<T, E>枚举类作为返回值来进行异常表达:
enum Result<T, E> {
Ok(T),
Err(E),
}
2
3
4
在Rust标准库中可能产生异常的函数的返回值都是Result类型的. 例如: 当我们尝试打开一个文件时:
use std::fs::File;
fn main() {
let f = File::open("hello.txt");
match f {
Ok(file) => {
println!("File opened successfully.");
},
Err(err) => {
println!("Failed to open the file. {}", err);
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
如果hello.txt文件不存在, 会打印: Failed to open the file. No such file or directory (os error 2). 当然, 我们在枚举类章节讲到的if let语法可以简化match语法块:
use std::fs::File;
fn main() {
let f = File::open("hello.txt");
if let Ok(file) = f {
println!("File opened successfully. {:?}", file);
} else if let Err(err) = f {
println!("Failed to open the file. {}", err);
}
}
2
3
4
5
6
7
8
9
10
如果想使一个可恢复错误按不可恢复错误处理, Result类提供了两个办法: unwrap()和expect(message: &str):
use std::fs::File;
fn main() {
// let f1 = File::open("hello.txt").unwrap();
// println!("File opened successfully: {:?}", f1);
let f2 = File::open("world.txt").expect("Failed to open world.txt");
println!("File opened successfully: {:?}", f2);
}
2
3
4
5
6
7
8
这段程序相当于在Result为Err时调用panic!宏, 两者的区别在于expect能够向panic!宏发送一段指定的错误信息.
# 可恢复的错误的传递
之前所将的是接收到错误的处理方式, 但是如果我们自己编写的一个函数在遇到错误时想传递出去怎么办?
fn f(i: i32) -> Result<i32, bool> {
if i >= 0 { Ok(i) } else { Err(false) }
}
fn main() {
let r = f(10000);
if let Ok(v) = r {
println!("Ok: f(-1) = {}", v);
} else {
println!("Err");
}
}
// 输出: Ok: f(-1) = 10000
2
3
4
5
6
7
8
9
10
11
12
13
14
这段程序中函数f是错误的根源, 现在我们再写一个传递错误的函数g:
fn f(i: i32) -> Result<i32, bool> {
if i >= 0 { Ok(i) } else { Err(false) }
}
fn g(i: i32) -> Result<i32, bool> {
let t = f(i);
return match t {
Ok(i) => Ok(i),
Err(e) => Err(e),
};
}
fn main() {
let r = g(10000);
if let Ok(v) = r {
println!("Ok: g(10000) = {}", v);
} else {
println!("Err");
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
函数g传递了函数f可能出现的错误(这里的g只是一个简单的例子, 实际上传递错误的函数一般还包含其他操作). 这样写有些冗长, Rust中可以在Result后面添加?操作符将同类的Err直接传递出去:
fn f(i: i32) -> Result<i32, bool> {
if i >= 0 { Ok(i) } else { Err(false) }
}
fn g(i: i32) -> Result<i32, bool> {
let t = f(i)?;
Ok(t) // 因为确定 t 不是 Err, t 在这里已经时 i32 类型
}
fn main() {
let r = g(-2);
if let Ok(v) = r {
println!("Ok: g(-2) = {}", v);
} else {
println!("Err");
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
?符的实际作用是将Result类非异常的值直接取出, 如果有异常就将异常Result返回出去, 所以, ?符仅用于返回值类型为Result<T, E>的函数, 其中 E 类型必须和 ? 所处理的 Result 的 E 类型一致.
# kind 方法
到此为止, Rust似乎没有像 try 块一样可以领任何位置发生的同类异常都直接得到相同的解决的语法, 但这样并不意味着Rust实现不了: 我们完全可以把 try 块在独立的函数中实现, 将所有的异常都传递出去解决. 实际上这才是一个分化良好的程序应当遵循的编程方法: 应该注重独立功能的完整性. 但是这样需要判断Result的Err类型, 获取Err类型的函数是kind().
use std::fs::File;
use std::io;
use std::io::Read;
fn read_text_from_file(path: &str) -> Result<String, io::Error> {
let mut f = File::open(path)?;
let mut s = String::new();
f.read_to_string(&mut s)?;
Ok(s)
}
fn main() {
let str_file = read_text_from_file("hello.txt");
match str_file {
Ok(s) => println!("{}", s),
Err(e) => match e.kind() {
io::ErrorKind::NotFound => println!("File not found."),
_ => println!("Cannot read the file {}", e),
},
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# Rust 泛型与特性
泛型是一个编程语言不可或缺的机制. C++语言中用"模板"来实现泛型, 而C语言中没有泛型的机制, 这也导致C语言难以构建类型复杂的工程. 泛型机制是编程语言用于表达类型抽象的机制, 一般用于功能确定, 数据类型待定的类, 如链表, 映射等.
# Rust 泛型简介
# 在函数中定义泛型
这是一个对整型数字选择排序的方法:
fn max(array: &[i32]) -> i32 {
let mut max_index = 0;
let mut i = 1;
while i < array.len() {
if array[i] > array[max_index] {
max_index = i;
}
i += 1;
}
array[max_index]
}
fn main() {
let a = [2, 4, 6, 3, 1];
println!("max = {}", max(&a)); // max = 6
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
这是一个简单的取最大值程序, 可以用于处理i32数字类型的数据, 但无法用于f64类型的数据. 通过使用泛型我们可以使这个函数可以利用到各个类型中去. 但实际上并不是所有的数据类型都可以比大小, 所以接下来一段代码并不是用来运行的, 而是用来描述一下函数泛型的语法:
fn max<T>(array: &[T]) -> T {
let mut max_index = 0;
let mut i = 1;
while i < array.len() {
if array[i] > array[max_index] {
max_index = i;
}
i += 1;
}
array[max_index]
}
2
3
4
5
6
7
8
9
10
11
# 结构体与枚举类中的泛型
在之前我们学习的Option和Result枚举类就是泛型的. Rust中的结构体和枚举类都可以实现泛型机制:
struct Point<T> {
x: T,
y: T
}
2
3
4
这是一个点坐标结构体, T表示描述点坐标的数字类型, 我们可以这样使用:
let p1 = Point { x: 1, y: 2 };
let p2 = Point { x: 1.0, y: 2.0 };
2
使用时并没有声明类型, 这里使用的是自动类型机制, 但不允许出现类型不匹配的情况如下:
let p = Point {x: 1, y: 2.0};
x与1绑定时就已经将T设定为i32, 所以不允许再出现f64的类型. 如果我们想让x与y用不同的数据类型表示, 可以使用两个泛型标识符:
struct Point<T1, T2> {
x: T1,
y: T2
}
2
3
4
在枚举类中表示泛型的方法诸如Option和Result:
enum Option<T> {
Some(T),
None,
}
enum Result<T, E> {
Ok(T),
Err(E),
}
2
3
4
5
6
7
8
9
结构体与枚举类都可以定义方法, 那么方法也应该实现泛型的机制, 否则泛型的类将无法被有效的方法操作.
struct Point<T> {
x: T,
y: T,
}
impl<T> Point<T> {
fn x(&self) -> &T {
&self.x
}
}
fn main() {
let p = Point { x: 1, y: 2 };
println!("p.x = {}", p.x()); // p.x = 1
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
注意, impl关键字的后方必须有<T>, 因为它后面的T是以之为榜样的. 但我们也可以为其中的一种泛型添加方法:
impl Point<f64> {
fn x(&self) -> f64 {
self.x
}
}
2
3
4
5
impl 块本身的泛型并没有阻碍其内部方法具有泛型的能力:
impl<T, U> Point<T, U> {
fn mixup<V, W>(self, other: Point<V, W>) -> Point<T, W> {
Point {
x: self.x,
y: other.y,
}
}
}
2
3
4
5
6
7
8
方法 mixup 将一个 Point<T, U> 点的 x 与 Point<V, W> 点的 y 融合成一个类型为 Point<T, W> 的新点.
# Rust 特性
特性(trait)概念接近于Java中的接口(Interface), 但两者不完全相同. 特性与接口相同的地方在于它们都是一种行为规范, 可以用于标识哪些类有哪些方法. 特性在Rust中用trait表示:
trait Descriptive {
fn describe(&self) -> String;
}
2
3
Descriptive规定了实现者必须有describe(&self) -> String方法. 我们用它实现一个结构体:
struct Person {
name: String,
age: u8
}
impl Descriptive for Person {
fn describe(&self) -> String {
format!("{} {}", self.name, self.age)
}
}
2
3
4
5
6
7
8
9
10
格式是: impl <特性名> for <所实现的类型名>
Rust同一个类可以实现多个特性, 每个impl块只能实现一个.
# 默认特性
这是特性与接口的不同点: 接口只能规范方法而不能定义方法, 但特性可以定义方法作为默认方法, 因为"默认", 所以对象既可以重新定义方法, 也可以不重新定义方法使用默认的方法:
trait Descriptive {
fn describe(&self) -> String {
String::from("[Object]")
}
}
struct Person {
name: String,
age: u8
}
impl Descriptive for Person {
// fn describe(&self) -> String {
// format!("{} {}", self.name, self.age)
// }
}
fn main() {
let cali = Person {
name: String::from("Cali"),
age: 24
};
println!("{}", cali.describe());
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
运行结果: Cali 24
如果我们将impl Descriptive for Person块中的内容去掉, 那么运行结果就是: [Object]
# 特性做参数
很多情况下我们需要传递一个函数做参数, 例如回调函数, 设置按钮事件等. 在Java中函数必须以接口实现的类实例来传递, 在Rust中可以通过传递特性参数来实现:
fn output(object: impl Descriptive) {
println!("{}", object.describe());
}
2
3
任何实现了Descriptive特性的对象都可以作为这个函数的参数, 这个函数没必要了解传入对象有没有其他属性或方法, 只需要了解它一定有Descriptive特性规范规范的方法就可以了. 当然, 此函数内也无法使用其他的属性与方法. 特性参数还可以用这种等效语法实现:
fn output<T: Descriptive>(object: T) {
println!("{}", object.describe());
}
2
3
这是一种风格类似泛型的语法糖, 这种语法糖在有多个参数类型均是特性的情况下十分实用:
fn output_two<T: Descriptive>(arg1: T, arg2: T) {
println!("{}", arg1.describe());
println!("{}", arg2.describe());
}
2
3
4
特性作类型表示时如果涉及多个特性, 可以用+符号表示, 例如:
fn notify(item: impl Summary + Display);
fn notify<T: Summary + Display>(item: T);
2
注意: 仅用于表示类型的时候, 并不意味着可以在impl块中使用. 复杂的视线关系可以使用where关键字简化, 例如:
fn some_function<T: Display + Clone, U: Clone + Debug>(t: T, u: U);
可以简化成:
fn some_function<T, U>(t: T, u: U) -> i32
where T: Display + Clone,
U: Clone + Debug
2
3
在了解这个语法之后, 泛型章节中的"取最大值"案例就可以真正实现了:
trait Comparable {
fn compare(&self, object: &Self) -> i8;
}
fn max<T: Comparable>(array: &[T]) -> &T {
let mut max_index = 0;
let mut i = 1;
while i < array.len() {
if array[i].compare(&array[max_index]) > 0 {
max_index = i;
}
i += 1;
}
&array[max_index]
}
impl Comparable for f64 {
fn compare(&self, object: &Self) -> i8 {
if &self > &object {
1
} else if &self == &object {
0
} else {
-1
}
}
}
fn main() {
let a = [2.0, 4.5, 6.3, 3.1, 1.0];
println!("max = {}", max(&a)); // max = 6.3
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
Tip: 由于需要声明compare函数的第二个参数必须与实现该特性的类型相同, 所以Self(注意大小写)关键字就代表了当前类型(不是实例)本身.
# 特性做返回值
特性做返回值格式如下:
fn person() -> impl Descriptive {
Person {
name: String::from("Cali"),
age: 24
}
}
2
3
4
5
6
但是有一点, 特性做返回值只接受实现了该特性的对象做返回值且在同一个函数中所有可能的返回值类型必须完全一样. 比如结构体A与结构体B都实现了特性Trait, 下面这个函数就是错误的:
fn some_function(bool bl) -> impl Descriptive {
if bl {
return A {};
} else {
return B {};
}
}
2
3
4
5
6
7
# 有条件实现方法
impl功能十分强大, 我们可以用它实现类的方法, 但对于泛型类来说, 有时我们需要区分一下它所属的泛型已经实现的方法来决定它接下来该实现的方法:
struct A<T> {}
impl<T: B + C> A<T> {
fn d(&self) {}
}
2
3
4
5
这段代码声明了A<T>类型必须在T已经实现B和C特性的前提下才能有效实现此impl块.
# Rust 生命周期
Rust生命周期机制是与所有权机制同等重要的资源管理机制. 之所以引入这个概念主要是应对复杂类型系统中资源管理的问题. 引用是对待复杂类型时必不可少的机制, 毕竟复杂类型的数据不能被处理器轻易地复制和计算. 但引用往往导致及其复杂的资源管理问题, 首先认识一下垂悬引用:
{
let r;
{
let x = 5;
r = &x;
}
println!("r: {}", r);
}
2
3
4
5
6
7
8
9
10
这段代码是不会通过Rust编译器的, 原因是r所引用的值已经在使用之前被释放.

上图中的绿色范围'a表示r的生命周期, 蓝色范围'b表示x的生命周期, 很显然'b比'a小得多, 引用必须在值的生命周期以内才有效. 一直以来我们都在结构体中使用String而不用&str, 我们用一个案例解释原因:
fn longer(s1: &str, s2: &str) -> &str {
if s2.len() > s1.len() {
s2
} else {
s1
}
}
2
3
4
5
6
7
longer函数取s1和s2两个字符串切片中较长的的一个返回其引用值. 但是这段代码不会通过编译, 原因是返回值引用可能会返回过期的引用:
fn longer(s1: &str, s2: &str) -> &str {
if s1.len() > s2.len() {
s1
} else {
s2
}
}
fn main() {
let r;
{
let s1 = "rust";
let s2 = "ecmascript";
r = longer(s1, s2);
}
println!("{} is longer", r);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
这段程序中虽然经过了比较, 但r被使用的时候源值s1和s2都已经失效了. 当然我们可以把r的使用移到s1和s2的生命周期以内防止这种错误的发生, 但对于函数来说, 它并不能知道自己以外的地方是什么情况, 它为了保障自己传递出去的值是正常的, 必选所有权原则消除一切危险, 所以longer函数并不能通过编译.
# 生命周期注释
生命周期注释是描述引用生命周期的办法. 虽然这样并不能改变引用的生命周期, 但可以在合适的地方声明两个引用的生命周期一致. 生命周期注释用单引号开头, 跟着一个小写字母单词:
&i32 // 常规引用
&'a i32 // 含有生命周期注释的引用
&'a mut i32 // 可变型含有生命周期注释的引用
2
3
4
5
让我们用生命周期注释改造longer函数:
fn longer<'a>(s1: &'a str, s2: &'a str) -> &'a str {
if s2.len() > s1.len() {
s2
} else {
s1
}
}
2
3
4
5
6
7
我们需要用泛型声明来规范生命周期的名称, 随后函数返回值的生命周期将与两个参数的生命周期一致, 所以在调用时可以这样写:
fn longer<'a>(s1: &'a str, s2: &'a str) -> &'a str {
if s1.len() > s2.len() {
s1
} else {
s2
}
}
fn main() {
let r;
{
let s1 = "rust";
let s2 = "ecmascript";
r = longer(s1, s2);
}
println!("{} is longer", r);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
注意: 别忘了自动类型判断的原则.
# 结构体中使用字符串切片引用
这是之前留下的疑问, 在此解答:
fn main() {
struct Str<'a> {
content: &'a str
}
let s = Str {
content: "string_slice"
};
println!("s.content = {}", s.content); // s.content = string_slice
}
2
3
4
5
6
7
8
9
如果对结构体Str有方法定义:
impl<'a> Str<'a> {
fn get_content(&self) -> &str {
self.content
}
}
2
3
4
5
这里返回值并没有生命周期注释, 但是加上也无妨. 这是一个历史问题, 早期Rust不支持声明周期自动判断, 所有的生命周期必须严格声明, 但主流稳定版本的Rust已经支持了这个功能.
- 用泛型声明来规范生命周期的名称
在Rust中, 生命周期参数(如'a)本质上和泛型参数(如T)是一样的.
- 泛型T: 告诉编译器这里可以是任何类型.
- 生命周期
'a: 告诉编译器这里可以是任何存活时间.
所以, 就像你必须先声明<T>才能使用T一样, 你也必须先声明<'a>才能使用'a.
// 必须在函数名后面先声明 <'a>
fn longer<'a>(...)
2
- 函数返回值的生命周期将与两个参数的生命周期一致
这句话的核心逻辑.
fn longer<'a>(s1: &'a str, s2: &'a str) -> &'a str { ... }
- 输入:
s1和s2都被标注了'a, 这意味着编译器会取s1和s2实际生命周期的交集(即两者中较短的那个), 并将其命名为'a. - 输出: 返回值也被标注了
'a, 这意味着返回值的生命周期至少要和那个"较短的生命周期"一样长.
通俗理解: 编译器不知道if-else到底会返回s1还是s2. 为了安全, 它强制要求: "不管返回哪一个, 返回值的有效期不能超过输入参数中活得最短的那个".
- 注意别忘了自动类型判断
这句话是在提醒, 虽然我们在函数定义上写了'a, 但在调用函数时, 通常不需要手动写'a. Rust编译器非常聪明, 它会自动分析传入的实参(比如r = longer(s1, s2)), 自动推导出s1和s2的实际生命周期, 然后自动计算出'a应该是多少, 最后检查你的代码是否安全.
fn longer<'a>(s1: &'a str, s2: &'a str) -> &'a str {
if s1.len() > s2.len() {
s1
} else {
s2
}
}
fn main() {
let r;
{
let s1 = "rust";
let s2 = "ecmascript";
r = longer(s1, s2);
}
println!("{} is longer", r);
}
// 这段代码为什么会成功运行?
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
上面的代码之所以能成功运行, 是因为这里有一个特殊的"特例": 字符串字面量(String Literals). 这看起来似乎违反了我们上面讨论的"生命周期交集"原则(即s1和s2在内部花括号结束时就"死"了, r应该编程垂悬引用), 但实际上并没有.
核心原因: 'static生命周期, 在Rust中, 当你直接写let s = "hello";时, 这个字符串数据的存储位置并不是在堆上, 也不是在栈上, 而是直接硬编码在编译后的二进制程序的数据段中.
这意味着:
"rust"和"ecmascript"这两个字符串数据的生命周期是'static(整个程序运行期间都有效).- 虽然变量
s1和s2(作为栈上的指针变量)在花括号}处离开了作用域, 但它们指向的数据永远不会消失.
编译器是如何推理的?
- 输入参数:
s1指向"rust", 声明周期是'static.s2指向"ecmascript", 声明周期是'static.
- 计算
'a:- 函数签名要求
'a是两个参数生命周期的交集. min('static', 'static')的结果依然是'static.- 所以, 泛型
'a被推导为'static.
- 函数签名要求
- 返回值:
- 返回值
r的生命周期也是'a(即'static) - 这意味着
r指向的数据在整个程序中都是有效的.
- 返回值
- 检查:
- 在
println!处, 依然有效, 因为它是'static.
- 在
对比: 如果换成String就会报错. 为了验证这一点, 如果我们把字面量改成堆上分配的String(它有明确的销毁时间), 代码就会立刻报错:
fn longer<'a>(s1: &'a str, s2: &'a str) -> &'a str {
if s1.len() > s2.len() {
s1
} else {
s2
}
}
fn main() {
let r;
{
// 改成 String::from 数据存在堆上, s1 拥有所有权
let s1 = String::from("rust");
let s2 = String::from("ecmascript");
// 这里传入的是 &String, Rust 会自动解引用成 &str
// 此时 s1 和 s2 的生命周期仅限于这个花括号内部
r = longer(&s1, &s2);
println!("{} is longer", r);
} // <--- s1 和 s2 在这里被 drop, 堆内存被释放
// ❌ 报错!r 指向的内存已经被释放了
// println!("{} is longer", r);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
# 静态生命周期
生命周期注释有一个特别的: 'static. 所有用双引号包括的字符串常量所代表的精确数据类型都是&'static str, 'static所表示的生命周期从程序运行开始到程序运行结束.
# 泛型, 特性与生命周期协同作战
// 这段程序出自Rust圣经, 是一个同时使用了泛型, 特性, 生命周期机制的程序.
use std::fmt::Display;
fn longest_with_an_announcement<'a, T>(x: &'a str, y: &'a str, ann: T) -> &'a str
where
T: Display,
{
println!("Announcement! {}", ann);
if x.len() > y.len() { x } else { y }
}
fn main() {
let string1 = String::from("abcd");
let string2 = "xyz";
let result = longest_with_an_announcement(string1.as_str(), string2, "Comparing two strings");
println!("The longest string is {}", result);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# Rust 文件与IO
# 接收命令行参数
命令行程序是计算机程序最基础的存在形式, 几乎所有的操作系统都支持命令行程序并将可视化程序的运行基于命令行机制. 命令行程序必须能够接收来自命令行环境的参数, 这些参数往往在一条命令行之后以空格符分隔. 在很多语言中(如Java和C/C++)环境参数是以主函数的参数(常常是一个字符串数组)传递给程序, 但在Rust中主函数是个无参函数, 环境参数需要通过std::env模块取出, 过程十分简单:
fn main() {
let args = std::env::args();
println!("{:?}", args); // Args { inner: ["/home/sunyy/Sources/train/rust-train/greeting/target/debug/greeting"] }
}
2
3
4
这个结果中Args结构体中有一个inner数组, 只包含唯一的字符串, 代表了当前运行的程序所在的位置. 但这个数据结构令人难以理解, 没关系, 我们可以简单地遍历它:
fn main() {
let args = std::env::args();
for arg in args {
println!("{}", arg);
}
}
2
3
4
5
6
一般参数们就是用来被遍历的, 不是吗? 现在我们打开许久未碰的launch.json, 找到"args": [], 这里可以设置运行时的参数, 我们将它写成"args": ["first", "second"], 然后保存, 再次运行刚才的程序, 运行结果:
/home/sunyy/Sources/train/rust-train/greeting/target/debug/greeting
first
second
2
3
作为一个真正的命令行程序, 我们从未真正使用过它, 作为语言教程不在此叙述如何用命令行运行Rust程序, 但如果你是个训练有素的开发者, 你应该可以找到可执行文件的位置, 你可以尝试进入目录并使用命令行来测试程序接收命令行环境参数.
# 命令行输入
早期的章节详细讲述了如何使用命令行输出, 这是由于语言学习的需要, 没有输出是无法调试程序的, 但从命令行获取输入的信息对于一个命令行程序来说依然是相当重要的. 在Rust中, std::io模块提供了标准输入(可认为是命令行输入)的相关功能:
use std::io::stdin;
fn main() {
let mut str_buf = String::new();
stdin().read_line(&mut str_buf).expect("Failed to read line");
println!("You input line is \n: {}", str_buf.trim());
}
2
3
4
5
6
7
std::io::stdin包含read_line读取方法, 可以读取一行字符串到缓冲区, 返回值都是Result枚举类, 用于传递读取中出现的错误, 所以常用expect或unwrap函数来处理错误.
注意: 目前Rust标准库还没有提供直接从命令行读取数字或格式化数据的方法, 我们可以读取一行字符串并使用字符串识别函数处理数据.
# 文件读取
在计算机的/home/sunyy/Temp/下建立text.txt, 内容如下:
This is a text file.
这是一个将文本文件读入字符串的程序:
use std::fs;
fn main() {
let text = fs::read_to_string("/home/sunyy/Temp/text.txt").unwrap();
println!("{}", text); // This is a text file.
let content = fs::read("/home/sunyy/Temp/text.txt").unwrap();
println!("{:?}", content);
// [84, 104, 105, 115, 32, 105, 115, 32, 97, 32, 116, 101, 120, 116, 32, 102, 105, 108, 101, 46, 10]
}
2
3
4
5
6
7
8
9
10
在Rust中读取内存可容纳的一整个文件是一件极度简单的事情, std::fs模块中的read_to_string方法可以轻松完成文本文件的读取. 但如果要读取的文件是二进制文件, 可以用std::fs::read函数读取u8类型集合.
以上两种方式是一次性读取, 十分适合Web应用的开发. 但是对于一些底层程序来说, 传统的按流读取依然是无法取代的. 因为更多情况下文件的大小可能远超内存容量.
Rust中文件流读取方式:
use std::io::prelude::*;
use std::fs;
fn main() {
let mut buffer = [0u8; 5];
let mut file = fs::File::open("/home/sunyy/Temp/text.txt").unwrap();
file.read(&mut buffer).unwrap();
println!("{:?}", buffer); // [84, 104, 105, 115, 32]
file.read(&mut buffer).unwrap();
println!("{:?}", buffer); // [105, 115, 32, 97, 32]
}
2
3
4
5
6
7
8
9
10
11
std::fs模块中的File类是描述文件的类, 可以用于打开文件, 再打开文件之后, 我们可以使用File的read方法按流读取文件的下面一些字节到缓冲区(缓冲区是一个u8数组), 读取的字节数等于缓冲区的长度.
注意: VSCode目前还不具备自动添加标准库引用的功能, 所以有时出现"函数或方法不存在"一样的错误有可能是标准库引用的问题. 可以查看标准库的注释文档(鼠标放到上面会出现)来手动添加标准库.
std::fs::File的open方法是"只读"打开文件, 并且没有配套的close方法, 因为Rust编译器可以在文件不再被使用时自动关闭文件.
# 文件写入
文件写入分为一次性写入和流式写入, 流式写入需要打开文件, 打开方式有"新建"(create)和"追加"(append)两种.
一次性写入:
use std::fs;
fn main() {
fs::write("/home/sunyy/Temp/text.txt", "FROM RUST PROGRAM").unwrap();
}
2
3
4
5
这和一次性读取一样简单方便, 执行程序之后, 文件的内容将会被重写为FROM RUST PROGRAM, 所以, 一次性写入请谨慎使用! 因为它会直接删除文件内容(无论文件多么大), 如果文件不存在就会创建文件. 如果想使用流的方式写入文件内容, 可以使用std::fs::File的create方法:
use std::io::prelude::*;
use std::fs::File;
fn main() {
let mut file = File::create("/home/sunyy/Temp/text.txt").unwrap();
file.write(b"FROM RUST PROGRAM").unwrap();
}
2
3
4
5
6
7
这段程序与上一个程序等价.
注意: 打开的文件一定存放在可变的变量中才能使用File的方法!
File类中不存在append静态方法, 但是我们可以使用OpenOptions来实现用特定方法打开文件:
use std::fs::OpenOptions;
use std::io::prelude::*;
fn main() -> std::io::Result<()> {
let mut file = OpenOptions::new()
.append(true)
.open("/home/sunyy/Temp/text.txt")?;
file.write(b" APPEND WORD")?;
Ok(())
}
2
3
4
5
6
7
8
9
10
11
在Rust的std::fs::OpenOptions中, 所谓的"权限"通常指两类配置:
访问模式(Access Modes): 决定你如何操作文件(读, 写, 追加)
创建与截断行为(Creation & Trancation): 决定文件不存在或已存在时怎么处理.
系统级权限(OS Permissions): (仅限Unix/Linux)设置文件的
rwx权限位.基础访问模式: 这些方法控制打开文件后能做什么
read(true): 以只读方式打开.write(true): 以可写方式打开, 默认情况下, 这不会清空文件, 通常需要配合create或truncate使用append(true): 以追加模式打开, 自动开启写入权限, 文件指针始终位于文件末尾. (即使你手动seek到开头, 写入时也会跳回末尾).
创建与截断行为: 这些方法控制文件打开时的状态变化
trancate(true): 如果文件存在, 打开时将其长度截断为0(清空文件内容), 必须同时开启write(true).create(true): 如果文件不存在, 则创建新文件; 如果存在, 则直接打开. 最常用的"打开或新建".create_new(true): 如果文件不存在, 则创建; 如果文件以存在, 则报错(返回Err). 用于确保文件是全新的, 防止覆盖已有文件(原子操作).
Linux/Unix特有权限(Mode): 由于在Linux环境下, 可以使用扩展
trait设置文件的系统权限(如755,644). 需要引入:use std::os::unix::fs::OpenOptionExtmode(u32): 设置新建文件的权限位,.mode(0o644)(用户读写, 组读, 其他读).
# Rust 集合与字符串
集合(Collection)是数据结构中最普遍的数据存放形式, Rust标准库中提供了丰富的集合类型帮助开发者处理数据结构的操作.
# 向量
向量(Vector)是一个存放多值的单数据结构, 该结构将相同类型的值线性的存放在内存中. 向量是线性的, 在Rust中的表示是Vec<T>. 向量的使用方式类似于列表List, 我们可以通过这种方式创建指定类型的向量:
let vector: Vec<i32> = Vec::new(); // 创建类型为 i32 的空向量
let vector: vec![1, 2, 4, 8]; // 通过数组创建向量
2
我们使用线性表常常会用到追加的操作, 但是追加和栈的push操作本质上是一样的, 所以向量只有push方法来追加单个元素:
fn main() {
let mut vector = vec![1, 2, 4, 8];
vector.push(16);
vector.push(32);
vector.push(64);
println!("{:?}", vector);
}
2
3
4
5
6
7
append方法用于将一个向量拼接到另一个向量的尾部:
fn main() {
let mut v1: Vec<i32> = vec![1, 2, 4, 8];
let mut v2: Vec<i32> = vec![16, 32, 64];
v1.append(&mut v2);
println!("{:?}", v1);
}
2
3
4
5
6
get方法用于取出向量中的值:
fn main() {
let mut v = vec![1, 2, 4, 8];
println!("{}", match v.get(0) {
Some(value) => value.to_string(),
None => "None".to_string(),
}); // 1
}
2
3
4
5
6
7
因为向量的长度无法从逻辑上推断, get方法无法保证一定取到值, 所以get方法的返回值是Option枚举类, 有可能为空. 这是一种安全的取值方法, 但是书写起来有些麻烦. 如果你能确保取值的下标不会超出向量下标取值范围, 你也可以使用数组取值语法:
fn main() {
let v = vec![1, 2, 4, 8];
println!("{}", v[1]); // 但是如果我们尝试获取 v[4], 那么向量会返回错误.
}
2
3
4
遍历向量:
fn main() {
let v = vec![100, 32, 57];
for i in &v {
println!("{}", i);
}
}
2
3
4
5
6
如果遍历过程中需要更改变量的值:
fn main() {
let mut v = vec![100, 32, 57];
for i in &mut v {
*i += 50;
}
println!("{:?}", v);
}
2
3
4
5
6
7
# 字符串
字符串类(String)到本章为止已经使用了很多, 所以有很多的方法已经被读者熟知, 本章主要介绍字符串的方法和UTF-8性质:
新建字符串: let string = String::new();
基础类型转换成字符串:
let one = 1.to_string(); // 整数到字符串
let float = 1.3.to_string(); // 浮点数到字符串
let slice = "slice".to_string(); // 字符串切片到字符串
2
3
包含UTF-8字符的字符串:
let hello = String::from("السلام عليكم");
let hello = String::from("Dobrý den");
let hello = String::from("Hello");
let hello = String::from("שָׁלוֹם");
let hello = String::from("नमस्ते");
let hello = String::from("こんにちは");
let hello = String::from("안녕하세요");
let hello = String::from("你好");
let hello = String::from("Olá");
let hello = String::from("Здравствуйте");
let hello = String::from("Hola");
2
3
4
5
6
7
8
9
10
11
字符串追加:
let mut s = String::from("run");
s.push_str("oob"); // 追加字符串切片
s.push('!'); // 追加字符
2
3
用 + 号拼接字符串:
let s1 = String::from("Hello, ");
let s2 = String::from("world!");
let s3 = s1 + &s2;
2
3
这个语法也可以包含字符串切片:
let s1 = String::from("tic");
let s2 = String::from("tac");
let s3 = String::from("toe");
let s = s1 + "-" + &s2 + "-" + &s3;
2
3
4
5
使用format!宏:
let s1 = String::from("tic");
let s2 = String::from("tac");
let s3 = String::from("toe");
let s = format!("{}-{}-{}", s1, s2, s3);
2
3
4
5
字符串长度:
let s = "hello";
let len = s.len(); // 5
2
let s = "您好";
let len = s.len(); // 6
// 这里的 len 值是 6, 因为中文是UTF-8编码的, 每个字符长3字节, 所以长度为6.
2
3
但是Rust中支持UTF-8字符对象, 所以如果想统计字符数量可以先去字符串为字符集合:
let s = "hello你好";
let len = s.chars().count(); // 7, 因为一共有7个字符. 统计字符的速度比统计数据长度的速度慢的多.
2
遍历字符串:
fn main() {
let s = String::from("Hello, world!");
for c in s.chars() {
println!("{}", c);
}
}
2
3
4
5
6
从字符串中取单个字符:
fn main() {
let s = String::from("Hello, world!");
let a = s.chars().nth(5);
println!("{:?}", a); // Some(',')
}
2
3
4
5
注意: nth函数是从迭代器中取出某值的方法, 请不要在遍历中这样使用! 因为UTF-8每个字符的长度不一定相等!
如果想截取字符串:
fn main() {
let s = String::from("EN中文");
let sub = &s[0..2];
println!("{}", sub); // Output: EN
}
2
3
4
5
但是请注意此用法有可能肢解一个UTF-8字符! 那样会报错:
fn main() {
let s = String::from("EN中文");
let sub = &s[0..3];
println!("{}", sub);
}
2
3
4
5
# 映射表
映射表(Map)在其他语言中广泛存在, 其中应用最普遍的就是键值散列映射表(Hash Map). 新建一个散列值映射表:
use std::collections::HashMap;
fn main() {
let mut map = HashMap::new();
map.insert("color", "red");
map.insert("size", "10 m^2");
println!("{}", map.get("color").unwrap()); // Output: red
}
2
3
4
5
6
7
8
9
10
注意: 这里没有声明散列表的泛型, 是因为Rust的自动判断类型机制.
insert方法和get方法是映射表最常用的两个方法. 映射表支持迭代器:
use std::{collections::HashMap, hash::Hash};
fn main() {
let mut map = HashMap::new();
map.insert("color", "red");
map.insert("size", "10 m^2");
for p in map.iter() {
println!("{:?}", p);
}
// 输出:
// ("size", "10 m^2")
// ("color", "red")
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
迭代元素时表示键值对的元组. Rust的映射表是十分方便的数据结构, 当使用insert方法添加新的键值对的时候, 如果已经存在相同的键, 会直接覆盖对应的值. 如果你想"安全地插入", 就是在确认当前不存在某个键时才执行的插入动作, 可以这样:
map.entry("color").or_insert("red");
这句话的意思就是如果没有键为"color的键值对就添加它并设定值为"red", 否则将跳过. 在已经确定有某个键的情况下如果想直接修改对应的值, 有更快的办法:
use std::collections::HashMap;
fn main() {
let mut map = HashMap::new();
map.insert(1, "a");
if let Some(x) = map.get_mut(&1) {
*x = "b";
}
}
2
3
4
5
6
7
8
9
10
# Rust 面相对象
面向对象的编程语言通常实现了数据的封装与继承并能基于数据调用方法. Rust不是面向对象的编程语言, 但这些功能都得以实现.
# 封装
封装就是对外显示的策略, 在Rust中可以通过模块的机制来实现最外层的封装, 并且每一个Rust文件都可以看作一个模块, 模块内的元素可以通过pub关键字对外明示. 这一点在"组织管理"章节详细叙述过.
"类"往往是面向对象的编程语言中常用到的概念. "类"封装的是数据, 是对同一类数据实体以及其处理方法的抽象. 在Rust中, 我们可以使用结构体或枚举类来实现类的功能:
pub struct ClassName {
pub field: Type,
}
pub impl ClassName {
fn some_method(&self) {
// 方法函数体
}
}
pub enum EnumName {
A,
B,
}
pub impl EnumName {
fn some_method(&self) {
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
下面建造一个完整的类:
// second.rs
pub struct ClassName {
field: i32,
}
impl ClassName {
pub fn new(value: i32) -> ClassName {
ClassName { field: value }
}
pub fn public_method(&self) {
println!("from public method");
self.private_method();
}
fn private_method(&self) {
println!("from private method");
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
// main.rs
mod second;
use second::ClassName;
fn main() {
let object = ClassName::new(1024);
object.public_method();
// from public method
// from private method
}
2
3
4
5
6
7
8
9
10
# 继承
几乎其他的面向对象的编程语言都可以实现"继承", 并用"extend"词语来描述这个动作.
继承是多态(Polymorphism)思想的实现, 多态指的是编程语言可以处理多种类型数据的代码. 在Rust中, 通过特性(trait)实现多态. 有关特性的细节已在"特性"章节给出. 但是特性无法实现属性的继承, 只能实现类似于"接口"的功能, 所以想继承一个类的方法最好在"子类"中定义"父类"的实例.
总结地说, Rust没有提供跟继承有关的语法糖, 也没有官方的继承手段(完全等同于Java中的类的继承), 但灵活的语法依然可以实现相关的功能.
# Rust 并发编程
安全高效的处理并发是Rust诞生的目的之一, 主要解决的是服务器高负载承受能力. 并发(concurrent)的概念是指程序不同的部分独立执行, 这与并行(parallel)的概念容易混淆, 并行强调的是"同时执行". 并发往往会造成并行.
# 线程
线程(thread)是一个程序中独立运行的一个部分. 线程不同于进程(process)的地方是线程是程序以内的概念, 程序往往是在一个进程中执行的. 在有操作系统的环境中进程往往被交替地调度得以执行, 线程则在进程以内由程序进行调度. 由于线程并发很有可能出现并行的情况, 所以在并行中可能遇到的死锁, 延宕错误常出现于含有并发机制的程序. 为了解决这些问题, 很多其他语言(如Java, C#)采用特殊的运行时(runtime)软件来协调资源, 但这样无疑极大地降低了程序的执行效率.
C/C++语言在操作系统的最底层也支持多线程, 且语言本身以及其编译器不具备侦察和避免并行错误的能力, 这对于开发者来说压力很大, 开发者需要花费大量的精力避免发生错误.
Rust不依靠运行时环境, 这一点像C/C++一样. 但Rust在语言本身就设计了包括所有权机制在内的手段尽可能地把最常见的错误消灭在编译阶段, 这一点其他语言不具备. 但这不意味着我们编程的时候可以不小心, 迄今为止由于并发造成的问题还没有在公共范围内得到完全解决, 仍有可能出现错误, 并发编程时要尽量小心.
Rust中通过std::thread::spawn函数创建新线程:
use std::thread;
use std::time::Duration;
fn spawn_function() {
for i in 0..5 {
println!("spawned thread print: {}", i);
thread::sleep(Duration::from_millis(1));
}
}
fn main() {
thread::spawn(spawn_function);
for i in 0..3 {
println!("main thread print: {}", i);
thread::sleep(Duration::from_millis(1));
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18

这个结果在某些情况下顺序有可能变化, 但总体上是这样打印出来的. 此程序有一个子线程, 目的是打印5行文字, 主线程打印三行文字, 但很显然随着主线程的结束, spawn线程也随之结束了, 并没有完成所有的打印.
std::thread::spawn函数的参数是一个无参函数, 但上述写法不是推荐的写法, 我们可以使用闭包(closures)来传递函数作为参数:
use std::thread;
use std::time::Duration;
fn main() {
thread::spawn(|| {
for i in 0..5 {
println!("spawned thread print {}", i);
thread::sleep(Duration::from_millis(1));
}
});
for i in 0..3 {
println!("main thread print {}", i);
thread::sleep(Duration::from_millis(1));
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
闭包是可以保存进变量或作为参数传递给其他函数的匿名函数. 闭包相当于Rust中的Lambda表达式, 格式如下:
|参数1, 参数2, ... | -> 返回值类型 {
// 函数体
}
2
3
例如:
fn main() {
let inc = |num: i32| -> i32 {
num + 1
};
println!("inc(5) = {}", inc(5)); // inc(5) = 6
}
2
3
4
5
6
7
闭包可以省略类型声明使用Rust自动类型判断机制:
fn main() {
let inc = |num| {
num + 1
};
println!("inc(5) = {}", inc(5)); // inc(5) = 6
}
2
3
4
5
6
# join 方法
use std::thread;
use std::time::Duration;
fn main() {
let handle = thread::spawn(|| {
for i in 0..5 {
println!("spawned thread print {}", i);
thread::sleep(Duration::from_millis(1));
}
});
for i in 0..3 {
println!("main thread print {}", i);
thread::sleep(Duration::from_millis(1));
}
handle.join().unwrap();
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18

join方法可以使子线程运行结束后再停止运行程序.
# move 强制所有权转移
这是一个经常遇到的情况:
use std::thread;
fn main() {
let s = "hello";
let handle = thread::spawn(|| {
println!("{}", s);
});
handle.join().unwrap();
}
2
3
4
5
6
7
8
9
10
11
在子线程中尝试使用当前函数的资源, 这一定是错误的! 因为所有权机制禁止这种危险情况的产生, 它将破坏所有权机制销毁资源的一定性. 我们可以使用闭包move关键字来处理:
use std::thread;
fn main() {
let s = "hello";
let handle = thread::spawn(move || {
println!("{}", s);
});
handle.join().unwrap();
}
2
3
4
5
6
7
8
9
10
11
# 消息传递
Rust中一个实现消息传递并发的主要工具是通道(channel), 通道有两部分组成, 一个发送者(transmitter)和一个接受者(receiver).
std::sync::mpsc包含了消息传递的方法:
use std::thread;
use std::sync::mpsc;
fn main() {
let (tx, rx) = mpsc::channel();
thread::spawn(move || {
let val = String::from("hi");
tx.send(val).unwrap();
});
let received = rx.recv().unwrap();
println!("Got: {}", received); // Got: hi
}
2
3
4
5
6
7
8
9
10
11
12
13
14
子线程获得了主线程的发送者tx, 并调用了它的send方法发送了一个字符串, 然后主线程就通过对应的接受者rx接收到了.
# Rust 宏
Rust宏(Macros)是一种在编译时生成代码的强大工具, 它允许你在编写代码时创建自定义语法扩展. 宏(Macro)是一种在代码中进行元编程(Metaprogramming)的技术, 它允许在编译时生成代码, 宏可以帮助简化代码, 提高代码的可读性和可维护性, 同时允许开发者在编译时执行一些代码生成的操作.
宏在Rust中有两种类型: 声明式宏(Declarative Macros)和过程宏(Procedural Macros).
# 宏的定义
在Rust中, 使用macro_rules!关键字进行定义, 它们被称为 "macro_rules" 宏. 这种宏的定义是基于模式匹配的, 可以匹配代码的结构并根据匹配的模式生成相应的代码. 这样的宏在不引入新的语法结构的情况下, 可以用来简化一些通用的代码模式.
下面是一个简单的宏定义的例子:
// 宏的定义
macro_rules! greet {
// 模式匹配
($name: expr) => {
// 宏的展开
println!("Hello, {}!", $name);
};
}
fn main() {
// 调用宏
greet!("World");
}
2
3
4
5
6
7
8
9
10
11
12
13
说明:
- 模式匹配: 宏通过模式匹配来匹配传递给宏的代码片段, 模式是宏规则的左侧部分, 用于捕获不同的代码结构.
- 规则: 宏规则是一组由
$引导的模式和相应的展开代码, 规则由分号分隔. - 宏的展开: 当宏被调用时, 匹配的模式将被替换为相应的展开代码, 展开代码是宏规则的右侧部分.
理解Rust的声明式宏(macro_rules!), 最好的方式是把它想象成一个高级的代码生成器或编译时的"查找替换"工具. 它不像函数那样在运行时被调用, 而是在代码编译之前, 编译器先把宏"翻译"成真正的Rust代码.
可以通过greet!例子, 结合模具的比喻来拆解这三个概念:
- 模式匹配(Pattern Matching) -- "识别输入的模具"
在普通的match语句中, 我们匹配的是数据的值(比如数字1, 2, 3). 但在宏里, 我们匹配的是代码的语法结构.
宏定义中的($name: expr)就是一个模式.
$符号: 告诉编译器"这是一个变量", 用来捕获传入的代码片段.name: 给捕获到的代码片段起个名字(类似于函数参数名), 在宏的身体里可以用$name来引用它.:expr(Designator/指示符): 这是最关键的部分, 它告诉编译器"我要匹配什么样的语法结构".expr(Expression): 匹配表达式(如1+1,hello,func()).ident(Identifier): 匹配标识符(如变量名x, 函数名main).ty(Type): 匹配类型(如i32,String).
理解: 当写成greet!("World")时, 编译器会拿着"World"去跟模式($name:expr)比对.
- 编译器问:
"World"是一个表达式吗? - 答案: 是.
- 于是,
$name就捕获了"World"这个代码片段.
- 规则(Rules) -- "多功能的处理分支"
宏可以定义多条规则, 类似于match语句的多个分支, 每条规则由(模式) => { 代码块 };组成. 编译器会从上到下依次尝试匹配, 一旦匹配成功, 就停止尝试, 并使用该规则对应的代码块.
例子: 让宏支持两种用法:
macro_rules! say_hello {
// 规则A: 如果没有参数
() => {
println!("Hello, Stranger!");
};
// 规则B: 如果由一个表达式参数
($name: expr) => {
println!("Hello, {}!", $name);
};
}
fn main() {
say_hello!(); // 调用规则A
say_hello!("Alice"); // 调用规则B
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
理解: 规则就是宏的逻辑分支, 它允许同一个宏根据你传入代码样子的不同(是一个参数? 还是两个? 是括号? 还是大括号?), 生成完全不同的代码.
- 宏的展开(Macro Expansion) -- "代码替换"
这是宏工作的最后一步, 也是最本质的一步, 宏的展开发生在编译阶段. 当编译器看到greet!("World")并且匹配成功后, 它不会把greet!当作一个函数调用保留在二进制文件中. 相反, 它会把宏调用替换成规则右边{ ... }里的代码.
展开过程演示:
源代码:
fn main() {
greet!("World");
}
2
3
编译器在编译前, 实际上看到的是(展开后):
fn main() {
// $name 被替换成了 "World"
println!("Hello, {}!", "World");
}
2
3
4
下面是一个更复杂的例子, 演示了如何使用宏创建一个简单的vec!宏, 以便更方便地创建Vec:
// 宏的定义
macro_rules! vec {
// 基本情况, 空的情况
() => {
Vec::new()
};
// 递归情况, 处理一个或多个元素
($($element:expr),+ $(,)?) => {
{
let mut temp_vec = Vec::new();
$(
temp_vec.push($element);
)+
temp_vec
}
};
}
fn main() {
// 调用宏
let my_vec = vec![1, 2, 3,];
println!("{:?}", my_vec); // 输出: [1, 2, 3]
let emtpy_vec: Vec<i32> = vec![];
println!("{:?}", emtpy_vec); // 输出: []
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
在这个例子中, vec!宏使用了模式匹配, 以及($($element:expr), + $(,)?)这样的语法来捕获传递给宏的元素, 并用他们创建一个Vec. 注意, $(,)?)用于处理末尾的逗号, 使得在不同情况下都能正常工作.
在Rust的宏(macro_rules!)定义中, expr(表达式)和ident(标识符)是两种最常用的指示符(Designators). 它们的根本区别在于: ident是用来"命名"的, 而expr是用来"计算"或"求值"的.
以下是详细的对比和场景说明:
ident(Identifier / 标识符)- 定义: 代表一个名字, 它可以是变量名, 函数名, 结构体名, 模块名等.
- 特点: 它只是一个标签, 不包含运算逻辑.
- 典型例子:
x,my_variable,calculate,String,main. - 使用场景: 当你需要在宏里声明一个新的变量, 函数或结构体时.
示例: 创建一个变量: 如果你想写一个宏来生成一个变量, 你必须用ident, 因为变量名必须是一个合法的标识符.
macro_rules! create_var {
($name:ident) => {
let $name = 100; // 展开后变成: let x = 100;
};
}
fn main() {
create_var!(x); // 传入 'x' 作为名字
println!("{}", x); // 输出 100
}
2
3
4
5
6
7
8
9
10
如果这里用expr会怎样? 如果你传入1 + 1, 宏展开会变成let 1 + 1 = 100;, 这在Rust语法中是错误的.
expr(Expression / 表达式)- 定义: 代表一段可以被求值(计算出结果)的代码.
- 特点: 它运行后会产生一个值.
- 典型例子:
5,"hello",x + y,func(),if true { 1 } else { 0 }. - 使用场景: 当你需要把一个值传递给函数, 赋值给变量, 或者进行运算时.
# 过程宏
过程宏是一种更为灵活和强大的宏, 允许在编译时通过自定义代码生成过程来操作抽象语法树(AST). 过程宏在功能上更接近于函数, 但是它在编写和使用上更加复杂.
过程宏的类型:
- 派生宏(Derive Macros): 用于自动实现
trait(比如Copy, Debug)的宏 - 属性宏(Attribute Macros): 用于在声明上附加额外的元数据, 如
#[derive(Debug)]
过程宏的实现通常需要使用proc_macro库提供的功能, 例如TokenStream和TokenTree, 以便更直接地操纵源代码.
# Rust 智能指针
智能指针(Smart pointers)是一种在Rust中常见的数据结构, 它们提供了额外的功能和安全性保证, 以帮助管理内存和数据. 在Rust中, 智能指针是一种封装了对动态分配内存的所有权和生命周期管理的数据类型.
智能指针通常封装了一个原始指针, 并提供了一些额外的功能, 比如引用计数, 所有权转移, 生命周期管理等. 在Rust中, 标准库提供了几种常见的智能指针类型, 例如Box, Rc, Arc和RefCell.
# 智能指针的使用场景
- 当需要在堆上分配内存时, 使用
Box<T>. - 当需要多处共享所有权时, 使用
Rc<T>或Arc<T>. - 当需要内部可变性时, 使用
RefCell<T>. - 当需要线程安全的共享所有权时, 使用
Arc<T>. - 当需要互斥访问数据时, 使用
Mutex<T>. - 当需要读取-写入访问数据时, 使用
RwLock<T>. - 当需要解决循环引用问题时, 使用
Weak<T>.
# Box<T> 智能指针
Box<T>是Rust中最简单的智能指针之一, 它允许在堆上分配一块内存, 并将值存储在这个内存中. 由于Rust的所有权规则, 使用Box可以在堆上创建具有已知大小的数据.
let b = Box::new(5);
println!("b = {}", b);
2
# Rc<T> 智能指针
Rc<T>(引用计数指针)允许多个所有者共享数据, 它使用引用计数来跟踪数据的所有者数量, 并在所有者数量为零时释放数据. Rc<T>适用于单线程环境下的数据共享.
use std::rc::Rc;
let data = Rc::new(5);
let data_clone = Rc::clone(&data);
2
3
4
# Arc<T> 智能指针
Arc<T>(原子引用计数指针)与Rc<T>类似, 但是可以安全地在多线程环境中共享数据, 因为它使用原子操作来更新引用计数.
use std::sync::Arc;
let data = Arc::new(5);
let data_clone = Arc::clone(&data);
2
3
4
# RefCell<T> 智能指针
RefCell<T>允许在运行时检查借用规则, 它使用内部可变性来提供了一种安全的内部可变性模式, 允许在不可变引用的情况下修改数据. 但是, RefCell<T>只能用于单线程环境.
use std::cell::RefCell;
let data = RefCell::new(5);
let mut borrowed_data = data.borrow_mut();
*borrowed_data = 10;
2
3
4
5
# Mutex<T> 智能指针
Mutex<T>是一个互斥锁, 它保证了在任何时刻只有一个线程可以访问Mutex内部的数据.
use std::sync::Mutex;
let m = Mutex::new(5);
let mut data = m.lock().unwrap();
2
3
4
# RwLock<T> 智能指针
RwLock<T>是一种读-写锁, 允许多个读者同时访问数据, 但在写入时是排他的.
use std::sync::RwLock;
let lock = RwLock::new(5);
let read_guard = lock.read().unwrap();
2
3
4
# Weak<T> 智能指针
Weak<T>是Rc<T>的非拥有智能指针, 它不增加引用计数, 用于解决循环引用问题.
use std::rc::{Rc, Weak};
let five = Rc::new(5);
let weak_five = Rc::downgrade(&five);
2
3
4
# 智能指针的生命周期管理
智能指针可以帮助管理数据的生命周期, 当智能指针被销毁时, 它们会自动释放内存, 从而避免了内存泄漏和野指针的问题. 此外, 智能指针还允许在创建时指定特定的析构函数, 以实现自定义的资源管理.
下面是一个简单的Rust智能指针完整示例, 该示例使用Rc<T>智能指针实现了一个简单的引用计数功能, 并演示了多个所有者共享数据的情况.
// 引入所需的依赖库
use std::rc::Rc;
// 定义一个结构体, 用于存储数据
#[derive(Debug)]
struct Data {
value: i32,
}
// 主函数
fn main() {
// 创建一个 Rc 智能指针, 共享数据
let data: Rc<Data> = Rc::new(Data { value: 5 });
// 克隆 Rc 指针, 增加引用计数
let data_clone1 = Rc::clone(&data);
let data_clone2 = Rc::clone(&data);
// 输出数据的值和引用计数
println!("Data value: {}", data.value); // Data value: 5
println!("Reference count: {}", Rc::strong_count(&data)); // Reference count: 3
// 打印克隆后的 Rc 智能指针
println!("Cloned Data 1 : {:?}", data_clone1); // Cloned Data 1 : Data { value: 5 }
println!("Cloned Data 2 : {:?}", data_clone2); // Cloned Data 2 : Data { value: 5 }
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
以上代码中, 我们首先定义了一个Data结构体, 用于存储一个整数值, 然后在main函数中创建了一个Rc<Data>智能指针, 用于共享数据. 接着通过Rc::clone方法克隆了两个智能指针, 增加了数据的引用计数. 最后打印了数据的值, 引用计数和克隆后的智能指针. 运行该程序, 可以看到输出了数据的值和引用计数, 以及克隆后的智能指针. 由于Rc智能指针使用引用计数来跟踪数据的所有者数量, 因此在每次克隆时, 数据的引用计数会增加, 当所有者数量为零时, 数据会被自动释放.
# 总结
Rust的智能指针提供了一种安全和自动化的方式来管理内存和共享所有权. 智能指针是Rust中非常重要的一种数据结构, 它们提供了一种安全, 灵活和方便的内存管理方式, 帮助程序员避免了常见的内存安全问题, 提高了代码的可靠性和可维护性.
智能指针是Rust安全性模型的重要组成部分, 允许开发者编写低级代码而不必担心内存安全问题. 通过智能指针, Rust既保持了C语言的控制能力, 又避免了其风险.
# Rust 异步编程
# 异步编程简介
在现代编程中, 异步编程变得越来越重要, 因为它允许程序在等待I/O操作(如文件读写, 网络通信等)时不被阻塞, 从而提高性能和响应性. 异步编程是一种在Rust中处理非阻塞操作的方式, 允许程序在执行长时间的I/O操作时不被阻塞, 而是在等待的同时可以执行其他任务. Rust提供了多种工具和库来实现异步编程, 包括async和await关键字, futures和异步运行时(如tokio, async-std等), 以及其他辅助工具.
- Future: Future是Rust中表示异步操作的抽象, 它是一个可能还没有完成的计算, 将来某个时刻会返回一个值或一个错误.
- async/await: async关键字用于定义一个异步函数, 它返回一个Future, await关键字用于暂停当前Future的执行, 直到它完成.
实例: 以下示例展示了如何使用async和await关键字编写一个异步函数, 以及如何在异步函数中执行异步任务并等待其完成.
// 引入所需的依赖库
use tokio;
use tokio::time::{self, Duration};
// 异步函数, 模拟异步任务
async fn async_task() -> i32 {
// 模拟异步操作, 等待 1 秒钟
time::sleep(Duration::from_secs(1)).await;
// 返回结果
42
}
// 异步任务执行函数
async fn execute_async_task() {
// 调用异步任务并等待结果
let result = async_task().await;
// 输出结果
println!("Asynchronous task result: {}", result); // Asynchronous task result: 42
}
// 主函数
#[tokio::main]
async fn main() {
println!("Starting asynchronous task...");
// 执行异步任务
execute_async_task().await;
println!("Asynchronous task completed.");
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
Rust的标准库不含tokio, 需要手动将它添加到Cargo.toml的[dependencies]部分. 为了支持代码中用到的功能(macros用于#[tokio::main], rt-multi-thread用于运行时, time用于sleep), 需要添加full特性或者单独开启这些特性.
在Cargo.toml中添加如下内容:
[dependencies]
tokio = { version = "1", features = ["full"] }
2
或者, 如果你只想启用最基础的必要特性(更轻量):
[dependencies]
tokio = { version = "1", features = ["macros", "rt-multi-thread", "time"] }
2
添加后, 保存文件, VSCode通常会自动运行cargo check下载依赖, 或者可以手动运行cargo build.
上面的代码是一个标准的Rust异步编程(Asynchronous Programming)入门示例, 使用了Rust生态中最流行的一部运行时库Tokio. 它的主要功能是模拟一个耗时的操作(如网络请求或数据库查询), 并在不阻塞线程的情况下等待其完成. 以下是详细的代码分析:
核心组件分析
#[tokio::main]宏
#[tokio::main] async fn main() { ... }1
2- 作用: Rust的原生
main函数不能是async的, 这个宏是一个语法糖, 它在编译时将你的async fn main转换为一个普通的同步fn main, 并在其中初始化Tokio运行时(Runtime), 然后通过block_on来运行你的异步代码. - 意义: 它是异步世界的入口
async fn(异步函数)
async fn async_task() -> i32 { ... }1- 定义: 使用
async关键字定义的函数, 调用时不会立即执行函数体内的代码. - 返回值: 它会立即返回一个实现了
Futuretrait的对象(一个"未来"), 只有当这个Future被执行器(Executor)轮询(poll)时, 代码才会真正运行.
.await(等待)
time::sleep(Duration::from_secs(1)).await; let result = async_task().await;1
2- 作用:
.await是异步编程的核心. 它告诉运行时: "暂停当前任务, 直到被调用的这个Future完成". - 非阻塞: 在等待期间, 当前线程不会被阻塞(即线程不会傻傻地停在那里). Tokio运行时可以利用这段空闲时间去处理其他任务(虽然这个简单的单任务示例中体现不明显, 但在高并发场景下这是性能的关键).
tokio::time::sleepvsstd::thread::sleep
time::sleep(Duration::from_secs(1)).await;1- 关键点: 这里使用的是
tokio::time::sleep, 而不是标准的std::thread::sleep.std::thread::sleep: 会让整个操作系统线程挂起, 线程无法做任何其他事情. 在异步代码中绝对禁止使用.tokio::time::sleep: 只是让当前的任务(Task)让出CPU控制权, 现成依然是活跃的, 可以去处理别的任务.
执行流程梳理
- 启动: 程序进入
main函数, 打印"Starting asynchronous task...". - 调用:
main调用execute_async_task(). - 嵌套调用:
execute_async_task调用async_task(). - 挂起:
async_task内部遇到了time::sleep(...).await.- 任务被挂起1秒钟, 此时控制权交给Tokio运行时.
- 恢复:
- 1秒钟后, 计时器到期, Tokio唤醒任务.
async_task继续执行, 返回42.
- 输出:
execute_async_task拿到结果42.- 打印
"Asynchronous task result: 42".
- 结束:
- 回到
main函数. - 打印
"Asynchronous task completed.. - 程序退出.
- 回到
- 启动: 程序进入
上面的例子演示了Rust中使用async和await关键字编写异步函数, 以及如何在异步函数中执行异步任务并等待其完成. 以下示例使用tokio库执行异步HTTP请求, 并输出响应结果:
// 引入所需的依赖库
use std::error::Error;
use tokio::runtime::Runtime;
use reqwest::get;
// 异步函数, 用于执行 HTTP GET 请求并返回响应结果
async fn fetch_url(url: &str) -> Result<String, Box<dyn Error>> {
let response = get(url).await?;
let body = response.text().await?;
Ok(body)
}
// 异步任务执行函数
async fn execute_async_task() -> Result<(), Box<dyn Error>> {
// 发起异步 HTTP GET 请求
let url = "https://jsonplaceholder.typicode.com/posts/1";
let result = fetch_url(url).await?;
// 输出响应结果
println!("Response: {}", result);
Ok(())
}
// 主函数
fn main() {
// 创建异步运行时
let rt = Runtime::new().unwrap();
// 在异步运行时中执行异步任务
let result = rt.block_on(execute_async_task());
// 处理异步任务执行结果
match result {
Ok(_) => println!("Asynchronous task completed successfully."),
Err(e) => eprintln!("Error occurred: {}", e),
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
以上代码, 我们首先引入了tokio和reqwest库, 分别用于执行异步任务和进行HTTP请求. 然后定义了一个异步函数fetch_url, 用于执行异步的HTTP GET请求, 并返回响应结果. 接着定义了一个异步任务执行函数execute_async_task, 该函数在其中发起了异步HTTP请求, 并输出响应结果. 最后, 在main函数中创建了一个tokio异步运行时, 并在其中执行了异步任务, 处理了异步任务的执行结果.
Reading package lists... Done
Building dependency tree... Done
Reading state information... Done
pkg-config is already the newest version (1.8.1-2build1).
Some packages could not be installed. This may mean that you have
requested an impossible situation or if you are using the unstable
distribution that some required packages have not yet been created
or been moved out of Incoming.
The following information may help to resolve the situation:
The following packages have unmet dependencies:
libssl-dev : Depends: libssl3t64 (= 3.0.13-0ubuntu3) but 3.0.13-0ubuntu3.4 is to be installed
E: Unable to correct problems, you have held broken packages.
2
3
4
5
6
7
8
9
10
11
12
13
这是一个典型的Ubunt/Debian依赖版本冲突问题. 错误信息提示: 系统已经安装了较新版本的libssl3t64(3.0.13-0ubuntu3.4), 但libssl-dev却依赖旧版本的libssl3t64(3.0.13-0ubuntu3). 这通常是因为系统进行了部分更新, 或者软件源索引不一致导致的.
步骤1: 尝试修复损坏的包并更新, 这通常能解决大部分版本不匹配的问题.
sudo apt update
sudo apt install -f
sudo apt upgrade
2
3
步骤2: 使用aptitude智能解决冲突(推荐), 如果步骤1无效, aptitude通常比apt-get更聪明, 能找到降级或升级的方案.
# 安装 aptitude (如果没有)
sudo apt install aptitude
// 尝试安装 libssl-dev
sudo aptitude install libssl-dev
2
3
4
注意: 它会给出一个解决方案, 如果第一个方案是"Keep the following packages at their current version" (保持现状, 即不安装), 请输入 n. 它随后会提供第二个方案(通常是降级(libssl3t64)到匹配的版本), 此时输入 y.
步骤3: 如果以上都失败, 尝试强制安装特定的版本, 既然系统里已经是3.0.13-ubuntu3.4, 我们可以尝试让系统把所有相关包都对齐到最新版.
sudo apt install libssl-dev libssl3t64
# 或者尝试重装 libssl3t64
sudo apt install --reinstall libssl3t64=3.0.13-0ubuntu3.4
2
3
备选方案: 绕过 OpenSSL 依赖 (使用 rustls), 如果不想折腾系统的 OpenSSL 库, 可以让 Rust 使用 rustls (纯Rust实现的TLS库)而不是 openssl, 这通常能直接绕过这个问题. 修改 Cargo.toml:
[package]
name = "greeting"
version = "0.1.0"
edition = "2024"
[dependencies]
itertools = "0.14.0"
tokio = { version = "1", features = ["full"] }
reqwest = { version = "0.12.24", features = ["json", "rustls-tls"], default-features = false}
2
3
4
5
6
7
8
9
# 异步编程说明
# async 关键字
async 关键字用于定义异步函数, 即返回 Future 或 impl Future 类型的函数. 异步函数执行时会返回一个未完成的 Future 对象, 它表示一个尚未完成的计算或操作. 异步函数可以包含 await 表达式, 用于等待其他异步操作的完成.
async fn hello() -> String {
"Hello, world!".to_string()
}
2
3
# await 关键字
await 关键字用于等待异步操作的完成, 并获取其结果. await 表达式只能在异步函数或异步块中使用, 它会暂停当前的异步函数执行, 等待被等待的 Future 完成, 然后继续执行后续的代码.
async fn print_hello() {
let result = hello().await;
println!("{}", result);
}
2
3
4
# 异步函数返回值
异步函数的返回值类型通常是impl Future<Output = T>, 其中 T 是异步操作的结果类型. 由于异步函数的返回值是一个Future, 因此可以使用.await来等待异步操作的完成, 并获取其结果.
async fn add(a: i32, b: i32) -> i32 {
a + b
}
2
3
# 异步块
除了定义异步函数外, Rust还提供了异步块的语法, 可以在同步代码中使用异步操作. 异步块由 async {} 构成, 其中可以包含异步函数调用和 await 表达式.
async {
let result1 = hello().await;
let result2 = add(1, 2).await;
println!("Result: {}, {}", result1, result2);
};
2
3
4
5
# 异步任务执行
在Rust中, 异步任务通常需要在执行上下文中运行, 可以使用tokio::main, async-std的task::block_on或futures::executor::block_on等函数来执行异步任务. 这些函数会接受一个异步函数或异步块, 并在当前线程或执行环境中执行它.
use async_std::task;
fn main() {
task::block_on(print_hello());
}
2
3
4
5
# 错误处理
await 后面跟一个 ? 操作符可以传播错误. 如果 await 的 Future 完成时返回了一个错误, 那么这个错误会被传播到调用者.
async fn my_async_function() -> Result<(), MyError> {
some_async_operation().await?;
// 如果 some_async_operation 出错, 错误会被传播
}
2
3
4
# 异步 trait 方法
Rust允许为trait定义异步方法, 这使得你可以为不同的类型的对象定义异步操作.
trait MyAsyncTrait {
async fn async_method(&self) -> Result<(), MyError>;
}
impl MyAsyncTrait for MyType {
async fn async_method(&self) -> Result<(), MyError> {
// 异步逻辑
}
}
2
3
4
5
6
7
8
9
# 异步上下文
在Rust中, 异步代码通常在异步运行时(如Tokio或async-std)中执行, 这些运行时提供了调度和执行异步任务的机制.
#[tokio::main]
async fn main() {
some_async_operation().await;
}
2
3
4
以上代码中, #[tokio::main]属性宏将main函数包装在一个异步运行时中.
# 异步宏
Rust提供了一些异步宏, 如tokio::spawn, 用于在异步运行时中启动新的异步任务.
#[tokio::main]
async fn main() {
let handle = tokio::spawn(async {
// 异步逻辑
});
handle.await.unwrap();
}
2
3
4
5
6
7
# 异步 I/O
Rust的标准库提供了异步I/O操作, 如tokio::fs::File和async_std::fs::File.
use tokio::fs::File;
use tokio::io::{self, AsyncReadExt};
#[tokio::main]
async fn main() -> io::Result<()> {
let mut file = File::open("file.txt").await?;
let mut contents = String::new();
file.read_to_string(&mut contents).await?;
println!("Contents: {}", contents);
Ok(())
}
2
3
4
5
6
7
8
9
10
11
# 异步通道
Rust的一些异步运行时提供了异步通道(如tokio::sync::mpsc), 允许在异步任务之间传递消息.
use tokio::sync::mpsc;
use tokio::spawn;
#[tokio::main]
async fn main() {
let (tx, mut rx) = mpsc::channel(32);
let child = spawn(async move {
let response = "Hello, world!".to_string();
tx.send(response).await.unwrap();
});
let response = rx.recv().await.unwrap();
println!("Received: {}", response);
child.await.unwrap();
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 总结
Rust的异步编程模型async/await提供了一种简洁, 高效的方式来处理异步操作. 它允许开发者以一种更自然和直观的方式来处理异步操作, 同时保持了Rust的安全性和性能. 通过async/await, Rust为异步编程提供了一流的语言支持, 使得编写高效且可读性强的异步程序变得更加容易.
- Rust 简介
- Rust 语言的特点
- Rust 的应用
- 第一个Rust程序
- 参考链接
- Rust 环境搭建
- 搭建Visual Studio Code开发环境
- Cargo 教程
- Cargo 是什么
- Cargo 主要特性和功能
- Cargo 功能
- 在VSCode中配置Rust工程
- 在VSCode中调试Rust
- Rust 输出到命令行
- Rust 基础语法
- 变量
- 常量与不可变变量的区别
- 数据类型
- 函数
- 控制流
- 所有权(Ownership)
- 结构体(Structs)
- 枚举(Enums)
- 模式匹配(match)
- 错误处理
- 所有权与借用的声明周期
- 重影(Shadowing)
- Rust 运算符
- 算术运算符
- 关系(比较)运算符
- 逻辑运算符
- 位运算符
- 赋值与复合赋值运算符
- 其他常见运算符
- Rust 数据类型
- 整数型(Integer)
- 浮点数型(Floating-Point)
- 数学运算
- 布尔型
- 字符型
- 复合类型
- Rust 注释
- 用于说明文档的注释
- Rust 函数
- 函数参数
- 函数体的语句和表达式
- 函数返回值
- Rust 条件语句
- Rust 循环
- while 循环
- for 循环
- loop 循环
- Rust 迭代器
- 创建迭代器
- 迭代器方法
- 使用for循环遍历迭代器
- 消耗型适配器
- 适配器
- 迭代器链
- 收集器
- 惰性求值
- 自定义迭代器
- 并行迭代器
- 迭代器和声明周期
- 迭代器与闭包
- 迭代器和性能
- 实例
- Rust迭代器方法
- 总结
- Rust 闭包
- Rust 闭包简介
- 捕获外部变量
- 闭包的特性
- 更多应用说明
- 总结
- Rust 所有权
- Rust 所有权简介
- Rust 内存和分配
- Rust 变量与数据交互的方式
- 移动
- 克隆
- 涉及函数的所有权机制
- 函数返回值的所有权机制
- 引用与租借
- Rust Slice (切片)类型
- 字符串切片
- 非字符串切片
- Rust 结构体
- 结构体简介
- 结构体所有权
- 结构体关联函数
- Rust 枚举类
- Option 枚举类
- Rust 组织管理
- Rust 组织管理简介
- 访问权限
- 难以发现的模块
- use 关键字
- 引用标准库
- Rust 错误处理
- 不可恢复错误
- 可恢复错误
- 可恢复的错误的传递
- kind 方法
- Rust 泛型与特性
- Rust 泛型简介
- Rust 特性
- Rust 生命周期
- 生命周期注释
- 结构体中使用字符串切片引用
- 静态生命周期
- 泛型, 特性与生命周期协同作战
- Rust 文件与IO
- 接收命令行参数
- 命令行输入
- 文件读取
- 文件写入
- Rust 集合与字符串
- 向量
- 字符串
- 映射表
- Rust 面相对象
- 封装
- 继承
- Rust 并发编程
- 线程
- join 方法
- move 强制所有权转移
- 消息传递
- Rust 宏
- 宏的定义
- 过程宏
- Rust 智能指针
- 智能指针的使用场景
- Box<T> 智能指针
- Rc<T> 智能指针
- Arc<T> 智能指针
- RefCell<T> 智能指针
- Mutex<T> 智能指针
- RwLock<T> 智能指针
- Weak<T> 智能指针
- 智能指针的生命周期管理
- 总结
- Rust 异步编程
- 异步编程简介
- 异步编程说明
- 总结