
FastAPI 高级用户指南
# 路径操作的高级配置
# OpenAPI 的 operationId
如果你并非OpenAPI的专家, 你可能不需要这部分内容.
你可以在路径操作中通过参数operation_id设置要使用的OpenAPIoperationId. 务必确保每个操作路径的operation_id都是唯一的.
from fastapi import FastAPI
app = FastAPI()
@app.get("/items/", operation_id="some_specific_id_you_define")
async def read_items():
return [{"item_id": "Foo"}]
2
3
4
5
6
7
8
# 使用 路径操作函数 的函数名作为 operationId
如果你想用你的API的函数名作为operationId的名字, 你可以遍历一遍API的函数名, 然后使用他们的APIRoute.name重写每个路径操作的operation_id. 你应该在添加了所有路径操作之后执行此操作.
from fastapi import FastAPI
from fastapi.routing import APIRoute
app = FastAPI()
@app.get("/items/")
async def read_items():
return [{"item_id": "Foo"}]
def use_route_names_as_operation_ids(app: FastAPI) -> None:
"""
Simplify operation IDs so that generated API clients have simpler function names.
Should be called only aflter all routes have been added.
"""
for route in app.routes:
if isinstance(route, APIRoute):
route.operation_id = route.name # in this case, 'read_item'
use_route_names_as_operation_ids(app)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
如果你手动调用app.openapi(), 你应该在此之前更新operationId.
如果你这样做, 务必确保你的每个路径操作函数的名字唯一. 即使它们在不同的模块中(Python 文件).
# 从 OpenAPI 中排除
使用参数include_in_scheme并将其设置为False, 来从生成的OpenAPI方案中排除一个路径操作(这样一来, 就从自动化文档系统中排除掉了).
from fastapi import FastAPI
app = FastAPI()
@app.get("/items/", include_in_schema=False)
async def read_items():
return [{"item_id": "Foo"}]
2
3
4
5
6
7
8
# docstring的高级用途
你可以限制路径操作函数的docstring中用于OpenAPI的行数. 添加一个\f(一个换页的转义字符)可以使FastAPI在那一位置截断用于OpenAPI的输出. 剩余部分不会出现在文档中, 但是其他工具(比如Sphinx)可以使用剩余部分.
from typing import Set, Union
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
name: str
description: Union[str, None] = None
price: float
tax: Union[float, None] = None
tags: Set[str] = set()
@app.post("/items/", response_model=Item, summary="Create an item")
async def create_item(item: Item):
"""
Create an item with all the information:
- **name**: each item must have a name
- **description**: a long description
- **price**: required
- **tax**: if the item doesn't have tax, you can omit this
- **tags**: a set of unique tag strings for this item
\f
:param item: User input
"""
return item
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
# 额外的状态码
FastAPI默认使用JSONResponse返回一个响应, 将你的路径操作中的返回内容放到该JSONResponse中. FastAPI会自动使用默认的状态码或者使用你在路径操作中设置的状态码.
# 额外的状态码
如果你想要返回主要状态之外的状态码, 你可以通过直接返回一个Response来实现, 比如JSONResponse, 然后直接设置额外的状态码. 例如, 假设你想有一个路径操作能够更新条目, 并且更新成功时返回200(成功)的HTTP状态码. 但是你也希望它能够接受新的条目. 并且当这些条目不存在时, 会自动创建并返回201(创建)的HTTP状态码.
要实现它, 导入JSONResponse, 然后在其中直接返回你的内容, 并将status_code设置为你要的值.
from typing import Union
from fastapi import Body, FastAPI, status
from fastapi.responses import JSONResponse
app = FastAPI()
items = {"foo": {"name": "Fighters", "size" 6}, "bar": {"name": "Tenders", "size": 3}}
@app.put("/items/{item_id}")
async def upsert_item(
item_id: str,
name: Union[str, None] = Body(default=None),
size: Union[int, None] = Body(default=None),
):
if item_id in items:
item = items[item_id]
item["name"] = name
item["size"] = size
return item
else:
item = {"name": name, "size": size}
items[item_id] = item
return JSONResponse(status_code=status.HTTP_201_CREATED, content=item)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
当你直接返回一个像上面例子中的Response对象时, 它会直接返回. FastAPI不会用模型等对给响应进行序列化. 确保其中有你想要的数据, 且返回的值为合法的JSON(如果你使用JSONResponse的话).
技术细节
你也可以使用from starlette.responses import JSONResponse.
出于方便, FastAPI为开发者提供同starlette.responses一样的fastapi.responses. 但是大多数可用的响应都是直接来自Starlette. status也是一样.
# OpenAPI 和 API 文档
如果你直接返回额外的状态码和响应, 它们不会包含在OpenAPI方案(API文档)中, 因为FastAPI没办法预先知道你要返回什么.
但是你可以使用额外的响应在代码中记录这些内容.
# 直接返回响应
当你创建一个FastAPI路径操作时, 你可以正常返回以下任意一种数据: dict, list, Pydantic模型, 数据库模型等等.
FastAPI默认会使用jsonable_encoder将这些类型的返回值转换成JSON格式, jsonable_encoder在JSON兼容编码器有阐述.
然后, FastAPI会在后台将这些兼容JSON的数据(比如字典)放到一个JSONResponse中, 该JSONResponse会用来发送响应给客户端. 但是你可以在你的路径操作中直接返回一个JSONResponse. 直接返回响应可能会有用处, 比如返回自定义的响应头和cookies.
# 返回Response
事实上, 可以返回任意Response或者任意Response的子类.
JSONResponse本身是一个Response的子类.
当你返回一个Response时, FastAPI会直接传递它. FastAPI不会用Pydantic模型做任何数据转换, 不会将响应内容转换成任何类型, 等等. 这种特性给你极大的可扩展性. 你可以返回任何数据类型, 重写任何数据声明或者校验, 等等.
# 在Response中使用jsonable_encoder
由于FastAPI并未对你返回的Response做任何改变, 你必须确保你已经准备好响应内容. 例如, 如果不首先将Pydantic模型转换为dict, 并将所有数据类型(如datetime, UUID等)转换为兼容JSON的类型, 则不能将其放入JSONResponse中.
对于这些情况, 在将数据传递给响应之前, 你可以使用jsonable_encoder来转换你的数据.
from datetime import datetime
from typing import Union
from fastapi import FastAPI
from fastapi.encoders import jsonable_encoder
from fastapi.responses import JSONResponse
from pydantic import BaseModel
class Item(BaseModel):
title: str
timestamp: datetime
description: Union[str, None] = None
app = FastAPI()
@app.put("/items/{id}")
def update_item(id: str, item: Item):
json_compatible_item_data = jsonable_encoder(item)
return JSONResponse(content=json_compatible_item_data)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
技术细节
你也可以使用from starlette.responses import JSONResponse.
出于方便, FastAPI会提供与starlette.response相同的fastapi.responses给开发者, 但是大多数可用的响应都直接来自Starlette.
# 返回自定义Response
上面的例子展示了需要的所有部分, 但还不够实用, 因为你本可以只是直接返回item, 而FastAPI默认帮你把这个item放到JSONResponse中, 又默认将其转换成了dict等等.
现在, 让我们看看如何才能返回一个自定义的响应.
假设你想要返回一个XML响应. 你可以把XML内容放到一个字符串中, 放到一个Response中, 然后返回.
from fastapi import FastAPI, Response
app = FastAPI()
@app.get("/legacy/")
def get_legacy_data():
data = """<?xml version="1.0"?>
<shampoo>
<Header>
Apply shampoo here.
</Header>
<Body>
You'll have to use soap here.
</Body>
</shampoo>
"""
return Response(content=data, media_type="application/xml")
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# 说明
当你直接返回Response时, 它的数据既没有校验, 又不会进行转换(序列化), 也不会自动生成文档. 但是你仍可以参考OpenAPI中的额外响应给响应编写文档. 在后续的章节中可以了解如何使用/声明这些自定义的Response的同时还保留自动化的数据转换和文档等.
# 自定义响应 -- HTML, 流, 文件和其他
FastAPI默认使用JSONResponse返回响应. 你可以通过直接返回Response来重载它, 参见直接返回响应. 但是如果你直接返回Response, 返回数据不会自动转换, 也不会自动生成文档(例如, 在HTTP头Content-Type中包含特定的媒体类型作为生成的OpenAPI的一部分).
你还可以在路径操作装饰器中声明你想用的Response. 你从路径操作函数中返回的内容将被放在该Response中. 并且如果该Response有一个JSON媒体类型(application/json), 比如使用JSONResponse或者UJSONResponse的时候, 返回的数据将使用你在路径操作装饰器中声明的任何Pydantic的response_model自动转换(和过滤).
说明
如果你使用不带有任何媒体类型的响应类, FastAPI认为你的响应没有任何内容, 所以不会在生成的OpenAPI文档中记录响应格式.
# 使用ORJSONResponse
例如, 如果你需要压榨性能, 你可以安装并使用orjson并将响应设置为ORJSONResponse. 导入你想要使用的Response类(子类)然后在路径操作装饰器中声明它.
from fastapi import FastAPI
from fastapi.responses import ORJSONResponse
app = FastAPI()
@app.get("/items/", response_class=ORJSONResponse)
async def read_items():
return ORJSONResponse([{"item_id": "Foo"}])
2
3
4
5
6
7
8
9
提示
参数response_class也会用来定义响应的媒体类型. 在这个例子中, HTTP头的Content-Type会被设置成application/json. 并且在OpenAPI文档中也会这样记录.
ORJSONResponse目前只在FastAPI中可用, 而在Starlette中不可用.
# HTML响应
使用HTMLResponse来从FastAPI中直接返回一个HTML响应.
- 导入
HTMLResponse. - 将
HTMLResponse作为你的路径操作的response_class参数传入.
from fastapi import FastAPI
from fastapi.responses import HTMLResponse
app = FastAPI()
@app.get("/items/", response_class=HTMLResponse)
async def read_items():
return """
<html>
<head>
<title>Some HTML in here</title>
</head>
<body>
<h1>Look ma! HTML!</h1>
</body>
</html>
"""
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# 返回一个Response
正如你在直接返回响应中了解到的, 你也可以通过直接返回响应在路径操作中直接重载响应.
和上面一样的例子, 返回一个HTMLResponse看起来可能是这样:
from fastapi import FastAPI
from fastapi.responses import HTMLResponse
app = FastAPI()
@app.get("/items/")
async def read_items():
html_content = """
<html>
<head>
<title>Some HTML in here</title>
</head>
<body>
<h1>Look ma! HTML!</h1>
</body>
</html>
"""
return HTMLResponse(content=html_content, status_code=200)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
路径操作函数直接返回的Response不会被OpenAPI的文档记录(比如, Content-Type不会被文档记录), 并且在自动化文档中也是不可见的.
当然, 实际的Content-Type头, 状态码等等, 将来自于你返回的Response对象.
# OpenAPI中的文档和重载Response
如果你想要在函数内重载响应, 但是同时在OpenAPI中文档化媒体类型, 你可以使用response_class参数并返回一个Response对象. 接着response_class参数只会被用来文档化OpenAPI的路径操作, 你的Response用来返回响应.
# 直接返回HTMLResponse
比如像这样:
from fastapi import FastAPI
from fastapi.responses import HTMLResponse
app = FastAPI()
def generate_html_response():
html_content = """
<html>
<head>
<title>Some HTML in here</title>
</head>
<body>
<h1>Look ma! HTML!</h1>
</body>
</html>
"""
return HTMLResponse(content=html_content, status_code=200)
@app.get("/items/", response_class=HTMLResponse)
async def read_item():
return generate_html_response()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
在这个例子中, 函数generate_html_response()已经生成并返回Response对象而不是在str返回HTML. 通过返回函数generate_html_response()的调用结果, 你已经返回一个重载FastAPI默认行为的Response对象, 但如果你在response_class中也传入了HTMLResponse, FastAPI会知道如何在OpenAPI和交互式文档中使用text/html将其文档化为HTML.
# 可用响应
这里有一些可用的响应. 要记得你可以使用Response来返回任何其他东西, 甚至创建一个自定义的子类.
技术细节
你也可以使用from starlette.responses import HTMLResponse.
FastAPI提供了同fastapi.responses相同的starlette.responses只是为了方便开发者. 但大多数可用的响应都直接来自Starlette.
# Response
其他全部的响应都继承自主类Response. 你可以直接返回它. Response类接受如下参数:
content: 一个str或者bytes.status_code: 一个int类型的HTTP状态码.headers: 一个由字符串组成的dict.media_type: 一个给出媒体类型的str, 比如text/html.
FastAPI(实际上是Starlette)将自动包含Content-Length的头. 它还将包含一个基于media_type的Content-Type头, 并为文本类型附加一个字符集.
from fastapi import FastAPI, Response
app = FastAPI()
@app.get("/legacy/")
def get_legacy_data():
data = """<?xml version="1.0"?>
<shampoo>
<Header>
Apply shampoo here.
</Header>
<Body>
You'll have to use soap here.
</Body>
</shampoo>
"""
return Response(content=data, media_type="application/xml")
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# HTMLResponse
如上文所述, 接收文本或字节并返回HTML响应.
# PlainTextResponse
接受文本或字节并返回纯文本响应.
from fastapi import FastAPI
from fastapi.responses import PlainTextResponse
app = FastAPI()
@app.get("/", response_class=PlainTextResponse)
async def main():
return "Hello World"
2
3
4
5
6
7
8
9
# JSONResponse
接受数据并返回一个application/json编码的响应. 如上文所述, 这是FastAPI中使用的默认响应.
# ORJSONResponse
如上文所述, ORJSONResponse是一个使用orjson的快速的可选JSON响应.
# UJSONResponse
UJSONResponse是一个使用ujson的可选JSON响应.
在处理某些边缘情况时, ujson不如Python的内置实现那么谨慎.
from fastapi import FastAPI
from fastapi.responses import UJSONResponse
app = FastAPI()
@app.get("/items/", response_class=UJSONResponse)
async def read_items():
return [{"item_id": "Foo"}]
2
3
4
5
6
7
8
9
ORJSONResponse可能是一个更快的选择.
# RedirectResponse
返回HTTP重定向, 默认情况下使用307状态代码(临时重定向).
from fastapi import FastAPI
from fastapi.responses import RedirectResponse
app = FastAPI()
@app.get("/typer")
async def redirect_typer():
return RedirectResponse("https://typer.tiangolo.com")
2
3
4
5
6
7
8
9
# StreamingResponse
采用异步生成器或普通生成器/迭代器, 然后流失传输响应主体.
from fastapi import FastAPI
from fastapi.responses import StreamingResponse
app = FastAPI()
async def fake_video_streamer():
for i in range(10):
yield b"some fake video bytes"
@app.get("/")
async def main():
return StreamingResponse(fake_video_streamer())
2
3
4
5
6
7
8
9
10
11
12
13
14
# 对类似文件的对象使用StreamingResponse
如果你有类似文件的对象(例如, 由open()返回的对象), 则可以在StreamingResponse中将其返回. 包括许多云存储, 视频处理等交互的库.
from fastapi import FastAPI
from fastapi.responses import StreamingResponse
some_file_path = "large-video-file.mp4"
app = FastAPI()
@app.get("/")
def main():
def iterfile(): # (1)
with open(some_file_path, mode='rb') as file_like: # (2)
yield from file_like # (3)
retrun StreamingResponse(iterfile(), media_type="video/mp4")
2
3
4
5
6
7
8
9
10
11
12
13
14
注意这里, 因为我们使用的是不支持async和await的标准open(), 我们使用普通的def声明了路径操作.
# FileResponse
异步传输文件作为响应. 与其他响应类型相比, 接受不同的参数集进行实例化:
path: 要流式传输的文件的文件路径.headers: 任何自定义响应头, 传入字典类型.media_type: 给出媒体类型的字符串. 如果未设置, 则文件名或路径将用于推断媒体类型.filename: 如果给出, 它将包含在响应的Content-Disposition中.
文件响应将包含适当的Content-Length, Last-Modified和ETag的响应头.
from fastapi import FastAPI
from fastapi.responses import FileResponse
some_file_path = "large-video-file.mp4"
app = FastAPI()
@app.get("/")
async def main():
return FileResponse(some_file_path)
2
3
4
5
6
7
8
9
10
# 额外文档
你还可以使用response在OpenAPI中声明媒体类型和许多其他详细信息: OpenAPI中的额外文档.
# OPENAPI中的其他响应
你可以声明附加响应, 包括附加状态代码, 媒体类型, 描述等. 但是对于那些额外的响应, 你必须确保你直接返回一个像JSONResponse一样的Response, 并包含你的状态代码和内容.
# model附加响应
你可以像路径操作装饰器传递参数responses. 它接收一个dict, 键是每个响应的状态代码(如200), 值是包含每个响应信息的其他dict. 每个响应字典都可以有一个关键模型, 其中包含一个Pydantic模型, 就像response_model一样. FastAPI将采用该模型, 生成其JSON Schema并将其包含在OpenAPI中的正确位置. 例如, 要声明一个具有状态码404和Pydantic模型Message的响应, 可以写:
from fastapi import FastAPI
from fastapi.responses import JSONResponse
from pydantic import BaseModel
class Item(BaseModel):
id: str
value: str
class Message(BaseModel):
message: str
app = FastAPI()
@app.get("/items/{item_id}", response_model=Item, responses={404: {"model": Message}})
async def read_item(item_id: str):
if item_id == "foo":
return {"id": "foo", "value": "there goes my hero"}
return JSONResponse(status_code=404, content={"message": "Item not found"})
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
请记住, 你必须直接返回JSONResponse.
The model key is not part of OpenAPI.
FastAPI will take the Pydantic model from there, generate the JSON Schema, and put it in the correct place.
The correct place is:
- In the key
content, that has as value another JSON object (dict) that contains:- A key with the media type, e.g.
application/json, that contains as value another JSON object, that contains:- A key
schema, that has as the value the JSON Schema from the model, here's the correct place.- FastAPI adds a reference here to the global JSON Schemas in another place in your OpenAPI instead of including it directly. This way, other applications and clients can use those JSON Schemas directly, provide better code generation tools, etc.
- A key
- A key with the media type, e.g.
在OpenAPI中为该路径操作生成的响应将是:
{
"responses": {
"404": {
"description": "Additional Response",
"content": {
"application/json": {
"schema": {
"$ref": "#/components/schemas/Message"
}
}
}
},
"200": {
"description": "Successful Response",
"content": {
"application/json": {
"schema": {
"$ref": "#/components/schemas/Item"
}
}
}
},
"422": {
"description": "Validation Error",
"content": {
"application/json": {
"schema": {
"$ref": "#/components/schemas/HTTPValidationError"
}
}
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
模式被引用到OpenAPI模式中的另一个为止:
{
"components": {
"schemas": {
"Message": {
"title": "Message",
"required": [
"message"
],
"type": "object",
"properties": {
"message": {
"title": "Message",
"type": "string"
}
}
},
"Item": {
"title": "Item",
"required": [
"id",
"value"
],
"type": "object",
"properties": {
"id": {
"title": "Id",
"type": "string"
},
"value": {
"title": "Value",
"type": "string"
}
}
},
"ValidationError": {
"title": "ValidationError",
"required": [
"loc",
"msg",
"type"
],
"type": "object",
"properties": {
"loc": {
"title": "Location",
"type": "array",
"items": {
"type": "string"
}
},
"msg": {
"title": "Message",
"type": "string"
},
"type": {
"title": "Error Type",
"type": "string"
}
}
},
"HTTPValidationError": {
"title": "HTTPValidationError",
"type": "object",
"properties": {
"detail": {
"title": "Detail",
"type": "array",
"items": {
"$ref": "#/components/schemas/ValidationError"
}
}
}
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
# 主响应的其他媒体类型
你可以使用相同的responses参数为相同的主响应添加不同的媒体类型. 例如, 你可以添加一个额外的媒体类型image/png, 声明你的路径操作可以返回JSON对象(媒体类型application/json)或PNG图像:
from typing import Union
from fastapi import FastAPI
from fastapi.responses import FileResponse
from pydantic import BaseModel
class Item(BaseModel):
id: str
value: str
app = FastAPI()
@app.get(
"/items/{item_id}",
response_model=Item,
responses={
200: {
"content": {
"image/png": {}
},
"description": "Return the JSON item or an image.",
}
},
)
async def read_item(item_id: str, img: Union[bool, None] = None):
if img:
return FileResponse("image.png", media_type="image/png")
else:
return {"id": "foo", "value": "there goes my hero"}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
请注意, 你必须直接使用FileResponse返回图像.
- 除非在
responses参数中明确指定不同的媒体类型, 否则FastAPI将假定响应与主响应类具有相同的媒体类型(默认为applicatoin/json). - 但是如果你指定了一个自定义响应类, 并将
None作为其媒体类型, FastAPI将使用application/json作为具有关联模型的任何其他响应.
# 组合信息
你还可以联合接收来自多个位置的响应信息, 包括response_model, status_code和responses参数. 你可以使用默认的状态码200(或者你需要的自定义状态码)声明一个response_model, 然后直接在OpenAPI模式中在responses中声明想用响应的其他信息. FastAPI将保留来自responses的附加信息, 并将其与模型中的JSON Schema结合起来. 例如, 你可以使用状态码404声明响应, 该响应使用Pydantic模型并具有自定义的description. 以及一个状态码为200的响应, 它使用你的response_model, 但包含自定义的example:
from fastapi import FastAPI
from fastapi.responses import JSONResponse
from pydantic import BaseModel
class Item(BaseModel):
id: str
value: str
class Message(BaseModel):
message: str
app = FastAPI()
@app.get(
"/items/{item_id}",
response_model=Item,
responses={
404: {"model": Message, "description": "The item was not found"},
200: {
"description": "Item requested by ID",
"content": {
"application/json": {
"example": {"id": "bar", "value": "The bar tenders"}
}
},
},
},
)
async def read_item(item_id: str):
if item_id == "foo":
return {"id": "foo", "value": "there goes my hero"}
else:
return JSONResponse(status_code=404, content={"message": "Item not found"})
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
所有这些都将被合并并包含在您的OpenAPI中, 并在API文档中显示.
# 联合预定义响应和自定义响应
你可能希望有一些应用于许多路径操作的预定义响应, 但是你想将不同的路径和自定义的响应组合在一块. 对于这些情况, 你可以使用Python的技术, 将dict与**dict_to_unpack解包:
old_dict = {
"old key": "old value",
"second old key": "second old value",
}
new_dict = {**old_dict, "new key": "new value"}
2
3
4
5
这里, new_dict将包含来自old_dict的所有键值对加上新的键值对:
{
"old key": "old value",
"second old key": "second old value",
"new key": "new value",
}
2
3
4
5
你可以使用该技术在路径操作中重用一些预定义的响应, 并将它们与其他自定义响应相结合, 例如:
from typing import Union
from fastapi import FastAPI
from fastapi.responses import FileResponse
from pydantic import BaseModel
class Item(BaseModel):
id: str
value: str
responses = {
404: {"description": "Item not found"},
302: {"description": "The item was moved"},
403: {"description": "Not enough privileges"},
}
app = FastAPI()
@app.get(
"/items/{item_id}",
response_model=Item,
responses={**responses, 200: {"content": {"image/png": {}}}},
)
async def read_item(item_id: str, img: Union[bool, None] = None):
if img:
return FileResponse("image.png", media_type="image/png")
else:
return {"id": "foo", "value": "there goes my hero"}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
# 有关OpenAPI响应的更多信息
要了解可以在响应中包含哪些内容, 可以查看OpenAPI规范中的以下部分: OpenAPI响应对象, 它包括Response Object. 你可以直接在responses参数中的每个响应中包含任何内容. 包括description, headers, content(其中是声明不同的媒体类型和JSON Schemas)和links.
# 响应Cookies
# 使用Response参数
你可以在路径函数中定义一个类型为Response的参数, 这样你就可以在这个临时响应对象中设置cookie了.
from fastapi import FastAPI, Response
app = FastAPI()
@app.post("/cookie-and-object/")
def create_cookie(response: Response):
response.set_cookie(key="fakesession", value="fake-cookie-session-value")
return {"message": "Come to the dark side, we have cookies"}
2
3
4
5
6
7
8
9
而且你可以根据需要响应不同的对象, 比如常用的dict, 数据库model等. 如果你定义了response_model, 程序会自动根据response_model来过滤和转换你响应的对象. FastAPI会使用这个临时响应对象去装载这些cookies信息(同样还有headers和状态码等信息), 最终会将这些信息和通过response_model转化过的数据合并到最终的响应里. 你也可以在depend中定义Response参数, 并设置cookie和header.
# 直接响应Response
你还可以在直接响应Response时直接创建cookies. 可以参考Return a Response Directly来创建response, 然后设置Cookies, 并返回:
from fastapi import FastAPI
from fastapi.responses import JSONResponse
app = FastAPI()
@app.post("/cookie/")
def create_cookie():
content = {"message": "Come to the dark side, we have cookies"}
response = JSONResponse(content=content)
response.set_cookie(key="fakesession", value="fake-cookie-session-value")
return response
2
3
4
5
6
7
8
9
10
11
12
需要注意, 如果你直接返回一个response对象, 而不是使用Response入参, FastAPI则会直接返回你封装的response对象. 所以你需要确保你响应数据类型的正确性, 如: 你可以使用JSONResponse来兼容JSON的场景, 同时, 你也应当仅返回通过response_model过滤过的数据.
# 更多信息
技术细节
你也可以使用from starlette.responses import Response或者from starlette.responses import JSONResponse.
为了方便开发者, FastAPI封装了相同数据类型, 如starlette.responses和fastapi.responses. 不过大部分response对象都是直接引用自Starlette.
因为Response对象可以非常便捷的设置headers和cookies, 所以FastAPI同时也封装了fastapi.Response.
如果你想查看所有可用的参数和选项, 可以参考Starlette帮助文档.
# 响应头
# 使用Response参数
你可以在你的路径操作函数中声明一个Response类型的参数(就像在cookies做的那样). 然后你可以在这个临时响应对象中设置头部.
from fastapi import FastAPI, Response
app = FastAPI()
@app.get("/headers-and-ojbect/")
def get_headers(response: Response):
response.headers["X-Cat-Dog"] = "alone in the world"
return {"message": "Hello World"}
2
3
4
5
6
7
8
9
然后你可以像平常一样返回任何你需要的对象(例如一个dict或者一个数据库模型). 如果你声明了一个response_model, 它仍然会被用来过滤和转换你返回的对象. FastAPI将使用这个临时响应来提取头部(也包括cookies和状态码), 并将它们放入包含你返回的值的最终响应中, 该响应由任何response_model过滤. 你也可以在依赖项中声明Response参数, 并在其中设置头部(和cookies).
# 直接返回Response
你也可以直接返回Response时添加头部, 按照直接返回响应中所述创建响应, 并将头部作为附加参数传递:
from fastapi import FastAPI
from fastapi.responses import JSONResponse
app = FastAPI()
@app.get("/headers/")
def get_headers():
content = {"message": "Hello World"}
headers = {"X-Cat-Dog": "alone in the world", "Content-Language": "en-US"}
return JSONResponse(content=content, headers=headers)
2
3
4
5
6
7
8
9
10
11
你也可以使用from starlette.responses import Response或from starlette.responses import JSONResponse.
FastAPI提供了与fastapi.responses相同的starlette.responses, 只是为了方便开发者. 但是, 大多数可用的响应都直接来自Starlette.
由于Response经常用于设置头部和cookies, 因此FastAPI还在fastapi.Response中提供了它.
# 自定义头部
请注意, 可以使用X-前缀添加自定义专有头部. 但是, 如果你有自定义头部, 你希望浏览器中的客户端能够看到它们, 你需要将它们添加到你的CORS配置中(在CORS(跨源资源共享)有介绍), 使用在Starlette的CORS文档中记录的expose_headers参数.
# 响应 -- 更改状态码
你可能已经了解到, 可以设置默认的响应状态码, 但在某些情况下, 你需要返回一个不同于默认值的状态码.
# 使用场景
例如, 假设你想默认返回一个HTTP状态码为"OK" 200, 但如果数据不存在, 你想创建它, 并返回一个HTTP状态码为"CREATED" 201, 但你仍然希望能够使用response_model过滤和转换你返回的数据, 对于这种情况, 你可以使用一个Response参数.
# 使用Response参数
你可以在你的路径操作函数中声明一个Response类型的参数, 然后你可以在这个临时响应对象中设置status_code.
from fastapi import FastAPI, Response, status
app = FastAPI()
tasks = {"foo": "Listen to the Bar Fighters"}
@app.put("/get-or-create-task/{task_id}", status_code=200)
def get_or_create_task(task_id: str, response: Response):
if task_id not in tasks:
tasks[task_id] = "This didn't exist before"
response.status_code = status.HTTP_201_CREATED
return tasks[task_id]
2
3
4
5
6
7
8
9
10
11
12
13
然后你可以像平常一样返回任何你需要的对象(例如一个dict或者一个数据库模型). 如果你声明了一个response_model, 它仍然会被用来过滤和转换你返回的对象. FastAPI将使用这个临时响应来提取状态码(也包括cookies和headers), 并将它们放入包含你返回的值的最终响应中, 该响应由任何response_model过滤. 你也可以在依赖项中声明Response参数, 并在其中设置状态码, 但请注意, 最后设置的状态码将会生效.
# 高级依赖项
# 参数化的依赖项
我们之前看到的所有依赖项都是写死的函数或类. 但也可以为依赖项设置参数, 避免声明多个不同的韩硕或类. 假设要创建校验查询参数q是否包含固定内容的依赖项, 但此处要把带检验的固定内容定义为参数.
# 可调用实例
Python可以把类实例变为可调用项, 这里说的不是类本身(类本就是可调用项), 而是类实例. 为此, 需要声明__call__方法:
from fastapi import Depends, FastAPI
app = FastAPI()
class FixedContentQueryChecker:
def __init__(self, fixed_content: str):
self.fixed_content = fixed_content
def __call__(self, q: str=""):
if q:
return self.fixed_content in q
return False
checker = FixedContentQueryChecker("bar")
@app.get("/query-checker/")
async def read_query_check(fixed_content_icluded: bool = Depends(checker)):
return {"fixed_content_in_query": fixed_content_included}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
本例中, FastAPI使用__call__检查附加参数及子依赖项, 稍后, 还要调用它向路径操作函数传递值.
# 参数化实例
接下来, 使用__init__声明用于参数化依赖项的实例参数:
from fastapi import Depends, FastAPI
app = FastAPI()
class FixedContentQueryChecker:
def __init__(self, fixed_content: str):
self.fixed_content = fixed_content
def __call__(self, q: str = ""):
if q:
return self.fixed_content in q
return False
checker = FixedContentQueryChecker("bar")
@app.get("/query-checker/")
async def read_query_check(fixed_content_included: bool = Depends(checker)):
return {"fixed_content_in_query": fixed_content_included}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
本例中, FastAPI不使用__init__, 我们要直接在代码中使用.
# 创建实例
使用以下代码创建类实例:
from fastapi import Depends, FastAPI
app = FastAPI()
class FixedContentQueryChecker:
def __init__(self, fixed_content: str):
self.fixed_content = fixed_content
def __call__(self, q: str = ""):
if q:
return self.fixed_content in q
return False
checker = FixedContentQueryChecker("bar")
@app.get("/query-checker/")
async def read_query_check(fixed_content_included: bool = Depends(checker)):
return {"fixed_content_in_query": fixed_content_included}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
这样就可以参数化依赖项, 它包含checker.fixed_content的属性 -- "bar".
# 把实例作为依赖项
然后, 不要再在Depends(checker)中使用Depends(FixedContentQueryChecker), 而是要使用checker, 因为依赖项是类实例--checker, 不是类. 处理依赖项时, FastAPI以如下方式调用checker:
checker(q="somequery")
并用路径操作函数的参数fixed_content_included返回依赖项的值:
from fastapi import Depends, FastAPI
app = FastAPI()
class FixedContentQueryChecker:
def __init__(self, fixed_content: str):
self.fixed_content = fixed_content
def __call__(self, q: str = ""):
if q:
return self.fixed_content in q
return False
checker = FixedContentQueryChecker("bar")
@app.get("/query-checker/")
async def read_query_check(fixed_content_included: bool = Depends(checker)):
return {"fixed_content_in_query": fixed_content_included}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
本章示例有些刻意, 也看不出什么用处. 这个简例只是为了说明高级依赖项的运作机制. 在有关安全的章节中, 工具函数将以这种方式实现. 只要能理解本章内容, 就能理解安全工具背后的运行机制.
# 高级安全
除教程-用户指南: 安全性中涵盖的功能之外, 还有一些额外的功能来处理安全性.
接下来的章节, 并不一定是高级的. 而且对于你的使用场景来说, 解决方案可能就在其中.
# OAuth2 作用域
FastAPI无缝集成OAuth2作用域(Scopes), 可以直接使用. 作用域是更精密的权限系统, 遵循OAuth2标准, 与OpenAPI应用(和API自动文档)集成. OAuth2也是脸书, 谷歌, GitHub, 微软, 推特等第三方身份验证应用使用的机制. 这些身份验证应用在用户登录应用时使用OAuth2提供指定权限. 脸书, 谷歌, GitHub, 微软, 推特就是OAuth2作用域登录. 本章介绍如何在FastAPI应用中使用OAuth2作用域管理验证与授权.
本章内容较难, 刚接触FastAPI的新手可以跳过. OAuth2作用域不是必须的, 没有它, 你也可以处理身份验证与授权. 但OAuth2作用域与API(通过OpenAPI)及API文档集成地更好. 不管怎么说, FastAPI支持在代码中使用作用域或其它安全/授权需求项. 很多情况下, OAuth2作用域就像一把牛刀, 但如果你确定要使用作用域, 或对它有兴趣, 请继续阅读.
# OAuth2作用域与OpenAPI
OAuth2规范的作用域是由空格分隔的字符串组成的列表. 这些字符串支持任何格式, 但不能包含空格. 作用域表示的是权限. OpenAPI中(例如API文档)可以定义安全方案. 这些安全方案在使用OAuth2时, 还可以声明和使用作用域. 作用域只是(不带空格的)字符串. 常用于声明特定安全权限, 例如:
- 常见用例为,
users:read或users:write - 脸书和Instagram使用
instagram_basic - 谷歌使用
https://www.googleapis.com/auth/drive
说明
OAuth2中, 作用域只是声明特定权限的字符串. 是否使用冒号:等符号, 或是不是URL并不重要. 这些细节只是特定的实现方式. 对OAuth2来说, 它们都只是字符串而已.
# 全局纵览
首先, 快速浏览一下以下代码与用户指南中OAuth2实现密码哈希与Bearer JWT令牌验证一章中代码的区别, 以下代码使用OAuth2作用域:
from datetime import datetime, timedelta, timezone
from typing import List, Union
import jwt
from fastapi import Depends, FastAPI, HTTPException, Security, status
from fastapi.security import (
OAuth2PasswordBearer,
OAuth2PasswordRequestForm,
SecurityScopes,
)
from jwt.exceptions import InvalidTokenError
from passlib.context import CryptContext
from pydantic import BaseModel, ValidationError
# to get a string like this run:
# openssl rand -hex 32
SECRET_KEY = "09d25e094faa6ca2556c818166b7a9563b93f7099f6f0f4caa6cf63b88e8d3e7"
ALGORITHM = "HS256"
ACCESS_TOKEN_EXPIRE_MINUTES = 30
fake_users_db = {
"johndoe": {
"username": "johndoe",
"full_name": "John Doe",
"email": "johndoe@example.com",
"hashed_password": "$2b$12$EixZaYVK1fsbw1ZfbX3OXePaWxn96p36WQoeG6Lruj3vjPGga31lW",
"disabled": False,
},
"alice": {
"username": "alice",
"full_name": "Alice Chains",
"email": "alicechains@example.com",
"hashed_password": "$2b$12$gSvqqUPvlXP2tfVFaWK1Be7DlH.PKZbv5H8KnzzVgXXbVxpva.pFm",
"disabled": True,
},
}
class Token(BaseModel):
access_token: str
token_type: str
class TokenData(BaseModel):
username: Union[str, None] = None
scopes: List[str] = []
class User(BaseModel):
username: str
email: Union[str, None] = None
full_name: Union[str, None] = None
disabled: Union[bool, None] = None
class UserInDB(User):
hashed_password: str
pwd_context = CryptContext(schemes=["bcrypt"], deprecated="auto")
oauth2_scheme = OAuth2PasswordBearer(
tokenUrl="token",
scopes={"me": "Read information about the current user.", "items": "Read items."},
)
app = FastAPI()
def verify_password(plain_password, hashed_password):
return pwd_context.verify(plain_password, hashed_password)
def get_password_hash(password):
return pwd_context.hash(password)
def get_user(db, username: str):
if username in db:
user_dict = db[username]
return UserInDB(**user_dict)
def authenticate_user(fake_db, username: str, password: str):
user = get_user(fake_db, username)
if not user:
return False
if not verify_password(password, user.hashed_password):
return False
return user
def create_access_token(data: dict, expires_delta: Union[timedelta, None] = None):
to_encode = data.copy()
if expires_delta:
expire = datetime.now(timezone.utc) + expires_delta
else:
expire = datetime.now(timezone.utc) + timedelta(minutes=15)
to_encode.update({"exp": expire})
encoded_jwt = jwt.encode(to_encode, SECRET_KEY, algorithm=ALGORITHM)
return encoded_jwt
async def get_current_user(
security_scopes: SecurityScopes, token: str = Depends(oauth2_scheme)
):
if security_scopes.scopes:
authenticate_value = f'Bearer scope="{security_scopes.scope_str}"'
else:
authenticate_value = "Bearer"
credentials_exception = HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Could not validate credentials",
headers={"WWW-Authenticate": authenticate_value},
)
try:
payload = jwt.decode(token, SECRET_KEY, algorithms=[ALGORITHM])
username: str = payload.get("sub")
if username is None:
raise credentials_exception
token_scopes = payload.get("scopes", [])
token_data = TokenData(scopes=token_scopes, username=username)
except (InvalidTokenError, ValidationError):
raise credentials_exception
user = get_user(fake_users_db, username=token_data.username)
if user is None:
raise credentials_exception
for scope in security_scopes.scopes:
if scope not in token_data.scopes:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Not enough permissions",
headers={"WWW-Authenticate": authenticate_value},
)
return user
async def get_current_active_user(
current_user: User = Security(get_current_user, scopes=["me"]),
):
if current_user.disabled:
raise HTTPException(status_code=400, detail="Inactive user")
return current_user
@app.post("/token")
async def login_for_access_token(
form_data: OAuth2PasswordRequestForm = Depends(),
) -> Token:
user = authenticate_user(fake_users_db, form_data.username, form_data.password)
if not user:
raise HTTPException(status_code=400, detail="Incorrect username or password")
access_token_expires = timedelta(minutes=ACCESS_TOKEN_EXPIRE_MINUTES)
access_token = create_access_token(
data={"sub": user.username, "scopes": form_data.scopes},
expires_delta=access_token_expires,
)
return Token(access_token=access_token, token_type="bearer")
@app.get("/users/me", response_model=User)
async def read_users_me(current_user: User = Depends(get_current_active_user)):
return current_user
@app.get("/users/me/items/")
async def read_own_items(
current_user: User = Security(get_current_active_user, scopes=["items"]),
):
return [{"item_id": "Foo", "owner": current_user.username}]
@app.get("/status/")
async def read_system_status(current_user: User = Depends(get_current_user)):
return {"status": "ok"}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
下面, 我们逐步说明修改的代码内容.
# OAuth2安全方案
第一个修改的地方是, 使用两个作用域me和items声明OAuth2安全方案. scopes参数接收字典, 键是作用域, 值是作用域的描述:
oauth2_scheme = OAuth2PasswordBearer(
tokenUrl="token",
scopes={"me": "Read information about the current user.", "items": "Read items."},
)
2
3
4
因为声明了作用域, 所以登录或授权时会在API文档中显示. 此处, 选择给予访问权限的作用域: me和items. 这也是使用脸书, 谷歌, GitHub登录时的授权机制.
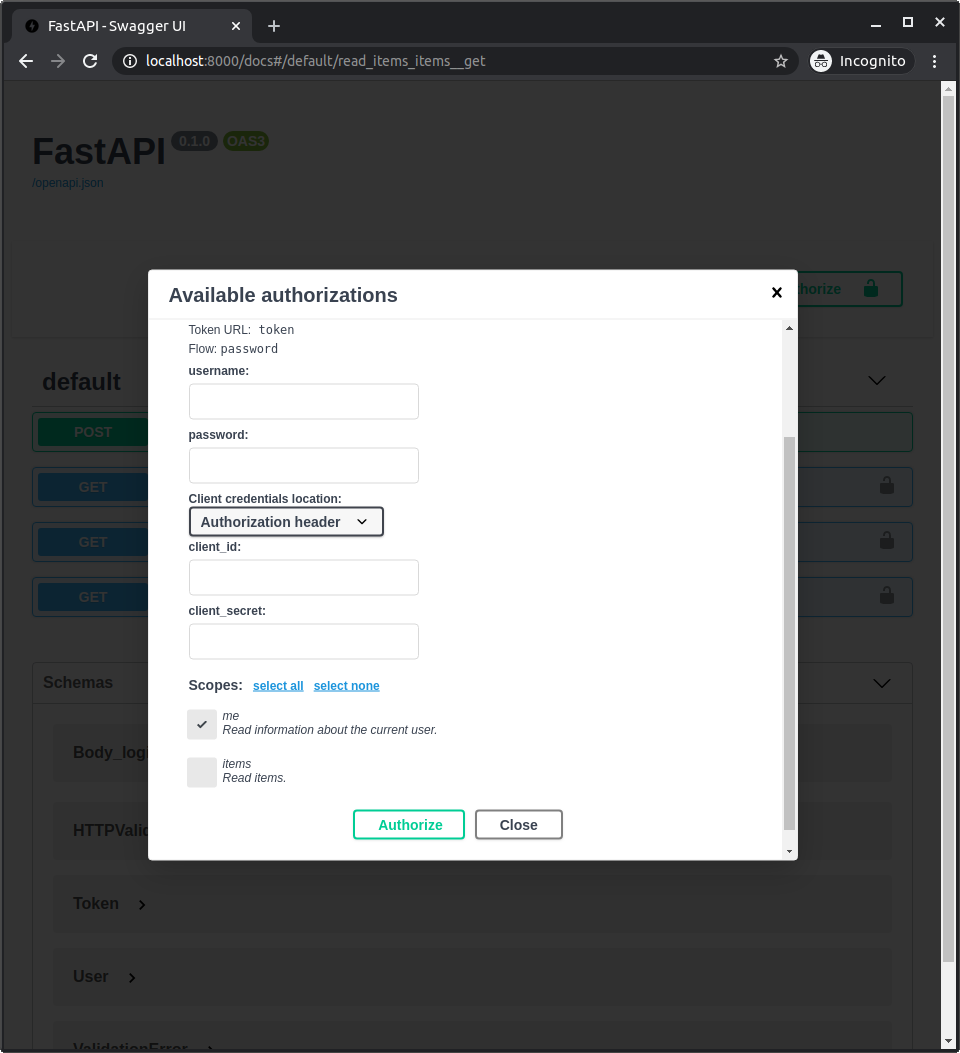
# JWT令牌作用域
现在, 修改令牌路径操作, 返回请求的作用域. 此处仍然使用OAuth2PasswordRequestForm, 它包含类型为字符串列表的scopes属性, 且scopes属性中包含要在请求里接收的每个作用域. 这样, 返回的JWT令牌中就包含了作用域.
危险
为了简明起见, 本例把接收的作用域直接添加到了令牌里. 但在你的应用中, 为了安全起见, 应该只把作用域添加到确实需要作用域的用户, 或预定义的用户.
# 在路径操作与依赖项中声明作用域
接下来, 为路径操作/users/me/items/声明作用域items. 为此, 要从fastapi中导入并使用Security. Security声明依赖项的方式和Depends一样, 但Security还能接收作用域(字符串)列表类型的参数scopes. 此处使用与Depends相同的方式, 把依赖项函数get_current_active_user传递给Security. 同时, 还传递了作用域列表, 本例中只传递了一个作用域: items(此处支持传递更多作用域).
依赖项函数get_current_active_user还能声明子依赖项, 不仅可以使用Depends, 也可以使用Security. 声明子依赖项函数(get_current_user)及更多作用域. 本例要求使用作用域me(还可以使用更多作用域).
笔记
不必在不同位置添加不同的作用域, 本例使用的这种方式只是为了展示FastAPI如何处理在不同层级声明的作用域.
async def get_current_active_user(
current_user: User = Security(get_current_user, scopes=["me"]),
):
if current_user.disabled:
raise HTTPException(status_code=400, detail="Inactive user")
return current_user
# ...
@app.get("/users/me/items/")
async def read_own_items(
current_user: User = Security(get_current_active_user, scopes=["items"]),
):
return [{"item_id": "Foo", "owner": current_user.username}]
2
3
4
5
6
7
8
9
10
11
12
13
14
技术细节
Security实际上是Depends的子类, 而且只比Depends多一个参数. 但使用Security代替Depends, FastAPI可以声明安全作用域, 并在内部使用这些作用域, 同时, 使用OpenAPI存档API. 但实际上, 从fastapi导入的Query, Path, Depends, Security等对象, 只是返回特殊类的函数.
# 使用SecurityScopes
修改依赖项get_current_user, 这是上面的依赖项使用的依赖项. 这里使用的也是之前创建的OAuth2方案, 并把它声明为依赖项: oauth2_scheme. 该依赖项函数本身不需要作用域, 因此, 可以使用Depends和oauth2_scheme. 不需要指定安全作用域时, 不必使用Security. 此处还声明了从fastapi.security导入的SecurityScopes类型的特殊参数. SecurityScopes类与Request类似(Request用于直接提取请求对象).
oauth2_scheme = OAuth2PasswordBearer(
tokenUrl="token",
scopes={"me": "Read information about the current user.", "items": "Read items."},
)
async def get_current_user(
security_scopes: SecurityScopes, token: str = Depends(oauth2_scheme)
):
if security_scopes.scopes:
authenticate_value = f'Bearer scope="{security_scopes.scope_str}"'
else:
authenticate_value = "Bearer"
credentials_exception = HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Could not validate credentials",
headers={"WWW-Authenticate": authenticate_value},
)
try:
payload = jwt.decode(token, SECRET_KEY, algorithms=[ALGORITHM])
username: str = payload.get("sub")
if username is None:
raise credentials_exception
token_scopes = payload.get("scopes", [])
token_data = TokenData(scopes=token_scopes, username=username)
except (InvalidTokenError, ValidationError):
raise credentials_exception
user = get_user(fake_users_db, username=token_data.username)
if user is None:
raise credentials_exception
for scope in security_scopes.scopes:
if scope not in token_data.scopes:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Not enough permissions",
headers={"WWW-Authenticate": authenticate_value},
)
return user
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
# 使用scopes
参数security_scopes的类型是SecurityScopes. 它的属性scopes是作用域列表, 所有依赖项都把它作为子依赖项. 也就是说所有依赖...这听起来有些绕, 后文会有解释. (类SecurityScopes的)security_scopes对象还提供了单字符串类型的属性scope_str, 该属性是(要在本例中使用的)用空格分割的作用域. 此处还创建了后续代码中要服用(raise)的HTTPException. 该异常包含了作用域所需的(如有), 以空格分隔的字符串(使用scope_str). 该字符串要放到包含作用域的WWW-Authenticate请求头中(这也是规范的要求).
async def get_current_user(
security_scopes: SecurityScopes, token: str = Depends(oauth2_scheme)
):
if security_scopes.scopes:
authenticate_value = f'Bearer scope="{security_scopes.scope_str}"'
else:
authenticate_value = "Bearer"
credentials_exception = HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Could not validate credentials",
headers={"WWW-Authenticate": authenticate_value},
)
try:
payload = jwt.decode(token, SECRET_KEY, algorithms=[ALGORITHM])
username: str = payload.get("sub")
if username is None:
raise credentials_exception
token_scopes = payload.get("scopes", [])
token_data = TokenData(scopes=token_scopes, username=username)
except (InvalidTokenError, ValidationError):
raise credentials_exception
user = get_user(fake_users_db, username=token_data.username)
if user is None:
raise credentials_exception
for scope in security_scopes.scopes:
if scope not in token_data.scopes:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Not enough permissions",
headers={"WWW-Authenticate": authenticate_value},
)
return user
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
# 检验username与数据形状
我们可以校验是否获取了username, 并抽取作用域. 然后, 使用Pydantic模型校验数据(捕获ValidationError异常), 如果读取JWT令牌或使用Pydantic模型验证数据时出错, 就会触发之前创建的HTTPException异常. 对此, 要使用新的属性scopes更新Pydantic模型TokenData. 使用Pydantic验证数据可以确保数据中含有由作用域组成的字符串列表, 以及username字符串等内容. 反之, 如果使用字典或其他数据结构, 就由可能在后面某些位置破坏应用, 形成安全隐患. 还可以使用用户名验证用户, 如果没有用户, 也会触发之前创建的异常.
# 检验scopes
接下来, 校验所有依赖项和依赖要素(包括路径操作)所需的作用域. 这些作用域包含在令牌的scopes里, 如果不存在其中就会触发HTTPException异常. 为此, 要使用包含所有作用域字符串列表的security_scopes.scopes.
# 依赖项树与作用域
再次查看这个依赖树与作用域. get_current_active_user依赖项包含子依赖项get_current_user, 并在get_current_active_user中声明了作用域"me"包含所需作用域列表, 在security_scopes.scopes中传递给get_current_user. 路径操作自身也声明了作用域, "items", 这也是security_scopes.scopes列表传递给get_current_user的.
依赖项与作用域的层级架构如下:
- 路径操作
read_own_items包含:- 依赖项所需的作用域
["items"]: get_current_active_user:- 依赖项函数
get_current_active_user包含:- 所需的作用域
"me"包含依赖项: get_current_user:- 依赖项函数
get_current_user包含:- 没有作用域需求其自身
- 依赖项使用
oauth2_scheme security_scopes参数的类型是SecurityScopes:security_scopes参数的属性scopes是包含上述声明的所有作用域的列表, 因此:security_scopes.scopes包含用于路径操作的["me", "items"]security_scopes.scopes包含路径操作read_users_me的["me"], 因为它在依赖项里被声明security_scopes.scopes包含用于路径操作read_system_status的[](空列表), 并且它的依赖项get_current_user也没有声明任何scope
- 依赖项函数
- 所需的作用域
- 依赖项函数
- 依赖项所需的作用域
提示
此处重要且神奇的事情是, get_current_user检查每个路径操作时可以使用不同的scopes列表. 所有这些依赖于在每个路径操作和指定路径操作的依赖树中的每个依赖项.
# SecurityScopes的更多细节
你可以在任何位置或多个位置使用SecurityScopes, 不一定非得在根依赖项中使用. 它总是在当前Security依赖项中和所有依赖因子对于特定路径操作和特定依赖树中安全作用域, 因为SecurityScopes包含所有由依赖项声明的作用域, 可以在核心依赖函数中用它验证所需作用域的令牌, 然后再在不同的路径操作中声明不同的作用域需求. 它们会为每个路径操作进行单独检查.
# 查看文档
打开API文档, 进行身份验证, 并指定要授权的作用域.
没有选择任何作用域, 也可以进行身份验证, 但访问/users/me或/users/me/items时, 会显示没有足够的权限. 但仍可以访问/status/. 如果选择了作用域me, 但没有选择作用域items, 则可以访问/users/me/, 但不能访问/users/me/item. 这就是通过用户提供的令牌使用第三方应用访问这些路径操作时会发生的情况, 具体怎样取决于用户授权第三方应用的权限.
# 关于第三方集成
本例使用OAuth2密码流, 这种方式适用于登录我们自己的应用, 最好使用我们自己的前端. 因为我们能控制自己的前端应用, 可以新人它接收username与password. 但如果构建的是连接其他应用的OAuth2应用, 比如具有与脸书, 谷歌, GitHub相同功能的第三方身份验证应用, 那你就应该使用其他安全流. 最常用的是隐式流. 最安全的是代码流, 但实现起来更复杂, 而且需要更多步骤, 因为它更复杂, 很多第三方身份验证应用最终建议使用隐式流.
笔记
每个身份验证应用都会采用不同方式去命名流, 以便融合如自己的品牌. 但归根结底, 它们使用的都是OAuth2标准.
FastAPI的fastapi.security.oauth2里包含了所有OAuth2身份验证流工具.
# 装饰器dependencies中的Security
同样, 也可以在装饰器的dependencies参数中定义Depends列表, (详见路径操作装饰器依赖项), 也可以把scopes与Security一起使用.
# HTTP 基础授权
最简单的用例是使用HTTP基础授权(HTTP Basic Auth). 在HTTP基础授权中, 应用需要请求头包含用户名和密码. 如果没有接收到HTTP基础授权, 就返回HTTP 401 "Unauthorized" 错误, 并返回包含Basic值的请求头WWW-Authenticate以及可选的realm参数. HTTP基础授权让浏览器显示内置的用户名与密码提示, 输入用户名与密码后, 浏览器会把它们自动发送至请求头.
# 简单的HTTP基础授权
- 导入
HTTPBasic与HTTPBasicCredentials - 使用
HTTPBasic创建安全概图 - 在路径操作的依赖项中使用
security - 返回类型为
HTTPBasicCredentials的对象:- 包含发送的
username与password
- 包含发送的
from typing import Annotated
from fastapi import Depends, FastAPI
from fastapi.security import HTTPBasic, HTTPBasicCredentials
app = FastAPI()
security = HTTPBasic()
@app.get("/users/me")
def read_current_user(credentials: Annotated[HTTPBasicCredentials, Depends(security)]):
return {"username": credentials.username, "password": credentials.password}
2
3
4
5
6
7
8
9
10
11
12
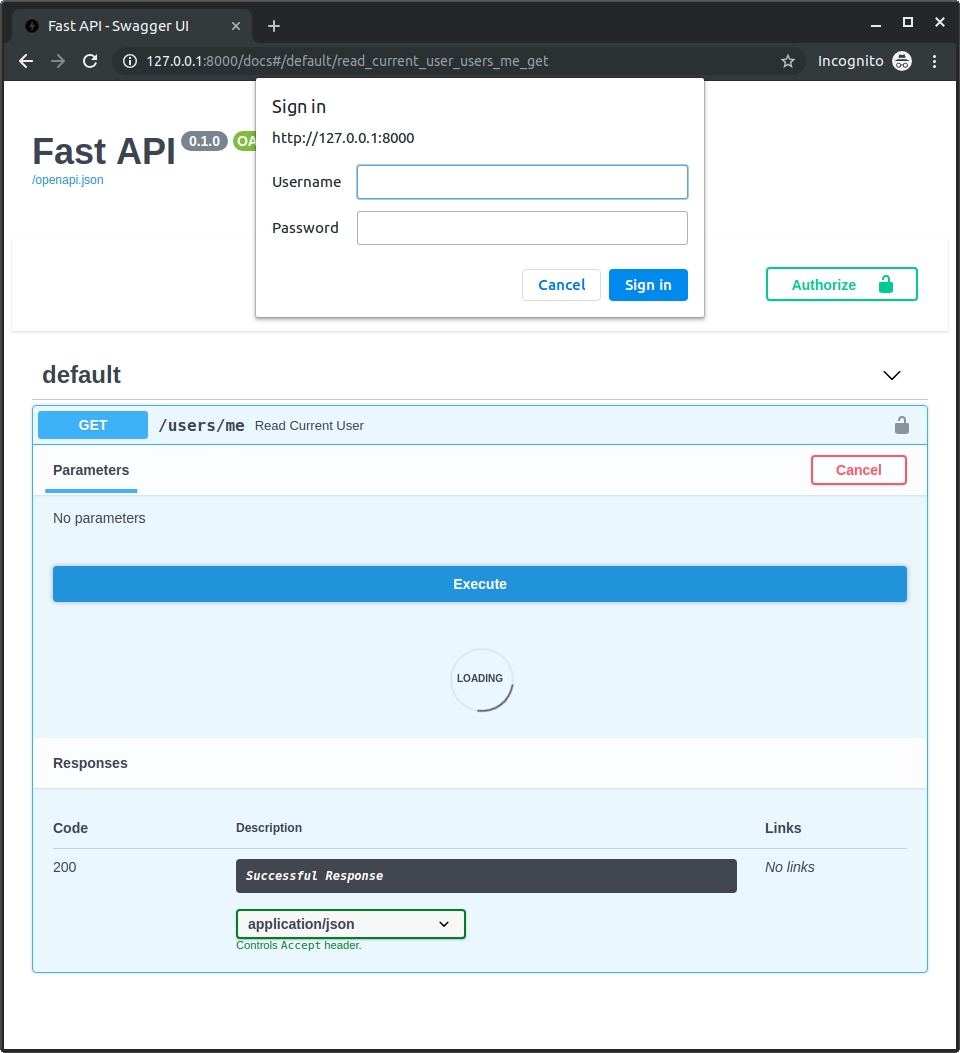
13
第一次打开URL(或在API文档中点击Execute按钮)时, 浏览器要求输入用户名与密码:
# 检查用户名
以下是更完整的实例. 使用依赖项检查用户名和密码是否正确. 为此要使用Python标准模块secrets检查用户名和密码. secrets.compare_digest()需要仅包含ASCII字符(英语字符)的bytes或str, 这意味着它不适用与像á一样的字符, 如Sebastián. 为了解决这个问题, 我们首先将username和password转换为使用UTF-8编码的bytes. 然后我们可以使用secrets.compare_digest()来确保credentials.username是"stanleyjobson", 且credentials.password是"swordfish".
import secrets
from typing import Annotated
from fastapi import Depends, FastAPI, HTTPException, status
from fastapi.security import HTTPBasic, HTTPBasicCredentials
app = FastAPI()
security = HTTPBasic()
def get_current_username(
credentials: Annotated[HTTPBasicCredentials, Depends(security)],
):
current_username_bytes = credentials.username.encode("utf8")
correct_username_bytes = b"stanleyjobson"
is_correct_username = secrets.compare_digest(
current_username_bytes, correct_username_bytes
)
current_password_bytes = credentials.password.encode("utf8")
correct_password_bytes = b"swordfish"
is_correct_password = secrets.compare_digest(
current_password_bytes, correct_password_bytes
)
if not (is_correct_username and is_correct_password):
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Incorrect username or password",
headers={"WWW-Authenticate": "Basic"},
)
return credentials.username
@app.get("/users/me")
def read_current_user(username: Annotated[str, Depends(get_current_username)]):
return {"username": username}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
这类似于:
if not (credentials.username == "stanleyjobson") or not (credentials.password == "swordfish"):
# Return some error
...
2
3
但使用secrets.compare_digest(), 可以防御时差攻击, 更加安全.
# 时差攻击
假设攻击者视图猜出用户名与密码. 它们发送用户名为johndoe, 密码为love123的请求. 然后, Python代码执行如下操作:
if "johndoe" == "stanleyjobson" and "love123" == "swordfish":
...
2
但就在Python比较晚johndoe的第一个字母j与stanleyjobson的s时, Python就已经知道这两个字符串不相同了, 它会这么想, 没必要浪费更多时间执行剩余字母的对比计算了, 应用立刻返回错误的用户或密码. 但接下来, 攻击者继续尝试stanleyjobsox和密码love123. 应用代码会执行类似下面的操作:
if "stanleyjobsox" == "stanleyjobson" and "love123" == "swordfish":
...
2
此时, Python要对比stanleyjobsox与stanleyjobson中的stanleyjobso, 才能知道这两个字符串不一样, 因此会花费几微秒来返回错误的用户或密码.
- 反应时间对攻击者的帮助
通过服务器花费了更多微秒才发送错误的用户或密码响应, 攻击者会知道猜对了一些内容, 起码开头字母是正确的. 然后, 它们就可以放弃johndoe, 再用类似stanleyjobsox的内容进行尝试.
- 专业攻击
当然, 攻击者不用手动操作, 而是编写每秒能执行成千上万次测试的攻击程序, 每次都会找到更多正确字符. 但是, 在你的应用帮助下, 攻击者利用时间差, 就能在几分钟或几小时内, 以这种方式猜出正确的用户名和密码.
- 使用
secrets.compare_digest()修补
在此, 代码中使用了secrets.compare_digest(). 简单的说, 它使用相同的时间对比stanleyjobsox和stanleyjobson, 还有johndoe和stanleyjobson, 对比密码时也一样. 在代码中使用secrets.compare_digest(), 就可以安全地防御全面攻击了.
# 返回错误
检测到凭证不正确后, 返回HTTPException及状态码401(与无凭证时返回的内容一样), 并添加请求头WWW-Authenticate, 让浏览器再次显示登录提示:
import secrets
from typing import Annotated
from fastapi import Depends, FastAPI, HTTPException, status
from fastapi.security import HTTPBasic, HTTPBasicCredentials
app = FastAPI()
security = HTTPBasic()
def get_current_username(
credentials: Annotated[HTTPBasicCredentials, Depends(security)],
):
current_username_bytes = credentials.username.encode("utf8")
correct_username_bytes = b"stanleyjobson"
is_correct_username = secrets.compare_digest(
current_username_bytes, correct_username_bytes
)
current_password_bytes = credentials.password.encode("utf8")
correct_password_bytes = b"swordfish"
is_correct_password = secrets.compare_digest(
current_password_bytes, correct_password_bytes
)
if not (is_correct_username and is_correct_password):
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Incorrect username or password",
headers={"WWW-Authenticate": "Basic"},
)
return credentials.username
@app.get("/users/me")
def read_current_user(username: Annotated[str, Depends(get_current_username)]):
return {"username": username}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
# 直接使用请求
至此, 我们已经使用多种类型声明了请求的各种组件, 并从以下对象中提取数据:
- 路径参数
- 请求头
- Cookies
- 等
FastAPI使用这种方式验证数据, 转换数据, 并自动生成API文档, 但有时, 我们也需要直接访问Request对象.
# Request对象的细节
实际上, FastAPI的底层是Starlette, FastAPI只不过是在Starlette顶层提供了一些工具, 所以能直接使用Starlette的Request对象. 但直接从Request对象提取数据时(例如, 读取请求体), FastAPI不会验证, 转换和存档数据(为API文档使用OpenAPI). 不过, 仍可以验证, 转换与注释(使用Pydantic模型的请求体等)其它正常声明的参数. 但在某些特定情况下, 还是需要提取Request对象.
# 直接使用Request对象
假设要在路径操作函数中获取客户端IP地址和主机. 此时, 需要直接访问请求.
from fastapi import FastAPI, Request
app = FastAPI()
@app.get("/items/{item_id}")
def read_root(item_id: str, request: Request):
client_host = request.client.host
return {"client_host": client_host, "item_id": item_id}
2
3
4
5
6
7
8
9
把路径操作函数的参数类型声明为Request, FastAPI就能把Request传递到参数里.
注意, 本例除了声明请求参数之外, 还声明了路径参数. 因此, 能够提取, 验证路径参数, 并转换为指定类型, 还可以用OpenAPI注释. 同样, 你也可以正常声明其他参数, 而且还可以提取Request.
# Request文档
更多细节详见Starlette文档 - Request对象.
技术细节
也可以使用from starlette.requests import Request. FastAPI的from fastapi import Request只是为开发者提供的快捷方式, 但其实它直接继承自Starlette.
# 使用数据类
FastAPI基于Pydantic构建, 前文已经介绍过如何使用Pydantic模型声明请求与响应. 但FastAPI还可以使用数据类(dataclasses):
from dataclasses import dataclass
from typing import Union
from fastapi import FastAPI
@dataclass
class Item:
name: str
price: float
description: Union[str, None] = None
tax: Union[float, None] = None
app = FastAPI()
@app.post("/items/")
async def create_item(item: Item):
return item
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
这还是借助于Pydantic及其内置的dataclasses. 因此, 即便上述代码没有显示使用Pydantic, FastAPI仍会使用Pydantic把标准数据类转换为Pydantic数据类(dataclasses). 并且, 它仍然支持以下功能:
- 数据验证
- 数据序列化
- 数据存档等
数据类的运作方式与Pydantic模型相同, 实际上, 它的底层使用的也是Pydantic.
注意, 数据类不支持Pydantic模型的所有功能. 因此, 开发时仍需要使用Pydantic模型, 但如果数据类很多, 这一技巧能给FastAPI开发Web API增添不少助力.
# response_model使用数据类
在response_model参数中使用dataclasses:
from dataclasses import dataclass, field
from typing import List, Union
from fastapi import FastAPI
@dataclass
class Item:
name: str
price: float
tags: List[str] = field(default_factory=list)
description: Union[str, None] = None
tax: Union[float, None] = None
app = FastAPI()
@app.get("/items/next", response_model=Item)
async def read_next_item():
return {
"name": "Island In The Moon",
"price": 12.99,
"description": "A place to be playin' and havin' fun".
"tags": ["breater"],
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
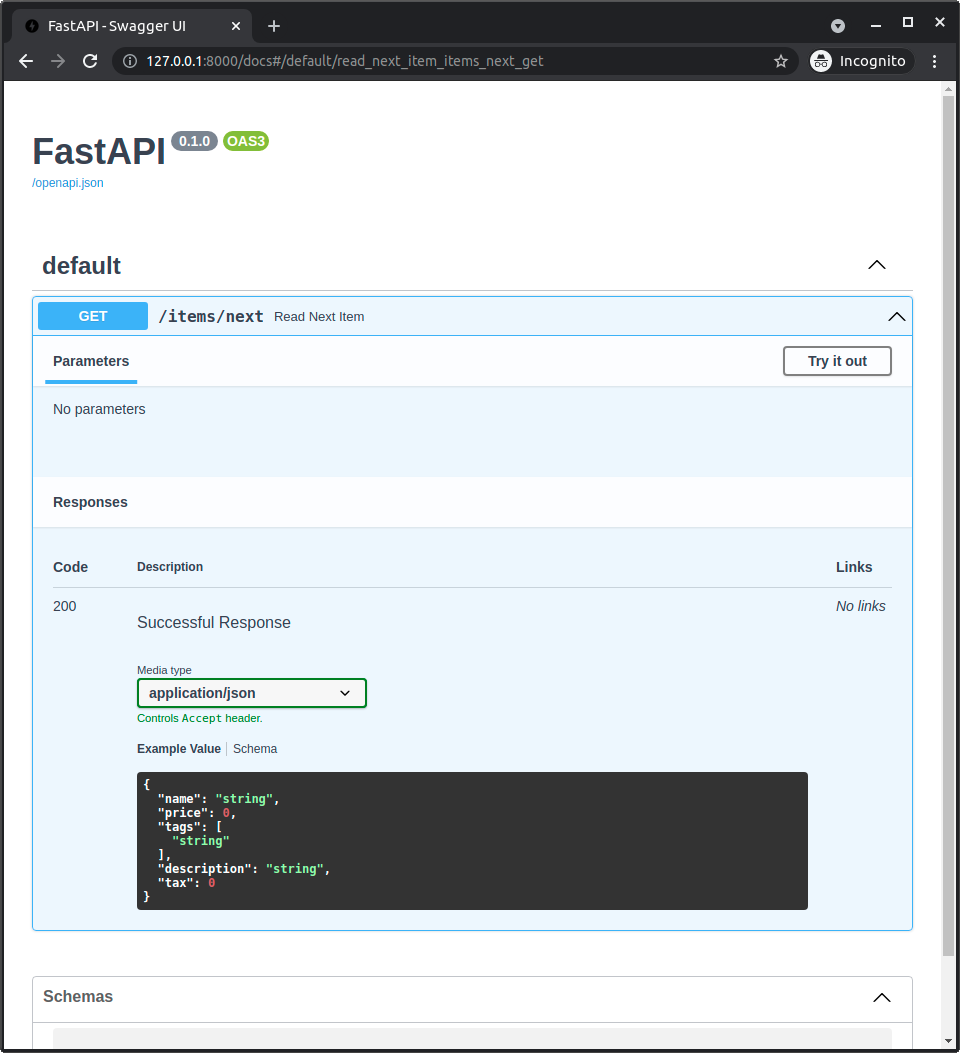
26
本例把数据类自动转换为Pydantic数据类. API文档中也会显示相关概图:
# 在嵌套数据结构中使用数据类
你还可以把dataclasses与其它类型注解组合在一起, 创建嵌套数据结构. 还有一些情况也可以使用Pydantic的dataclasses, 例如, 在API文档中显示错误. 本例把标准的dataclasses直接替换为pydantic.dataclasses:
from dataclasses import field # 本例依然要从标准的 dataclasses 中导入 field
from typing import List, Union
from fastapi import FastAPI
from pydantic.dataclasses import dataclass # 使用 pydantic.dataclasses 直接替换 dataclasses
@dataclass
class Item:
name: str
description: Union[str, None] = None
@dataclass
class Author:
name: str
items: List[Item] = field(default_factory=list) # Author 数据类包含 Item 数据类列表
app = FastAPI()
@app.post("/authors/{author_id}/items/", response_model=Author) # Author 数据类用于 response_model 参数
async def create_author_items(author_id: str, items: List[Item]): # 其它带有数据类的标准类型注解也可以作为请求体, 本例使用的是 Item 数据类列表
return {"name": author_id, "items": items} # 这行代码返回的是包含 items 的字典,items 是数据类列表. FastAPI 仍能把数据序列化为 JSON
@app.get("/authors/", response_model=List[Author]) # 这行代码中, response_model 的类型注解是 Author 数据类列表, 再一次, 可以把 dataclasses 与标准类型注解一起使用
def get_authors(): # 注意, 路径操作函数使用的是普通函数, 不是异步函数; 与往常一样, 在 FastAPI 中, 可以按需组合普通函数与异步函数; 如果不清楚何时使用异步函数或普通函数, 请参阅急不可待?
# 一节中对 async 与 await 的说明
return [ # 路径操作函数返回的不是数据类(虽然它可以返回数据类), 而是返回内含数据的字典列表; FastAPI 使用(包含数据类的) response_model 参数转换响应
{
"name": "Breaters",
"items": [
{
"name": "Island In The Moon",
"description": "A place to be playin' and havin' fun",
},
{"name": "Holy Buddies"},
],
},
{
"name": "System of an Up",
"items": [
{
"name": "Salt",
"description": "The kombucha mushroom people's favorite",
},
{"name": "Pad Thai"},
{
"name": "Lonely Night",
"description": "The mostests lonliest nightiest of allest",
},
],
},
]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
把dataclasses与其它类型注解组合在一起, 可以组成不同形式的复杂数据结构. 更多内容详见上述代码内注释.
# 深入学习
你还可以把dataclasses与其它Pydantic模型组合在一起, 继承合并的模型, 把它们包含在你自己的模型里. 详见Pydantic文档-数据类.
# 版本
本章内容自FastAPI0.67.0起生效.
# 高级中间件
用户指南介绍了如何为应用添加自定义中间件. 以及如何使用CORSMiddleware处理CORS. 本章学习如何使用其他中间件.
# 添加ASGI中间件
因为FastAPI基于Starlette, 且执行ASGI规范, 所以可以使用任意ASGI中间件. 中间件不必是专为FastAPI或Starlette定制的, 只要遵循ASGI规范即可. 总之, ASGI中间件是类, 并把ASGI应用作为第一个参数. 因此, 有些第三方ASGI中间件的文档推荐以如下方式使用中间件:
from unicorn import UnicornMiddleware
app = SomeASGIApp()
new_app = UnicornMiddleware(app, some_config="rainbow")
2
3
4
5
但FastAPI(实际上是Starlette)提供了一种更简单的方式, 能让内部中间件在处理服务器错误的同时, 还能让自定义异常处理器正常运作. 为此, 要使用app.add_middleware()(与CORS中的示例一样).
from fastapi import FastAPI
from unicorn import UnicornMiddleware
app = FastAPI()
app.add_middleware(UnicornMiddleware, some_config="rainbow")
2
3
4
5
6
app.add_middleware()的第一个参数是中间件的类, 其它参数则是要传递给中间件的参数.
# 集成中间件
FastAPI为常见用例提供了一些中间件, 下面介绍怎么使用这些中间件.
技术细节
以下几个示例中也可以使用from starlette.middleware.something import SomethingMiddleware.
FastAPI在fastapi.middleware中提供的中间件只是为了方便开发者使用, 但绝大多数可用的中间件都直接继承自Starlette.
# HTTPSRedirectMiddleware
强制所有传入请求必须是https或wss. 任何转向http或ws的请求都会被重定向至安全方案.
from fastapi import FastAPI
from fastapi.middleware.httsredirect import HTTPSRedirectMiddleware
app = FastAPI()
app.add_middleware(HTTPSRedirectMiddleware)
@app.get("/")
async def main():
return {"message": "Hello World"}
2
3
4
5
6
7
8
9
10
11
# TrustedHostMiddleware
强制所有传入请求都必须正确设置Host请求头, 以防HTTP主机头攻击.
from fastapi import FastAPI
from fastapi.middleware.trustedhost import TrustedHostMiddleware
app = FastAPI()
app.add_middleware(
TrustedHostMiddleware, allowed_hosts=["example.com", "*.example.com"]
)
@app.get("/")
async def main():
return {"message": "Hello World"}
2
3
4
5
6
7
8
9
10
11
12
13
支持以下参数:
allowed_hosts: 允许的域名(主机名)列表.*.example.com等通配符域名可以匹配子域名, 或使用allowed_hosts=["*"]允许任意主机名, 或省略中间件.
如果传入的请求没有通过验证, 则发送400响应.
# GZipMiddleware
处理Accept-Encoding请求头中包含gzip请求的GZip响应. 中间件会处理标准响应与流响应.
from fastapi import FastAPI
from fastapi.middleware.gzip import GZipMiddleware
app = FastAPI()
app.add_middleware(GZipMiddleware, minimum_size=1000, compresslevel=5)
@app.get("/")
async def main():
return "somebigcontent"
2
3
4
5
6
7
8
9
10
11
支持以下参数:
minimum_size: 小于最小字节的响应不使用GZip, 默认值是500.
# 其它中间件
除了上述中间件外, FastAPI还支持其他ASGI中间件. 例如:
其它可用中间件详见Starlette文档-中间件及ASGI Awesome列表.
# 子应用 -- 挂载
如果需要两个独立的FastAPI应用, 拥有各自独立的OpenAPI与文档, 则需设置一个主应用, 并挂载一个(或多个)子应用.
挂载是指在特定路径中添加完全独立的应用, 然后在该路径下使用路径操作声明的子应用处理所有事务.
# 顶层应用
首先, 创建主(顶层)FastAPI应用及其路径操作:
from fastapi import FastAPI
app = FastAPI()
@app.get("/app")
def read_main():
return {"message": "Hello World from main app"}
subapi = FastAPI()
@subapi.get("/sub")
def read_sub():
return {"message": "Hello World from sub API"}
app.mount("/subapi", subapi)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 子应用
接下来, 创建子应用及其路径操作. 子应用只是另一个标准FastAPI应用, 但这个应用是被挂载的应用:
subapi = FastAPI()
@subapi.get("/sub")
def read_sub():
return {"message": "Hello World from sub API"}
2
3
4
5
6
# 挂载子应用
在顶层应用app中, 挂载子应用subapi. 本例的子应用挂载在/subapi路径下:
subapi = FastAPI()
@subapi.get("/sub")
def read_sub():
return {"message": "Hello World from sub API"}
app.mount("/subapi", subapi)
2
3
4
5
6
7
8
9
# 查看文档
查看主文件是main.py, 则用以下uvicorn命令运行主应用:
uvicorn main:app --reload
查看文档http://127.0.0.1:8000/docs, 下图显示的是主应用API文档, 只包括其自有的路径操作.
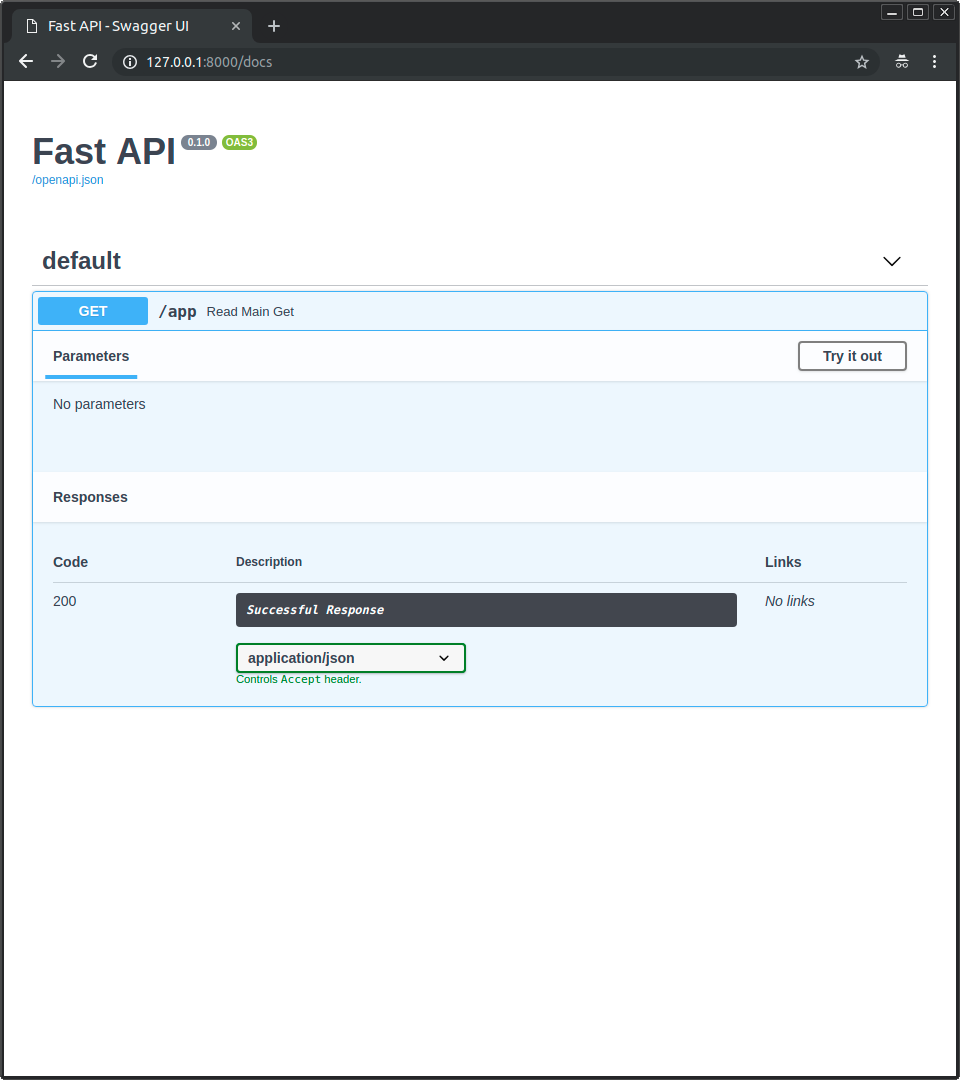
然后查看子应用文档http://127.0.0.1:8000/subapi/docs, 下图显示的是子应用的API文档, 也是只包括其自有的路径操作, 所有这些路径操作都在/subapi子路径前缀下.
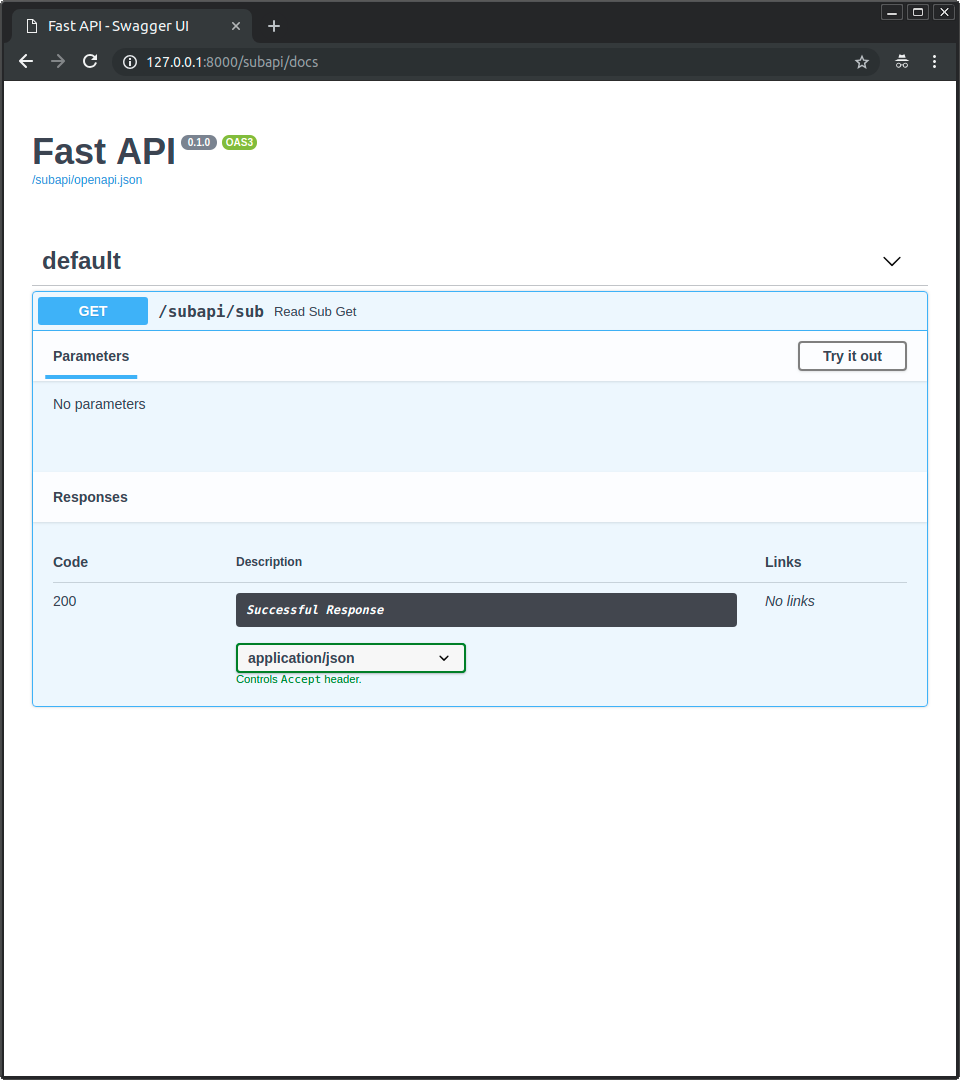
两个用户界面都可以正常运行, 因为浏览器能够与每个指定的应用或子应用会话.
# 技术细节: root_path
以上述方式挂载子应用时, FastAPI使用ASGI规范中的root_path机制处理挂载子应用路径之间的通信. 这样, 子应用就可以为自动文档使用路径前缀. 并且子应用还可以再挂载子应用, 一切都会正常运行, FastAPI可以自动处理所有root_path, 关于root_path及如何显式使用root_path的内容, 详见使用代理一章.
# 使用代理
有些情况下, 你可能要使用Traefik或Nginx等代理服务器, 并添加应用不能识别的附加路径前缀配置. 此时, 要使用root_path配置应用. root_path是ASGI规范提供的机制, FastAPI就是基于此规范开发的(通过Starlette). root_path用于处理这些特定情况. 在挂载子应用时, 也可以在内部使用.
# 移除路径前缀的代理
本例中, 移除路径前缀的代理是指在代码中声明路径/app, 然后在应用顶层添加代理, 把FastAPI应用放在/api/v1路径下. 本例的原始路径/app实际上是在/api/v1/app提供服务. 哪怕所有代码都假设只有/app. 代理只在把请求传送给Uvicorn之前才会移除路径前缀, 让应用以为它是在/app提供服务, 因此不必在代码中加入前缀/api/v1.
但之后, 在(前端)打开API文档时, 代理会要求在/openapi.json, 而不是/api/v1/openapi.json中提取OpenAPI概图. 因此, (运行在浏览器中的)前端会尝试访问/openapi.json, 但没有办法获取OpenAPI概图. 这是应为应用使用了以/api/v1为路径前缀的代理, 前端要从/api/v1/openapi.json中提取OpenAPI概图.

IP 0.0.0.0常用于指程序监听本机或服务器上的所有有效IP.
API文档还需要OpenAPI概图声明API server位于/api/v1(使用代理时的URL). 例如:
{
"openapi": "3.0.2",
// More stuff here
"servers": [
{
"url": "/api/v1"
}
],
"paths": {
// More stuff here
}
}
2
3
4
5
6
7
8
9
10
11
12
本例中的Proxy是Traefik, server是运行FastAPI应用的Uvicorn.
# 提供root_path
为此, 要以如下方式使用命令行选项--root-path:
uvicorn main:app --root-path /api/v1
Hypercorn也支持--root-path选项.
技术细节
ASGI规范定义的root_path就是为了这种用例, 并且--root-path命令行选项支持root_path.
# 查看当前的root_path
获取应用为每个请求使用的当前root_path, 这是scope字典的内容(也是ASGI规范的内容). 我们在这里的信息里包含root_path只是为了演示.
from fastapi import FastAPI, Request
app = FastAPI()
@app.get("/app")
def read_main(request: Request):
return {"message": "Hello World", "root_path": request.scope.get("root_path")}
2
3
4
5
6
7
8
然后, 用以下命令启动Uvicorn:
uvicorn main:app --root-path /api/v1
返回的响应如下:
{
"message": "Hello World",
"root_path": "/api/v1"
}
2
3
4
# 在FastAPI应用里设置root_path
还有一种方案, 如果不能提供--root-path或等效的命令行选项, 则在创建FastAPI应用时要设置root_path参数.
from fastapi import FastAPI, Request
app = FastAPI(root_path="/api/v1")
@app.get("/app")
def read_main(request: Request):
return {"message": "Hello World", "root_path": request.scope.get("root_path")}
2
3
4
5
6
7
8
传递给root_path给FastAPI与传递--root-path命令行选项给Uvicorn或Hypercorn一样.
# 关于root_path
注意, 服务器(Uvicorn)只是把root_path传递给应用. 在浏览器中输入http://127.0.0.1:8000时能看到标准响应:
{
"message": "Hello World",
"root_path": "/api/v1"
}
2
3
4
它不要求访问http://127.0.0.1:8000/api/v1/app. Uvicorn预期代理在http://127.0.0.1:8000/app访问Uvicorn, 而在顶部添加/api/v1前缀是代理要做的事情.
# 关于移除路径前缀的代理
注意, 移除路径前缀的代理只是配置代理的方式之一. 大部分情况下, 代理默认都不会移除路径前缀. (未移除路径前缀时)代理监听https://myawesomeapp.com等对象, 如果浏览器跳转到https://myawesomeapp.com/api/v1/app, 且服务器(例如Uvicorn)监听http://127.0.0.1:8000代理(未移除路径前缀)会在同样的路径: http://127.0.0.1:8000/api/v1/app访问Uvicorn.
# 本地测试Traefik
你可以轻易地在本地使用Traefik运行移除路径前缀的试验. 下载Traefik, 这是一个二进制文件, 需要解压文件, 并在Terminal中直接运行. 然后创建包含如下内容的traefik.toml文件:
[entryPoints]
[entryPoints.http]
address = ":9999"
[providers]
[providers.file]
filename = "routes.toml"
2
3
4
5
6
7
这个文件把Traefik监听端口设置为9999, 并设置要使用另一个文件routes.toml.
使用端口9999代理标准的HTTP端口80, 这样就不必使用管理员权限运行(sudo).
接下来, 创建routes.toml:
[http]
[http.middlewares]
[http.middlewares.api-stripprefix.stripPrefix]
prefixes = ["/api/v1"]
[http.routers]
[http.routers.app-http]
entryPoints = ["http"]
service = "app"
rule = "PathPrefix(`/api/v1`)"
middlewares = ["api-stripprefix"]
[http.services]
[http.services.app]
[http.services.app.loadBalancer]
[[http.services.app.loadBalancer.servers]]
url = "http://127.0.0.1:8000"
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
这个文件配置Traefik使用路径前缀/api/v1. 然后, 它把请求重定位到运行在http://127.0.0.1:8000上的Uvicorn. 现在, 启动Traefik:
./traefik --configFile=traefik.toml
接下来, 使用Uvicorn启动应用, 并使用--root-path选项:
uvicorn main:app --root-path /api/v1
# 查看响应
访问含Uvicorn端口的URL: http://127.0.0.1:8000/app, 就能看到标准响应:
{
"message": "Hello World",
"root_path": "/api/v1"
}
2
3
4
注意, 就算访问http://127.0.0.1:8000/app, 也显示从选项--root-path中提取的/api/v1, 这是root_path的值.
打开含Traefik端口的URL, 包含路径前缀: http://127.0.0.1:9999/api/v1/app. 得到同样的响应:
{
"message": "Hello World",
"root_path": "/api/v1"
}
2
3
4
但这一次URL包含了代理提供的路径前缀: /api/v1. 当然, 这是通过代理访问应用的方式, 因此, 路径前缀/app/v1版本才是正确的. 而不带路径前缀的版本(http://127.0.0.1:8000/app), 则由Uvicorn直接提供, 专供代理(Traefik)访问. 这演示了代理(Traefik)如何使用路径前缀, 以及服务器(Uvicorn)如何使用选项--root-path中的root_path.
# 查看文档
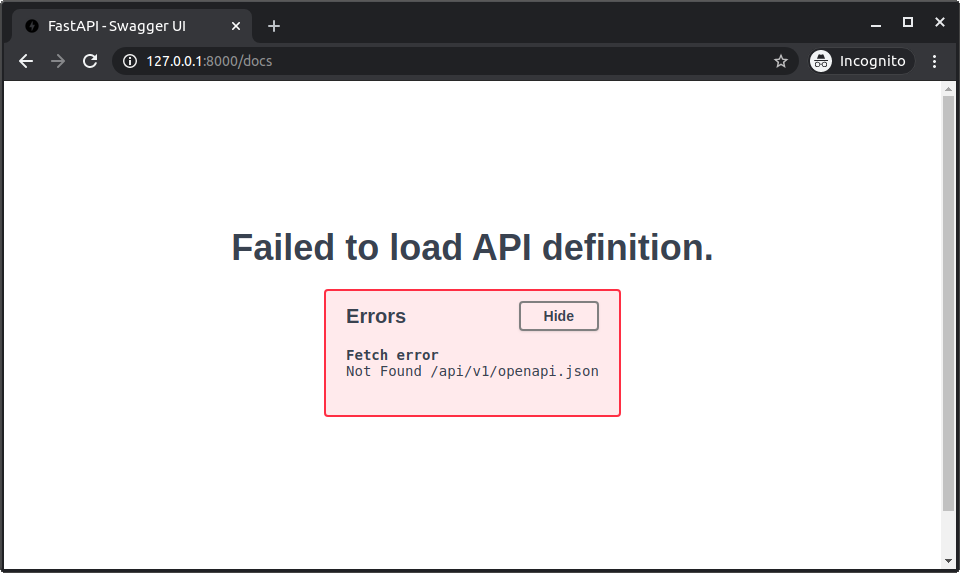
这才是有趣的地方, 访问应用的官方方式是通过含路径前缀的代理, 因此, 不出所料, 如果没有在URL中添加路径前缀, 直接访问通过Uvicorn运行的API文档, 不能正常访问, 因为需要通过代理才能访问. 输出http://127.0.0.1:8000/docs查看API文档
但输入官方链接/api/v1/docs, 并使用端口9999访问API文档, 就能正常运行了. 输出http://127.0.0.1:9999/api/v1/docs查看文档:
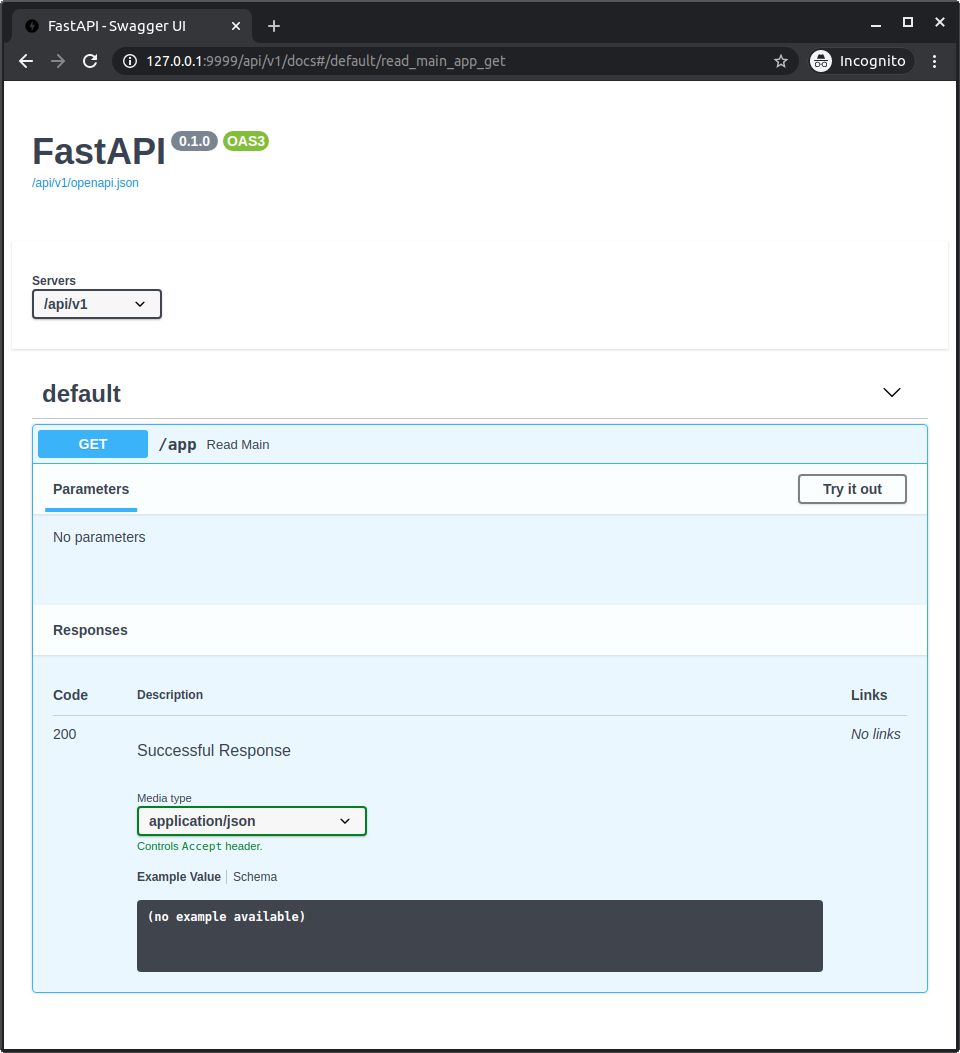
这是因为FastAPI在OpenAPI里使用root_path提供的URL创建默认server.
# 附加的服务器
此用例较难, 可以跳过.
默认情况下, FastAPI使用root_path的链接在OpenAPI概图中创建server. 但也可以使用其他备选servers, 例如, 需要同一个API文档与staging和生产环境交互. 如果传递自定义servers列表, 并有root_path(因为API使用了代理), FastAPI会在列表开头使用这个root_path插入服务器.
from fastapi import FastAPI, Request
app = FastAPI(
servers=[
{"url": "https://stag.example.com", "description": "Staging environment"},
{"url": "https://prod.example.com", "description": "Production environment"},
],
root_path="/api/v1",
)
@ap.get("/app")
def read_main(request: Request):
return {"message": "Hello World", "root_path": request.scope.get("root_path")}
2
3
4
5
6
7
8
9
10
11
12
13
14
这段代码将产生如下OpenAPI概图:
{
"openapi": "3.0.2",
// More stuff here
"servers": [
{
"url": "/api/v1"
},
{
"url": "https://stag.example.com",
"description": "Staging environment"
},
{
"url": "https://prod.example.com",
"description": "Production environment"
}
],
"paths": {
// More stuff here
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
注意, 自动生成服务器时, url的值/api/v1提取自root_path.
http://127.0.0.1:9999/api/v1/docs的API文档所示如下:
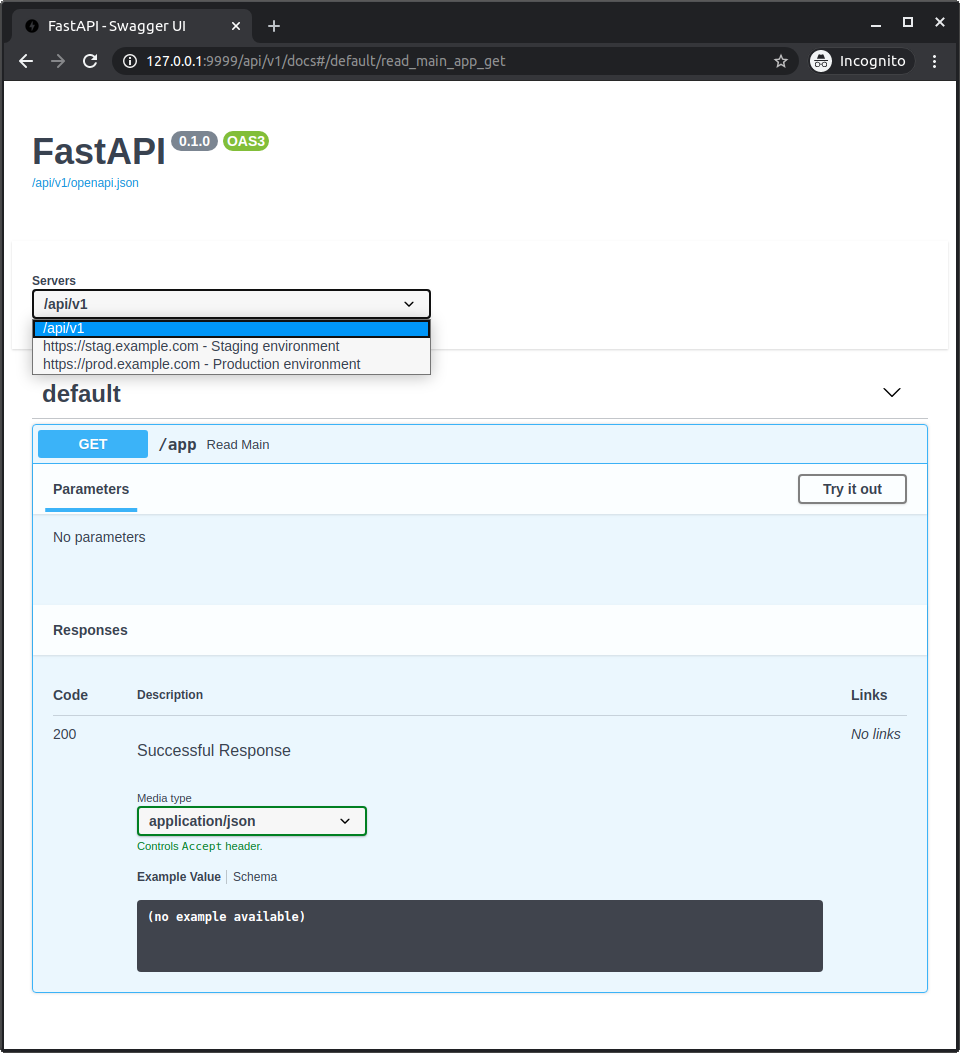
API文档与所选的服务器进行交互.
# 从root_path禁用自动服务器
如果不想让FastAPI包含使用root_path的自动服务器, 则要使用参数root_path_in_servers=False:
from fastapi import FastAPI, Request
app = FastAPI(
servers=[
{"url": "https://stag.example.com", "description": "Staging environment"},
{"url": "https://prod.example.com", "description": "Production environment"},
],
root_path="/api/v1",
root_path_in_servers=False,
)
@app.get("/app")
def read_main(request: Request):
return {"message": "Hello World", "root_path": request.scope.get("root_path")}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
这样, 就不会在OpenAPI概图中包含服务器了.
# 挂载子应用
如需挂载子应用(详见子应用-挂载), 也要通过root_path使用代理, 这与正常应用一样, 别无二致. FastAPI在内部使用root_path, 因此子应用也可以正常运行.
# 模板
FastAPI支持多种模板引擎, Flask等工具使用的Jinja2是最常用的模板引擎. 在Starlette的支持下, FastAPI应用可以直接使用工具轻易地配置Jinja2.
# 安装依赖项
安装jinja2:
pip install jinja2
# 使用Jinja2Templates
- 导入
Jinja2Templates - 创建可复用的
templates对象 - 在返回模板的路径操作中声明
Request参数 - 使用
templates渲染并返回TemplateResponse, 传递模板的名称, request对象以及一个包含多个键值对(用于Jinja2模板)的"context"字典
from fastapi import FastAPI, Request
from fastapi.responses import HTMLResponse
from fastapi.staticfiles import StaticFiles
from fastapi.templating import Jinja2Templates
app = FastAPI()
app.mount("/static", StaticFiles(directory="static"), name="static")
templates = Jinja2Templates(directory="templates")
@app.get("/items/{id}", response_class=HTMLResponse)
async def read_item(request: Request, id: str):
return templates.TemplateResponse(
request=request, name="item.html", context={"id": id}
)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
笔记
在FastAPI 0.108.0, Starlette 0.29.0之前, name是第一个参数. 并且, 在此之前, request对象是作为context的一部分以键值对的形式传递的.
通过声明response_class=HTMLResponse, API文档就能识别响应的对象是HTML.
技术细节
你还可以使用from starlette.templating import Jinja2Templates.
FastAPI的fastapi.templating只是为开发者提供的快捷方式. 实际上, 绝大多数可用响应都直接继承自Starlette. Request与StaticFiles也一样.
# 编写模板
编写模板templates/item.html, 代码如下:
<html>
<head>
<title>Item Details</title>
<link href="{{ url_for('static', path='/styles.css') }}" rel="stylesheet">
</head>
<body>
<h1><a href="{{ url_for('read_item', id=id) }}">Item ID: {{ id }}</a></h1>
</body>
</html>
2
3
4
5
6
7
8
9
# 模板上下文
在包含如下语句的html中:
Item ID: {{ id }}
这将显示你从"context"字典传递的id:
{"id": id}
例如, 当ID为42时, 会渲染成:
Item ID: 42
# 模板url_for参数
你还可以在模板内使用url_for(), 其参数与路径操作函数的参数相同. 所以, 该部分:
<a href="{{ url_for('read_item', id=id) }}">
将生成一个与处理路径操作函数read_item(id=id)的URL相同的链接, 例如, 当ID为42时, 会渲染成:
<a href="/items/42">
# 模板与静态文件
你还可以在模板内部将url_for()用于静态文件, 例如你挂载的name="static"的StaticFiles.
<html>
<head>
<title>Item Details</title>
<link href="{{ url_for('static', path='/styles.css') }}" rel="stylesheet">
</head>
<body>
<h1><a href="{{ url_for('read_item', id=id) }}">Item ID: {{ id }}</a></h1>
</body>
</html>
2
3
4
5
6
7
8
9
本例中, 它将链接到static/styles.css中的CSS文件:
h1 {
color: green;
}
2
3
因为使用了StaticFiles, FastAPI应用会自动提供位于URL /static/styles.css的CSS文件.
# 更多说明
包括测试模板等更多详情, 请参阅Starlette官方文档-模板.
# Websockets
你可以在FastAPI中使用WebSockets.
# 安装WebSockets
首先, 你需要安装WebSockets:
pip install websockets
# WebSockets客户端
在你的生产系统中, 你可能使用现代框架(如React, Vue.js或Angular)创建了一个前端. 要使用WebSockets与后端进行通信, 你可能会使用前端工具. 或者, 你可能有一个原生移动应用程序, 直接使用原生代码与WebSocket后端通信. 或者, 你可能有其他与WebSocket终端通信的方式.
但是, 在本示例中, 我们将使用一个非常简单的HTML文档, 其中包含一些JavaScript, 全部放在一个长字符串中. 当然, 这并不是最优的做法, 你不应该在生产环境中使用它. 在生产环境中, 你应该选择上述任一选项. 但这是一种专注于WebSockets的服务器端并提供一个工作示例的最简单方式:
from fastapi import FastAPI, WebSocket
from fastapi.responses import HTMLResponse
app = FastAPI()
html = """
<!DOCTYPE html>
<html>
<head>
<title>Chat</title>
</head>
<body>
<h1>WebSocket Chat</h1>
<form action="" onsubmit="sendMessage(event)">
<input type="text" id="messageText" autocomplete="off"/>
<button>Send</button>
</form>
<ul id='messages'>
</ul>
<script>
var ws = new WebSocket("ws://localhost:8000/ws");
ws.onmessage = function(event) {
var messages = document.getElementById('messages')
var message = document.createElement('li')
var content = document.createTextNode(event.data)
message.appendChild(content)
messages.appendChild(message)
};
function sendMessage(event) {
var input = document.getElementById("messageText")
ws.send(input.value)
input.value = ''
event.preventDefault()
}
</script>
</body>
</html>
"""
@app.get("/")
async def get():
return HTMLResponse(html)
@app.websocket("/ws")
async def websocket_endpoint(websocket: WebSocket):
await websocket.accept()
while True:
data = await websocket.receive_text()
await websocket.send_text(f"Message text was: {data}")
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
# 创建websocket
在你的FastAPI应用程序中, 创建一个websocket.
技术细节
你也可以使用from starlette.websockets import WebSocket.
FastAPI直接提供了相同的WebSocket, 只是为了方便开发人员, 但它直接来自Starlette.
# 等待消息并发送消息
在你的WebSocket路由中, 你可以使用await等待消息并发送消息. 你可以接收和发送二进制, 文本和JSON数据.
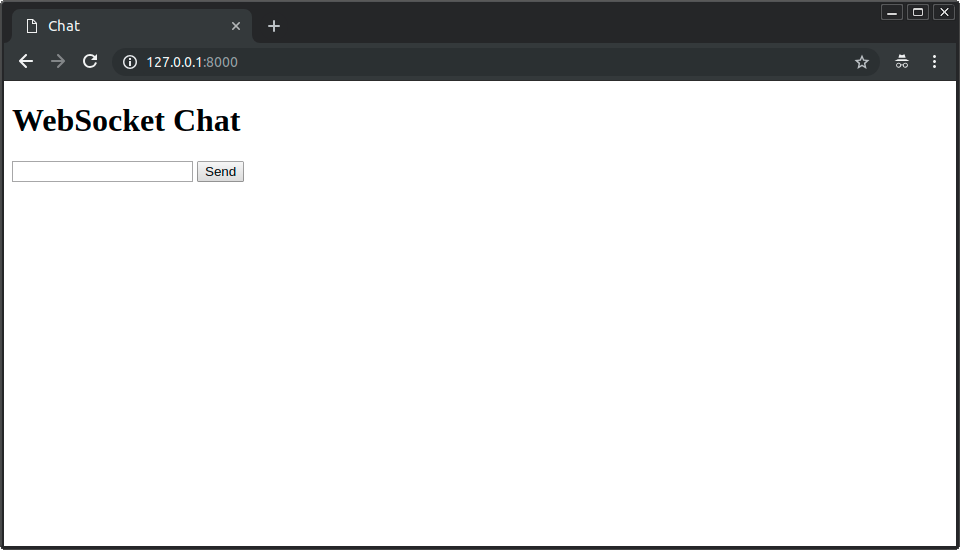
# 尝试一下
如果你的文件名为main.py, 请使用以下命令运行应用程序:
uvicorn main:app --reload
在浏览器中打开http://127.0.0.1:8000. 你将看到一个简单的页面, 如下所示:
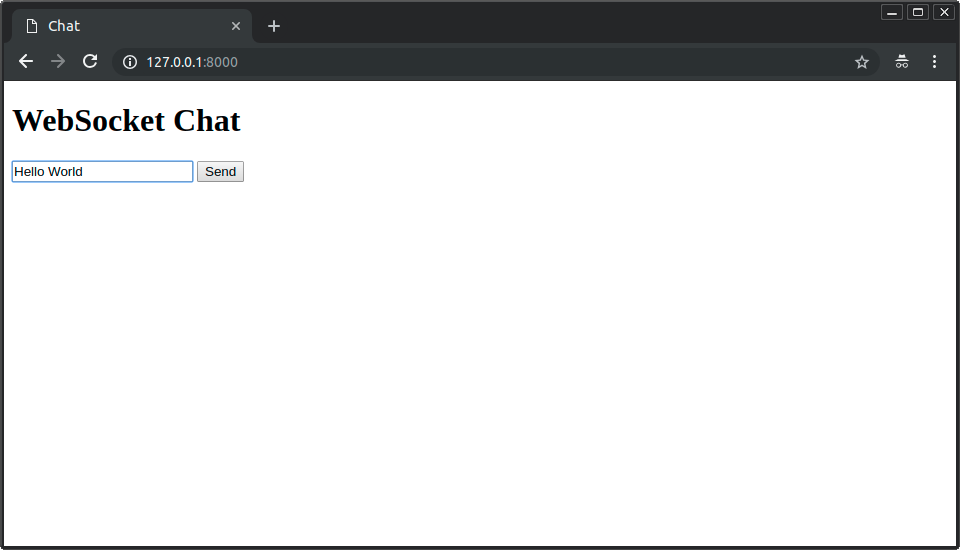
你可以在输入框中输入消息并发送:
你的FastAPI应用程序将回复:
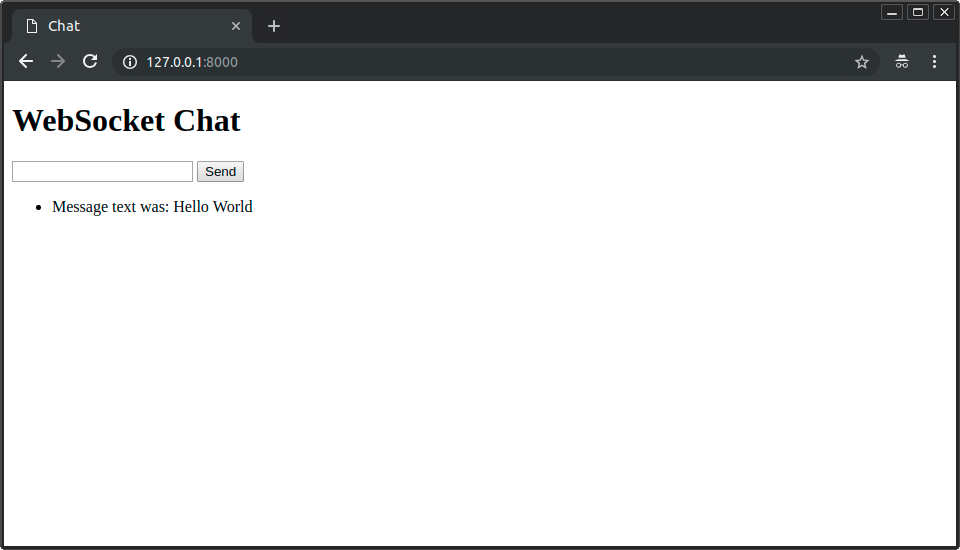
你可以发送(和接收)多条消息:
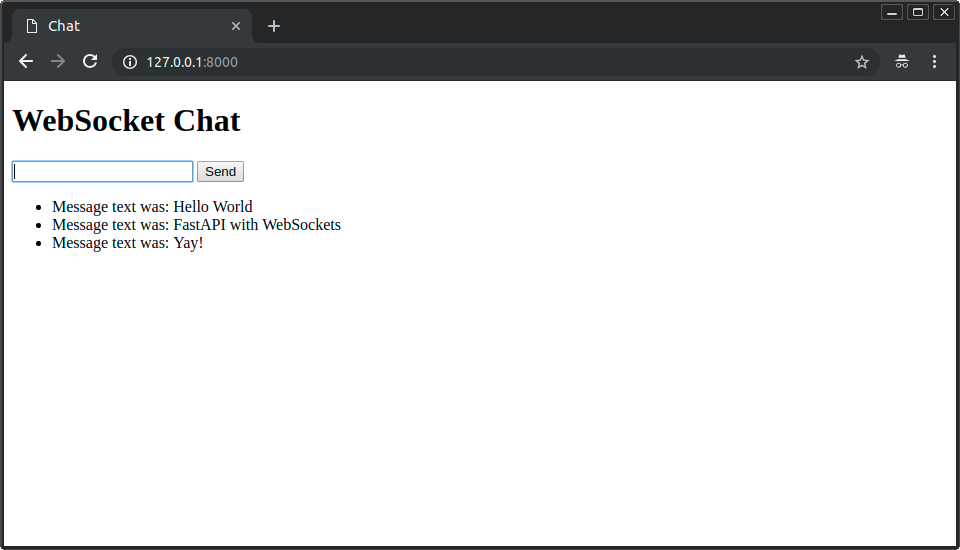
所有这些消息都将使用同一个WebSocket连接.
# 使用Depends和其他依赖项
在WebSocket端点中, 你可以从fastapi导入并使用以下内容:
DependsSecurityCookieHeaderPathQuery
它们的工作方式与其他FastAPI端点/路径操作相同:
from typing import Annotated
from fastapi import (
Cookie,
Depends,
FastAPI,
Query,
WebSocket,
WebSocketException,
status,
)
from fastapi.responses import HTMLResponse
app = FastAPI()
html = """
<!DOCTYPE html>
<html>
<head>
<title>Chat</title>
</head>
<body>
<h1>WebSocket Chat</h1>
<form action="" onsubmit="sendMessage(event)">
<label>Item ID: <input type="text" id="itemId" autocomplete="off" value="foo"/></label>
<label>Token: <input type="text" id="token" autocomplete="off" value="some-key-token"/></label>
<button onclick="connect(event)">Connect</button>
<hr>
<label>Message: <input type="text" id="messageText" autocomplete="off"/></label>
<button>Send</button>
</form>
<ul id='messages'>
</ul>
<script>
var ws = null;
function connect(event) {
var itemId = document.getElementById("itemId")
var token = document.getElementById("token")
ws = new WebSocket("ws://localhost:8000/items/" + itemId.value + "/ws?token=" + token.value);
ws.onmessage = function(event) {
var messages = document.getElementById('messages')
var message = document.createElement('li')
var content = document.createTextNode(event.data)
message.appendChild(content)
messages.appendChild(message)
};
event.preventDefault()
}
function sendMessage(event) {
var input = document.getElementById("messageText")
ws.send(input.value)
input.value = ''
event.preventDefault()
}
</script>
</body>
</html>
"""
@app.get("/")
async def get():
return HTMLResponse(html)
async def get_cookie_or_token(
websocket: WebSocket,
session: Annotated[str | None, Cookie()] = None,
token: Annotated[str | None, Query()] = None,
):
if session is None and token is None:
raise WebSocketException(code=status.WS_1008_POLICY_VIOLATION)
return session or token
@app.websocket("/items/{item_id}/ws")
async def websocket_endpoint(
*,
websocket: WebSocket,
item_id: str,
q: int | None = None,
cookie_or_token: Annotated[str, Depends(get_cookie_or_token)],
):
await websocket.accept()
while True:
data = await websocket.receive_text()
await websocket.send_text(
f"Session cookie or query token value is: {cookie_or_token}"
)
if q is not None:
await websocket.send_text(f"Query parameter q is: {q}")
await websocket.send_text(f"Message text was: {data}, for item ID: {item_id}")
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
由于这是一个WebSocket, 抛出HTTPException并不是很合理, 而是抛出WebSocketException. 你可以使用规范中定义的有效代码.
# 尝试带有依赖项的WebSockets
如果你的文件名为main.py, 请使用以下命令运行应用程序:
uvicorn main:app --reload
在浏览器中打开http://127.0.0.1:8000. 在页面中, 你可以设置:
- "Item ID", 用于路径
- "Token", 作为查询参数.
注意, 查询参数token将由依赖项处理.
通过这样, 你可以连接WebSocket, 然后发送和接收消息:
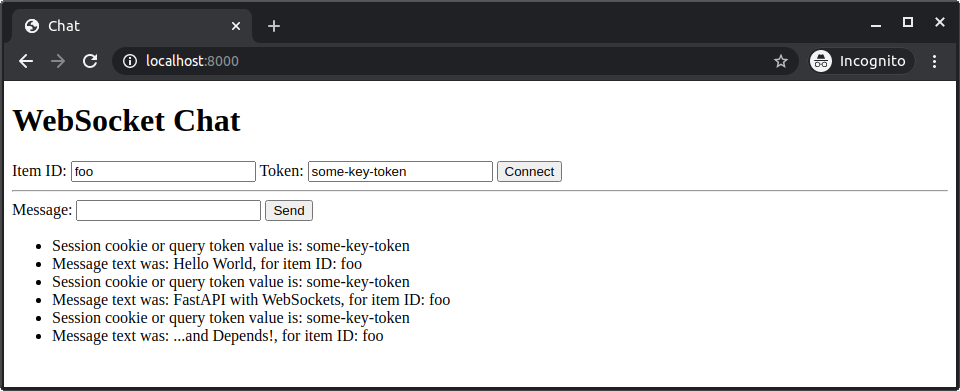
# 处理断开连接和多个客户端
当WebSocket连接关闭时, await websocket.receive_text()将引发WebSocketDisconnect异常, 你可以捕获并处理该异常, 就像本示例中的实例一样.
from fastapi import FastAPI, WebSocket, WebSocketDisconnect
from fastapi.responses import HTMLResponse
app = FastAPI()
html = """
<!DOCTYPE html>
<html>
<head>
<title>Chat</title>
</head>
<body>
<h1>WebSocket Chat</h1>
<h2>Your ID: <span id="ws-id"></span></h2>
<form action="" onsubmit="sendMessage(event)">
<input type="text" id="messageText" autocomplete="off"/>
<button>Send</button>
</form>
<ul id='messages'>
</ul>
<script>
var client_id = Date.now()
document.querySelector("#ws-id").textContent = client_id;
var ws = new WebSocket(`ws://localhost:8000/ws/${client_id}`);
ws.onmessage = function(event) {
var messages = document.getElementById('messages')
var message = document.createElement('li')
var content = document.createTextNode(event.data)
message.appendChild(content)
messages.appendChild(message)
};
function sendMessage(event) {
var input = document.getElementById("messageText")
ws.send(input.value)
input.value = ''
event.preventDefault()
}
</script>
</body>
</html>
"""
class ConnectionManager:
def __init__(self):
self.active_connections: list[WebSocket] = []
async def connect(self, websocket: WebSocket):
await websocket.accept()
self.active_connections.append(websocket)
def disconnect(self, websocket: WebSocket):
self.active_connections.remove(websocket)
async def send_personal_message(self, message: str, websocket: WebSocket):
await websocket.send_text(message)
async def broadcast(self, message: str):
for connection in self.active_connections:
await connection.send_text(message)
manager = ConnectionManager()
@app.get("/")
async def get():
return HTMLResponse(html)
@app.websocket("/ws/{client_id}")
async def websocket_endpoint(websocket: WebSocket, client_id: int):
await manager.connect(websocket)
try:
while True:
data = await websocket.receive_text()
await manager.send_personal_message(f"You wrote: {data}", websocket)
await manager.broadcast(f"Client #{client_id} says: {data}")
except WebSocketDisconnect:
manager.disconnect(websocket)
await manager.broadcast(f"Client #{client_id} left the chat")
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
尝试以下操作:
- 使用多个浏览器选项卡打开应用程序
- 从这些选项卡中发送消息
- 然后关闭其中一个选项卡
这将引发WebSocketDisconnect异常, 并且所有其他客户端都会收到类似以下的消息:
Client #1596980209979 left the chat
上面的应用程序是一个最小的简单示例, 用于演示如何处理和向多个WebSocket连接广播消息. 但请记住, 由于所有内容都在内存中以单个列表的形式处理, 因此它只能在进程运行时工作, 并且只能使用单个进程. 如果你需要与FastAPI集成更简单更强大的功能, 支持Redis, PostgreSQL或其他功能, 请查看encode/broadcaster.
# 更多信息
要了解更多选项, 请查看Starlette的文档:
# 生命周期事件
你可以定义在应用启动前执行的逻辑(代码), 这意味着在应用开始接收请求之前, 这些代码只会被执行一次. 同样地, 你可以定义在应用关闭时应执行的逻辑, 在这种情况下, 这段代码将在处理可能的多次请求后执行一次. 因为这段代码在应用开始接收请求之前执行, 也会在处理可能的若干请求之后执行, 它覆盖了整个应用程序的生命周期(声明周期这个词很重要). 这对于设置你需要在整个应用中使用的资源非常有用, 这些资源在请求之间共享, 你可能需要在之后进行释放. 例如, 数据库连接池, 或加载一个共享的机器学习模型.
# 用例
让我们从一个示例用例开始, 看看如何解决它们. 假设你有几个机器学习的模型, 你想要用它们来处理请求. 相同的模型在请求之间是共享的, 因此并非每个请求或每个用户各自拥有一个模型. 假设加载模型可能需要相当长的时间, 因为它必须从磁盘读取大量数据, 因此你不希望每个请求都加载它.
你可以在模块/文件的顶部加载它, 但这也意味着即使你只是在运行一个简单的自动化测试, 它也会加载模型, 这样测试将变慢, 因为它必须在能够独立运行代码的其他部分之前等待模型加载完成. 这就是我们要解决的问题--在处理请求之前加载模型, 但只是在应用开始接收请求之前, 而不是代码执行时.
# 声明周期lifespan
你可以使用FastAPI()应用的lifespan参数和一个上下文管理器(稍后我将为你展示)来定义启动和关闭的逻辑. 让我们从一个例子开始, 然后详细介绍.
我们使用yield创建了一个异步函数lifespan():
from contextlib import asynccontextmanager
from fastapi import FastAPI
def fake_answer_to_everything_ml_model(x: float):
return x * 42
ml_models = {}
@asynccontextmanager
async def lifespan(app: FastAPI):
# Load the ML model
ml_models["answer_to_everything"] = fake_answer_to_everything_ml_model
yield
# Clean up the ML models and release the resources
ml_models.clear()
app = FastAPI(lifespan=lifespan)
@app.get("/predict")
async def predict(x: float):
result = ml_models["answer_to_everything"](x)
return {"result": result}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
在这里, 我们在yield之前将(虚拟的)模型函数放入机器学习模型的字典中, 以此模拟加载模型的耗时启动操作. 这段代码将在应用程序开始处理请求之前执行, 即启动期间.
然后, 在yield之后, 我们卸载模型. 这段代码将会在应用程序完成处理请求后执行, 即在关闭之前, 这可以释放诸如内存或GPU之类的资源.
关闭事件只会在你停止应用时触发, 可能你需要启动一个新版本, 或者你只是厌倦了运行它.
# 生命周期函数
首先要注意的是, 我们定义了一个带有yield的异步函数, 这与带有yield的依赖项非常相似.
from contextlib import asynccontextmanager
from fastapi import FastAPI
def fake_answer_to_everything_ml_model(x: float):
return x * 42
ml_models = {}
@asynccontextmanager
async def lifespan(app: FastAPI):
# Load the ML model
ml_models["answer_to_everything"] = fake_answer_to_everything_ml_model
yield
# Clean up the ML models and release the resources
ml_models.clear()
app = FastAPI(lifespan=lifespan)
@app.get("/predict")
async def predict(x: float):
result = ml_models["answer_to_everything"](x)
return {"result": result}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
这个函数在yield之前的部分, 会在应用启动前执行, 剩下的部分在yield之后, 会在应用完成后执行.
# 异步上下文管理器
如你所见, 这个函数有一个装饰器@asynccontextmanager, 它将函数转化为所谓的异步上下文管理器.
在Python中, 上下文管理器是一个可以在with语句中使用的东西, 例如, open()可以作为上下文管理器使用.
with open("file.txt") as file:
file.read()
2
Python的最近几个版本也有了一个异步上下文管理器, 你可以通过async with来使用:
async with lifespan(app):
await do_stuff()
2
你可以像上面一样创建了一个上下文管理器或者异步上下文管理器, 它的作用是在进入with块时, 执行yield之前的代码, 并且在离开with块时, 执行yield后面的代码. 但在上面的例子中, 我们并不是直接使用, 而是传递给FastAPI来供其使用. FastAPI()的lifespan参数接受一个异步上下文管理器, 所以我们可以把我们新定义的上下文管理器lifespan传给它.
# 替代事件(弃用)
配置启动和关闭事件的推荐方法是使用FastAPI()应用的lifespan参数, 如前所示, 如果你提供了一个lifespan参数, 启动(startup)和关闭(shutdown)事件处理器将不再生效. 要么使用lifespan, 要么配置所有事件, 两者不能共用.
有一种替代方法可以定义在启动和关闭期间执行的逻辑. FastAPI支持定义在应用启动前, 或应用关闭时执行的事件处理器(函数). 事件函数既可以声明为异步函数(async def), 也可以声明为普通函数(def).
# startup事件
使用startup事件声明app启动前运行的函数:
from fastapi import FastAPI
app = FastAPI()
items = {}
@app.on_event("startup")
async def startup_event():
items["foo"] = {"name": "Fighters"}
items["bar"] = {"name": "Tenders"}
@app.get("/items/{item_id}")
async def read_items(item_id: str):
return items[item_id]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
本例中, startup事件处理器函数为项目数据库(只是字典)提供了一些初始值, FastAPI支持多个事件处理器函数. 只有所有startup事件处理器运行完毕, FastAPI应用才开始接收请求.
# shutdown事件
使用shutdown事件声明app关闭时运行的函数:
from fastapi import FastAPI
app = FastAPI()
@app.on_event("shutdown")
def shutdown_event():
with open("log.txt", mode="a") as log:
log.write("Application shutdown")
@app.get("/items/")
async def read_items():
return [{"name": "Foo"}]
2
3
4
5
6
7
8
9
10
11
12
13
14
此外, shutdown事件处理器函数在log.txt中写入一行文本Application shutdown.
说明
open()函数中, mode="a"指的是追加, 因此这行文本会添加文件已有内容之后, 不会覆盖之前的内容.
提示
注意, 本例使用Python open() 标准函数与文件交互, 这个函数执行I/O(输入/输出)操作, 需要等待内容写进磁盘. 但open()函数不支持使用async与await. 因此, 声明时间处理函数需要使用def, 不能使用async def.
# startup和shutdown一起使用
启动和关闭的逻辑很可能是连接在一起的, 你可能希望启动某个东西然后结束它, 获取一个资源然后释放它等等. 在不共享逻辑或变量的不同函数中处理这些逻辑比较困难, 因为你需要在全局变量中存储值或使用类似的方式. 因此, 推荐使用lifespan.
# 技术细节
只是为好奇者提供的技术细节. 在底层, 这部分是声明周期协议的一部分, 参见ASGI技术规范, 定义了称为启动(startup)和关闭(shutdown)的事件.
说明
有关事件处理器的详情, 请参阅Starlette官方文档--事件. 包括如何处理声明周期状态, 这可以用于程序的其他部分.
# 子应用
FastAPI只会触发主应用中的生命周期事件, 不包括子应用--挂载中的.
# 测试 Wwebsockets
测试WebSockets也使用TestClient. 为此, 要在with语句中使用TestClient连接WebSocket.
from fastapi import FastAPI
from fastapi.testclient import TestClient
from fastapi.websockets import WebSocket
app = FastAPI()
@app.get("/")
async def read_main():
return {"msg": "Hello World"}
@app.websocket("/ws")
async def websocket(websocket: WebSocket):
await websocket.accept()
await websocket.send_json({"msg": "Hello WebSocket"})
await websocket.close()
def test_read_main():
client = TestClient(app)
response = client.get("/")
assert response.status_code == 200
assert response.json() == {"msg": "Hello World"}
def test_websocket():
client = TestClient(app)
with client.websocket_connect("/ws") as websocket:
data = websocket.receive_json()
assert data == {"msg": "Hello WebSocket"}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
更多细节详见Starlette 官方文档--测试WebSockets.
# 测试事件: 启动 -- 关闭
使用TestClient和with语句, 在测试中运行事件处理器(startup与shutdown).
from fastapi import FastAPI
from fastapi.testclient import TestClient
app = FastAPI()
items = {}
@app.on_event("startup")
async def startup_event():
items["foo"] = {"name": "Fighters"}
items["bar"] = {"name": "Tenders"}
@app.get("/items/{item_id}")
async def read_items(item_id: str):
return items[item_id]
def test_read_items():
with TestClient(app) as client:
response = client.get("/items/foo")
assert response.status_code = 200
assert response.json() == {"name": {Fighters}}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
# 测试依赖项
有些场景下, 你可能需要在测试时覆盖依赖项, 即不希望运行原有依赖项(及其子依赖项). 反之, 要在测试期间(或只是为某些特定测试)提供只用于测试的依赖项, 并使用此依赖项的值替换原有依赖项的值.
# 用例: 外部服务
常见实例是调用外部第三方身份验证应用, 向第三方应用发送令牌, 然后返回经验证的用户. 但第三方服务商处理每次请求都可能会收费, 并且耗时通常也比调用写死的模拟测试用户更长. 一般只要测试一次外部验证应用就够了, 不必每次测试都去调用. 此时, 最好覆盖调用外部验证应用的依赖项, 使用返回模拟测试用户的自定义依赖项就可以了.
# 使用app.dependency_overrides属性
对于这些用例, FastAPI应用支持app.dependency_overrides属性, 该属性就是字典. 要在测试时覆盖原有依赖项, 这个字典的键应当是原依赖项(函数), 值是覆盖依赖项(另一个函数). 这样一来, FastAPI就会调用覆盖依赖项, 不再调用原依赖项.
from typing import Annotated
from fastapi import Depends, FastAPI
from fastapi.testclient import TestClient
app = FastAPI()
async def common_parameters(q: str | None = None, skip: int = 0, limit: int = 100):
return {"q": q, "skip": skip, "limit": limit}
@app.get("/items/")
async def read_items(commons: Annotated[dict, Depends(common_parameters)]):
return {"message": "Hello Items!", "params": commons}
@app.get("/users/")
async def read_users(commons: Annotated[dict, Depends(common_parameters)]):
return {"message": "Hello Users!", "params": commons}
client = TestClient(app)
async def override_dependency(q: str | None = None):
return {"q": q, "skip": 5, "limit": 10}
app.dependency_overrides[common_parameters] = override_dependency
def test_override_in_items():
response = client.get("/items/")
assert response.status_code = 200
assert response.json() == {
"message": "Hello Items!",
"params": {"q": None, "skip": 5, "limit" 10},
}
def test_override_in_items_with_q():
response = client.get("/items/?q=foo")
assert response.status_code == 200
assert response.json() == {
"message": "Hello Items!",
"params": {"q": "foo", "skip": 5, "limit": 10},
}
def test_override_in_items_with_params():
response = client.get("/items/?q=foo&skip=100&limit=200")
assert response.status_code == 200
assert response.json() == {
"message": "Hello Items!",
"params": {"q": "foo", "skip": 5, "limit": 10},
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
提示
FastAPI应用中的任何位置都可以实现覆盖依赖项, 原依赖项可用于路径操作函数, 路径操作装饰器(不需要返回值时), .include_router()调用等. FastAPI可以覆盖这些位置的依赖项.
然后, 使用app.dependency_overrides把覆盖依赖项重置为空字典:
app.dependency_overrides = {}
提示
如果只在某些测试时覆盖依赖项, 你可以在测试开始时(在测试函数内)设置覆盖依赖项, 并在结束时(在测试函数结尾)重置覆盖依赖项.
# 异步测试
你已经了解了如何使用TestClient测试FastAPI应用程序, 但是到目前为止, 你只了解了如何编写同步测试, 而没有使用async异步函数. 在测试中能够使用异步函数可能会很有用, 比如当您需要异步查询数据库的时候, 想象一下, 你想要测试向FastAPI应用程序发送请求, 然后验证你的后端是否成功在数据库中写入了正确的数据, 与此同时你使用了异步的数据库的库. 让我们看下如何实现这一点.
# pytest.mark.anyio
如果我们想在测试中调用异步函数, 那么我们的测试函数必须是异步的, AnyIO为此提供了一个简洁的插件, 它允许我们指定一些测试函数要异步调用.
# HTTPX
即使你的FastAPI应用程序使用普通的def函数而不是async def, 它本质上仍是一个async异步应用程序.
TestClient在内部通过一些"魔法"操作, 使得你可以在普通的def测试函数中调用异步的FastAPI应用程序, 并使用标准的pytest. 但当我们在异步函数中使用它时, 这种"模范"就不再生效了, 由于测试以异步方式运行, 我们无法在测试函数中继续使用TestClient. TestClient是基于HTTPX的, 幸运的是, 我们可以直接使用它来测试API.
# 示例
举个简单的例子, 让我们来看一个更大的应用和测试中描述的类似文件结构:
.
├── app
│ ├── __init__.py
│ ├── main.py
│ └── test_main.py
2
3
4
5
文件main.py将包含:
from fastapi import FastAPI
app = FastAPI()
@app.get("/")
async def root():
return {"message": "Tomato"}
2
3
4
5
6
7
8
文件test_main.py将包含针对main.py的测试, 现在它可能看起来如下:
import pytest
from httpx import ASGITransport, AsyncClient
from .main import app
@pytest.mark.anyio
async def test_root():
async with AsyncClient(
transport=ASGITransport(app=app), base_url="http://test"
) as ac:
response = await ac.get("/")
assert response.status_code == 200
assert response.json() == {"message": "Tomato"}
2
3
4
5
6
7
8
9
10
11
12
13
14
# 运行测试
你可以通过以下方式运行测试:
pytest
# 详细说明
这个标记@pytest.mark.anyio会告诉pytest该测试函数应该被异步调用:
import pytest
from httpx import ASGITransport, AsyncClient
from .main import app
@pytest.mark.anyio
async def test_root():
async with AsyncClient(
transport=ASGITransport(app=app), base_url="http://test"
) as ac:
response = await ac.get("/")
assert response.status_code == 200
assert response.json() == {"message": "Tomato"}
2
3
4
5
6
7
8
9
10
11
12
13
14
请注意, 测试函数现在用的是async def, 而不是像以前使用TestClient时那样的def.
我们现在可以使用应用程序创建一个AsyncClient, 并使用await向其发送异步请求.
import pytest
from httpx import ASGITransport, AsyncClient
from .main import app
@pytest.mark.anyio
async def test_root():
async with AsyncClient(
transport=ASGITransport(app=app), base_url="http://test"
) as ac:
response = await ac.get("/")
assert response.status_code == 200
assert response.json() == {"message": "Tomato"}
2
3
4
5
6
7
8
9
10
11
12
13
14
这相当于, 我们曾经通过它向TestClient发出请求.
response = client.get('/')
:::itp
请注意, 我们正在将async/await与新的AsyncClient一起使用--请求是异步的.
:::
如果你的应用程序依赖于声明周期事件, AsyncClient将不会触发这些事件, 为了确保它们被触发, 请使用florimondmanca/asgi-lifespan中的LifespanManager.
# 其他异步函数调用
由于测试函数现在是异步的, 因此除了在测试中向FastAPI应用程序发送请求之外, 你现在还可以调用(和使用await等待)其他async异步函数, 就和你在代码中的其他任何地方调用它们的方法一样.
如果你在测试程序中集成异步函数调用的时候遇到一个RuntimeError: Task attached to a different loop的报错(例如, 使用MongoDB的MotorClient时), 请记住, 只能在异步函数中实例化需要事件循环的对象, 例如通过@app.on_event("startup")回调函数进行初始化.
# 设置和环境变量
在许多情况下, 你的应用程序可能需要一些外部设置或配置, 例如密钥, 数据库凭据, 电子邮件服务的凭据等等. 这些设置中的大多数是可变的(可以更改的), 比如数据库的URL, 而且许多设置可能是敏感的, 比如密钥. 因此, 通常会将它们提供为由应用程序读取的环境变量.
# 环境变量
如果你已经知道什么是环境变量以及如何使用它们, 请跳到下一节.
环境变量(也称为"env var")是一种存在于Python代码之外, 存在于操作系统中的变量, 可以被你的Python代码(或其他程序)读取. 你可以在shell中创建和使用环境变量, 而无需使用Python:
# 你可以创建一个名为MY_NAME的环境变量
export MY_NAME="Wade Wilson"
# 然后可以与其他程序一起使用它
echo "Hello $MY_NAME"
# Hello Wade Wilson
2
3
4
5
6
7
# 在Python中读取环境变量
你可以在Python之外的地方(例如终端或使用其他任何方法)创建环境变量, 然后在Python中读取它们. 例如, 你可以有一个名为main.py的文件, 其中包含以下内容:
import os
name = os.getenv("MY_NAME", "World")
print(f"Hello {name} from Python")
2
3
4
os.getenv()的第二个参数是要返回的默认值. 如果没有提供默认值, 默认为None, 此处我们提供了"World"作为要使用的默认值.
然后你可以调用该Python程序:
# 这里我们还没有设置环境变量
python main.py
# 因为我们没有设置环境变量, 所以我们得到默认值
Hello World from Python
# 但是如果我们先创建一个环境变量
export MY_NAME="Wade Wilson"
# 然后再次调用程序
python main.py
# 现在它可以读取环境变量
Hello Wade Wilson from Python
2
3
4
5
6
7
8
9
10
11
12
13
14
由于环境变量可以在代码之外设置, 但可以由代码读取, 并且不需要与其他文件一起存储(提交到git), 因此通常将它们用于配置或设置. 你还可以仅为特定程序调用创建一个环境变量, 该环境变量仅对该程序可用, 并且仅在其运行期间有效. 要做到这一点, 在程序本身之前的同一行创建它:
# 在此程序调用行中创建一个名为MY_NAME的环境变量
MY_NAME="Wade Wilson" python main.py
# 现在它可以读取环境变量
Hello Wade Wilson from Python
# 之后环境变量不再存在
python main.py
Hello World from Python
2
3
4
5
6
7
8
9
10
你可以在Twelve-Factor APP: Config中阅读更多相关信息.
# 类型和验证
这些环境变量只能处理文本字符串, 因为它们是外部于Python的, 并且必须与其他程序和整个系统兼容(甚至与不同的操作系统, 如Linux, Windows, macOS). 这意味着从环境变量中在Python中读取的任何值都将是str类型, 任何类型的转换或验证都必须在代码中完成.
# Pydantic的Settings
幸运的是, Pydantic提供了一个很好的工具来处理来自环境变量的设置, 即Pydantic: Settings management.
# 创建Settings对象
从Pydantic导入BaseSettings并创建一个子类, 与Pydantic模型非常相似. 与Pydantic模型一样, 你使用类型注释声明类属性, 还可以指定默认值. 你可以使用与Pydantic模型相同的验证功能和工具, 比如不同的数据类型和使用Field()进行附加验证.
from fastapi import FastAPI
from pydantic_settings import BaseSettings
class Settings(BaseSettings):
app_name: str = "Awesome API"
admin_email: str
items_per_user: int = 50
settings = Settings()
app = FastAPI()
@app.get("/info")
async def info():
return {
"app_name": settings.app_name,
"admin_email": settings.admin_email,
"items_per_user": settings.items_per_user,
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
如果你需要一个快速的复制粘贴示例, 请不要使用此示例, 而应使用下面的最后一个示例.
然后, 当你创建该Settings类的实例(在此示例中是settings对象)时, Pydantic将以不区分大小写的方式读取环境变量, 因此, 大写的变量APP_NAME仍将为属性app_name读取. 然后, 它将转换和验证数据. 因此, 当你使用该settings对象时, 你将获得你声明的类型的数据(例如items_per_user将为int类型).
# 使用settings
然后, 你可以在应用程序中使用新的settings对象:
from fastapi import FastAPI
from pydantic_settings import BaseSettings
class Settings(BaseSettings):
app_name: str = "Awesome API"
admin_email: str
items_per_user: int = 50
settings = Settings()
app = FastAPI()
@app.get("/info")
async def info():
return {
"app_name": settings.app_name,
"admin_email": settings.admin_email,
"items_per_user": settings.items_per_user,
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# 运行服务器
接下来, 你将运行服务器, 并将配置作为环境变量传递. 例如, 你可以设置一个ADMIN_EMAIL和APP_NAME, 如下所示:
ADMIN_EMAIL="deadpool@example.com" APP_NAME="ChimichangApp" uvicorn main:app
要为单个命令设置多个环境变量, 只需用空格分隔它们, 并将它们全部放在命令之前.
然后, admin_email设置为"deadpool@example.com", app_name将为"ChimichangApp", 而items_per_user将保持其默认值为50.
# 在另一个模块中设置
你可以将这些设置放在另一个模块文件中, 就像你在Bigger Applications -- Multiple Files中所见的那样. 例如, 你可以创建一个名为config.py的文件, 其中包含以下内容:
from pydantic_settings import BaseSettings
class Settings(BaseSettings):
app_name: str = "Awesome API"
admin_email: str
items_per_user: int = 50
settings = Settings()
2
3
4
5
6
7
8
9
10
然后在一个名为main.py的文件中使用它:
from fastapi import FastAPI
from .config import settings
app = FastAPI()
@app.get("/info")
async def info():
return {
"app_name": settings.app_name,
"admin_email": settings.admin_email,
"items_per_user": settings.items_per_user,
}
2
3
4
5
6
7
8
9
10
11
12
13
14
你还需要一个名为__init__.py的文件, 就像你在Bigger Applications -- Multiple Files中看到的那样.
# 在依赖项中使用设置
在某些情况下, 从依赖项中提供设置可能比在所有地方都使用全局对象settings更有用. 这在测试期间尤其有用, 因为很容易用自定义设置覆盖依赖项.
# 配置文件
根据前面的示例, 你的config.py文件可能如下所示:
from pydantic_settings import BaseSettings
class Settings(BaseSettings):
app_name: str = "Awesome API"
admin_email: str
items_per_user: int = 50
2
3
4
5
6
7
请注意, 现在我们不创建默认实例settings = Settings().
# 主应用程序文件
现在我们创建一个依赖项, 返回一个新的config.Settings().
from functools import lru_cache
from typing import Annotated
from fastapi import Depends, FastAPI
from .config import Settings
app = FastAPI()
@lru_cache
def get_settings():
return Settings()
@app.get("/info")
async def info(settings: Annotated[Settings, Depends(get_settings)]):
return {
"app_name": settings.app_name,
"admin_email": settings.admin_email,
"items_per_user": settings.items_per_user,
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
我们稍后会讨论@lru_cache, 目前, 你可以将get_settings()视为普通函数.
然后, 我们可以将其作为依赖项从"路径操作函数"中引入, 并在需要时使用它.
from functools import lru_cache
from typing import Annotated
from fastapi import Depends, FastAPI
from .config import Settings
app = FastAPI()
@lru_cache
def get_settings():
return Settings()
@app.get("/info")
async def info(settings: Annotated[Settings, Depends(get_settings)]):
return {
"app_name": settings.app_name,
"admin_email": settings.admin_email,
"items_per_user": settings.items_per_user,
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# 设置和测试
然后, 在测试期间, 通过创建get_settings的依赖项覆盖, 很容易提供一个不同的设置对象:
from fastapi.testclient import TestClient
from .config import Settings
from .main import app, get_settings
client = TestClient(app)
def get_settings_override():
return Settings(admin_email="testing_admin@example.com")
app.dependency_override[get_settings] = get_settings_override
def test_app():
response = client.get("/info")
data = response.json()
assert data == {
"app_name": "Awesome API",
"admin_email": "testing_admin@example.com",
"items_per_user": 50,
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
在依赖项覆盖中, 我们在创建新的Settings对象时为admin_email设置了一个新值, 然后返回该新对象. 然后, 我们可以测试它是否被使用.
# 从.env文件中读取设置
如果你有许多可能经常更改的设置, 可能在不同的环境中, 将它们放在一个文件中, 然后从该文件中读取它们, 就像它们是环境变量一样, 可能非常有用. 这种做法相当常见, 有一个名称, 这些环境变量通常放在一个名为.env的文件中, 该文件被称为"dotenv".
以点(.)开头的文件时Unix-like系统(如Linux何macOS)中的隐藏文件. 但是, dotenv文件实际上不一定要具有确切的文件名.
Pydantic支持使用外部库从这些类型的文件中读取, 你可以在Pydantic设置: Dotenv(.env)支持中阅读更多相关信息.
要使其工作, 你需要执行pip install python-dotenv.
# .env文件
你可以使用以下内容创建一个名为.env的文件:
ADMIN_EMAIL="deadpool@example.com"
APP_NAME="ChimichangApp"
2
# 从.env文件中读取设置
然后, 你可以使用以下方式更新你的config.py:
from pydantic_settings import BaseSettings
class Settings(BaseSettings):
app_name: str = "Awesome API"
admin_email: str
items_per_user: int = 50
class Config:
env_file = ".env"
2
3
4
5
6
7
8
9
10
在这里, 我们在Pydantic的Settings类中创建了一个名为Config的类, 并将env_file设置为我们想要使用的dotenv文件的文件名.
Config类仅用于Pydantic配置, 你可以在Pydantic Model Config中阅读更多相关信息.
# 使用lru_cache仅创建一次Settings
从磁盘中读取文件通常是一项耗时的(慢)操作, 因此你可能希望仅在首次读取后并重复使用相同的设置对象, 而不是为每个请求都读取它.
但是, 每次执行以下操作:
Settings()
都会创建一个新的Settings对象, 并且在创建时会再次读取.env文件. 如果依赖项函数只是这样的:
def get_settings():
return Settings()
2
我们将为每个请求创建该对象, 并且将在每个请求中读取.env文件. 但是, 由于我们在顶部使用了@lru_cache装饰器, 因此只有在第一次调用它时, 才会创建Settings对象一次.
from functools import lru_cache
from fastapi import Depends, FastAPI
from typing_extensions import Annotated
from . import config
app = FastAPI()
@lru_cache
def get_settings():
return config.Settings()
@app.get("/info")
async def info(settings: Annotated[config.Settings, Depends(get_settings)])::
return {
"app_name": settings.app_name,
"admin_email": settings.admin_email,
"items_per_user": settings.items_per_user,
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
然后, 在下一次请求的依赖项中对get_settings()进行任何后续调用时, 它不会执行get_settings()的内部代码并创建新的Settings对象, 而是返回在第一次调用时返回的相同对象, 一次又一次.
# lru_cache技术细节
@lru_cache修改了它所装饰的函数, 以返回第一次返回的相同值, 而不是再次计算它, 每次都执行函数的代码. 因此, 下面的函数将对每个参数组合执行一次. 然后, 每个参数组合返回的值将在使用完全相同的参数组合调用函数时再次使用. 例如, 如果你有一个函数:
@lru_cache
def say_hi(name: str, salutation: str = "Ms."):
return f"Hello {salutation} {name}"
2
3

对于我们的依赖项get_settings(), 该函数甚至不接受任何参数, 因此它始终返回相同的值. 这样, 它的行为几乎就像是一个全局变量, 但是由于它使用了依赖项函数, 因此我们可以轻松地进行测试时的覆盖.
@lru_cache是functools的一部分, 它是Python标准库的一部分, 你可以在Python文档中了解有关@lru_cache的更多信息.
# 小结
你可以使用Pydantic设置处理应用程序的设置或配置, 利用Pydantic模型的所有功能.
- 通过使用依赖项, 你可以简化测试.
- 可以使用
.env文件 - 使用
@lru_cache可以避免为每个请求重复读取dotenv文件, 同时允许你在测试时进行覆盖.
# OpenAPI 回调
你可以创建触发外部API请求的路径操作API, 这个外部API可以是别人创建的, 也可以是由你自己创建的. API应用调用外部API时的流程叫做回调, 因为外部开发者编写编写的软件发送请求至你的API, 然后你的API药进行回调, 并把请求发送至外部API. 此时, 我们需要存档外部API的信息, 比如应该有哪些路径操作, 返回什么样的请求体, 应该返回哪种响应等.
# 使用回调的应用
示例如下, 假设要开发一个创建发票的应用. 发票包括id, title(可选), customer, total等属性. API的用户(外部开发者)要在你的API内使用POST请求创建一条发票记录. (假设)你的API将:
- 把发票发送至外部开发者的消费者
- 归集现金
- 把通知发送至API的用户(外部开发者)
- 通过(从你的API)发送POST请求至外部API(即回调)来完成
# 常规FastAPI应用
添加回调前, 首先看下常规API应用是什么样子. 常规API应用包含接收Invoice请求体的路径操作, 还有包含回调URL的查询参数callback_url. 这部分代码很常规, 你对绝大多数代码应该都比较熟悉了:
from typing import Union
from fastapi import APIRouter, FastAPI
from pydantic import BaseModel, HttpUrl
app = FastAPI()
class Invoice(BaseModel):
id: str
title: Union[str, None] = None
customer: str
total: float
class InvoiceEvent(BaseModel):
description: str
paid: bool
class InvoiceEventReceived(BaseModel):
ok: bool
invoices_callback_router = APIRouter()
@invoices_callback_router.post(
"{$callback_url}/invoices/{$request.body.id}", response_model=InvoiceEventReceived
)
def invoice_notification(body: InvoiceEvent):
pass
@app.post("/invoices/", callbacks=invoices_callback_router.routes)
def create_invoice(invoice: Invoice, callback_url: Union[HttpUrl, None] = None):
"""
Create an invoice
This will (let's imagine) let the API user (some external developer) create an invoice.
And this path operation will:
* Send the invoice to the client.
* Collect the money from the client.
* Send a notification back to the API user (the external developer), as a callback.
* At this point is that the API will somehow send a POST request to the external API with the notification of
the invoice event (e.g. "payment successful").
"""
# Send the invoice, collect the money, send the notification (the callback)
return {"msg": "Invoice received"}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
callback_url查询参数使用Pydantic的URL类型.
此处唯一比较新的内容是路径操作装饰器中的callbacks=invoices_callback_router.routes参数, 下文介绍.
# 存档回调
实际的回调代码高度依赖于你自己的API应用, 并且可能每个应用都各不相同. 回调代码可能只有一两行, 比如:
callback_url = "https://example.com/api/v1/invoices/events/"
requests.post(callback_url, json={"description": "Invoice paid", "paid": True})
2
但回调最重要的部分可能是, 根据API要发送给回调请求体的数据等内容, 确保你的API用户(外部开发者)正确地实现外部API. 因此, 我们下一步要做的就是添加代码, 为从API接收回调的外部API存档. 这部分文档在/docs下的Swargger API文档中显示, 并且会告诉外部开发者如何构建外部API, 本例没有实现回调本身(只是一行代码), 只有文档部分.
# 编写回调文档代码
应用不执行这部分代码, 只是用它来记录外部API, 但, 你已经知道用FastAPI创建自动API文档有多简单了, 我们要使用与存档外部API相同的知识...通过创建外部API要实现的路径操作(你的API要调用的).
编写存档回调的代码时, 假设你是外部开发者可能会用的上, 并且你当前正在实现的是外部API, 不是你自己的API. 临时改变(为外部开发者的)视角能让你更清楚该如何放置外部API响应和请求体的参数与Pydantic模型等.
# 创建回调的APIRouter
首先, 新建包含一些用于回调的APIRouter.
from typing import Union
from fastapi import APIRouter, FastAPI
from pydantic import BaseModel, HttpUrl
app = FastAPI()
class Invoice(BaseModel):
id: str
title: Union[str, None] = None
customer: str
total: float
class InvoiceEvent(BaseModel):
description: str
paid: bool
class InvoiceEventReceived(BaseModel):
ok: bool
invoices_callback_router = APIRouter()
@invoices_callback_router.post(
"{$callback_url}/invoices/{$request.body.id}", response_model=InvoiceEventReceived
)
def invoice_notification(body: InvoiceEvent):
pass
@app.post("/invoices/", callbacks=invoices_callback_router.routes)
def create_invoice(invoice: Invoice, callback_url: Union[HttpUrl, None] = None):
"""
Create an invoice.
This will (let's imagine) let the API user (some external developer) create an
invoice.
And this path operation will:
* Send the invoice to the client.
* Collect the money from the client.
* Send a notification back to the API user (the external developer), as a callback.
* At this point is that the API will somehow send a POST request to the
external API with the notification of the invoice event
(e.g. "payment successful").
"""
# Send the invoice, collect the money, send the notification (the callback)
return {"msg": "Invoice received"}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
# 创建回调路径操作
创建回调路径操作也使用之前创建的APIRouter, 它看起来和常规FastAPI路径操作差不多:
- 声明要接收的请求体, 例如,
body: InvoiceEvent - 还要声明要返回的响应, 例如,
response_model=InvoiceEventReceived
@invoices_callback_router.post(
"{$callback_url}/invoices/{$request.body.id}", response_model=InvoiceEventReceived
)
def invoice_notification(body: InvoiceEvent):
pass
2
3
4
5
回调路径操作与常规路径操作有两点主要区别:
- 它不需要任何实际的代码, 因为应用不会调用这段代码. 它只是用于存档外部API, 因此, 函数的内容只需要
pass就可以了. - 路径可以包含OpenAPI3表达式(详见下文), 可以使用带参数的变量, 以及发送至你的API的原始请求的部分.
# 回调路径表达式
回调路径支持包含发送给你的API的原始请求的部分的OpenAPI 3 表达式. 本例中是字符串:
"{$callback_url}/invoices/{$request.body.id}"
因此, 如果你的API用户(外部开发者)发送请求到你的API:
https://yourapi.com/invoices/?callback_url=https://www.external.org/events
使用如下JSON请求体:
{
"id": "2expen51ve",
"customer": "Mr. Richie Rich",
"total": "9999"
}
2
3
4
5
然后, 你的API就会处理发票, 并在某个点之后, 发送回调请求至callback_url(外部API):
https://www.external.org/events/invoices/2expen51ve
JSON请求体包含如下内容:
{
"description": "Payment celebration",
"paid": true
}
2
3
4
它会与其外部API的响应包含如下JSON请求体:
{
"ok": true
}
2
3
注意, 回调URL包含callback_url(https://www.external.org/events)中的查询参数, 还有JSON请求体内部的发票ID(2expen51ve).
# 添加回调路由
至此, 在上文创建的回调路由里就包含了回调路径操作(外部开发者要在外部API中实现). 现在使用API路径操作装饰器的参数callback, 从回调路由传递属性.routes(实际上只是路由/路径操作的列表):
@app.post("/invoices/", callbacks=invoices_callback_router.routes)
def create_invoice(invoice: Invoice, callback_url: Union[HttpUrl, None] = None):
"""
Create an invoice.
This will (let's imagine) let the API user (some external developer) create an
invoice.
And this path operation will:
* Send the invoice to the client.
* Collect the money from the client.
* Send a notification back to the API user (the external developer), as a callback.
* At this point is that the API will somehow send a POST request to the
external API with the notification of the invoice event
(e.g. "payment successful").
"""
# Send the invoice, collect the money, send the notification (the callback)
return {"msg": "Invoice received"}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
注意, 不能把路由本身(invoices_callback_router)传递给callback=, 要传递invoices_callback_router.routes中的.routes属性.
# 查看文档
现在, 使用Uvicorn启动应用, 打开http://127.0.0.1:8000/docs就能看到文档的路径操作已经包含了回调的内容以及外部API.
# OpenAPI 网络钩子
有些情况下, 你可能想告诉你的API用户, 你的应用程序可以携带一些数据调用他们的应用程序(给他们发送请求), 通常是为了通知某种事件. 这意味着, 除了你的用户向你的API发送请求的一般情况, 你的API(或你的应用)也可以向他们的系统(他们的API, 他们的应用)发送请求. 这通常被称为网络钩子(Webhook).
# 使用网络钩子的步骤
通常的过程是你在代码中定义要发送的消息, 即请求的主体. 你还需要以某种方式定义你的应用程序将在何时发送这些请求或事件. 用户会以某种方式(例如在某个网页仪表板上)定义你的应用程序发送这些请求应该使用的URL. 所有关于注册网络钩子的URL的逻辑以及发送这些请求的实际代码都由你决定, 你可以在自己的代码中以任何想要的方式来编写它.
# 使用FastAPI和OpenAPI文档化网络钩子
使用FastAPI, 你可以利用OpenAPI来自定义这些网络钩子的名称, 你的应用可以发送的HTTP操作类型(例如POST, PUT等)以及你的应用将发送的请求体. 这能让你的用户更轻松地实现他们的API来接收你的网络钩子请求, 他们甚至可能能够自动生成一些自己的API代码.
网络钩子在OpenAPI 3.1.0及以上版本中可用, FastAPI 0.99.0及以上版本支持.
# 带有网络钩子的应用程序
当你创建一个FastAPI应用程序时, 有一个webhooks属性可以用来定义网络钩子, 方式与你定义路径操作的时候相同, 例如使用@app.webhooks.post().
from datetime import datetime
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
class Subscription(BaseModel):
username: str
monthly_fee: float
start_date: datetime
@app.webhooks.post("new-subscription")
def new_subscription(body: Subscription):
"""
When a new user subscribes to your service we'll send you a POST request with this
data to the URL that you register for the event `new-subscription` in the dashboard.
"""
@app.get("/users/")
def read_users():
return ["Rick", "Morty"]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
你定义的网络钩子将被包含在OpenAPI的架构中, 并出现在自动生成的文档UI中.
app.webhooks对象实际上只是一个APIRouter, 与你在使用多个文件来构建应用程序时所使用的类型相同.
请注意, 使用网络钩子时, 你实际上并没有声明一个路径(比如/items/), 你传递的文本只是这个网络钩子的标识符(事件的名称). 例如在@app.webhooks.post("new-subscription")中, 网络钩子的名称是new-subscription. 这是因为我们预计你的用户会以其他方式(例如通过网页仪表板)来定义他们希望接收网络钩子的请求的实际URL路径.
# 查看文档
现在你可以启动你的应用程序并访问http://127.0.0.1:8000/docs, 你会看到你的文档不仅有正常的路径操作显示 现在还多了一些网络钩子.
# 包含 WSGI - Flask, Django, 其它
你可以挂载多个WSGI应用, 正如你在Sub Applications -- Mounts, Behind a Proxy所看到的那样. 为此, 你可以使用WSGIMiddleware来包装你的WSGI应用, 如: Flask, Django, 等等.
# 使用WSGIMiddleware
你需要导入WSGIMiddleware. 然后使用该中间件包装WSGI应用(例如Flask), 之后将其挂载到某一个路径下:
from fastapi import FastAPI
from fastapi.middleware.wsgi import WSGIMiddleware
from flask import Flask, request
from markupsafe import escape
flask_app = Flask(__name__)
@flask_app.route("/")
def flask_main():
name = request.args.get("name", "World")
return f"Hello, {escape(name)} from Flask!"
app = FastAPI()
@app.get("/v2")
def read_main():
return {"message": "Hello World"}
app.mount("/v1", WSGIMiddleware(flask_app))
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# 检查
现在, 所有定义在/v1/路径下的请求将会被Flask应用处理, 其余的请求则会被FastAPI处理. 如果你使用Uvicorn运行应用实例并且访问http://localhost:8000/v1/, 你将会看到由Flask返回的响应:
Hello, World from Flask!
并且如果你访问http://localhost:8000/v2, 你将会看到由FastAPI返回的响应:
{
"message": "Hello World"
}
2
3
# 生成客户端
因为FastAPI是基于OpenAPI规范的, 自然可以使用许多匹配的工具, 包括自动生成API文档(由Swagger UI提供). 一个不太明显而又特别的优势是, 你可以为你的API针对不同的编程语言来生成客户端(有时候被叫做SDKs).
# OpenAPI客户端生成
有许多工具可以从OpenAPI生成客户端. 一个常见的工具是OpenAPI Generator. 如果你正在开发前端, 一个非常有趣的替代方案是openapi-ts.
# 生成一个TypeScript前端客户端
从一个简单的FastAPI应用开始:
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
name: str
price: float
class ResponseMessage(BaseModel):
message: str
@app.post("/items/", response_model=ResponseMessage)
async def create_item(item: Item):
return {"message": "item received"}
@app.get("/items/", response_model=list[Item])
async def get_items():
return [
{"name": "Plumbus", "price": 3},
{"name": "Portal Gun", "price": 9001},
]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
请注意, 路径操作定义了他们所用于请求数据和回应数据的模型, 所使用的模型是Item和ResponseMessage.
# API文档
如果你访问API文档, 你将看到它具有在请求中发送和在响应中接收数据的模式(schemas):
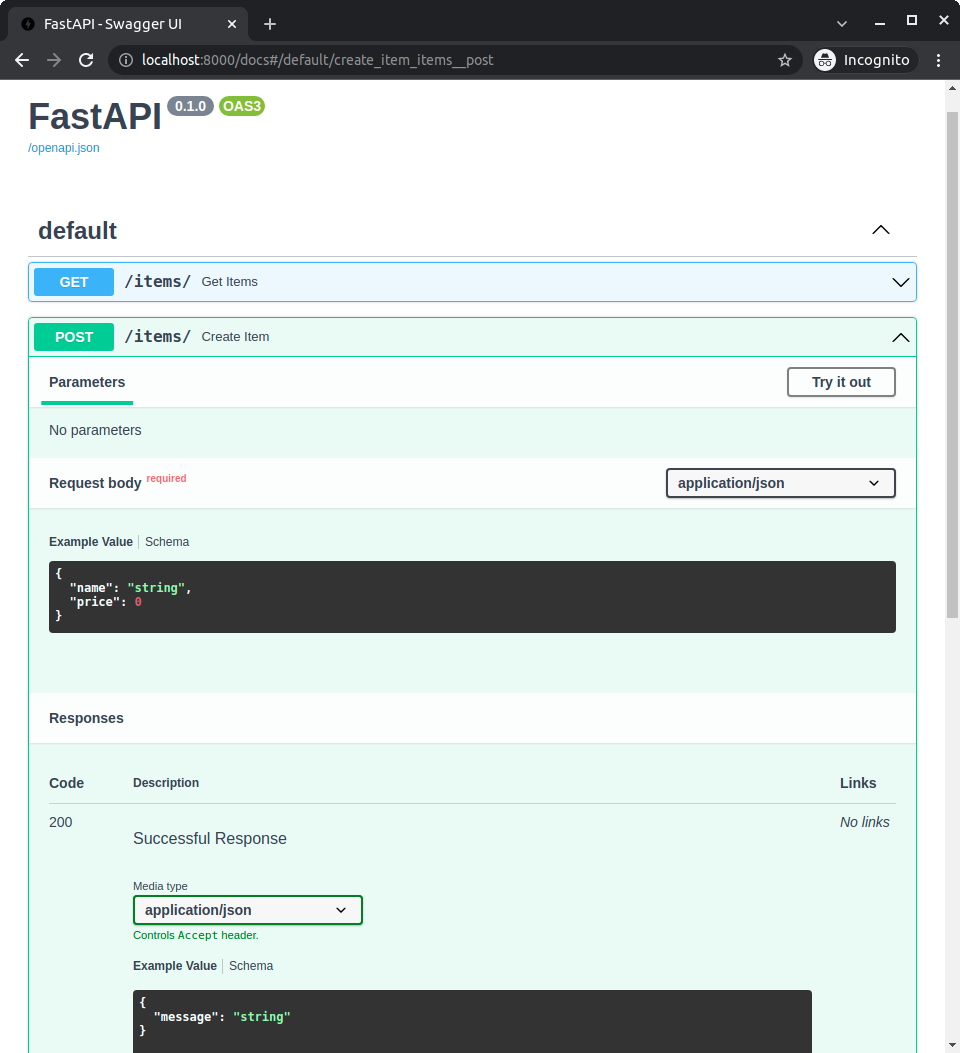
你可以看到这些模式, 因为它们是用程序中的模型声明的. 那些信息可以在应用的OpenAPI模式被找到, 然后显示在API文档中(通过Swagger UI). OpenAPI中所包含的模型里有相同的信息可以用于生成客户端代码.
# 生成一个TypeScript客户端
现在我们有了带有模型的应用, 我们可以为前端生成客户端代码. 安装openapi-ts.
# 安装openapi-ts
你可以使用以下工具在前端代码中安装openapi-ts:
npm install @hey-api/openapi-ts --save-dev
# 生成客户端代码
要生成客户端代码, 可以使用现在将要安装的命令行应用程序openapi-ts. 因为它安装在本地项目中, 所以你可能无法直接使用此命令, 你可以将其放在package.json文件中. 它看起来是这样的:
{
"name": "frontend-app",
"version": "1.0.0",
"description": "",
"main": "index.js",
"scripts": {
"generate-client": "openapi-ts --input http://localhost:8000/openapi.json --output ./src/client --client axios"
},
"author": "",
"license": "",
"devDependencies": {
"@hey-api/openapi-ts": "^0.27.38",
"typescript": "^4.6.2"
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
在这里添加NPM generate-client脚本后, 你可以使用以下命令运行它:
npm run generate-client
此命令将在./src/client中生成代码, 并将在其内部使用axios(前端HTTP库).
# 尝试客户端代码
现在你可以导入并使用客户端代码, 它可能看起来像这样, 请注意, 你可以为这些方法使用自动补全:
你还将自动补全要发送的数据:
请注意, name和price的自动补全, 是通过其在Item模型(FastAPI)中的定义实现的.
如果发送的数据字段不符, 你也会看到编辑器的错误提示:
响应(response)对象也拥有自动补全:
# 带有标签的FastAPI应用
在许多情况下, 你的FastAPI应用程序会更复杂, 你可能会使用标签来分隔不同组的路径操作(path operations). 例如, 你可以有一个用items的部分和另一个用于users的部分, 它们可以用标签来分隔:
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
name: str
price: float
class ResponseMessage(BaseModel):
message: str
class User(BaseModel):
username: str
email: str
@app.post("/items/", response_model=ResponseMessage, tags=["items"])
async def create_item(item: Item):
return {"message": "Item received"}
@app.get("/items/", response_model=list[Item], tags=["items"])
async def get_items():
return [
{"name": "Plumbus", "price": 3},
{"name": "Portal Gun", "price": 9001},
]
@app.post("/users/", response_model=ResponseMessage, tags=["users"])
async def create_user(user: User):
return {"message": "User received"}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
# 生成带有标签的TypeScript客户端
如果你为使用标签的FastAPI应用生成客户端, 它通常也会根据标签分隔客户端代码. 通过这种方式, 你将能够为客户端代码进行正确地排序和分组:
在这个案例中, 有:
ItemsServiceUsersService
# 客户端方法名称
现在生成的方法名像createItemItemPost看起来不太简洁:
ItemService.createItemItemPost({name: "Plumbus", price: 5})
这是因为客户端生成器为每个路径操作使用OpenAPI的内部操作ID(operation ID).
OpenAPI要求每个操作ID在所有路径操作中都是唯一的, 因此FastAPI使用函数名, 路径和HTTP方法/操作来生成此操作ID, 因为这样可以确保这些操作ID是唯一的.
# 自定义操作ID和更好的方法名
你可以修改这些操作ID的生成方式, 以使其更简洁, 并在客户端中具有更简洁的方法名称. 在这种情况下, 你必须确保每个操作ID在其他方面是唯一的. 例如, 你可以确保每个路径操作都有一个标签, 然后根据标签和路径操作名称(函数名)来生成操作ID.
# 自定义生成唯一ID函数
FastAPI为每个路径操作使用一个唯一ID, 它用于操作ID, 也用于任何所需自定义模型的名称, 用于请求或响应. 你可以自定义该函数, 它接受一个APIRoute对象作为输入, 并输出一个字符串. 例如, 以下是一个示例, 它使用第一个标签(你可能只有一个标签)和路径操作名称(函数名). 然后, 你可以将这个自定义函数作为generate_unique_id_function参数传递给FastAPI:
from fastapi import FastAPI
from fastapi.routing import APIRoute
from pydantic import BaseModel
def custom_generate_unique_id(route: APIRoute):
return f"{route.tags[0]}-{route.name}"
app = FastAPI(generate_unique_id_function=custom_generate_unique_id)
class Item(BaseModel):
name: str
price: float
class ResponseMessage(BaseModel):
message: str
class User(BaseModel):
username: str
email: str
@app.post("/items/", response_model=ResonseMessage, tags=["items"])
async def create_item(item: Item):
return {"message": "Item received"}
@app.get("/items/", response_model=list[Item], tags=["items"])
async def get_items():
return [
{"name": "Plumbus", "price": 3},
{"name": "Portal Gun", "price": 9001},
]
@app.post("/users/", response_model=ResponseMessage, tags=["users"])
async def create_user(user: User):
return {"message": "User received"}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
# 使用自定义操作ID生成TypeScript客户端
现在, 如果你再次生成客户端, 你会发现它具有改善的方法名称:
如你所见, 现在方法名称中只包含标签和函数名, 不再包含URL路径和HTTP操作的信息.
# 预处理用于客户端生成器的OpenAPI规范
生成的代码仍然存在一些重复的信息. 我们已经知道该方法与items相关, 因为它在ItemsService中(从标签中获取), 但方法名仍然有标签名作为前缀. 一般情况下对于OpenAPI, 我们可能仍然希望保留它, 因为这将确保操作ID是唯一的. 但对于生成的客户端, 我们可以在生成客户端之前修改OpenAPI操作ID, 以使方法名称更加美观和简洁. 我们可以将OpenAPI JSON下载到一个名为openapi.json的文件中, 然后使用以下脚本删除此前的标签:
import json
from pathlib import Path
file_path = Path("./openapi.json")
openapi_content = json.loads(file_path.read_text())
for path_data in openapi_content["paths"].values():
for operation in path_data.values():
tag = operation["tags"][0]
operation_id = operation["operationId"]
to_remove = f"{tag}-"
new_operation_id = operation_id[len(to_remove) :]
operation["operationId"] = new_operation_id
file_path.write_text(json.dumps(openapi_content))
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
通过这样做, 操作ID将从类似于items-get_items的名称重命名为get_items, 这样客户端生成器就可以生成更简洁的方法名称.
# 使用预处理的OpenAPI生成TypeScript客户端
现在, 由于最终结果保存在文件openapi.json中, 你可以修改package.json文件以使用此本地文件, 例如:
{
"name": "frontend-app",
"version": "1.0.0",
"description": "",
"main": "index.js",
"scripts": {
"generate-client": "openapi-ts --input ./openapi.json --output ./src/client --client axios"
},
"author": "",
"license": "",
"devDependencies": {
"@hey-api/openapi-ts": "^0.27.38",
"typescript": "^4.6.2"
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
生成新的客户端之后, 你现在将拥有清晰的方法名称, 具备自动补全, 错误提示等功能:
# 优点
当使用自动生成的客户端时, 你将获得以下的自动补全功能:
- 方法
- 请求体中的数据, 查询参数等
- 响应数据
你还将获得针对所有内容的错误提示. 每当你更新后端代码并重新生成前端代码时, 新的路径操作将作为方法可用, 旧的方法将被删除, 并且其他任何更改将反映在生成的代码中. 这也以为着如果有任何更改, 它将自动反映在客户端代码中, 如果你构建客户端, 在使用的数据上存在不匹配时, 它将报错. 因此, 你将在开发周期的早期检测到许多错误, 而不必等待错误在生产环境中向最终用户展示, 然后尝试调试问题所在.
# FastAPI CLI
FastAPI CLI是一个命令行程序, 你可以用它来部署和运行你的FastAPI应用程序, 管理你的FastAPI项目, 等等.
当你安装FastAPI时(例如使用pip install FastAPI命令), 会包含一个名为fastapi-cli的软件包, 该软件包在终端中提供fastapi命令. 要在开发环境中运行你的FastAPI应用, 你可以使用fastapi dev命令:
fastapi dev main.py
该命令行程序fastapi就是FastAPI CLI. FastAPI CLI接收你的Python程序路径, 自动检测包含FastAPI的变量(通常命名为app)及其导入方式, 然后启动服务. 在生产环境中, 你应该使用fastapi run命令. 在内部, FastAPI CLI使用了Uvicorn, 这是一个高性能, 适用于生产环境的ASGI服务器.
# fastapi dev
当你运行fastapi dev时, 它将以开发模式运行. 默认情况下, 它会启用自动重载, 因此当你更改代码时, 它会自动重新加载服务器. 该功能是资源密集型的, 且相较不启用时更不稳定, 因此你应该仅在开发环境下使用它. 默认情况下, 它将监听IP地址127.0.0.1, 这是你的机器与自身通信的IP地址(localhost).
# fastapi run
当你运行fastapi run时, 它默认以生产环境模式运行. 默认情况下, 自动重载是禁用的. 它将监听IP地址0.0.0.0, 即所有可用的IP地址, 这样任何能够与该机器通信的人都可以公开访问它, 这通常是你在生产环境中运行它的方式, 例如在容器中运行. 在大多数情况下, 你会(且应该)有一个"终止代理"在上层为你处理HTTPS, 这取决于你如何部署应用程序, 你的服务提供商可能会为你处理此事, 或者你可能需要自己设置.
你可以在[deployment documentation](https://fastapi.tiangolo.com/zh/deployment/)获得更多信息.
# 部署
部署FastAPI应用程序相对容易.
# 部署是什么意思
部署应用程序意味着执行必要的步骤以使其可供用户使用. 对于Web API来说, 通常涉及将其上传到云服务器中, 搭配一个性能和稳定性都不错的服务器程序, 以便你的用户可以高效地访问你的应用程序, 而不会出现中断或其他问题. 这与开发阶段形成鲜明对比, 在开发阶段, 你不断更改代码, 破坏代码, 修复代码, 来回停止和重启服务器等.
# 部署策略
根据你的使用场景和使用的工具, 有多种方法可以实现此目的. 你可以使用一些工具自行部署服务器, 你也可以使用能为你完成部分工作的云服务, 或其他可能的选项. 我将向你展示在部署FastAPI应用程序时你可能应该记住的一些主要概念(尽管其中大部分使用与任何其他类型的Web应用程序).
在接下来的部分中, 你将看到更多需要记住的细节以及一些技巧.
# 关于FastAPI版本
FastAPI已在许多应用程序和系统的生产环境中使用. 并且测试覆盖率保持在100%, 但其开发进度仍在快速推进. 经常添加新功能, 定期修复错误, 并且代码仍在持续改进. 这就是为什么当前版本仍然是0.x.x, 这反映出每个版本都可能有Breaking changes. 这遵循语义版本控制的约定. 你现在就可以使用FastAPI创建生产环境应用程序(你可能已经这样做了一段时间), 你只需确保使用的版本可以与其余代码正确配合即可.
# 固定你的fastapi版本
你应该做的第一件事是将你正在使用的FastAPI版本"固定"到你知道适用于你的应用程序的特定最新版本. 例如, 假设你在应用程序中使用版本0.45.0, 如果你使用requirements.txt文件, 你可以使用以下命令指定版本:
fastapi==0.45.0
或者你也可以将其固定位:
fastapi>=0.45.0,<0.46.0
这意味着你将使用0.45.0或更高版本, 但低于0.46.0, 例如, 版本0.45.2仍会被接受. 如果你使用任何其他工具来管理你的安装, 例如Poetry, Pipenv或其他工具, 他们都有一种定义包的特定版本的方法.
# 可用版本
你可以在发行说明中查看可用版本(例如查看当前最新版本).
# 关于版本
遵循语义版本控制约定, 任何低于1.0.0的版本都可能会添加breaking changes. FastAPI还遵循这样的约定: 任何PATCH版本更改都是为了bug修复和non-breaking changes.
"PATCH"是最后一个数字, 例如, 在0.2.3中, PATCH版本是3.
因此, 你应该能够固定到如下版本:
fastapi>=0.45.0,<0.46.0
"MINOR"版本会添加breaking changes和新功能.
"MINOR"是中间的数字, 例如, 在0.2.3中, MINOR版本是2.
# 升级FastAPI版本
你应该为你的应用程序添加测试, 使用FastAPI编写测试非常简单(感谢Starlette), 请参考文档: 测试. 添加测试后, 你可以将FastAPI版本升级到更新版本, 并通过运行测试来确保所有代码都能正常工作. 如果一切正常, 或者在进行必要的更改之后, 并且所有测试都通过了, 那么你可以将fastapi固定到新的版本.
# 关于Starlette
你不应该固定starlette的版本, 不同版本的FastAPI将使用特定的较新版本的Starlette. 因此, FastAPI自己可以使用正确的Starlette版本.
# 关于Pydantic
Pydantic包含针对FastAPI的测试及其自己的测试, 因此Pydantic的新版本(1.0.0以上)始终与FastAPI兼容. 你可以将Pydantic固定到适合你的1.0.0以上和2.0.0以下的任何版本呢. 例如:
pydantic>=1.2.0,<2.0.0
# 关于HTTPS
人们很容易认为HTTPS仅仅是"启用"或"未启用"的东西, 但实际情况比这复杂得多.
要从用户的视角了解HTTPS的基础知识, 请查看https://howhttps.works/. 现在, 从开发人员的视角, 在了解HTTPS时需要记住以下几点:
- 要使用HTTPS, 服务器需要拥有第三方生成的"证书"(certificate).
- 这些证书实际上是从第三方获取的, 而不是"生成"的
- 证书有声明周期
- 它们会过期
- 然后它们需要更新, 再次从第三方获取
- 连接的加密发生在TCP层
- 这是HTTP协议下面的一层.
- 因此, 证书和加密处理是在HTTP之前完成的.
- TCP不知道域名, 仅仅知道IP地址
- 有关所请求的特定域名的信息位于HTTP数据中.
- HTTPS证书"证明"某个域名, 但协议和加密发生在TCP层, 在知道正在处理哪个域名之前.
- 默认情况下, 这意味着你每个IP地址只能拥有一个HTTPS证书
- 无论你的服务器有多大, 或者服务器上的每个应用程序有多小.
- 不过, 对此有一个解决方案
- TLS协议(在HTTP之下的TCP层处理加密的协议)有一个扩展, 称为SNI.
- SNI扩展允许一台服务器(具有单个IP地址)拥有多个HTTPS证书并提供多个HTTPS域名/应用程序.
- 为此, 服务器上会有单独的一个组件(程序)倾听公共IP地址, 这个组件必须拥有服务器中的所有HTTPS证书.
- 获得安全连接后, 通信协议仍然是HTTP.
- 内容是加密过的, 即使它们是通过HTTP协议发送的.
通常的做法是在服务器上运行一个程序/HTTP服务器并管理所有HTTPS部分: 接收加密的HTTPS请求, 将解密的HTTP请求发送到在同一服务器中运行的实际HTTP应用程序(在本例中为FastAPI应用程序), 从应用程序中获取HTTP响应, 使用适当的HTTPS证书对其进行加密并使用HTTPS将其发送回客户端. 此服务器通常被称为TLS终止代理(TLS Termination Proxy).
你可以用作TLS终止代理的一些选项包括:
- Traefik(也可以处理证书更新)
- Caddy(也可以处理证书更新)
- Nginx
- HAProxy
# Let's Encrypt
在Let's Encrypt之前, 这些HTTPS证书由受信任的第三方出售, 过去, 获得这些证书的过程非常繁琐, 需要大量的文书工作, 而且证书非常昂贵. 但随后Let's Encrypt创建了. 它是Linux基金会的一个项目, 以自动方式免费提供HTTPS证书, 这些证书可以使用所有符合标准的安全加密, 并且有效期很短(大约3个月), 因此安全性实际上更好, 因为它们的生命周期缩短了. 域可以被安全地验证并自动生成证书, 还允许自动更新这些证书. 我们的想法是自动获取和更新这些证书, 以便你可以永久免费地拥有安全的HTTPS.
# 面向开发人员的HTTPS
这里有一个HTTPS API看起来是什么样的示例, 我们会分步说明, 并且主要关注对开发人员重要的部分.
# 域名
第一步我们要先获取一些域名(Domain Name), 然后可以在DNS服务器(可能是你的同一家云服务商提供的)中配置它. 你可能拥有一个云服务器(虚拟机)或类似的东西, 并且它会有一个固定公共IP地址. 在DNS服务器中, 你可以配置一条记录("A 记录")以将你的域名指向你服务器的公共IP地址. 这个操作一般只需要在最开始执行一次.
域名这部分发生在HTTPS之前, 由于这一切都依赖于域名和IP地址, 所以先在这里提一下.
# DNS
现在让我们关注真正的HTTPS部分. 首先, 浏览器将通过DNS服务器查询域名的IP是什么, 在本例中为someapp.example.com, DNS服务器会告诉浏览器使用某个特定的IP地址, 这将是你在DNS服务器中为你的服务器配置的公共IP地址.

# TLS握手开始
然后, 浏览器将在端口443(HTTPS端口)上与该IP地址进行通信. 通信的第一部分只是建立客户端和服务器之间的连接并决定它们将使用的加密密钥等.

客户端和服务器之间建立TLS连接的过程称为TLS握手.
# 带有SNI扩展的TLS
服务器上只有一个进程可以侦听特定IP地址的特定端口, 可能有其他进程在同一IP地址的其他端口上侦听, 但每个IP地址和端口组合只有一个进程. TLS(HTTPS)默认使用端口443, 这就是我们需要的端口. 由于只有一个进程可以监听此端口, 因此监听端口的进程将是TLS终止代理. TLS终止代理可以访问一个或多个TLS证书(HTTPS证书). 使用上面讨论的SNI扩展, TLS终止代理将检查应该用于此链接的可用TLS(HTTPS)证书, 并使用与客户端期望的域名相匹配的证书. 这种情况下, 它将使用someapp.example.com的证书.

客户端已经信任生成该TLS证书的实体(在本例中为Let's Encrypt, 但我们稍后会看到), 因此它可以验证该证书是否有效. 然后, 通过使用证书, 客户端和TLS终止代理决定如何加密TCP通信的其余部分. 这就完成了TLS握手部分.
此后, 客户端和服务器就拥有了加密的TCP连接, 这就是TLS提供的功能. 然后它们可以使用该连接来启动实际的HTTP通信. 这就是HTTPS, 它只是安全TLS连接内的普通HTTP, 而不是纯粹的(未加密的)TCP连接.
请注意, 通信加密发生在TCP层, 而不是HTTP层.
# HTTPS请求
现在客户端和服务器(特别是浏览器和TLS终止代理)具有加密的TCP连接, 它们可以开始HTTP通信. 接下来, 客户端发送一个HTTPS请求, 这其实只是一个通过TLS加密连接的HTTP请求.

# 解密请求
TLS终止代理将使用协商好的加密算法解密请求, 并将(解密的)HTTP请求传输到运行应用程序的进程(例如运行FastAPI应用的Uvicorn进程).

# HTTP响应
应用程序将处理请求并向TLS终止代理发送(未加密)HTTP响应.

# HTTPS响应
然后, TLS终止代理将使用之前协商的加密算法(以someapp.example.com的证书开头)对响应进行加密, 并将其发送会浏览器. 接下来, 浏览器将验证响应是否有效和是否使用了正确的加密密钥等, 然后它会解密响应并处理它.

客户端(浏览器)将知道响应来自正确的服务器, 因为它使用了他们之前使用HTTPS证书协商出的加密算法.
# 多个应用程序
在同一台(或多台)服务器中, 可能存在多个应用程序, 例如其他API程序或数据库. 只有一个进程可以处理特定的IP和端口(在我们的示例中为TLS终止代理), 但其他应用程序/进程也可以在服务器上运行, 只要它们不尝试使用相同的公共IP和端口的组合.

这样, TLS终止代理就可以为多个应用程序处理多个域名的HTTPS和证书, 然后在每种情况下将请求传输到正确的应用程序.
# 证书更新
在未来的某个时候, 每个证书都会过期(大约在获得证书后3个月). 然后, 会有另一个程序(在某些情况下是另一个程序, 在某些情况下可能是同一个TLS终止代理)与Let's Encrypt通信并更新证书.

TLS证书与域名相关联, 而不是与IP地址相关联. 因此, 要更新证书, 更新程序需要向权威机构(Let's Encrypt)证明它确实"拥有"并控制该域名. 有多种方法可以做到这一点, 一些流行的方式是:
- 修改一些DNS记录
- 为此, 续订程序需要支持DNS提供商的API, 因此, 要看你使用的DNS提供商是否提供这一功能.
- 在与域名关联的公共IP地址上作为服务器运行(至少在证书获取过程中).
- 正如我们上面所说, 只有一个进程可以监听特定的IP和端口.
- 这就是当同一个TLS终止代理还负责证书续订过程时它非常有用的原因之一.
- 否则, 你可能需要暂时停止TLS终止代理, 启动续订程序以获取证书, 然后使用TLS终止代理配置它们, 然后重新启动TLS终止代理. 这并不理想, 因为你的应用程序在TLS终止代理关闭期间将不可用.
通过拥有一个单独的系统来使用TLS终止代理来处理HTTPS, 而不是直接将TLS证书与应用程序服务器一起使用(例如Uvicorn), 你可以在更新证书的过程中同时保持提供服务.
# 回顾
拥有HTTPS证书非常重要, 并且在大多数情况下相当关键, 作为开发人员, 你围绕HTTPS所做的大部分努力就是理解这些概念以及它们的工作原理. 一旦你了解了面向开发人员的HTTPS的基础知识, 你就可以轻松组合和配置不同的工具, 以帮助你以简单的方式管理一切. 在接下来的一些章节中, 将向你展示几个为FastAPI应用程序设置HTTPS的具体示例.
# 手动运行服务器
# 使用fastapi run命令
简而言之, 使用fastapi run来运行你的FastAPI应用程序:
fastapi run main.py
这在大多数情况下都能正常运行, 例如, 你可以使用该命令在容器, 服务器等环境中启动你的FastAPI应用.
# ASGI服务器
让我们深入了解一些细节, FastAPI使用了一种用于构建Python Web框架和服务器的标准, 称为ASGI, FastAPI本质上是一个ASGI Web框架. 要在远程服务器上运行FastAPI应用(或任何其他ASGI应用), 你需要一个ASGI服务器程序, 例如Uvicorn, 它是fastapi命令默认使用的ASGI服务器. 除此之外, 还有其他一些可选的ASGI服务器, 例如:
- Uvicorn: 高性能ASGI服务器
- Hypercorn: 与HTTP/2和Trio等兼容的ASGI服务器
- Daphne: 为Django Channels构建的ASGI服务器
- Granian: 基于Rust的HTTP服务器, 专为Python应用设计
- NGINX Unit: NGINX Unit是一个轻量级且灵活的Web应用运行时环境
# 服务器主机和服务器程序
关于名称, 有一个小细节需要注意, "服务器"一词通常用于指远程/云计算机(物理机或虚拟机)以及在该计算机上运行的程序(例如Uvicorn). 请记住, 当提到这个名词时, 它可能指的是这两者之一. 当提到远程主机时, 通常将其称为服务器, 但也称为机器(machine), VM(虚拟机), 节点. 这些都是指某种类型的远程计算机, 通常运行Linux, 你可以在其中运行程序.
# 安装服务器程序
当你安装FastAPI时, 它自带一个生产环境服务器--Uvicron, 并且你可以使用fastapi run命令来启动它. 不过, 也可以手动安装ASGI服务器. 请确保你创建并激活一个虚拟环境, 然后再安装服务器应用程序. 例如, 要安装Uvicorn, 可以运行命令:
pip install "uvicron[standard]"
类似的流程也适用于任何其他ASGI服务器程序.
通过添加standard选项, Uvicorn将安装并使用一些推荐的额外依赖项. 其中包括uvloop, 这是asyncio的高性能替代方案, 能够显著提升并发性能. 当你使用pip install "fastapi[standard]"安装FastAPI时, 实际上也会安装uvicron[standard].
# 运行服务器程序
如果你手动安装了ASGI服务器, 通常需要以特定格式传递一个导入字符串, 以便服务器能够正确导入你的FastAPI应用:
uvicorn main:app --host 0.0.0.0 --port 80
命令uvicorn main:app的含义如下:
main: 指的是main.py文件(即Python模块)app: 指的是main.py文件中通过app = FastAPI()创建的对象. 它等价与以下导入语句:from main import app
每种ASGI服务器程序通常都会有类似的命令, 你可以在它们的官方文档中找到更多信息.
Uvicorn和其他服务器支持--reload选项, 该选项在开发过程中非常有用. 但--reload选项会消耗更多资源, 且相对不稳定, 它对于开发阶段非常有帮助, 但在生产环境中不应该使用.
# 部署概念
这些示例运行服务器程序(例如Uvicorn), 启动单个进程, 在所有IP(0.0.0.0)上监听预定义端口(例如80). 这是基本思路, 但你可能需要处理一些其他事情, 例如:
- 安全性 - HTTPS
- 启动时运行
- 重新启动
- 复制(运行的进程数)
- 内存
- 开始前的步骤
接下来的章节中, 将向你介绍每个概念, 如何思考它们, 以及一些具体示例以及处理它们的策略.
# 部署概念
在部署FastAPI应用程序或任何类型的Web API时, 有几个概念值得了解, 通过掌握这些概念你可以找到最合适的方法来部署你的应用程序.
一些重要的概念是:
- 安全性 - HTTPS
- 启动时运行
- 重新启动
- 复制(运行的进程数)
- 内存
- 开始前的先前步骤
我们接下来了解它们将如何影响部署, 我们的最终目标是能够以安全的方式为你的API客户端提供服务, 同时要避免中断, 并且尽可能高效地利用计算资源. 我将在这里告诉你更多关于这些概念的信息, 希望能够给你提供直觉来决定如何在非常不同的环境中部署API, 甚至是在尚不存在的环境里. 通过考虑这些概念, 你将能够评估和设计部署你自己的API的最佳方式, 在接下来的章节中, 我将为你提供更多部署FastAPI应用程序的具体方法. 但现在, 让我们仔细看一下这些重要的概念, 这些概念也适用于任何其他类型的Web API.
# 安全性 - HTTPS
在上一章节有关HTTPS中, 我们了解了HTTPS如何为你的API提供加密. 我们还看到, HTTPS通常由应用程序服务器的外部组件(TLS终止代理)提供. 并且必须有某个东西负责更新HTTPS证书, 它可以是相同的组件, 也可以是不同的组件.
# HTTPS示例工具
你可以用作TLS终止代理的一些工具包括:
- Traefik: 自动处理证书更新
- Caddy: 自动处理证书更新
- Nginx: 使用Certbot等外部组件进行证书更新
- HAProxy: 使用Certbot等外部组件进行证书更新
- 带有Ingress Controller(如Nginx)的Kubernetes: 使用诸如cert-manager之类的外部组件来进行证书更新
- 由与服务商内部处理, 作为其服务的一部分.
另一种选择是可以使用云服务来完成更多的工作, 包括设置HTTPS, 它可能有一些限制或向你收取更多费用等, 但在这种情况下, 你不必设置TLS终止代理.
接下来要考虑的概念都是关于运行实际API的程序(例如Uvicorn).
# 程序和进程
我们将讨论很多关于正在运行的"进程"的内容, 因此弄清楚它的含义以及与"程序"这个词有什么区别是很有用的.
# 什么是程序
程序这个词通常用来描述很多东西:
- 你编写的代码, Python文件
- 操作系统可以执行的文件, 例如:
python,python.exe或uvicorn - 在操作系统上运行, 使用CPU并将内容存储在内存上的特定程序, 这也被称为进程.
# 什么是进程
进程这个词通常以更具体的方式使用, 仅指在操作系统中运行的东西(如上面的最后一点):
- 在操作系统上运行的特定程序
- 这不是指文件, 也不是指代码, 它具体指的是操作系统正在执行和管理的东西
- 任何程序, 任何代码, 只有在执行时才能做事, 因此, 是当有进程正在运行时.
- 该进程可以由你或操作系统终止(或"杀死"), 那时, 它停止运行/被执行, 并且它可以不再做事情.
- 你计算机上运行的每个应用程序背后都有一些进程, 每个正在运行的程序, 每个窗口等, 并且通常在计算机打开时同时运行许多进程.
- 同一程序可以有多个进程同时运行.
如果你检查操作系统中的"任务管理器"或"系统监视器"(或类似工具), 你将能够看到许多正在运行的进程. 例如, 你可能会看到有多个进程运行同一个浏览器程序(Firefox, Chrome, Edge等), 他们通常每个tab运行一个进程, 在加上一些其他额外的进程.
现在我们知道了术语"进程"和"程序"之间的区别, 让我们继续讨论部署.
# 启动时运行
在大多数情况下, 当你创建Web API时, 你希望它始终运行, 不间断, 以便你的客户端始终可以访问它. 这是当然的, 除非你有特定原因希望它仅在某些情况下运行, 但大多数时候希望它不断运行并且可用.
# 在远程服务器中
在你设置远程服务器(云服务器, 虚拟机等)时, 你可以做的最简单的事情就是手动运行Uvicorn(或类似的), 就像本地开发时一样. 它将会在开发过程中发挥作用, 但是, 如果你与服务器的连接丢失, 正在运行的进程可能会终止. 如果服务器重新启动(例如更新后或从云提供商迁移后), 你可能不会注意到它. 因此, 你甚至不知道必须手动重新启动该进程. 所以, 你的API将一直处于挂掉的状态.
# 启动时自动运行
一般来说, 你可能希望服务器程序(例如Uvicorn)在服务器启动时自动启动, 并且不需要任何认为干预, 让进程始终与你的API一起运行(例如Uvicorn运行你的FastAPI应用程序).
# 单独的程序
为了实现这一点, 通常会有一个单独的程序来确保你的应用程序在启动时运行. 在许多情况下, 它还可以确保其他组件或应用程序也运行, 例如数据库.
# 启动时运行的示例工具
可以完成这项工作的工具的一些示例是:
- Docker
- Kubernetes
- Docker Compose
- Docker in Swarm Mode
- Systemd
- Supervisor
- 作为其服务的一部分由云提供商内部处理
- 其他的...
# 重新启动
与确保应用程序在启动时运行类似, 可能还希望确保它挂掉后重新启动.
# 我们会犯错误
作为人类, 我们总是会犯错误, 软件几乎总是在不同的地方隐藏着BUG. 作为开发人员, 当我们发现这些BUG兵实现新功能时, 会不断改进代码.
# 自动处理小错误
使用FastAPI构建Web API时, 如果我们的代码中存在错误, FastAPI通常会将其包含到触发错误的单个请求中. 对于该请求, 客户端将收到500内部服务器错误, 但应用程序将继续处理下一个请求, 而不是完全崩溃.
# 更大的错误 - 崩溃
尽管如此, 在某些情况下, 我们编写的一些代码可能会导致整个应用程序崩溃, 从而导致Uvicorn和Python崩溃. 尽管如此, 你可能不希望应用程序因为某个地方出现错误而保持死机状态, 你可能希望它继续运行, 至少对于未破坏的路径操作.
# 崩溃后重新启动
但在那些严重错误导致正在运行的进程崩溃的情况下, 你需要一个外部组件来负责重新启动进程, 至少尝试几次...
尽管如果整个应用程序只是立即崩溃, 那么永远重新启动它可能没有意义. 但在这些情况下, 你可能会在开发过程中注意到它, 或者至少在部署后立即注意到它. 因此, 让我们关注主要情况, 在未来的某些特定情况下, 它可能会完全崩溃, 但重新启动它仍然有意义.
你可能希望让这个东西作为外部组件负责重新启动你的应用程序, 因为到那时, 使用Uvicorn和Python的同一应用程序已经崩溃了, 因此同一应用程序的相同代码中没有东西可以对此做出什么.
# 自动重新启动的示例工具
在大多数情况下, 用于启动时运行程序的同一工具也用于处理自动重新启动.
例如, 可以通过以下方式处理:
- Docker
- Kubernetes
- Docker Compose
- Docker in Swarm mode
- Systemd
- Supervisor
- 作为其服务的一部分由云提供商内部处理
- 其他的...
# 复制 - 进程和内存
对于FastAPI应用程序, 使用像Uvicorn这样的服务器程序, 在同一个进程中运行一次就可以同时为多个客户端提供服务. 但在许多情况下, 你会希望同时运行多个工作进程.
# 多进程 - Workers
如果你的客户端数量多余单个进程可以处理的数量(例如, 如果虚拟机不是太大), 并且服务器的CPU中有多个核心, 那么你可以让多个进程运行同时处理同一个应用程序, 并在它们之间分发所有请求. 当你运行同一API程序的多个进程时, 它们通常称为workers.
# 工作进程和端口
还记得文档About HTTPS中只有一个进程可以侦听服务器中的端口和IP地址的一种组合吗? 现在仍然是对的, 因此, 为了能够同时拥有多个进程, 必须有一个单个进程侦听端口, 然后以某种方式将通信传输到每个工作进程.
# 每个进程的内存
现在, 当程序将内容加载到内存中时, 例如, 将机器学习模型加载到变量中, 或者将大文件的内容加载到变量中, 所有这些都会消耗服务器的一点内存(RAM). 多个进程通常不共享任何内存, 这意味着每个正在运行的进程都有自己的东西, 变量和内存. 如果你的代码消耗了大量的内存, 每个进程将消耗等量的内存.
# 服务器内存
例如, 如果你的代码加载1GB大小的机器学习模型, 则当你使用API运行一个进程时, 它将至少消耗1GB RAM, 如果你启动4个进程(4个工作进程), 每个进程将消耗1GB RAM. 因此, 你的API总共消耗4GB RAM. 如果你的远程服务器或虚拟机只有3GB RAM, 尝试加载超过4GB RAM将导致问题.
# 多进程 - 一个例子
在此示例中, 有一个Manager Process启动并控制两个Worker Processes. 该管理器进程可能是监听IP中的端口的进程, 它将所有通信传输到工作进程. 这协工作进程将是运行你的应用程序的进程, 它们将执行主要计算以接收请求并返回响应, 并且它们将加载你放入RAM中的变量中的任何内容.

当然, 除了你的应用程序之外, 同一台机器可能还运行其他进程. 一个有趣的细节是, 随着时间的推移, 每个进程使用的CPU百分比可能会发生很大的变化, 但内存(RAM)通常会或多或少保持稳定. 如果你有一个每次执行相当数量的计算的API, 并且你有很多客户端, 那么CPU利用率可能也会保持稳定(而不是不断快速上升和下降).
# 复制工具和策略示例
可以通过多种方法来实现这一目标, 我将在接下来的章节中向你详细介绍具体的策略, 例如在涉及Docker和容器时. 要考虑的主要限制是必需有一个单个组件来处理公共IP中的端口, 然后它必须有一种方法将通信传输到复制的进程/worker.
以下是一些可能的组合和策略:
- Gunicorn管理Uvicorn workers: Gunicorn将是监听IP和端口的进程管理器, 复制将通过多个Uvicorn工作进程进行
- Uvicorn管理Uvicorn workers: 一个Uvicorn进程管理器将监听IP和端口, 并且它将启动多个Uvicorn工作进程
- Kubernetes和其他分布式容器系统: Kubernetes层中的某些东西将侦听IP和端口, 复制将通过拥有多个容器, 每个容器运行一个Uvicorn进程
- 云服务为你处理此问题: 云服务可能为你处理复制, 它可能会让你定义要运行的进程, 或要使用的容器镜像, 在任何情况下, 它很可能是单个Uvicorn进程, 并且云服务将负责复制它.
如果关于容器, Docker或Kubernetes的内容还没有了解, 将在以后的章节中进行介绍容器中的FastAPI - Docker.
# 启动之前的步骤
在很多情况下, 希望在启动应用程序之前执行一些步骤. 例如, 可能想要运行数据库迁移. 但在大多数情况下, 这种操作可能只希望执行一次. 因此, 在启动应用程序之前, 将需要一单个进程来执行这些前面的步骤. 而且必须确保它是运行前面步骤的单个进程, 即使之后你为应用程序本身启动多个进程(多个worker). 如果这些步骤由多个进程运行, 它们会通过在并行运行来重复工作, 并且如果这些步骤像数据库迁移一样需要小心处理, 它们可能会导致每个进程和其他进程发生冲突. 当然, 也有一些情况, 多次运行前面的步骤也没有问题, 这样的话就好办多了.
另外, 请记住, 根据你的设置, 在某些情况下, 你在开始应用程序之前可能甚至不需要任何先前的步骤. 在这种情况下, 就不必担心这些.
# 前面步骤策略的示例
这将在很大程度上取决于你部署系统的方式, 并且可能与你启动程序, 处理重启等的方式有关. 以下是一些可能的想法:
- Kubernetes中的"Init Container"在应用程序容器之前运行
- 一个bash脚本, 运行前面的步骤, 然后启动你的应用程序
- 你仍然需要一种方法来启动/重新启动bash脚本, 监测错误等.
# 资源利用率
你的服务器是一个资源, 可以通过程序消耗或利用CPU上的计算时间以及可用的RAM内存. 你想要消耗/利用多少系统资源, 这可能很容易认为"不多", 但实际上你可能希望在不崩溃的情况下尽可能多地消耗.
如果你支付了3台服务器费用, 但只使用了它们的一点点RAM和CPU, 那么你可能浪费金钱, 并且可能浪费服务器电力, 等等. 另一方面, 如果你有2台服务器, 并且正在使用100%的CPU和RAM, 则在某些时候, 一个进程会要求更多内存, 并且服务器将不得不使用磁盘作为"内存"(这可能会慢数千倍), 甚至崩溃. 或者一个进程可能需要执行一些计算, 并且必须等到CPU再次空闲.
在这种情况下, 最好购买一台额外的服务器并在其上运行一些进程, 以便它们都有足够的RAM和CPU时间.
由于某种原因, 你的API的使用量也有可能出现激增. 也许它像病毒一样传播开来, 或者也许其他一些服务或机器人开始使用它. 在这些情况下, 你可能需要额外的资源来保证安全. 你可以将任意数字设置为目标, 例如, 资源利用率在50%到90%之间, 重点是, 这些可能是你想衡量和用来调整部署的主要内容.
你可以使用"htop"等简单工具来查看服务器中使用的CPU和RAM或每个进程使用的数量. 或者你可以使用更复杂的监控工具, 这些工具可能分布在服务器等上.
# 回顾
在这里了解了一些决定如何部署应用程序时可能需要牢记的主要概念:
- 安全性 -- HTTPS
- 启动时运行
- 重新启动
- 复制(运行的进程数)
- 内存
- 开始前的先前步骤
了解这些想法以及如何应用它们应该会给你足够的直觉在配置和调整部署时做出任何决定.
# 服务器工作进程(Workers) - 使用Uvicorn的多工作进程模式
让我们回顾一下之前的部署概念:
- 安全性 -- HTTPS
- 启动时运行
- 重新启动
- 复制(运行的进程数)
- 内存
- 开始前的先前步骤
到目前为止, 在文档中的所有教程中, 你可能一直在运行一个服务器程序, 例如使用fastapi命令来启动Uvicorn, 而它默认运行的是但进程模式. 部署应用程序时, 你可能希望进行一些进程复制, 以利用多核CPU并能够处理更多请求. 正如你在上一章有关部署概念中看到的, 你可以使用多种策略.
在本章节, 将展示如何使用fastapi命令或直接使用uvicorn命令以多工作进程模式运行Uvicorn.
如果使用容器, 例如Docker或Kubernetes, 将在容器中的FastAPI-Docker进行介绍.
比较特别的是, 在Kubernetes环境中运行时, 通常不需要使用多个工作进程, 而是每个容器运行一个Uvicorn进程.
# 多个工作进程
可以使用--workers命令行选项来启动多个工作进程.
# fastapi
fastapi run --workers 4 main.py
2
# uvicorn
uvicorn main:app --host 0.0.0.0 --port 8000 --workers 4
2
这里唯一的新选项是--workers告诉Uvicorn启动4个工作进程. 还可以看到它显示了每个进程的PID, 父进程(这里是进程管理器)的PID为27365, 每个工作进程的PID为: 27368, 27369, 27370和27367.
# 部署概念
在这里, 学习了如何使用多个工作进程(workers)来让应用程序的执行并行化, 充分利用CPU的多核性能, 并能够处理更多的请求.
从上面的部署概念列表来看, 使用worker主要有助于复制部分, 并对重新启动有一点帮助, 但仍然需要照顾其他部分:
- 安全性 -- HTTPS
- 启动时运行
- 重新启动
- 复制(运行的进程数)
- 内存
- 开始前的先前步骤
# 容器和Docker
在关于容器中的FastAPI - Docker的下一章中, 我将介绍一些可用于处理其他部署概念的策略.
我将向您展示如何从零开始构建自己的镜像, 以运行一个单独的 Uvicorn 进程. 这个过程相对简单, 并且在使用 Kubernetes 等分布式容器管理系统时,这通常是您需要采取的方法.
# 回顾
你可以使用fastapi或uvicorn命令时, 通过--workersCLI选项启用多个工作进程(workers), 以充分利用多核CPU, 以并行运行多个进程.
如果你需要设置自己的部署系统, 同时自己处理其他部署概念, 则可以使用这些工具和想法.
# 容器中的FastAPI - Docker
部署FastAPI应用程序时, 常见的方法是构建Linux容器镜像, 通常使用Docker完成, 然后, 可以通过几种可能的方式之一部署该容器镜像.
使用Linux容器有几个优点, 包括安全性, 可复制性, 简单性等.
# 什么是容器
容器(主要是Linux容器)是一种非常轻量级的打包应用程序的方式, 其包括所有依赖项和必要的文件, 同时它们可以和同一系统中的其他容器(或者其他应用程序/组件)相互隔离.
Linux容器使用宿主机(如物理服务器, 虚拟机, 云服务器等)的Linux内核运行. 这意味着它们非常轻量(与模拟整个操作系统的完整虚拟机相比). 通过这样的方式, 容器消耗很少的资源, 与直接运行进程相当(虚拟机会消耗更多). 容器的进程(通常只有一个), 文件系统和网络都运行在隔离的环境, 这简化了部署, 安全, 开发等.
# 什么是容器镜像
容器是从容器镜像运行的. 容器镜像是容器中文件, 环境变量和默认命令/程序的静态版本, 静态这里的意思是容器镜像还没有运行, 只是打包的文件和元数据.
与存储静态内容的"容器镜像"相反, "容器"通常指正在运行的实例, 即正在执行的.
当容器启动并运行时(从容器镜像启动), 它可以创建或更改文件, 环境变量等. 这些更改将仅存在于该容器中, 而不会持久化到底层的容器镜像中(不会保存到磁盘). 容器镜像相当于程序和文件, 例如python命令和某些文件如main.py. 而容器本身(与容器镜像相反)是镜像的实际运行实例, 相当于进程. 事实上, 容器仅在有进程运行时才运行(通常它只是一个单独的进程). 当容器中没有进程运行时, 容器就会停止.
# 容器镜像
Docker一直是创建和管理容器镜像和容器的主要工具之一. 还有一个公共Docker Hub, 其中包含预制的官方容器镜像, 适用于许多工具, 环境, 数据库和应用程序. 例如, 有一个官方的Python镜像. 还有许多其他镜像用于不同的需要(例如数据库), 例如:
- PostgreSQL
- MySQL
- MongoDB
- Redis, etc
通过使用预制的容器镜像, 可以非常轻松地组合并使用不同的工具. 例如, 尝试一个新的数据库. 在大多数情况下, 可以使用官方镜像, 只需为其配置环境变量即可. 这样, 在许多情况下, 可以了解容器和Docker, 并通过许多不同的工具和组件重复使用这些知识.
因此, 你可以运行带有不同内容的多个容器, 例如数据库, Python应用程序, 带有React前端应用程序的Web服务器, 并通过内网将他们连接在一起. 所有容器管理系统(Docker和Kubernetes)都集成了这些网络功能.
# 容器和进程
容器镜像通常在其元数据中包含启动容器时应运行的默认程序或命令以及要传递给该程序的参数, 与在命令行中的情况非常类似.
当容器启动时, 它将运行该命令/程序(尽管你可以覆盖它并使其运行不同的命令/程序). 只要主进程(命令或程序)在运行, 容器就在运行. 容器通常有一个单个进程, 但也可以从主进程启动子进程, 这样你就可以在同一个容器中拥有多个进程. 但是, 如果没有至少一个正在运行的进程, 就不可能有一个正在运行的容器. 如果主进程停止, 容器也会停止.
# 为FastAPI构建Docker镜像
下面将展示如何基于官方Python镜像从头开始为FastAPI构建Docker镜像. 例如:
- 使用Kubernetes或类似工具
- 在Raspberry Pi上运行时
- 使用可为你运行容器镜像的云服务等
# 依赖项
你通常会在某个文件中包含应用程序的依赖项. 具体做法取决于你安装这些依赖时所使用的工具. 最常见的方法是创建一个requirements.txt文件, 其中每行包含一个包名称和它的版本. 当然也可以使用在[关于FastAPI版本]中讲到的方法来设置版本范围.
fastapi>=0.68.0,<0.69.0
pydantic>=1.8.0,<2.0.0
uvicorn>=0.15.0,<0.16.0
2
3
pip install -r requirements.txt
# 创建FastAPI代码
- 创建
app目录并进入 - 创建一个空文件
__init__.py - 创建一个
main.py文件
from typing import Union
from fastapi import FastAPI
app = FastAPI()
@app.get("/")
def read_root():
return {"Hello", "World"}
@app.get("/items/{item_id}")
def read_item(item_id: int, q: Union[str, None] = None):
return {"item_id": item_id, "q": q}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# Dockerfile
现在在相同的project目录创建一个名为Dockerfile的文件
# 从官方Python基础镜像开始
FROM python:3.9
# 将当前工作目录设置为/code
# 这是我们放置requirements.txt文件和app目录的位置
WORKDIR /code
# 将复合要求的文件复制到/code目录中
# 首先仅复制requirements.txt文件, 而不复制代码
# 由于此文件不经常更改, Docker将检测到它并在这一步中使用缓存, 从而为下一步启用缓存
COPY ./requirements.txt /code/requirements.txt
# 安装需求文件中的包依赖项
# --no-cache-dir选项告诉pip不要在本地保存下载的包, 因为只有当pip再次运行以安装相同的包时才会这样, 但在与容器一起工作时情况并非如此
# --no-cache-dir仅与pip相关, 与Docker或容器无关.
# --upgrade选项告诉pip升级软件包(如果已经安装)
# 因为上一步复制文件可以被Docker缓存检测到, 所以此步骤也将使用Docker缓存(如果可用)
# 在开发过程中一次又一次构建镜像时, 在此步骤中使用缓存将节省大量时间, 而不是每次都下载和安装所有依赖项
RUN pip install --no-cache-dir --upgrade -r /code/requirements.txt
# 将./app目录复制到/code目录中
# 由于其中包含更改最频繁的所有代码, 因此Docker缓存不会轻易用于此操作或后续步骤.
# 因此, 将其放在Dockerfile接近最后的位置非常重要, 以优化容器镜像的构建时间.
COPY ./app /code/app
# 设置命令来运行uvicorn服务器
# CMD接受一个字符串列表, 每个字符串都是你在命令行中输入的内容, 并用空格分隔.
# 该命令将从当前工作目录运行, 即你上面使用WORKDIR /code设置的同一/code目录.
# 应为程序从/code启动, 并且其中包含你的代码目录./app, 所以Uvicorn将能够从app.main中查看并import app.
CMD ["uvicorn", "app.main:app", "--host", "0.0.0.0", "--port", "80"]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
你现在应该具有如下目录结构:
.
├── app
│ ├── __init__.py
│ └── main.py
├── Dockerfile
└── requirements.txt
2
3
4
5
6
# 在TLS终止代理后面
如果你在Nginx或Traefik等TLS终止代理(负载均衡器)后面运行容器, 请添加选项--proxy-headers, 这将告诉Uvicorn信任该代理发送的标头, 告诉它应用程序正在HTTPS后面运行等信息.
CMD ["uvicorn", "app.main:app", "--proxy-headers", "--host", "0.0.0.0", "--port", "80"]
# Docker缓存
这个Dockerfile中有一个重要的技巧, 我们首先只单独复制包含依赖项的文件, 而不是其余代码.
COPY ./requirements.txt /code/requirements.txt
Docker之类的构建工具是通过增量的方式来构建这些容器镜像的, 具体做法是从Dockerfile顶部开始, 每一条指令生成的文件都是镜像的"一层", 通过这些"层"一层一层地叠加到基础镜像上, 最后我们就得到了最终的镜像.
Docker和类似工具在构建镜像时也会使用内部缓存, 如果自上次构建容器镜像以来文件没有更改, 那么它将重新使用上次创建的同一层, 而不是再次复制文件从头开始创建新层. 仅仅避免文件的复制不一定会有太多速度提升, 但是如果在这一步使用了缓存, 那么才可以在下一步中使用缓存. 例如, 可以使用安装依赖项那条指令的缓存:
RUN pip install --no-cache-dir --upgrade -r /code/requirements.txt
包含包依赖项的文件不会频繁更改, 只复制该文件(不复制其他的应用代码), Docker才能在这一步使用缓存.
Docker进而能使用缓存进行下一步, 即下载并安装这些依赖项. 这才是我们节省大量时间的地方. 下载和安装依赖项可能需要几分钟, 但使用缓存最多只需要几秒钟. 由于你在开发过程中会一次又一次地构建容器镜像以检查代码更改是否有效, 因此可以累计节省大量时间.
在Dockerfile末尾附近, 再添加复制代码的指令, 由于代码是更改最频繁的, 所以将其放在最后, 因为这一步之后的内容基本上都是无法使用缓存的.
COPY ./app /code/app
# 构建Docker镜像
现在所有文件都已就位, 可以开始构建容器镜像.
- 转到项目目录(在
Dockerfile所在的位置, 包含app目录) - 构建你的FastAPI镜像
docker build -t myimage .
注意最后的., 它相当于./, 它告诉Docker用于构建容器镜像的目录. 在本例中, 它相当于当前目录(.)
# 启动Docker容器
根据你的镜像运行容器:
docker run -d --name mycontainer -p 80:80 myimage
# 检查以下
你应该能在Docker容器的URL中检查它, 例如: http://192.168.99.100/items/5?q=somequery或http://127.0.0.1/items/5?q=somequery(或其他等价的, 使用Docker主机).
你会看到类似内容:
{"item_id": 5, "q": "somequery"}
# 交互式API文档
现在可以访问http://192.168.99.100/docs或http://127.0.0.1/docs(或其他等价的, 使用Docker主机). 你将看到交互式API文档:
# 备选的API文档
你还可以访问http://192.168.99.100/redoc或http://127.0.0.1/redoc(或其他等价的, 使用Docker主机).
# 使用单文件FastAPI构建Docker镜像
如果你的FastAPI是单个文件, 例如没有./app目录的main.py, 则你的文件结构可能如下所示:
.
├── Dockerfile
├── main.py
└── requirements.txt
2
3
4
然后你只需要更改相应的路径即可将文件复制到Dockerfile中:
FROM python:3.9
WORKDIR /code
COPY ./requirements.txt /code/requirements.txt
RUN pip install --no-cache-dir --upgrade -r /code/requirements.txt
# 直接将main.py文件复制到/code目录中(不包含任何./app目录)
COPY ./main.py /code/
# 运行Uvicorn并告诉它从main导入app对象(而不是从app.main导入)
CMD ["uvicorn", "main:app", "--host", "0.0.0.0", "--port", "80"]
2
3
4
5
6
7
8
9
10
11
12
13
然后调整Uvicorn命令使用新模块main而不是app.main来导入FastAPI实例app.
# 部署概念
容器主要是一种简化构建和部署应用程序的过程的工具, 但它们并不强制执行特定的方法来处理这些部署概念, 并且有几种可能的策略. 好消息是, 对于每种不同的策略, 都有一种方法可以涵盖所有部署概念.
- 安全性 -- HTTPS
- 启动时运行
- 重新启动
- 复制(运行的进程数)
- 内存
- 开始前的先前步骤
# HTTPS
如果我们只关注FastAPI的应用程序的容器镜像(以及稍后运行的容器), HTTPS通常会由另一个工具在外部处理. 它可以是另一个容器, 例如使用Traefik, 处理HTTPS和自动获取证书. 或者, HTTPS可以由云服务上作为其服务之一进行处理(同时仍在容器中运行程序).
# 在启动和重新启动时运行
通常还有另一个工具负责启动和运行你的容器. 它可以直接是Docker, 或者Docker Compose, Kubernetes, 云服务等. 在大多数(或所有)情况下, 有一个简单的选项可以在启动时运行容器并在失败时重新启动. 例如, 在Docker中, 它是命令行选项--restart. 如果不使用容器, 让应用程序在启动时运行并重新启动可能会很麻烦而且困难.
# 复制 - 进程数
如果你有一个集群, 比如Kubernetes, Docker Swarm, Nomad或其他类似的复杂系统来管理多台机器上的分布式容器, 那么你可能希望在集群级别处理复制, 而不是在每个容器中使用进程管理器(如带有Worker的Gunicorn). 像Kubernetes这样的分布式容器管理系统通常有一些集成的方法来处理容器的复制, 同时仍然支持传入请求的负载均衡. 全部都在集群级别.
在这些情况下, 你可能希望从头开始构建一个Docker镜像, 如上面所解释的那样, 安装依赖项并运行单个Uvicorn进程, 而不是运行Gunicorn和Uvicron workers这种.
# 负载均衡器
使用容器时, 通常会有一些组件监听主端口. 它可能是处理HTTPS的TLS终止代理或一些类似的工具的另一个容器. 由于该组件将接受请求的负载并以平衡的方式在worker之间分配请求, 因此它通常也称为负载均衡器.
用于HTTPS TLS终止代理的相同组件也可能是负载均衡器.
当使用容器时, 你用来启动和管理容器的同一系统已经具有内部工具来传输来自该负载均衡器(也可以是TLS终止代理)的网络通信(例如HTTP请求)到你的应用程序容器.
# 一个负载均衡器 - 多个worker容器
当使用Kubernetes或类似的分布式容器管理系统时, 使用其内部网络机制将允许单个在主端口上侦听的负载均衡器将通信请求传输到可能的多个运行你应用程序的容器.
运行你的应用程序的每个容器通常只有一个进程(例如, 运行FastAPI应用程序的Uvicorn进程). 它们都是相同的容器, 运行相同的东西, 但每个容器都有自己的进程, 内存等. 这样就可以在CPU的不同核心, 甚至在不同的机器充分利用并行化(parallelization).
具有负载均衡器的分布式容器系统将请求轮流分配给你的应用程序的每个容器. 因此, 每个请求都可以由运行你的应用程序的多个复制容器之一来处理. 通常, 这个负载均衡器能够处理发送到集群中的其他应用程序的请求(例如发送到不同的域, 或在不同的URL路径前缀下), 并正确地将该通信传输到在集群中运行的其他应用程序的对应容器.
# 每个容器一个进程
在这种情况下, 你可能希望每个容器有一个(Uvicorn)进程, 因为你已经在集群级别处理复制. 因此, 在这种情况下, 你不会希望拥有像Gunicorn和Uvicorn worker一样的进程管理器, 或者Uvicorn使用自己的Uvicorn worker. 你可能希望每个容器(但可能有多个容器)只有一个单独的Uvicorn进程. 在容器内拥有另一个进程管理器(就像使用Gunicorn或Uvicorn管理Uvicorn工作线程一样)只会增加不必要的复杂性, 而你很可能已经在集群系统中处理这些复杂性了.
# 具有多个进程的容器
当然, 在某些特殊情况, 你可能希望拥有一个容器, 其中包含Gunicorn进程管理器, 并在其中启动多个Uvicorn worker进程. 在这些情况下, 你可以使用官方Docker镜像, 其中包含Gunicorn作为运行多个Uvicorn工作进程的进程管理器, 以及一些默认设置来根据当前情况调整工作进程数量自动CPU核心. 下面的Gunicorn-Uvicorn官方Docker镜像将会提供更多信息.
# 一个简单的应用程序
如果你的应用程序足够简单, 你不需要(至少当前不需要)过多地微调进程数量, 并且可以使用默认值, 那么你可能需要容器中的进程管理器(使用官方Docker镜像), 并且你在单个服务器而不是集群上运行它.
# Docker Compose
你可以使用Docker Compose部署到单个服务器(而不是集群), 因此你没有一种简单的方法来管理容器的复制(使用Docker Compose), 同时保留共享网络和负载均衡. 然后, 你可能希望拥有一个单个容器, 其中有一个进程管理器, 在其中启动多个worker进程.
# Prometheus和其他原因
你还可能有其他原因, 这将使你更容易拥有一个带有多个进程的单个容器, 而不是拥有每个容器中都有单个进程的多个容器. 例如(取决于你的设置)你可以在同一个容器中拥有一些工具, 例如Prometheus exporter, 该工具应该有权访问每个请求. 在这种情况下, 如果你有多个容器, 默认情况下, 当Prometheus来读取metrices时, 它每次都会获取单个容器的metrics(对于处理该特定请求的容器), 而不是获取所有复制容器的累积metrics.
在这种情况下, 这种做法会更加简单: 让一个容器具有多个进程, 并在同一个容器上使用本地工具(例如Prometheus exporter)搜集所有内部进程的Prometheus指标并公开单个容器上的这些指标.
要点是, 这些都不是你必须盲目遵循的一成不变的规则. 你可以根据这些思路评估你自己的场景并决定什么方法是最适合你的系统, 考虑如何管理以下概念:
- 安全性 -- HTTPS
- 启动时运行
- 重新启动
- 复制(运行的进程数)
- 内存
- 开始前的先前步骤
# 内存
如果你每个容器运行一个进程, 那么每个容器所消耗的内存或多或少是定义明确的, 稳定的且有限的(如果他们是复制的, 则不止一个).
然后, 你可以在容器管理系统的配置中设置相同的内存限制和要求(例如在Kubernetes中), 这样, 它将能够在可用机器中复制容器, 同时考虑容器所需的内存量以及集群中机器中的可用内存量.
如果你的应用程序很简单, 这可能不是问题, 并且你可能不需要指定内存限制, 但是, 如果你使用大量内存(例如使用机器学习模型), 则应该检查你消耗了多少内存并调整每台机器中运行的容器数量(也可以向集群添加更多机器).
如果你每个容器运行多个进程(例如使用官方Docker镜像), 你必须确保启动的进程数量不会消耗比可用内存更多的内存.
# 启动之前的步骤和容器
如果你使用容器(如Docker, Kubernetes), 那么你可以使用两种主要方法:
# 多个容器
如果你有多个容器, 可能每个容器都运行一个单个进程(例如, 在Kubernetes集群中), 那么你可能希望有一个单独的容器执行以下操作: 在单个容器中运行单个进程执行先前步骤, 即运行复制的worker容器之前.
如果你使用Kubernetes, 可能是Init Container.
如果在你的用例中, 运行前面的步骤并行多次没有问题(例如, 如果你没有运行数据库迁移, 而只是检查数据库是否已准备好), 那么你也可以将它们放在开始主进程之前在每个容器中.
# 单容器
如果你有一个简单的设置, 使用一个单个容器, 然后启动多个工作进程(或者也只是一个进程), 那么你可以在启动进程之前在应用程序同一个容器中运行先前的步骤. 官方Docker镜像内部支持这一点.
# 带有Gunicorn的官方Docker镜像 - Uvicorn
有一个官方Docker镜像, 其中包含与Uvicorn worker一起运行的Gunicorn, 如上一章所述: 服务器工作线程-Gunicorn与Uvicorn. 该镜像主要在上述情况下有用: 具有多个进程和特殊情况的容器.
你很有可能不需要此基础镜像或任何其他类似的镜像, 最好从头开始构建镜像, 如上面所述: 为FastAPI构建Docker镜像.
该镜像包含一个自动调整机制, 用于根据可用的CPU核心设置worker进程数. 它具有合理的默认值, 但仍然可以使用环境变量或配置文件更改和更新所有配置. 它还支持通过一个脚本运行开始前的先前步骤.
要查看所有配置和选项, 请转到Docker镜像页面: tiangolo/uvicorn-gunicorn-fastapi
# 官方Docker镜像上的进程数
此镜像上的进程数是根据可用的CPU核心自动计算的, 这意味着它将尝试尽可能多地榨取CPU的性能. 还可以使用环境变量等配置来调整它. 但这也意味着, 但这也意味着, 由于进程数量取决于容器运行的的CPU, 因此消耗的内存量也将取决于该数量.
因此, 如果你的应用程序消耗大量内存(例如机器学习模型), 并且你的服务器有很多CPU核心但内存很少, 那么你的容器最终可能会尝试使用比实际情况更多的内存, 并且性能会下降很多(甚至崩溃).
# 创建一个Dockerfile
以下是如何根据此镜像创建Dockerfile:
FROM tiangolo/uvicorn-gunicorn-fastapi:python3.9
COPY ./requirements.txt /app/requirements.txt
RUN pip install --no-cache-dir --upgrade -r /app/requirements.txt
COPY ./app /app
2
3
4
5
6
7
# 更大的应用程序
如果你按照有关创建具有多个文件的更大应用程序的部分进行操作, 你的Dockerfile可能看起来是这样的:
FROM tiangolo/uvicorn-gunicorn-fastapi:python3.9
COPY ./requirements.txt /app/requirements.txt
RUN pip install --no-cache-dir --upgrade -r /app/requirements.txt
COPY ./app /app/app
2
3
4
5
6
7
# 何时使用
如果你使用Kubernetes(或其他)并且你已经在集群级别设置复制, 并且具有多个容器, 在这些情况下, 你最好按照上面的描述从头开始构建镜像: 为FastAPI构建Docker镜像.
另外, 如果你多应用程序足够简单, 基于CPU设置默认进程数效果很好, 并且你不想在集群级别手动配置复制, 并且不会运行更多进程, 或者你使用Docker Compose进行部署, 在单个服务器上运行等. 那么该镜像主要在具有多个进程的容器和特殊情况中描述的特殊情况下有用.
# 部署容器镜像
拥有容器(Docker)镜像后, 有多种方法可以部署它. 例如:
- 在单个服务器中使用Docker Compose
- 使用Kubernetes集群
- 使用Docker Swarm模式集群
- 使用Nomad等其他工具
- 使用云服务获取容器镜像并部署它
# Docker镜像与Poetry
如果你使用Poetry来管理项目的依赖项, 你可以使用Docker多阶段构建:
# 这是第一个阶段, 称为requirements-stage
FROM python:3.9 as requirements-stage
# 将/tmp设置为当前工作目录
# 这是我们生成文件requirements.txt的地方
WORKDIR /tmp
# 在此阶段安装Poetry
RUN pip install poetry
# 将pyproject.toml和poetry.lock文件复制到/tmp目录
# 因为它使用./poetry.lock*(以*结尾), 所以如果该文件尚不可用, 它不会崩溃
COPY ./pyproject.toml ./poetry.lock* /tmp/
# 生成requirements.txt文件
RUN poetry export -f requirements.txt --output requirements.txt --without-hashes
# 这是最后阶段, 这里的任何内容都将保留在最终的容器镜像中
FROM python:3.9
# 将当前工作目录设置为/code
WORKDIR /code
# 将requirements.txt文件复制到/code目录
# 该文件仅存在于前一个阶段, 这就是为什么我们使用--from-requirements-stage来复制它
RUN pip install --no-cache-dir --upgrade -r /code/requirements.txt
# 将app目录复制到/code目录
COPY ./app /code/app
# 运行uvicorn命令, 告诉它使用从app.main导入的app对象
CMD ["uvicorn", "app.main:app", "--host", "0.0.0.0", "--port", "80"]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
Docker stage是Dockerfile的一部分, 用作临时容器镜像, 仅用于生成一些稍后使用的文件. 第一阶段仅用于安装Poetry并使用Poetry的pyproject.toml文件中的项目依赖项生成requirements. 此requirements.txt文件将在下一阶段于pip一起使用. 在最终的容器镜像中仅保留最后阶段, 之前的阶段将被丢弃.
使用Poetry时, 使用Docker多阶段构建是有意义的, 因为你实际上并不需要在最终的容器镜像中安装Poetry及其依赖项, 你只需要生成用于安装项目依赖项的requirements.txt文件. 然后, 在下一个(也是最后一个)阶段, 你将或多或少地以与前面描述的相同的方式构建镜像.
# 在TLS终止代理后面 - Poetry
同样, 如果你在Nginx或Traefik等TLS终止代理(负载均衡器)后面运行容器, 请将选项--proxy-headers添加到命令中:
CMD ["uvicorn", "app.main:app", "--proxy-headers", "--host", "0.0.0.0", "--port", "80"]
# 回顾
使用容器系统, 处理所有部署概念变得相当简单:
- 安全性 -- HTTPS
- 启动时运行
- 重新启动
- 复制(运行的进程数)
- 内存
- 开始前的先前步骤
在大多数情况下, 你可能不想使用任何基础镜像, 而是基于官方Python Docker镜像从头开始构建容器镜像. 处理好Dockerfile和Docker缓存中指令的顺序, 你可以最小化构建时间, 从而最大限度地提高生产力. 在某些情况下, 你可能需要使用FastAPI的官方Docker镜像.
- 路径操作的高级配置
- OpenAPI 的 operationId
- 从 OpenAPI 中排除
- docstring的高级用途
- 额外的状态码
- 额外的状态码
- OpenAPI 和 API 文档
- 直接返回响应
- 返回Response
- 在Response中使用jsonable_encoder
- 返回自定义Response
- 说明
- 自定义响应 -- HTML, 流, 文件和其他
- 使用ORJSONResponse
- HTML响应
- 可用响应
- 额外文档
- OPENAPI中的其他响应
- model附加响应
- 主响应的其他媒体类型
- 组合信息
- 联合预定义响应和自定义响应
- 有关OpenAPI响应的更多信息
- 响应Cookies
- 使用Response参数
- 直接响应Response
- 响应头
- 使用Response参数
- 直接返回Response
- 自定义头部
- 响应 -- 更改状态码
- 使用场景
- 使用Response参数
- 高级依赖项
- 参数化的依赖项
- 可调用实例
- 参数化实例
- 创建实例
- 把实例作为依赖项
- 高级安全
- OAuth2 作用域
- HTTP 基础授权
- 直接使用请求
- Request对象的细节
- 直接使用Request对象
- Request文档
- 使用数据类
- response_model使用数据类
- 在嵌套数据结构中使用数据类
- 深入学习
- 版本
- 高级中间件
- 添加ASGI中间件
- 集成中间件
- HTTPSRedirectMiddleware
- TrustedHostMiddleware
- GZipMiddleware
- 其它中间件
- 子应用 -- 挂载
- 顶层应用
- 子应用
- 挂载子应用
- 查看文档
- 技术细节: root_path
- 使用代理
- 移除路径前缀的代理
- 关于移除路径前缀的代理
- 本地测试Traefik
- 附加的服务器
- 挂载子应用
- 模板
- 安装依赖项
- 使用Jinja2Templates
- 编写模板
- 模板与静态文件
- 更多说明
- Websockets
- 安装WebSockets
- WebSockets客户端
- 创建websocket
- 等待消息并发送消息
- 尝试一下
- 使用Depends和其他依赖项
- 处理断开连接和多个客户端
- 更多信息
- 生命周期事件
- 用例
- 声明周期lifespan
- 生命周期函数
- 异步上下文管理器
- 替代事件(弃用)
- 技术细节
- 子应用
- 测试 Wwebsockets
- 测试事件: 启动 -- 关闭
- 测试依赖项
- 用例: 外部服务
- 使用app.dependency_overrides属性
- 异步测试
- pytest.mark.anyio
- HTTPX
- 示例
- 运行测试
- 详细说明
- 其他异步函数调用
- 设置和环境变量
- 环境变量
- Pydantic的Settings
- 在另一个模块中设置
- 在依赖项中使用设置
- 从.env文件中读取设置
- 小结
- OpenAPI 回调
- 使用回调的应用
- 常规FastAPI应用
- 存档回调
- 编写回调文档代码
- OpenAPI 网络钩子
- 使用网络钩子的步骤
- 使用FastAPI和OpenAPI文档化网络钩子
- 带有网络钩子的应用程序
- 包含 WSGI - Flask, Django, 其它
- 使用WSGIMiddleware
- 检查
- 生成客户端
- OpenAPI客户端生成
- 生成一个TypeScript前端客户端
- 带有标签的FastAPI应用
- 自定义操作ID和更好的方法名
- 优点
- FastAPI CLI
- fastapi dev
- fastapi run
- 部署
- 部署是什么意思
- 部署策略
- 关于FastAPI版本
- 固定你的fastapi版本
- 可用版本
- 关于版本
- 升级FastAPI版本
- 关于Starlette
- 关于Pydantic
- 关于HTTPS
- Let's Encrypt
- 面向开发人员的HTTPS
- 回顾
- 手动运行服务器
- 使用fastapi run命令
- ASGI服务器
- 服务器主机和服务器程序
- 安装服务器程序
- 运行服务器程序
- 部署概念
- 部署概念
- 安全性 - HTTPS
- 程序和进程
- 启动时运行
- 重新启动
- 复制 - 进程和内存
- 启动之前的步骤
- 资源利用率
- 回顾
- 服务器工作进程(Workers) - 使用Uvicorn的多工作进程模式
- 多个工作进程
- 部署概念
- 容器和Docker
- 回顾
- 容器中的FastAPI - Docker
- 什么是容器
- 什么是容器镜像
- 容器镜像
- 容器和进程
- 为FastAPI构建Docker镜像
- 检查以下
- 交互式API文档
- 备选的API文档
- 使用单文件FastAPI构建Docker镜像
- 部署概念
- HTTPS
- 在启动和重新启动时运行
- 复制 - 进程数
- 内存
- 启动之前的步骤和容器
- 带有Gunicorn的官方Docker镜像 - Uvicorn
- 部署容器镜像
- Docker镜像与Poetry
- 回顾