
FastAPI 简介
FastAPI是一个用于构建API的现代, 快速(高性能)的web框架, 使用Python并基于标准的Python类型提示.
关键特性:
- 快速: 可与NodeJS和Go并肩的极高性能(归功于Starlette和Pydantic). 最快的Python web框架之一.
- 高效编码: 提高功能开发速度约200%至300%.
- 更少BUG: 减少约40%的人为(开发者)导致错误.
- 智能: 极佳的编辑器支持. 处处皆可自动补全, 减少调试时间.
- 简单: 设计的易于使用和学习, 阅读文档的时间更短.
- 简短: 使代码重复最小化. 通过不同的参数生命实现丰富功能. bug更少.
- 健壮: 生产可用级别的代码. 还有自动生成的交互式文档.
- 标准化: 基于(并完全兼容)API的相关开放标准: OpenAPI(以前被称为Swagger)和JSON Schema.
# FastAPI 快速入门
# 依赖
Python及更高版本
FastAPI站在以下巨人的肩膀之上:
- Starlette 负责web部分
- Pydantic 负责数据部分
# 安装
pip install fastapi
还会需要一个ASGI服务器, 生产环境可以使用Uvicorn或者Hypercorn.
pip install "uvicorn[standard]"
# 示例
# 创建
创建一个main.py文件并写入以下内容:
from typing import Union
from fastapi import FastAPI
app = FastAPI()
@app.get("/")
def read_root():
return {"Hello": "World"}
@app.get("/items/{item_id}")
def read_item(item_id: int, q: Union[str, None] = None):
return {"item_id": item_id, "q": q}
2
3
4
5
6
7
8
9
10
11
12
13
async def
如果代码里会出现async/await, 请使用async def:
from typing import Union
from fastapi import FastAPI
app = FastAPI()
@app.get("/")
async def read_root():
return {"Hello": "World"}
@app.get("/items/{item_id}")
async def read_item(item_id: int, q: Union[str, None] = None):
return {"item_id": item_id, "q": q}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 运行
通过以下命令运行服务器:
uvicorn main:app --reload

uvicorn main:app --reload
uvicorn main:app命令含义如下:
main:main.py文件(一个Python模块)app: 在main.py文件中通过app = FastAPI()创建的对象--reload: 让服务器在更新代码后重新启动, 仅在开发时使用该选项
# 检查
http://127.0.0.1:8000/items/5?q=somequery
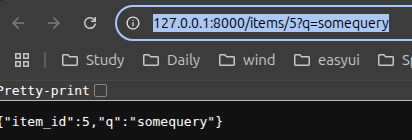
上面的代码已经创建了一个具有以下功能的API:
- 通过路径
/和/items/{item_id}接受HTTP请求 - 以上路径都接受
GET操作(也被称为HTTP方法) /items/{item_id}路径有一个路径参数item_id并且应该为int类型items/{item_id}路径有一个可选的str类型的查询参数q
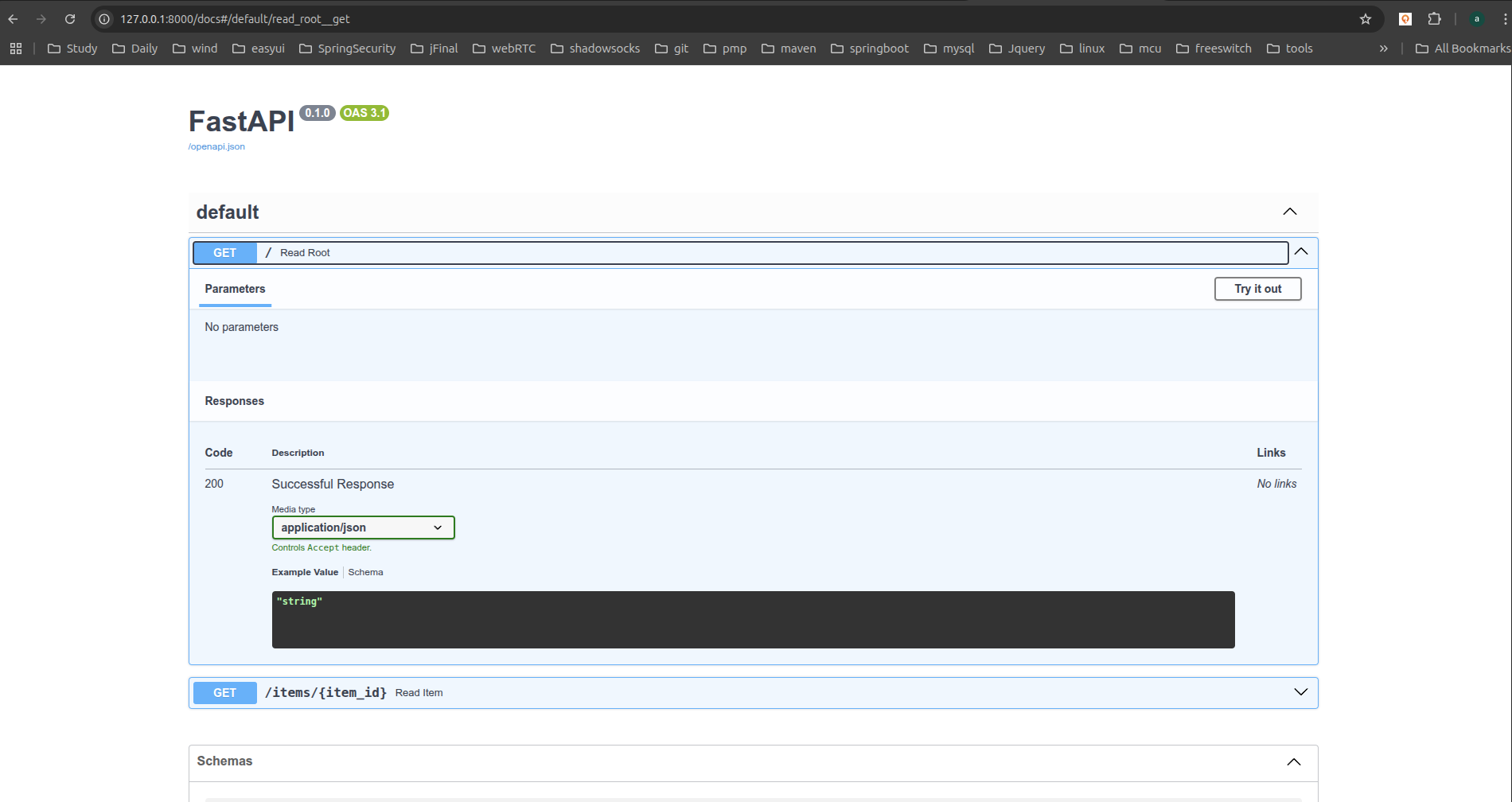
# 交互式API文档
访问http://127.0.0.1:8000/docs会看到自动生成的交互式API文档(由Swagger UI生成):
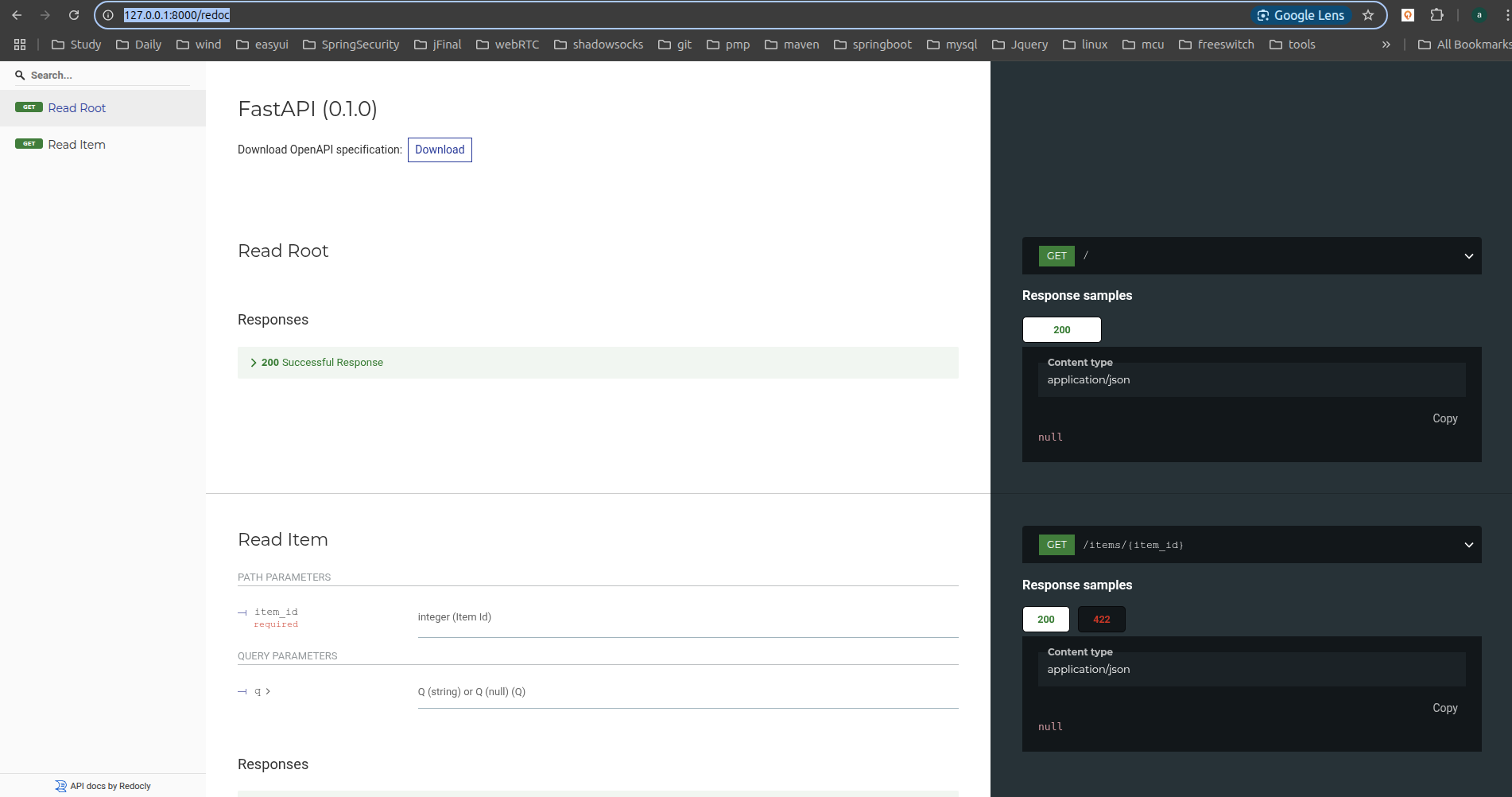
# 可选的API文档
访问http://127.0.0.1:8000/redoc会看到另一个自动生成的文档(由ReDoc生成):
# 示例升级
现在修改main.py文件来从PUT请求中接收请求体. 借助Pydantic来使用标准的Python类型生命请求体.
from typing import Union
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
name: str
price: float
is_offer: Union[bool, None] = None
@app.get("/")
async def read_root():
return {"Hello": "World"}
@app.get("/items/{item_id}")
async def read_item(item_id: int, q: Union[str, None] = None):
return {"item_id": item_id, "q": q}
@app.put("/items/{item_id}")
async def update_item(item_id: int, item: Item):
return {"item_name": item.name, "item_id": item_id}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
服务器会自动重载(因为上面的步骤中向uvicorn命令添加了--reload选项)
# 交互式API文档升级
- 交互式API文档将会自动更新, 并加入新的请求体:
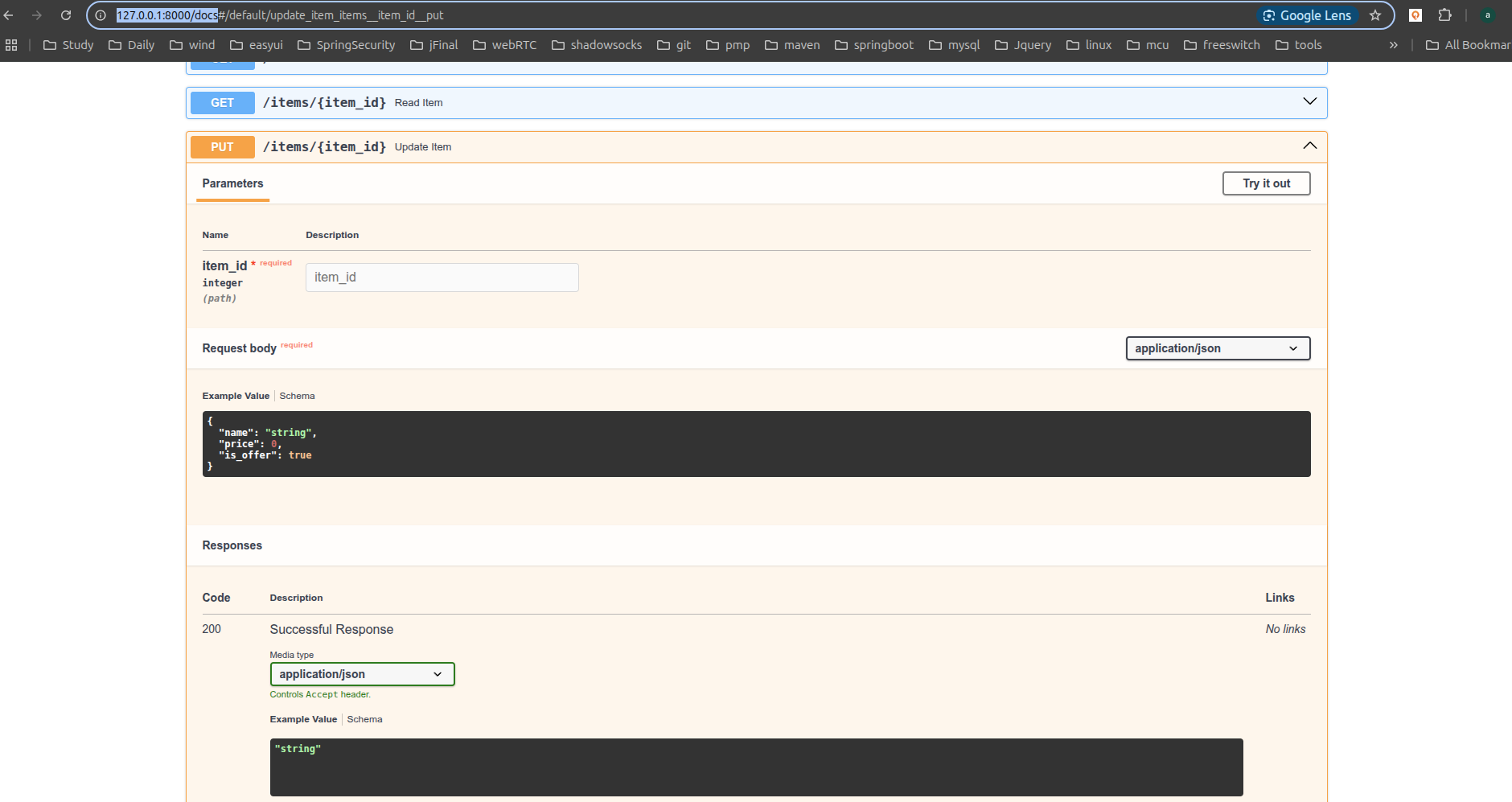
- 点击
Try it out按钮, 之后可以填写参数并直接调用API:
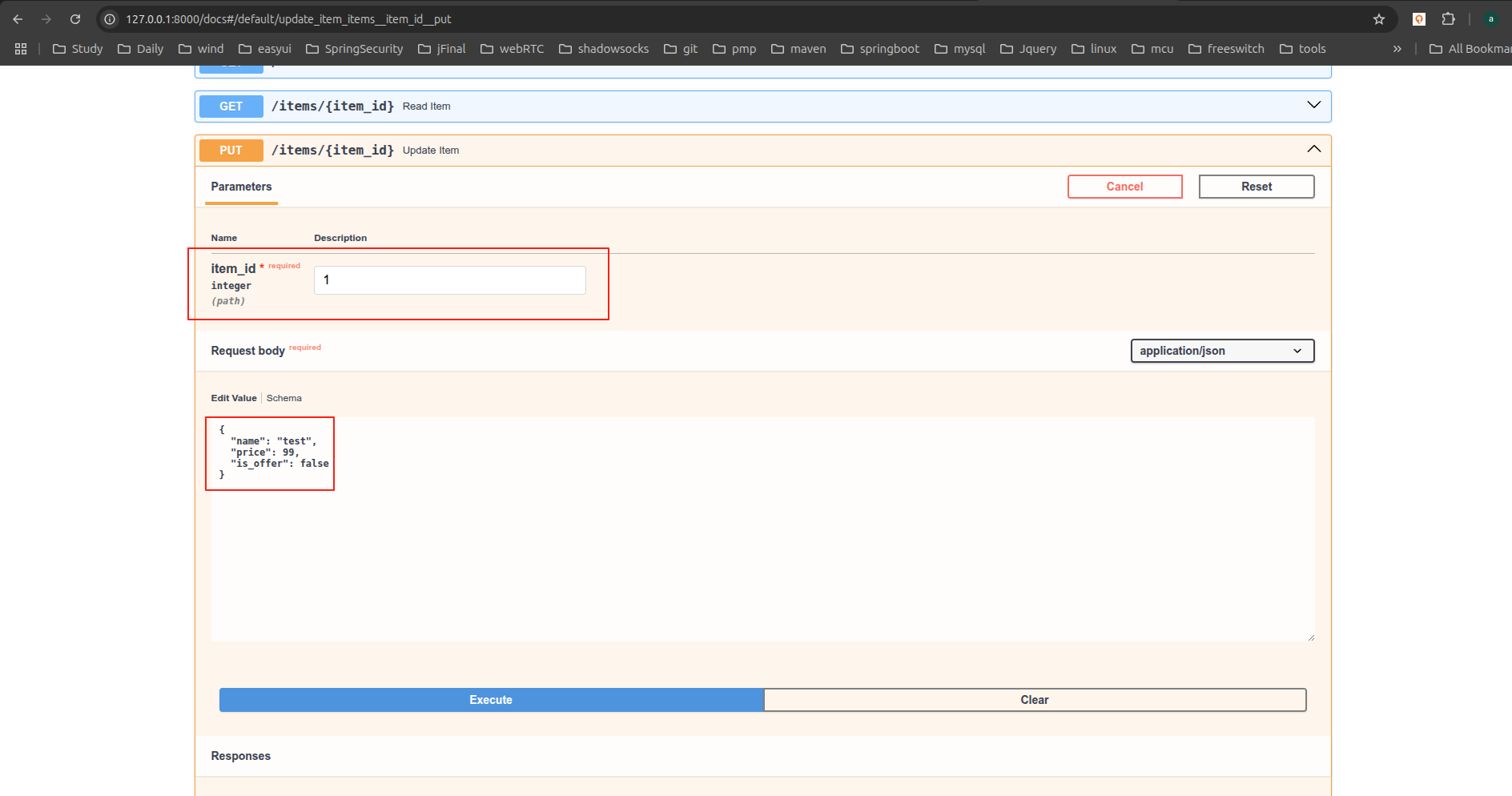
- 然后点击
Execute按钮, 用户界面将会和API进行通信, 发送参数, 获取结果并在屏幕上展示
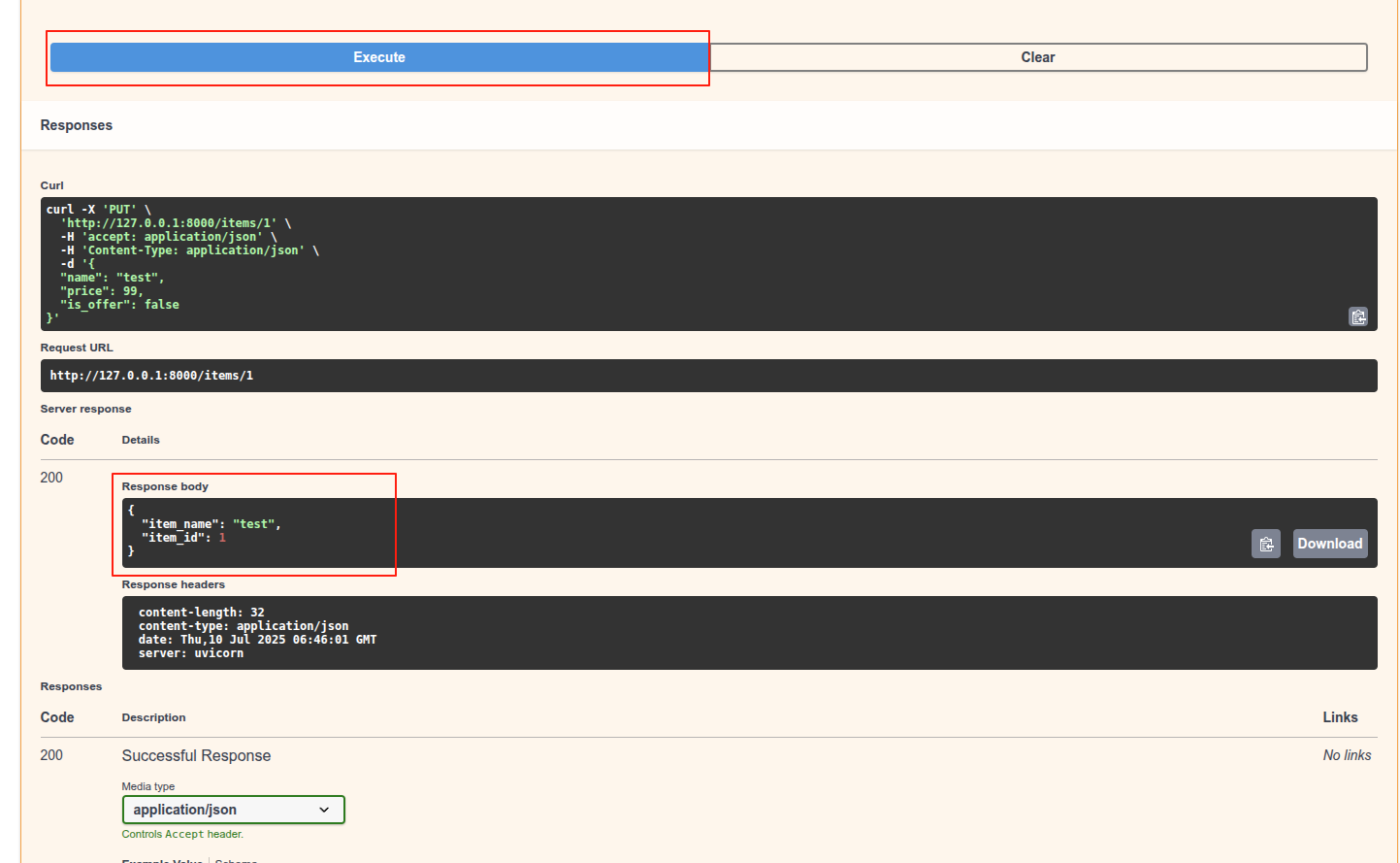
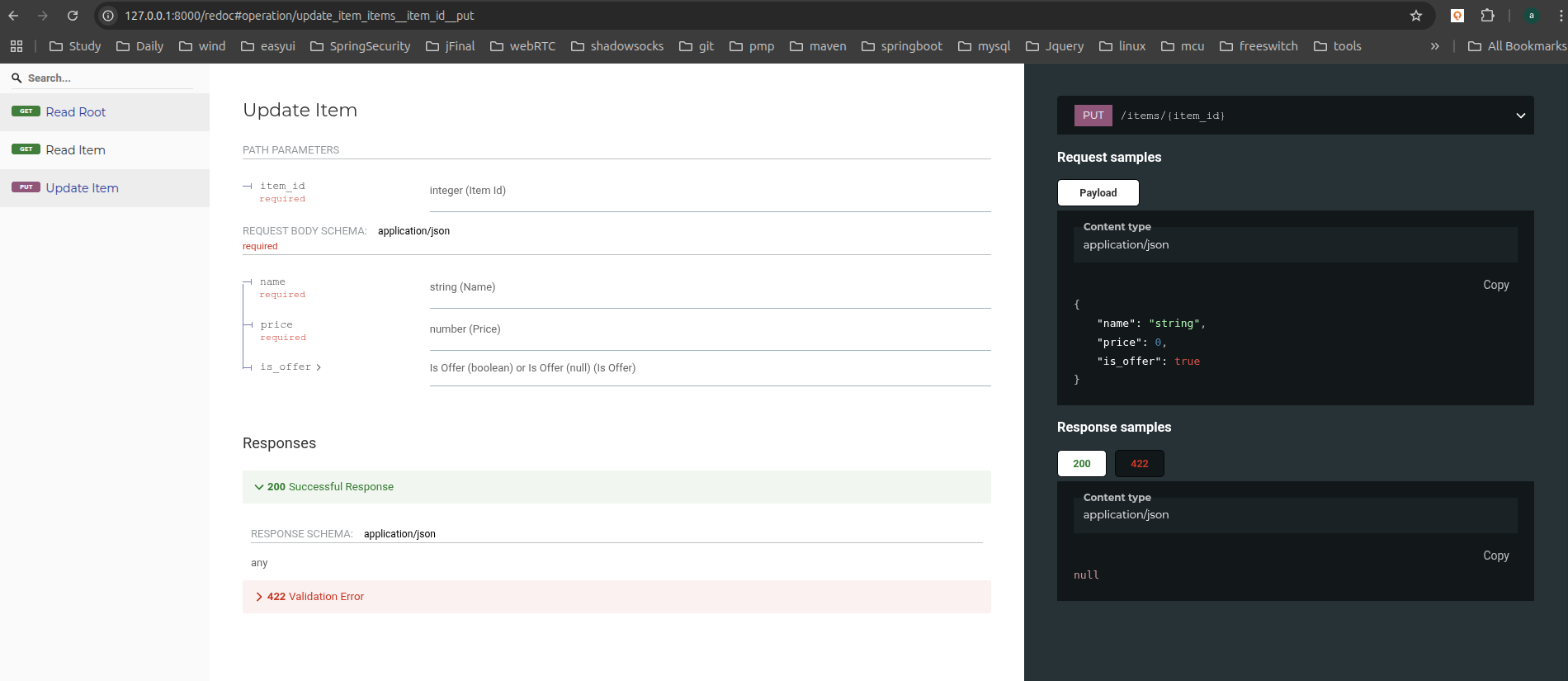
# 可选文档升级
访问http://127.0.0.1:8000/redoc, 可选文档同样会体现新加入的请求参数和请求体:
# 总结
总的来说, 你就像生命函数的参数类型一样只声明了一次请求参数, 请求体等的类型. 你使用了标准的现代Python类型来完成声明. 你不需要去学习新的语法, 了解特定库的方法或类, 等等. 只需要使用标准的Python及更高版本.
举个例子, 比如生命int类型: item_id: int 或者一个更复杂的Item模型: item: Item, 在进行一次声明之后, 将获得:
- 编辑器支持, 包括:
- 自动补全
- 类型检查
- 数据校验:
- 在校验失败时自动生成清晰的错误信息
- 对多层嵌套的JSON对象依然执行校验
- 转换来自网络请求的输入数据为Python数据类型, 包括以下数据:
- JSON
- 路径参数
- 查询参数
- Cookies
- 请求头
- 表单
- 文件
- 转换输出的数据: 转换Python数据类型为供网络传输的JSON数据
- 转换Python基础类型(
str,int,float,bool,list等) datetime对象UUID对象- 数据库模型
- ... 以及更多其他类型
- 转换Python基础类型(
- 自动生成的交互式API文档, 包括两种可选的用户界面:
- Swagger UI
- ReDoc
回到前面的代码示例, FastAPI将会:
- 校验
GET和PUT请求的路径中是否含有item_id - 校验
GET和PUT请求中的item_id是否为int类型- 如果不是, 客户端将会收到清晰有用的错误信息
- 检查
GET请求中是否有命名为q的可选查询参数(比如http://127.0.0.1:8000/items/foo?q=somequery)- 因为
q被声明为= None, 所以它是可选的 - 如果没有
None它将会是必需的(如PUT例子中的请求体)
- 因为
- 对于访问
/items/{item_id}的PUT请求, 将请求体读取为JSON并:- 检查是否有必需属性
name并且值为str类型 - 检查是否有必需属性
price并且值为float类型 - 检查是否有可选属性
is_offer, 如果有的话值应该为bool类型 - 以上过程对于多层嵌套的JSON对象同样也会执行
- 检查是否有必需属性
- 自动对JSON进行转换或转换成JSON
- 通过OpenAPI文档来记录所有内容, 可被用于:
- 交互式文档系统
- 许多编程语言的客户端代码自动生成系统
- 直接提供2种交互式文档web界面
# Python类型提示简介
Python 3.6+ 版本加入了对"类型提示"的支持. 这些"类型提示"是一种新的语法(在Python 3.6版本加入)用来声明一个变量的类型. 通过声明变量的类型, 编辑器和一些工具能提供更好的支持. 这只是一个关于Python类型提示的快速入门/复习. 它仅涵盖与FastAPI一起使用所需的最少部分...实际上只有很少一点.
整个FastAPI都基于这些类型提示构建, 它们带来了许多优点和好处.
# 动机
从一个简单的例子开始:
def get_full_name(first_name, last_name):
full_name = first_name.title() + " " + last_name.title()
return full_name
print(get_full_name("john", "doe"))
2
3
4
5
6
运行这段程序将输出: John Doe
这个函数做了下面这些事情:
- 接收
first_name和last_name参数 - 通过
title()将每个参数的第一个字母转换为大写形式 - 中间用一个空格来拼接它们
# 修改示例
这是一个非常简单的程序. 现在假设你从头开始编写这段程序. 在某一时刻, 开始定义函数, 并准备好了参数.... 现在需要调用一个"将第一个字母转换为大写形式的方法". 等等, 那个方法是什么来着? upper? 还是uppercase? first_uppercase? capitalize? 然后你尝试项编辑器自动补全寻求帮助. 输入函数的第一个参数first_name, 输入点好., 然后桥下Ctrl+Space来触发代码补全. 但遗憾的是并没有起什么作用:
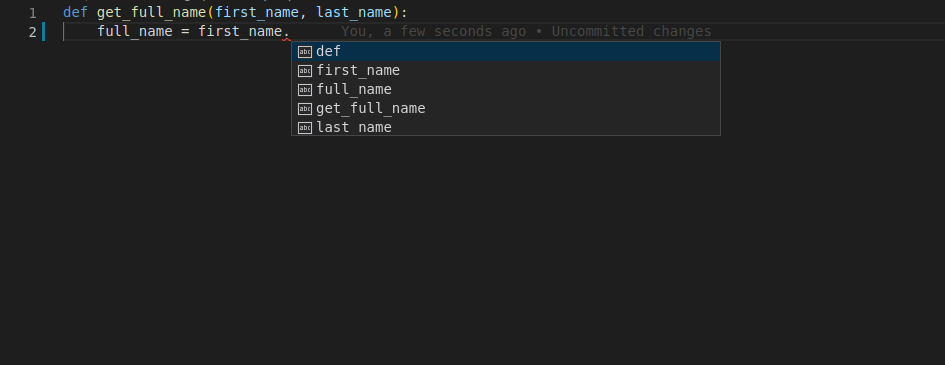
# 添加类型
让我们修改上面例子的一行代码. 将first_name, last_name改成first_name: str, last_name: str. 这些就是"类型提示":
def get_full_name(first_name: str, last_name: str):
full_name = first_name.title() + " " + last_name.title()
return full_name
print(get_full_name("john", "doe"))
2
3
4
5
6
这和声明默认值是不同的, 例如: first_name="john", last_name="doe", 这两者不一样, 我们用的是冒号:, 不是等号=. 而且添加类型提示一般不会改变原来的运行结果. 现在假设我们又一次正在创建这个函数, 这次添加了类型提示. 在同样的地方, 通过Ctrl+Space触发自动补全, 会发现:
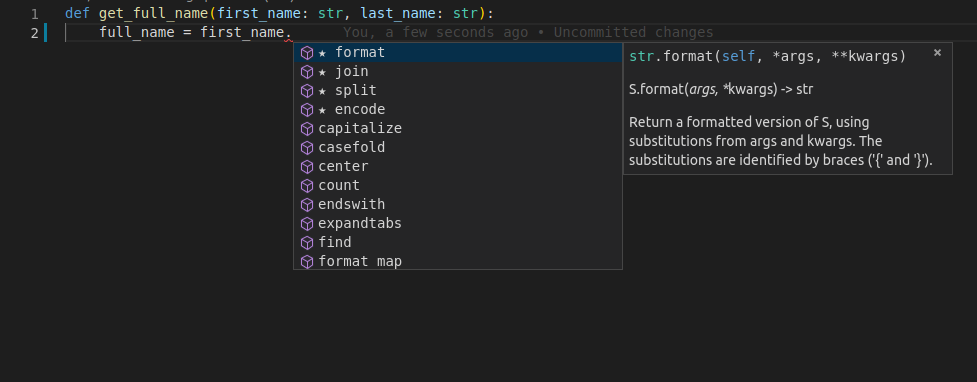
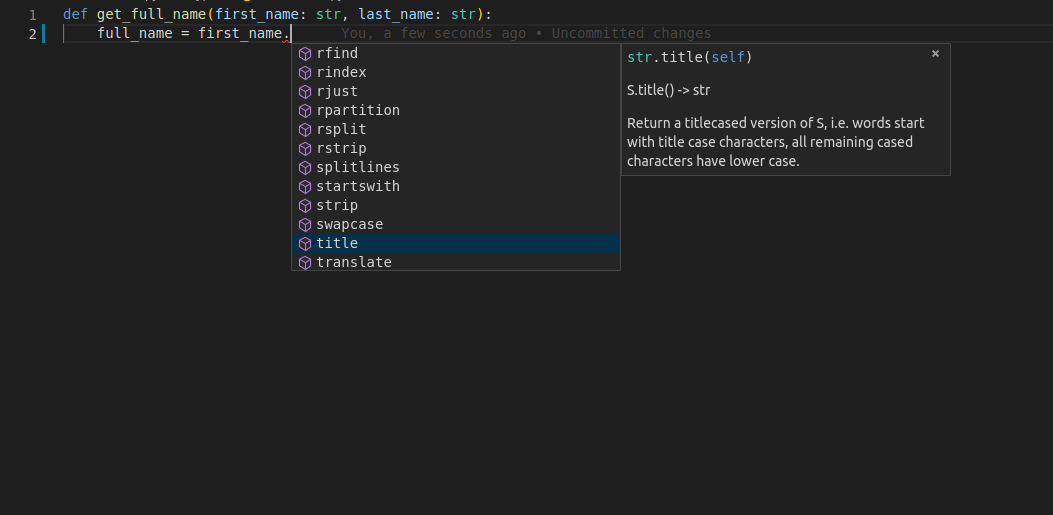
这样, 你可以滚动查看选项, 直到你找到看起来眼熟的那个:
# 更多动机
下面是一个已经有类型提示的函数:
def get_name_with_age(name: str, age: int):
name_with_age = name + " is this old: " + age
return name_with_age
2
3
因为编辑器已经知道了这些变量的类型, 所以不仅能对代码进行补全, 还能检查其中的错误:
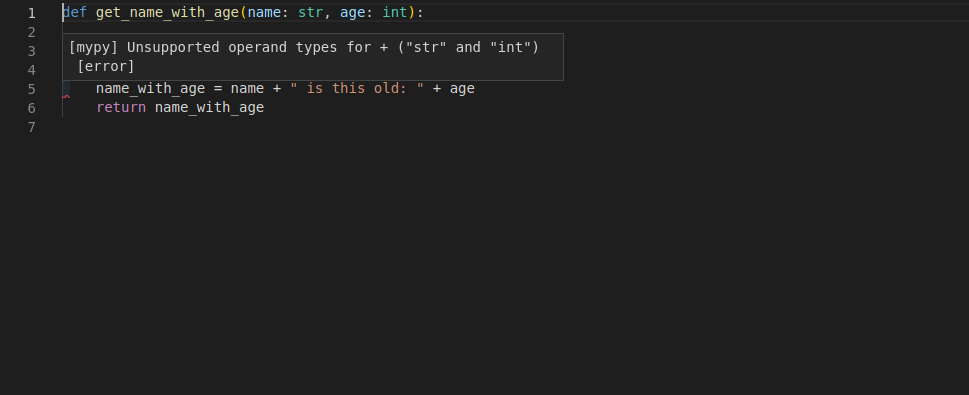
现在知道了必须先修复这个问题, 通过str(age)把age转换成字符串:
def get_name_with_age(name: str, age: int):
name_with_age = name + " is this old: " + str(age)
return name_with_age
2
3
# 声明类型
刚刚看到的就是声明类型提示的主要场景. 用于函数的参数. 这也是将在FastAPI中使用它们的主要场景.
- 简单类型: 不只是
str, 你能够声明所有的标准Python类型, 比如intfloatboolbytes
def get_items(item_a: str, item_b: int, item_c: float, item_d: bool, item_e: bytes):
return item_a, item_b, item_c, item_d, item_d, item_e
2
- 嵌套类型: 有些容器数据结构可以包含其他的值, 比如
dict,list,set和tuple. 它们内部的值也会拥有自己的类型. 可以使用Python的typing标准库来声明这些类型以及子类型. 它专门用来支持这些类型提示.
列表: 定义一个由str组成的list变量. 从typing模块导入List(注意时大写的L):
from typing import List
def process_items(items: List[str]):
for item in items:
print(item)
2
3
4
5
6
同样以冒号:来声明这个变量. 输入List作为类型. 由于列表是带有"子类型"的类型, 所以我们把子类型放在方括号中:
# Python 3.8+
from typing import List
def process_items(items: List[str]):
for item in items:
print(item)
2
3
4
5
6
# Python 3.9+
def process_items(items: list[str]):
for item in items:
print(item)
2
3
4
这表示: 变量items是一个list, 并且这个列表里的每一个元素都是str. 这样, 即使在处理列表中的元素时, 编辑器也可以提供支持. 没有类型, 几乎是不可能实现下面这样:
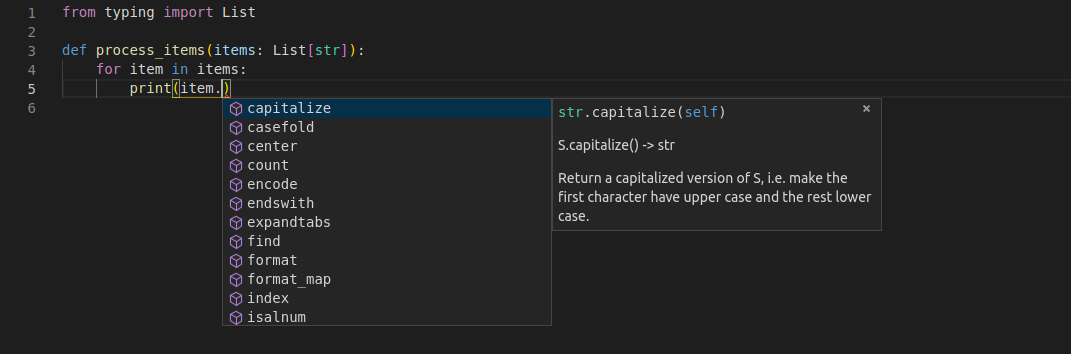
注意, 变量item是列表items中的元素之一. 而且, 编辑器仍然知道它是一个str, 并为此提供了支持.
元组和集合: 声明tuple和set的方法也是一样的
# Python 3.8+
from typing import Set, Tuple
def process_items(items_t: Tuple[int, int, str], items_s: Set[bytes]):
return items_t, items_s
2
3
4
5
# Python 3.9+
def process_items(items_t: tuple[int, int, str], items_s: set[bytes]):
return items_t, items_s
2
3
这表示:
- 变量
items_t是一个tuple, 其中的前两个元素都是int类型, 最后一个元素是str类型. - 变量
items_s是一个set, 其中的每个元素都是bytes类型
字典: 定义dict时, 需要传入两个子类型, 用逗号进行分割. 第一个子类型声明dict的所有键. 第二个子类型声明dict的所有值.
# Python 3.8+
from typing import Dict
def process_items(prices: Dict[str, float]):
for item_name, item_price in prices.items():
print(item_name)
print(item_price)
2
3
4
5
6
7
# Python 3.9+
def process_items(prices: dict[str, float]):
for item_name, item_price in prices.items():
print(item_name)
print(item_price)
2
3
4
5
这表示:
- 变量
prices是一个dict:- 这个
dict的所有键为str类型(可以看作是字典内每个元素的名称) - 这个
dict的所有值为float类型(可以看作是字典内每个元素的价格)
- 这个
# 类作为类型
也可以将类声明为变量的类型. 假设有一个名为Person的类, 拥有name属性:
class Person:
def __init__(self, name: str):
self.name = name
def get_person_name(one_person: Person):
return one_person.name
2
3
4
5
6
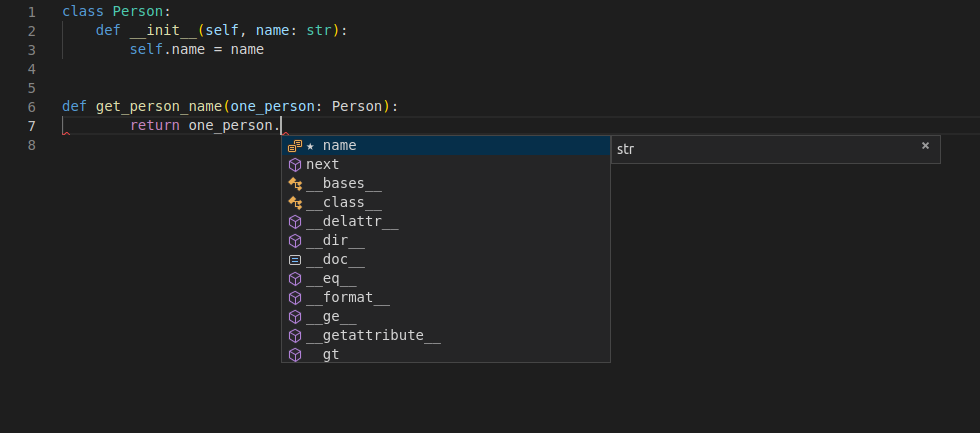
接下来, 可以将一个变量声明为Person类型:
class Person:
def __init__(self, name: str):
self.name = name
def get_person_name(one_person: Person):
return one_person.name
2
3
4
5
6
然后, 将再次获得所有编辑器支持:
# Pydantic 模型
Pydantic是一个用来执行数据校验的Python库. 可以将数据的"结构"声明为具有属性的类. 每个属性都拥有类型. 接着用一些值来创建这个类的实例, 这些值会被校验, 并被转换为适当的类型(在需要的情况下), 返回一个包含所有数据的对象. 然后, 你将获得这个对象的所有编辑器支持. 下面的例子来自Pydantic官方文档:
class Person:
def __init__(self, name: str):
self.name = name
def get_person_name(one_person: Person):
return one_person.name
2
3
4
5
6
想进一步了解Pydantic, 请阅读其文档, 整个FastAPI建立在Pydantic的基础之上.
# FastAPI中的类型提示
FastAPI利用这些类型提示来做下面几件事. 使用FastAPI时用类型提示声明参数可以获得:
- 编辑器支持
- 类型检查
...并且FastAPI还会用这些类型声明来:
- 定义参数要求: 声明对请求路径参数, 查询参数, 请求头, 请求体, 依赖等的要求
- 转换数据: 将来自请求的数据转换为需要的类型
- 校验数据: 对于每一个请求
- 当数据校验失败时自动生成错误信息返回给客户端
- 使用OpenAPI记录API:
- 然后用于自动生成交互式文档的用户界面
最重要的是, 通过使用标准的Python类型, 只需要在一个地方声明(而不是添加更多的类, 装饰器等), FastAPI会为你完成很多的工作.
# 并发 async / await
# 赶时间吗?
如果你正在使用第三方库, 它们会告诉你使用await关键字来调用它们, 类似:
results = await some_library()
然后, 通过async def声明你的路径操作函数:
@app.get('/')
async def read_results():
results = await some_library()
return results
2
3
4
Note
你只能在被async def创建的函数内使用await
如果你正在使用一个第三方库和某些组件(比如: 数据库, API, 文件系统...)进行通信, 第三方库又不支持使用await(目前大多数数据库三方库都是这样的), 这种情况你可以像平常那样使用def声明一个路径操作函数, 类似:
@app.get('/')
def results():
results = some_library()
return results
2
3
4
如果你的应用程序不需要与其他任何东西通信而等待其响应, 请使用async def. 如果不清楚, 使用def即可.
注意
你可以根据需要在路径操作函数中混合使用def和async def, 并使用最适合你的方式去定义每个函数. FastAPI将为它们做正确的事情. 无论如何, 在上述任何情况下, FastAPI仍将异步工作, 速度也非常快. 但是, 通过遵循以上步骤, 它将能够进行一些性能优化.
# 技术细节
Python的现代版本支持通过一种叫"协程"--使用async和await语法的东西来写"异步代码".
# 异步代码
异步代码仅仅意味着编程语言有办法告诉计算机/程序在代码中的某个点, 它将不得不等待在某些地方完成一些事情. 让我们假设一些事情被称为"慢文件". 所以, 在等待"慢文件"完成的这段时间, 计算机可以做一些其他工作. 然后计算机/程序每次有机会都会回来, 因为它又在等待, 或者它完成了当前所有的工作. 而且它将查看它等待的所有任务重是否有已经完成的, 做它必须做的任何事情. 接下来, 它完成第一个任务(比如是我们的"慢文件")并继续与之相关的一切. 这个"等待其他事情"通常指的是一些相对较慢(与处理器和RAM存储器的速度相比)的I/O操作, 比如说:
- 通过网络发送来自客户端的数据
- 客户端接收来自网络中的数据
- 磁盘中要由系统读取并提供给程序的文件的内容
- 程序提供给系统的要写入磁盘的内容
- 一个API的远程调用
- 一个数据库操作, 直到完成
- 一个数据库查询, 直到返回结果
- 等等
这个执行的时间大多是在等待I/O操作, 因此它们被叫做"I/O密集型"操作. 它被称为"异步"的原因是因为计算机/程序不必与慢任务"同步", 去等待任务完成的确切时刻, 而在此期间不做任何事情直到能够获取任务结果才继续工作. 相反, 作为一个"异步"系统, 一旦完成, 任务就可以排队等待一段时间(几微秒), 等待计算机程序完成它要做的任何事情, 然后回来获取结果并继续处理它们. 对于"同步"(与"异步"相反), 它们通常也使用"顺序"一词, 因为计算机程序在切换到另一个任务之前是按顺序执行所有步骤, 即使这些步骤涉及到等待.
# 并发与汉堡
上述异步代码的思想有时也被称为"并发", 它不同于"并行". 并发和并行都与"不同的事情或多或少同时发生"有关. 但是并发和并行之间的细节是完全不同的. 要了解差异, 请想象以下关于汉堡的故事:
# 并发汉堡
去快餐店, 你排队在后面, 收银员从你前面的人接单.

然后轮到你, 你选了两个汉堡.

收银员对厨房里的厨师说了一些话, 让他们知道必须为你准备汉堡(尽管他们目前正在为之前的顾客准备汉堡).

你付钱了, 收银员给你轮到的号码.

当你在等待的时候, 去挑选一张桌子, 然后坐下来等了很长时间(因为汉堡需要一些时间来准备). 当你坐在桌子旁等待的时候, 可以做一些其他事情, 比如书、手机.

在等待的过程中, 你会不时地查看柜台上显示的号码, 看是否已经轮到你了. 然后在某个时刻, 终于轮到你了, 你去柜台拿汉堡然后回到桌子上.

你享用了汉堡, 整个过程都很开心.

# 并行汉堡
现在让我们假设不时"并发汉堡", 而是"并行汉堡". 你和你的恋人一起去吃并行快餐. 你站在队伍中, 同时是厨师的几个收银员(比方说8个)从前面的人那里接单. 你之前的每个人都在等待他们的汉堡准备好后才离开柜台, 因为8名收银员都会在下一份订单前马上准备好汉堡.

然后, 终于轮到你了, 你为你的恋人和你订购了两个非常精美的汉堡. 你付钱了.

收银员去厨房, 你站在柜台前等待, 这样就不会有人在你之前抢走你的汉堡, 因为没有轮流的号码.

当你和你的恋人忙于不让任何人出现在你面前, 并且在他们到来的时候拿走你的汉堡时, 你无法关注到其他事情. 这是同步的工作, 你被迫与服务员/厨师同步, 你在此必须等待, 在收银员/厨师完成汉堡并将它们交给你的确切时间到达之前一直等待, 否则其他人可能会拿走它们.

你经过长时间等待, 收银员/厨师终于带着汉堡回到了柜台.

然后你拿着汉堡到桌子上, 仅仅是吃了它们就结束了.

没有太多的时间去关注其他事情, 因为大部分时间都在柜台前等待了. 在这个并行汉堡的场景中, 你是一个计算机程序且有两个处理器(你和你的恋人), 都在等待, 并投入他们的注意力在柜台上等待了很长一段时间.
这家快餐店有8个处理器(收银员/厨师). 而并发汉堡店可能只有2个(一个收银员和一个厨师). 但最终的体验仍然不时最好的.
一种更"贴近生活"的例子, 想象一家银行. 直到最近, 大多数银行都有多个出纳员, 还有一条尝尝排队队伍. 所有收银员都是一个接一个的在客户面前做完所有的工作. 你必须经过较长时间的排队, 否则你就没机会了.
# 汉堡结论
在"你与恋人一起吃汉堡"的这个场景中, 因为有很多人在等待, 使用并发系统更有意义. 大多数Web应用都是这样的. 你的服务器正在等待很多用户通过他们不太好的网络发送来的请求. 然后再次等待响应回来. 这个等待是以微秒为单位测量的, 但总的来说, 最后还是等待很久. 这就是为什么使用异步对于Web API很有意义的原因. 这种异步机制正式NodeJS收到欢迎的原因(尽管NodeJS不是并行的), 以及Go作为编程语言的优势所在.
这与FastAPI的性能水平相同. 你可以同时拥有并行性和异步性, 你可以获得比大多数经过测试的NodeJS框架更高的性能, 并且与Go不相上下, Go是一种更接近于C的编译语言(全部归功于Starlette).
# 并发比并行好吗?
不! 这不是上面故事的本意.
并发不同于并行. 而是在需要大量等待的特定场景下效果更好. 因此, 在Web应用程序开发中, 它通常比并行要好得多, 但这并不意味着全部. 因此, 为了平衡这一点, 想象一下下面的短片故事.
你必须打扫一个又打又脏的房子.
是的, 这就是完整的故事. 在任何地方, 都不需要等待, 只需要在房子的多个地方做着很多工作. 你可以像汉堡的例子那样轮流执行, 先是客厅, 然后是厨房, 但因为你不需要等待, 对于任何事情都是清洁, 清洁, 还是清洁, 轮流不会影响任何事情. 无论是否轮流执行(并发), 都需要相同的时间来完成, 而你也会完成相同的工作量. 但在这种情况下, 如果你能带上8名前收银员/厨师, 现在是清洁工一起清扫, 他们中的每一个人(加上你)都能占据房子的一个区域来清扫, 你就可以在额外的帮助下更快地完成所有工作. 在这个场景中, 每个清洁工(包括你)都将是一个处理器, 完成这个工作的一部分. 由于大多数执行时间是由实际工作(而不是等待)占用的, 并且计算机中的工作是由CPU完成的, 所以他们称这些问题为"CPU密集型".
CPU密集型操作的常见示例是需要复杂的数学处理:
- 音频或图像处理
- 计算机视觉: 一副图像由数百万像素组成, 处理通常需要同时对这些像素进行计算
- 机器学习: 它通常需要大量的"矩阵"和"向量"的乘法. 想象一个包含数字的巨大电子表格, 并同时将所有数字相乘
- 深度学习: 这是机器学习的一个子领域, 同样适用. 只是没有一个数字的电子表格可以相乘, 而是一个庞大的数字集合, 在很多情况下, 你需要使用一个特俗的处理器来构建和使用这些模型.
# 并发+并行: Web+机器学习
使用FastAPI, 你可以利用Web开发中常见的并发机制的优势(NodeJS的主要吸引力). 并且, 你也可以利用并行和多进程(让多个进程并行运行)的优点来处理与机器学习系统中类似的CPU密集型工作. 这一点, 在加上Python是数据科学, 机器学习(尤其是深度学习)的主要语言这一简单事实, 使得FastAPI与数据科学/机器学习Web API和应用程序(以及其他许多应用程序)非常匹配.
# async 和 await
现代版本的Python有一种非常直观的方式来定义异步代码, 这使它看起来就像正常的"顺序"代码, 并在适当的时候"等待". 当有一个操作需要等待才能给出结果, 且支持这个新的Python特性时, 可以编写如下代码: burgers = await get_burgers(2), 这里的关键是await, 它告诉Python必须等待get_burgers(2)完成它的工作, 然后将结果存储在burgers中. 这样, Python就会知道此时它可以去做其他事情(比如接收另一个请求).
要使await工作, 它必须位于支持这种异步机制的函数内. 因此, 只需使用async def声明它:
async def get_burgers(number: int):
# Do some asynchronous stuff to create the burgers
return burgers
2
3
...而不是def:
# This is not asynchronous
def get_sequential_burgers(number: int):
# Do some sequential stuff to create the burgers
return burgers
2
3
4
使用async def, Python就知道在该函数中, 它将遇上await, 并且它可以"暂停"执行该函数, 直至执行其他操作后回来. 当你想调用一个async def函数时, 你必须"等待"它. 因此, 这不会起作用:
# This won't work, because get_burgers was defined with: async def
burgers = get_burgers(2)
2
因此, 如果你使用的库告诉你可以使用await调用它, 则需要使用async def创建路径操作函数, 如:
@app.get('/burgers')
async def read_burgers():
burgers = await get_burgers(2)
return burgers
2
3
4
# 更多技术细节
你可能已经注意到, await只能在async def定义的函数内部使用. 但与此同时, 必须"等待"通过async def定义的函数. 因此, 带async def的函数也只能在async def定义的函数内部调用. 那么, 这关于先有鸡还是先有蛋的问题, 如何调用第一个async函数?
如果你使用FastAPI, 你不必担心这一点, 因为"第一个"函数将是你的路径操作函数, FastAPI将知道如何做正确的事情. 但如果你想在没有FastAPI的情况下使用async / await, 则可以这样做.
# 编写自己的异步代码
Starlette(和FastAPI)是基于AnyIO实现的, 这使得它们可以兼容Python的标准库asyncio和Trio. 特别是, 你可以直接使用AnyIO来处理高级的并发用例, 这些用例需要在自己的代码中使用更高级的模式. 即使你没有使用FastAPI, 你也可以使用AnyIO编写自己的异步程序, 使其拥有较高的兼容性并获得一些好处(例如, 结构化并发). 作者基于AnyIO新建了一个库, 作为一个轻量级的封装层, 用来优化类型注解, 同时提供了更好的自动补全, 内联错误提示等功能. 这个库还附带了一个友好的入门指南和教程, 能帮助理解并编写自己的异步代码: Asyncer. 如果有结合使用异步代码和常规(阻塞/同步)代码的需求, 这个库会特别有用.
# 其他形式的异步代码
这种使用async和await的风格在语言中相对较新. 但它使处理异步代码变得容易很多. 这种相同的语法(或几乎相同)最近也包含在现代版本的JavaScript中(在浏览器和NodeJS中). 但在此之前, 处理异步代码非常复杂和困难. 在以前的版本的Python, 你可以使用多线程或者Gevent. 但代码的理解, 调试和思考都要复杂许多. 在以前版本的NodeJS/浏览器JavaScript中, 你会使用"回调", 因此也可能导致回调地狱.
# 协程
协程只是async def函数返回的一个非常奇特的东西的称呼. Python知道它有点像一个函数, 它可以启动, 也会在某个时刻结束, 而且它可能会在内部暂停, 只要内部有一个await. 通过使用async和await的异步代码的所有功能大多数被概括为"协程". 它可以与Go的主要关键特性"Goroutines"相媲美.
# 结论
Python的现代版本可以通过使用
async和await语法创建协程, 并用于支持异步代码.
所有这些使得FastAPI(通过Starlette)如此强大, 也是它拥有如此令人印象深刻的性能的原因.
# 非常技术性的细节
# 路径操作函数
当使用def而不是async def来声明一个路径操作函数时, 它运行在外部的线程池中并等待其结果, 而不是直接调用(因为它会阻塞服务器).
如果你使用过另一个不以上述方式工作的异步框架, 并且你习惯于用普通的def定义普通的仅计算路径操作函数, 以获得微小的性能增益(大约100纳秒), 请注意, 在FastAPI中, 效果将完全相反. 在这些情况下, 最好使用async def, 除非路径操作函数内使用执行阻塞I/O的代码.
在这两种情况下, 与你之前的框架相比, FastAPI可能仍然很快.
# 依赖
这同样适用于依赖, 如果一个依赖是标准的def函数而不是async def, 它将被运行在外部线程池中.
# 子依赖
你可以拥有多个相互依赖的依赖以及子依赖(作为函数的参数), 它们中的一些可能是通过async def声明, 也可能是通过def声明. 它们仍然可以正常工作, 这些通过def声明的函数将会在外部线程中调用(来自线程池), 而不是"被等待".
# 其他函数
你可直接调用通过def或async def创建的任何其他函数, FastAPI不会影响你调用它们的方式. 这与FastAPI为你调用路径操作函数和依赖项的逻辑相反. 如果你的函数是通过def声明的, 它将被直接调用(在代码中编写的地方), 而不会在线程池中, 如果这个函数通过async def声明, 当在代码中调用时, 你就应该用await等待函数的结果.
# 环境变量
环境变量(也称为"env var")是一个独立于Python代码之外的变量, 它存在于操作系统重, 可以被你的Python代码(或其他程序)读取. 环境变量对于处理应用程序设置, 作为Python安装的一部分等方面非常有用.
# 创建和使用环境变量
你在shell(终端)中就可以创建和使用环境变量, 并不需要用到Python:
# 可以使用以下命令创建一个名为 MY_NAME 的环境变量
export MY_NAME="Wade Wilson"
# 可以在其他程序中使用它
echo "Hello $MY_NAME"
# 输出 Hello Wade Wilson
2
3
4
5
6
# 在Python中读取环境变量
也可以在Python之外的终端中创建环境变量(或使用任何其他方法), 然后在Python中读取它们. 例如, 可以创建一个名为main.py的文件, 其中包含以下内容:
import os
# 第二个参数是os.getenv()的默认返回值
# 如果没有提供, 默认值为None, 这里"World"作为默认值
name = os.getenv("MY_NAME", "World")
print(f"Hello {name} from Python")
2
3
4
5
6
由于环境变量可以在代码之外设置, 但可以被代码读取, 并且不必与其他文件一起存储(提交到代码仓库), 因此通常用于配置或设置. 你还可以为特定的程序调用创建特定的环境变量, 该环境变量仅对该程序可用, 且仅在其运行期间有效. 要实现这一点, 只需要在同一行, 程序本身之前创建它:
# 在这个程序调用的同一行中创建一个名为 MY_NAME 的环境变量
MY_NAME="Wade Wilson" python main.py
# 现在就可以读取到环境变量了
# 输出: Hello Wade Wilson from Python
# 在此之后这个环境变量将不会依然存在
python main.py
# 输出: Hello World from Python
2
3
4
5
6
7
# 类型和验证
这些环境变量只能处理文本字符串, 因为它们是处于Python范畴之外的, 必须与其他程序和操作系统的其余部分兼容(甚至与不同的操作系统兼容, 如Linux, Windows, macOS). 这意味着从环境变量中读取的任何值在Python中都将是一个str, 任何类型转换或验证都必须在代码中完成.
# PATH 环境变量
有一个特殊的环境变量称为PATH, 操作系统(Linux, macOS, Windows)用它来查找要运行的程序. PATH变量的值是一个长字符串, 由Linux和macOS上的冒号:分割的目录组成, 而在Windows上则是由分号;分隔的. 例如, PATH环境变量可能如下所示:
# Linux, macOS
/usr/local/bin:/usr/bin:/bin:/usr/sbin:/sbin
# Windows
C:\Program Files\Python312\Scripts;C:\Program Files\Python312;C:\Windows\System32
2
3
4
这意味着Linux, macOS系统应该在以下目录中查找程序:
/usr/local/bin/usr/bin/bin/usr/sbin/sbin
Windows系统应该在以下目录中查找程序:
C:\Program Files\Python312\ScriptsC:\Program Files\Python312C:\Windows\System32
当你在终端中输入一个命令时, 操作系统会在PATH环境变量中列出的每个目录中查找程序. 例如, 当在终端中输入python时, 操作系统会在该列表中的第一个目录中查找名为python的程序. 如果找到了, 那么操作系统将使用它; 否则, 操作系统会继续在其他目录中查找.
# 安装Python和更新PATH
安装Python时, 可能会询问你是否要更新PATH环境变量.
- Linux, macOS
假设你安装Python并最终将其安装在了目录/opt/custompython/bin中. 如果你同意更新PATH环境变量, 那么安装程序将会把/opt/custompython/bin添加到PATH环境变量中. 大概是这样:
/usr/local/bin:/usr/bin:/bin:/usr/sbin:/sbin:/opt/custompython/bin
如此, 当在终端中输入python时, 系统会在/opt/custompython/bin中找到Python程序(最后一个目录)并使用它.
# 结论
在许多情况下, 环境变量的用途和适用性并不是很明显. 但是在开发过程中, 它们会在许多不同的场景中出现, 因此了解它们是很有必要的.
# 虚拟环境
当你在Python工程中工作时, 可能会有必要用到一个虚拟环境(或类似的机制)来隔离每个工程安装的包.
虚拟环境和环境变量是不同的. 环境变量是系统中的一个变量, 可以被程序使用. 虚拟环境是一个包含一些文件的目录.
# 创建一个工程
首先, 为你对工程创建一个目录. 通常会在主目录下创建一个名为code的目录. 在这个目录下, 再为每个工程创建一个目录.
# 进入主目录
cd
# 创建一个用于存放所有代码工程的目录
mkdir code
# 进入 code 目录
cd code
# 创建一个用于存放这个工程的目录
mkdir awesome-project
# 进入这个工程的目录
cd awesome-project
2
3
4
5
6
7
8
9
10
# 创建一个虚拟环境
在开始一个Python工程的第一时间, 在你的工程内部创建一个虚拟环境.
# 可以使用Python自带的 venv 模块来创建一个虚拟环境
python -m venv .venv
# python: 使用名为 python 的程序
# -m: 以脚本的方式调用一个模块, 将告诉它接下来使用哪个模块
# venv: 使用名为 venv 的模块, 这个模块通常随Python一起安装
# .venv: 在新目录 .venv 中创建虚拟环境, 这个命令会在一个名为 .venv 的目录中创建一个新的虚拟环境. 你可以在不同的目录下创建虚拟目录, 但通常我们会把它命名为 .venv
2
3
4
5
6
如果安装了uv, 可以使用它来创建一个虚拟环境.
uv venv
# 默认情况, uv 会在一个名为 .venv 的目录中创建一个虚拟环境. 但你可以通过传递一个额外的参数来自定义它, 指定目录的名称. 你可以在不同的目录下创建虚拟环境, 但通常我们会把它命名为 .venv
2
3
# 激活虚拟环境
激活新的虚拟环境来确保你运行的任何Python命令或安装的包都能使用到它. 每次开始一个新的终端会话来工作在这个工程时, 你都需要执行这个操作.
source .venv/bin/activate
# 每次你在这个环境中安装一个新包时, 都需要重新激活这个环境. 这么做确保了当你使用一个由这个包安装的终端(CLI)程序时, 你使用的是你的虚拟环境中的程序, 而不是全局安装, 可能版本不同的程序.
2
3
# 检查虚拟环境是否激活
检查虚拟环境是否激活(前面的命令是否生效). 这是可选的, 但这是一个很好的方法, 可以检查一切是否按预期工作, 以及你是否使用了你打算使用的虚拟环境.
which python
# /home/user/code/awesome-project/.venv/bin/python
2
3
如果它显示了在你工程(在这个例子中是awesome-project)的.venv/bin/python中的python二进制文件, 那么它就生效了.
# 升级 pip
如果你使用 uv 来安装内容, 而不是 pip, 那么你就不需要升级 pip.
如果你使用 pip 来安装包(它是Python的默认组件), 你应该将它升级到最新版本. 在安装包时出现的许多奇怪的错误都可以通过先升级pip来解决. 通常只需要在创建虚拟环境后执行一次这个操作. 确保虚拟环境是激活的, 然后运行:
python -m pip install --upgrade pip
# 添加 .gitignore
如果你使用git, 添加一个.gitignore文件来排除你的.venv中的所有内容.
echo "*" > .venv/.gitignore
# echo "*": 将在终端中打印文本*(接下来的部分会对这个操作进行一些修改)
# >: 将左边的命令打印到终端的任何内容实际上都不会被打印, 而是会被写入到右边的文件中
# .gitignore: 被写入文本的文件的名称
2
3
4
# 安装软件包
在激活虚拟环境后, 可以在其中安装软件包.
# 直接安装包
如果你急于安装, 不想使用文件来声明工程的软件包依赖, 你可以直接安装它们. 将程序所需的软件包机器版本放在文件中(例如requirements.txt或pyproject.toml)是个非常好的注意.
pip install "fastapi[standard]"
# 从 requirements.txt 安装
如果有一个requirements.txt文件, 可以使用它来安装其中的软件包.
pip install -r requirements.txt
一个包含一些软件包的requirements.txt文件看起来应该是这样的:
fastapi[standard]==0.113.0
pydantic==2.8.0
2
# 运行程序
在激活虚拟环境后, 可以运行程序, 它将使用虚拟环境中的Python和你在其中安装的软件包: python main.py
# 配置编辑器
还需要配置你的编辑器使用你创建的虚拟环境, 以便你可以获得自动补全和内联错误提示.
# 推出虚拟环境
deactivate
# 开始工作
# 为什么要使用虚拟环境
需要安装Python才能使用FastAPI. 之后, 需要安装FastAPI和需要使用的其他软件包. 然而, 如果直接使用pip, 软件包将被安装在全局Python环境中.
# 存在的问题
有些时候, 可能会编写许多不同的程序, 这些程序依赖于不同的软件包; 你所做的一些功能也会依赖于同一软件包的不同版本. 如果你将软件包安装在全局环境中而不是在本地虚拟环境中, 你将不得不面临选择安装哪个版本的问题.
# 软件包安装在哪里
当安装Python时, 它会在计算机上创建一些目录, 并在这些目录中放一些文件. 其中一些目录负责存放你安装的所有软件包. pip install "fastapi[standard]", 这将会从PyPI下载一个压缩文件, 其中包含FastAPI代码. 它还会下载FastAPI依赖的其他软件包的文件. 然后它会解压所有这些文件, 并将它们放在你的计算机上的一个目录中. 默认情况下, 它会将下载并解压的这些文件放在Python安装的目录中, 这就是全局环境.
# 什么是虚拟环境
解决软件包都安装在全局环境中的问题的方法是为每个工程使用一个虚拟环境. 虚拟环境是一个目录, 与全局环境非常相似, 可以在其中专为某个工程安装软件包. 这样, 每个工程都会有自己的虚拟环境(.venv目录), 其中包含自己的软件包.
# 激活虚拟环境意味着什么
当激活了一个虚拟环境, 这个命令会创建或修改一些环境变量, 这些环境变量将在接下来的命令中可用, 其中之一是PATH变量. 激活虚拟环境会将其路径.venv/bin(Linux, macOS)或.venv\Scripts(Windows)添加到PATH环境变量中. 一个重要的细节是, 虚拟环境路径会被放在PATH变量的开头, 系统会在找到任何其他可用的Python之前找到它. 这样, 当运行python时, 他会使用虚拟环境中的Python, 而不是其他python.
# 检查虚拟环境
which python
这意味着将使用的python程序是在虚拟环境中的那个. 在Linux和macOS中使用which, 在Windows PowerShell中使用Get-Command. 这个命令的工作方式是, 它会在PATH环境变量中查找, 按顺序逐个路径查找名为python的程序. 一旦找到, 它会显示该程序的路径.
# 为什么要停用虚拟环境
为切换环境
# 替代方案
uv