
深入理解高并发编程
# 线程与线程池
# 线程与多线程
- 线程:在操作系统重,线程是比进程更小的能够独立运行的基本单位。同时,它也是CPU调度的基本单位。线程本身基本上不拥有系统资源,只是拥有一些运行时需要用到的系统资源,例如程序计数器,寄存器和栈等。一个进程中的所有线程可以共享进程中的所有资源。
- 多线程:多线程可以理解为在同一个程序中能够同时运行多个不同的线程来执行不同的任务,这些线程可以同时利用CPU的多个核心运行。多线程编程能够最大限度的利用CPU的资源。如果某一个线程的处理不需要占用CPU资源时(例如IO线程),可以使当前线程让出CPU资源来让其他线程能够获取到CPU资源,进而能够执行其他线程对应的任务,达到最大化利用CPU资源的目的。
# 线程的实现方式
在Java中,实现线程的方式大体上分为三种,通过继承Thread类、实现Runnable接口、实现Callable接口。示例如下:
- 继承
Thread类
public class ThreadTest extends Thread {
@Override
public void run() {
// TODO 在此写在线程中执行的业务逻辑
}
}
2
3
4
5
6
- 实现
Runnable接口的代码
public class RunnableTest implements Runnable {
@Override
public void run() {
// TODO 在此写在线程中执行的业务逻辑
}
}
2
3
4
5
6
- 实现
Callable接口
import java.util.concurrent.Callable;
public class CallableTest implements Callable<String> {
@Override
public String call() throws Exception {
// TODO 在此写在线程中执行的业务逻辑
return null;
}
}
2
3
4
5
6
7
8
9
# 线程的生命周期
- 生命周期
一个线程从创建,到最终消亡,需要经历多种不同的状态,而这些不同的线程状态,由始至终也构成了线程生命周期的不同阶段,线程的生命周期可以总结为下图:
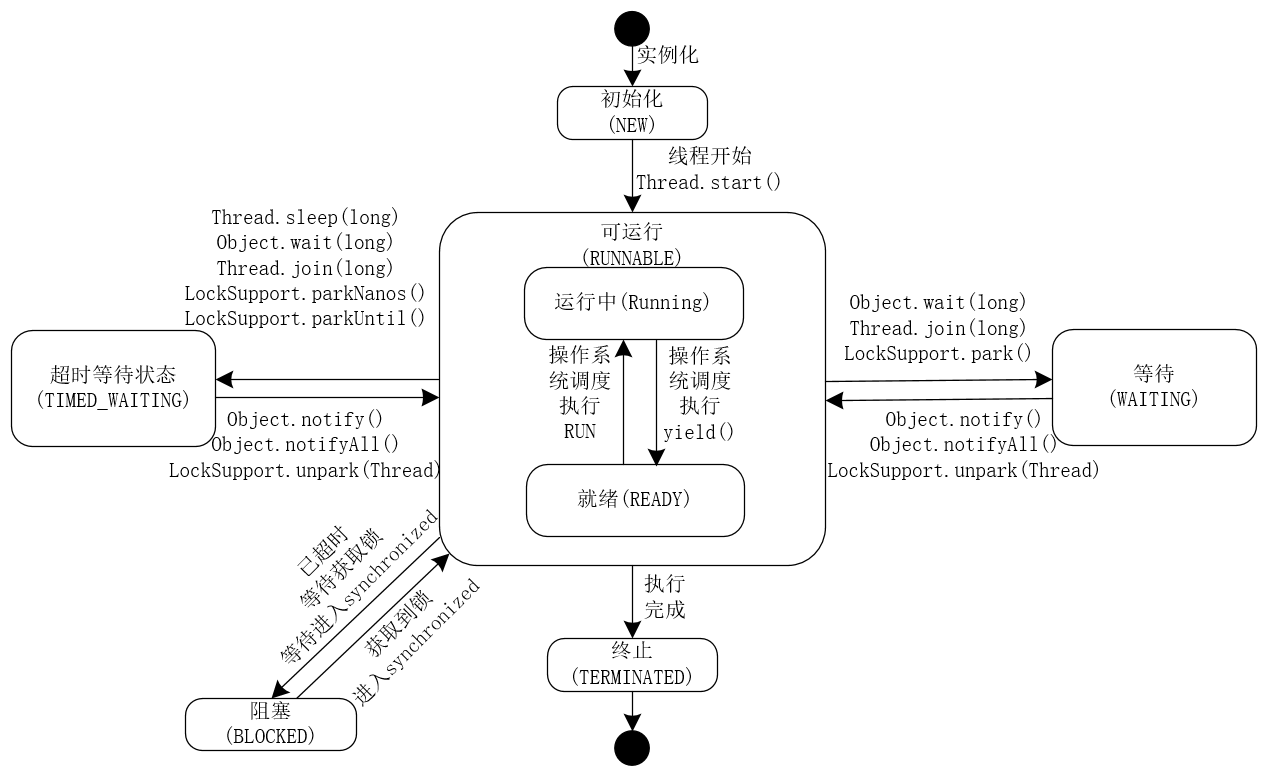
其中,几个重要的状态如下所示:
- NEW:初始状态,线程被构建,但是还没有调用
start()方法。 - RUNNABLE: 可运行状态,可运行状态可以包括,运行中状态和就绪状态。
- BLOCKED: 阻塞状态,处于这个状态的线程需要等待其他线程释放锁或者等待进入
synchronized。 - WAITING: 表示等待状态,处于该状态的线程需要等待其他线程对其进行通知或中断等操作,进而进入下一个状态。
- TIME_WAITING: 超时等待状态,可以在一定的时间自行返回。
- TERMINATED: 终止状态,当前线程执行完毕。
- 代码示例
为了更好的理解线程的生命周期,以及生命周期中的各个状态,接下来使用代码示例来输出线程的每个状态信息。
- WaitingTime
创建WaitingTime类,在while(true)循环中调用TimeUnit.SECONDS.sleep(long)方法来验证线程的TIMED_WAITING状态,代码如下:
package com.ainsn.dandelion.thread;
import java.util.concurrent.TimeUnit;
/**
* 线程不断休眠
*
* @author sunyy
* @version 0.0.1
* @since 2023.3.13
*/
public class WaitingTime implements Runnable {
@Override
public void run() {
while (true) {
waitSecond(200);
}
}
/**
* 线程等待seconds秒
*
* @param seconds
*/
public static final void waitSecond(long seconds) {
try {
TimeUnit.SECONDS.sleep(seconds);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
- WaitingState
创建WaitingState类,此线程会在一个while(true)循环中,获取当前类Class对象的synchronized锁,也就是说,这个类无论创建多少个实例,synchronized锁都是同一个,并且线程会处于等待状态。接下来,在synchronized中使用当前类的Class对象的wait()方法,来验证线程的WAITING状态,代码如下所示:
package com.ainsn.dandelion.thread;
/**
* 线程在waiting上等待
*
* @author sunyy
* @version 0.0.1
* @since 2023.3.13
*/
public class WaitingState implements Runnable {
@Override
public void run() {
while (true) {
synchronized (WaitingState.class) {
try {
WaitingState.class.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
- BlockedThread
BlockedThread主要是在synchronized代码块中的while(true)循环中调用TimeUnit.SECONDS.sleep(long)方法来验证线程的BLOCKED状态。当启动两个BlockedThread线程时,首先启动的线程会处于TIMED_WAITING状态,后启动的线程会处于BLOCKED状态。代码如下:
package com.ainsn.dandelion.thread;
/**
* 加锁后不再释放锁
*
* @author sunyy
* @version 0.0.1
* @since 2023.3.13
*/
public class BlockedThread implements Runnable {
@Override
public void run() {
synchronized (BlockedThread.class) {
while (true) {
WaitingTime.waitSecond(100);
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
- ThreadState
启动各个线程,验证各个线程输出的状态,代码如下所示:
package com.ainsn.dandelion.thread;
/**
* 线程的各种状态,测试线程的生命周期
*
* @author sunyy
* @version 0.0.1
* @since 2023.3.13
*/
public class ThreadState {
public static void main(String[] args) {
new Thread(new WaitingTime(), "WaitingTimeThread").start();
new Thread(new WaitingState(), "WaitingStateThread").start();
// BlockedThread-01线程会抢到锁,BlockedThread-02线程会阻塞
new Thread(new BlockedThread(), "BlockedThread-01").start();
new Thread(new BlockedThread(), "BlockedThread-02").start();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
运行ThreadState类,可以看到,未输出任何结果信息,可以在命令行输入jps命令来查看运行的Java进程。

可以看到ThreadState进程的进程号为34812,接下来,输入jstack 34812来查看ThreadState进程栈信息,如图:
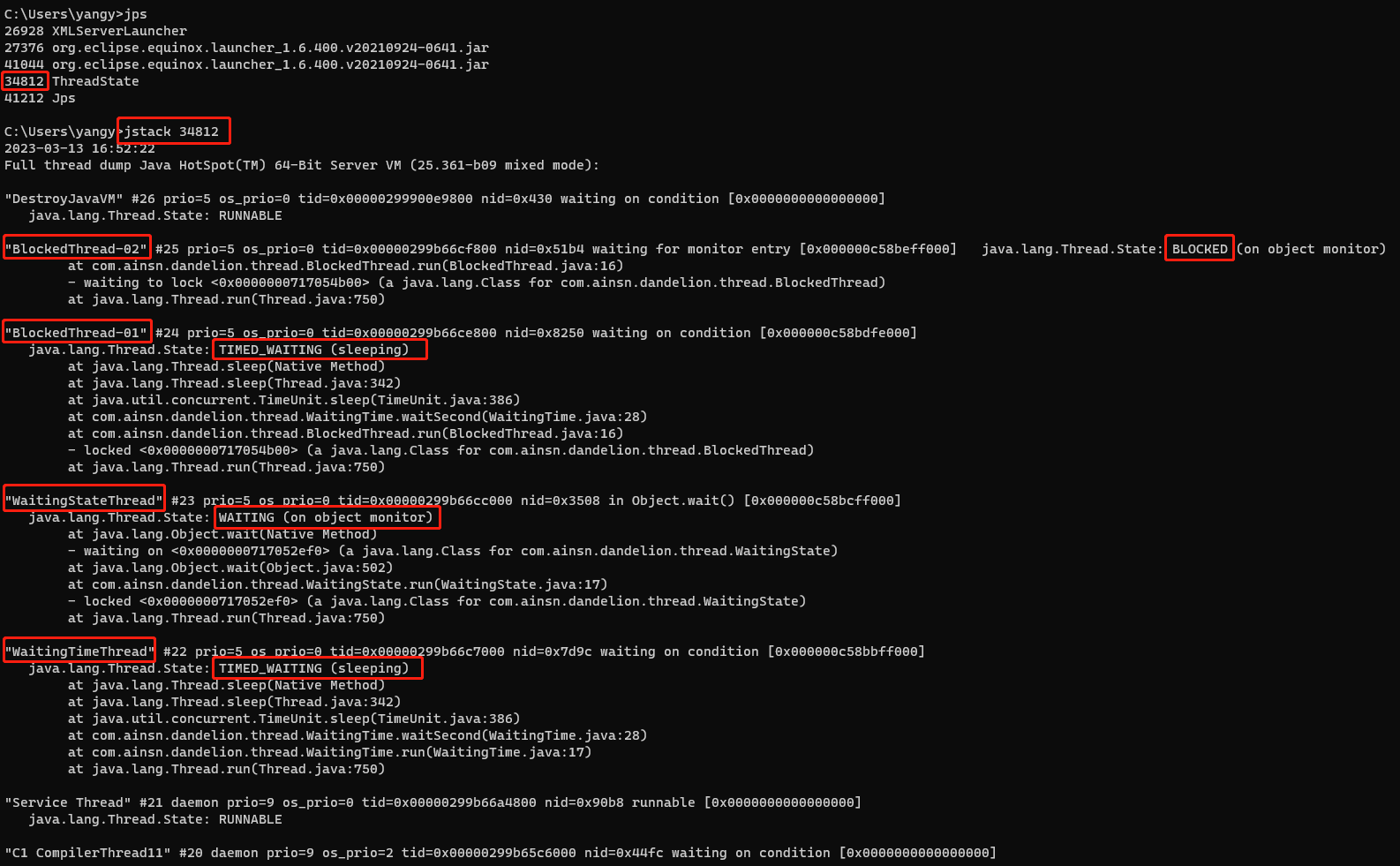
由以上输出的信息可以看出:名称为WaitingTimeThread的线程处于TIMED_WAITING状态;名称为WaitingStateThread的线程处于WAITING状态;名称为BlockedThread-01的线程处于TIMED_WAITING状态;名称为BlockedThread-02的线程处于BLOCKED状态。
注意
使用jps结合jstack命令可以分析线上生产环境的Java进程的异常信息。
# 线程的执行顺序
# 线程的执行顺序是不确定的
调用Thread的start()方法启动线程时,线程的执行顺序是不确定的,也就是说,在同一个方法中,连续创建多个线程后,调用线程的start()方法的顺序并不能决定线程的执行顺序。
例如,如下所示:
package com.ainsn.dandelion.thread;
/**
* 线程的顺序,直接调用Thread.start()方法执行不能确保线程的执行顺序
*
* @author sunyy
* @version 0.0.1
* @since 2023.3.13
*/
public class ThreadSort01 {
public static void main(String[] args) {
Thread thread1 = new Thread(() -> {
System.out.println("thread1");
});
Thread thread2 = new Thread(() -> {
System.out.println("thread2");
});
Thread thread3 = new Thread(() -> {
System.out.println("thread3");
});
thread1.start();
thread2.start();
thread3.start();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
在ThreadSort01类中分别创建了三个不同的线程,thread1、thread2和thread3,接下来,在程序中按照顺序分别调用thread1.start()、thread2.start()和thread3.start()方法分别启动三个不同的线程。那么,线程的执行顺序是否按照thread1、thread2和thread3的顺序执行呢?运行ThreadSort01的main方法,结果如下:

注意
每个人运行的情况可能都不一样,可以看到,每次运行程序,线程的执行顺序可能不同。线程的启动顺序并不能决定线程的执行顺序。
# 如何确保线程的执行顺序
- 确保线程执行顺序的简单示例
在实际业务场景中,有时,后启动的线程可能需要依赖先启动的线程执行完成才能正确的执行线程中的逻辑。此时,就需要确保线程的执行顺序。那么如何确保线程的执行顺序呢?
可以使用Thread类中的join()方法来确保线程的执行顺序。例如,下面的测试代码:
package com.ainsn.dandelion.thread;
/**
* 线程的顺序,Thread.join()方法能够确保线程的执行顺序
*
* @author sunyy
* @version 0.0.1
* @since 2023.3.13
*/
public class ThreadSort02 {
public static void main(String[] args) throws InterruptedException {
Thread thread1 = new Thread(() -> {
System.out.println("thread1");
});
Thread thread2 = new Thread(() -> {
System.out.println("thread2");
});
Thread thread3 = new Thread(() -> {
System.out.println("thread3");
});
thread1.start();
// 实际上让主线程等待子线程执行完成
thread1.join();
thread2.start();
thread2.join();
thread3.start();
thread3.join();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
可以看到,ThreadSort02类比ThreadSort01类,在每个线程的启动方法下面添加了调用线程的join()方法。此时,运行ThreadSort02类,结果如下:
thread1
thread2
thread3
2
3
再次运行,后续无论运行多少次,结果都如下:
thread1
thread2
thread3
2
3
join方法如何确保线程的执行顺序
既然Thread类的join方法能够确保线程的执行顺序,下面我们就来看看Thread类的join()方法到底是什么?
进入Thread的join()方法,如下:
public final void join() throws InterruptedException {
join(0);
}
2
3
可以看到join()方法调用同类中的一个有参join()方法,并传递参数0。继续跟进:
public final synchronized void join(long millis) throws InterruptedException {
long base = System.currentTimeMillis();
long now = 0;
if (millis < 0) {
throw new IllegalArgumentException("timeout value is negative");
}
if (millis == 0) {
while (isAlive()) {
wait(0);
}
} else {
while (isAlive()) {
long delay = millis - now;
if (delay <= 0) {
break;
}
wait(delay);
now = System.currentTimeMillis() - base;
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
可以看到,有一个long类型参数的join()方法使用了synchronized修饰,说明这个方法同一时刻只能被一个实例或者方法调用。由于,传递的参数为0,所以,程序会进入如下代码逻辑:
if (millis == 0) {
while (isAlive()) {
wait(0);
}
}
2
3
4
5
首先,在代码中以while循环的方式来判断当前线程是否已经启动处于活跃状态,如果已经启动处于活跃状态,则调用同类中的wait()方法,并传递参数0。继续跟进wait()方法,如下:
public final native void wait(long timeout) throws InterruptedException;
可以看到,wait()方法是一个本地方法,通过JNI的方式调用JDK底层的方法来使线程等待执行完成。
注意
需要注意的是,调用线程的wait()方法时,会使主线程处于等待状态,等待子线程执行完成后再次向下执行。也就是,在ThreadSort02类的main()方法中,调用子线程的join()方法,会阻塞main()方法的执行,当子线程执行完成后,main()方法会继续向下执行,启动第二个子线程,并执行子线程的业务逻辑,以此类推。
# Java中的Callable和Future
在Java的多线程编程中,除了Thread类和Runnable接口外,不得不说的就是Callable接口和Future接口了。使用继承Thread类或者实现Runnable接口的线程,无法返回最终的执行结果数据,只能等待线程执行完成。此时,如果想要获取线程执行后的返回结果,那么,Callable和Future就派上用场了。
# Callable接口
Callable接口介绍
Callable接口是JDK1.5新增的泛型接口,在JDK1.8中,被声明为函数式接口,如下:
@FunctionalInterface
public interface Callable<V> {
V call() throws Exception;
}
2
3
4
在JDK1.8中只声明有一个方法的接口为函数式接口,函数式接口可以使用@FunctionalInterface注解修饰,也可以不使用@FunctionalInterface注解修饰。只要一个接口中只包含有一个方法,那么,这个接口就是函数式接口。
在JDK总,实现Callable接口的子类如下图
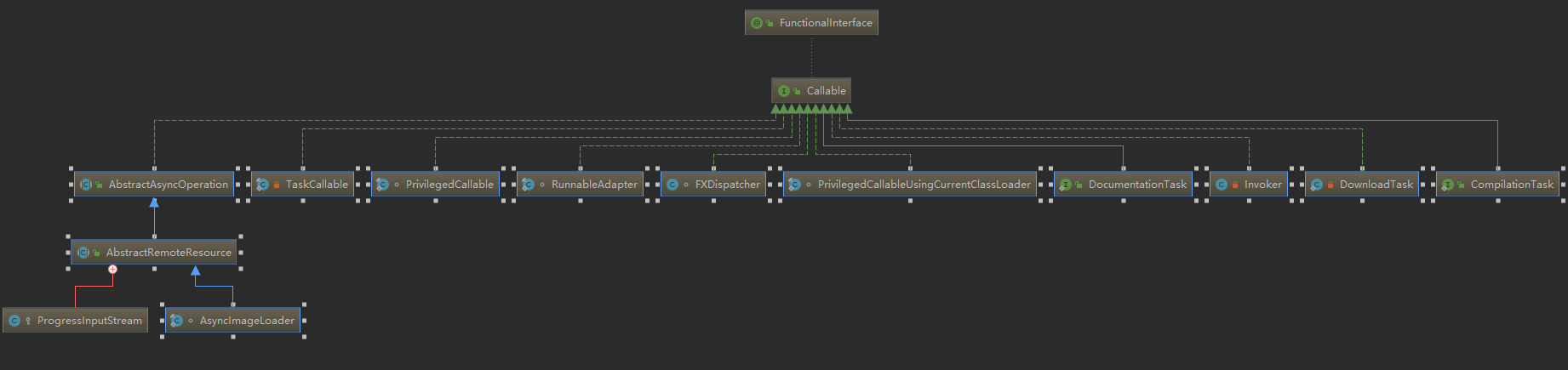
默认的子类层级关系图看不太清,可以通过IDEA右键Callable接口,选择Layout来指定Callable接口的实现类图的不同结构,如下:
这里,可以选择Organic Layout选项,选择后的Callable接口的子类结构如下:
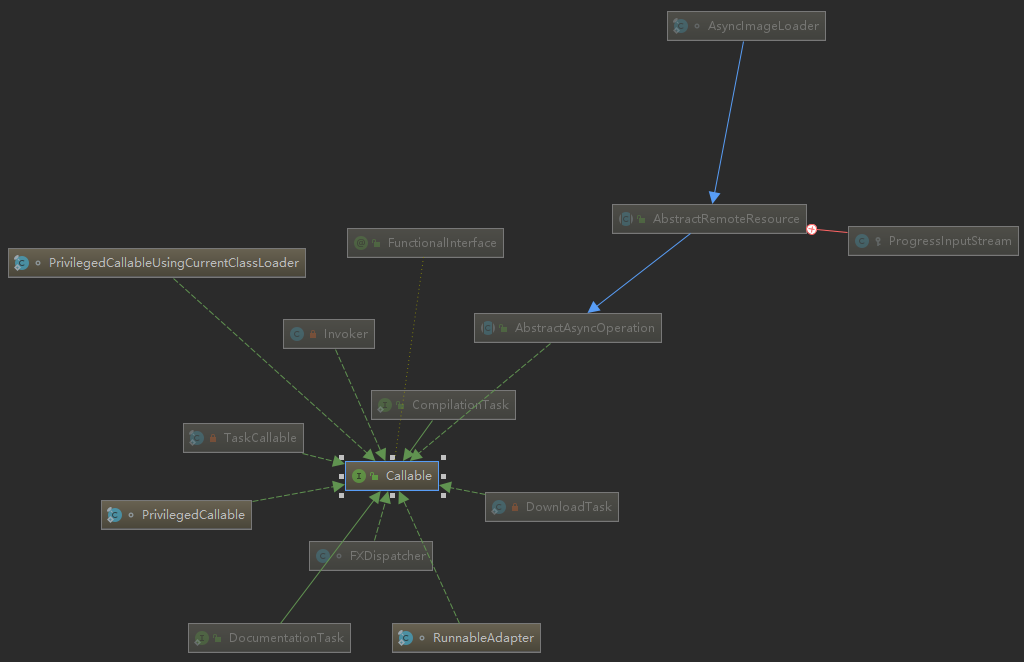
在实现Callable接口的子类中,有几个比较重要的类,如下:
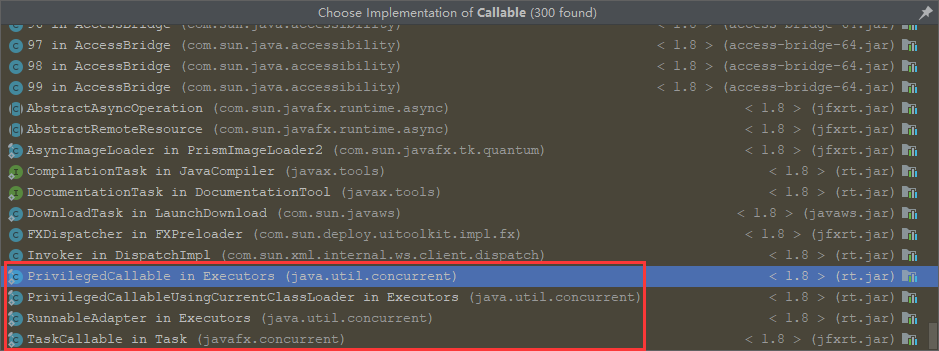
分别是:Executors类中的静态内部类:PrivilegedCallable、PrivilegedCallableUsingCurrentClassLoader、RunnableAdapter和Task类下的TaskCallable。
- 实现
Callable接口的重要类分析
接下来,分析的类主要有:PrivilegedCallable、PrivilegedCallableUsingCurrentClassLoader、RunnableAdapter和Task类下的TaskCallable。虽然这些类在实际工作中很少被直接用到,但了解并掌握这些类的实现有助于进一步理解Callable接口。
PrivilegedCallable
PrivilegedCallable类是Callable接口的一个特殊实现类,它表明Callable对象有某种特权来访问系统的某种资源,PrivilegedCallable类的源代码如下:
static final class PrivilegedCallable<T> implements Callable<T> {
private final Callable<T> task;
private final AccessControlContext acc;
PrivilegedCallable(Callable<T> task) {
this.task = task;
this.acc = AccessController.getContext();
}
public T call() throws Exception {
try {
return AccessController.doPrivileged(
new PrivilegedExceptionAction<T>() {
public T run() throws Exception {
return task.call();
}
},
acc
);
} catch (PrivilegedActionException e) {
throw e.getException();
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
从PrivilegedCallable类的源代码来看,可以将PrivilegedCallable看成是对Callable接口的封装,并且这个类也继承了Callable接口。在PrivilegedCallable类中有两个成员变量,分别是Callable接口的实例对象和AccessControlContext类的实例对象,如下:
private final Callable<T> task;
private final AccessControlContext acc;
2
其中,AccessControlContext类可以理解为一个具有系统资源访问决策的上下文类,通过这个类可以访问系统的特定资源。通过类的构造方法可以看出,在实例化AccessControlContext类的对象时,只需要传递Callable接口子类的对象即可。如下:
PrivilegedCallable(Callable<T> task) {
this.task = task;
this.acc = AccessController.getContext();
}
2
3
4
AccessControlContext类的对象是通过AccessController类的getContext()方法获取的,这里,查看AccessController类的getContext()方法,如下:
public static AccessControlContext getContext() {
AccessControlContext acc = getStackAccessControlContext();
if (acc == null) {
return new AccessControlContext(null, true);
} else {
return acc.optimize();
}
}
2
3
4
5
6
7
8
通过AccessController的getContext()方法可以看出,首先通过getStackAccessControlContext()方法来获取AccessControlContext对象实例。如果获取的AccessControlContext对象实例为空,则通过调用AccessControlContext类的构造方法实例化,否则,调用AccessControlContext对象实例的optimize()方法返回AccessControlContext对象实例。
private static native AccessControlContext getStackAccessControlContext();
getStackAccessControlContext()是个本地方法,方法的字面意思就是获取能够访问系统栈的决策上下文对象。
接下来,回到PrivilegedCallable类的call()方法,如下:
public T call() throws Exception {
try {
return AccessController.doPrivileged(
new PrivilegedExceptionAction<T>() {
public T run() throws Exception {
return task.call();
}
}, acc);
} catch (PrivilegedActionException e) {
throw e.getException();
}
}
2
3
4
5
6
7
8
9
10
11
12
通过调用AccessController.doPrivileged()方法,传递PrivilegedExceptionAction接口对象和AccessControlContext对象,并最终返回泛型的实例对象。
首先,看下AccessController.doPrivileged()方法,如下:
@CallerSensitive
public static native <T> T doPrivileged(PrivilegedExceptionAction<T> action, AccessControlContext context) throws PrivilegedActionException;
2
可以看到,又是一个本地方法。也就是说,最终的执行情况是将PrivilegedExceptionAction接口对象和AccessControlContext对象实例传递给这个本地方法执行。并且在PrivilegedExceptionAction接口对象的run()方法中调用Callable接口的call()方法来执行最终的业务逻辑,并且返回泛型对象。
PrivilegedCallableUsingCurrentClassLoader
此类表示为在已经建立的特定访问控制和当前的类加载器下运行的Callable类,源代码如下所示:
/**
* A callable that runs under established access control settings and
* current ClassLoader
*/
static final class PrivilegedCallableUsingCurrentClassLoader<T> implements Callable<T> {
private final Callable<T> task;
private final AccessControlContext acc;
private final ClassLoader ccl;
PrivilegedCallableUsingCurrentClassLoader(Callable<T> task) {
SecurityManager sm = System.getSecurityManager();
if (sm != null) {
sm.checkPermission(SecurityConstants.GET_CLASSLOADER_PERMISSION):
sm.checkPermission(new RuntimePermission("setContextClassLoader"));
}
this.task = task;
this.acc = AccessController.getContext();
this.ccl = Thread.currentThread().getContextClassLoader();
}
public T call() throws Exception {
try {
return AccessController.doPrivileged(new PrivilegedExceptionAction<T>() {
public T run() throws Exception {
Thread t = Thread.currentThread();
ClassLoader cl = t.getContextClassLoader();
if (ccl == cl) {
return task.call();
} else {
t.setContextClassLoader(ccl);
try {
return task.call();
} finally {
t.setContextClassLoader(cl);
}
}
}
}, acc);
} catch (PrivilegedActionException e) {
throw e.getException();
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
这个类理解起来比较简单,首先,在类中定义了三个成员变量,如下:
private final Callable<T> task;
private final AccessControlContext acc;
private final ClassLoader ccl;
2
3
接下来,通过构造方法注入Callable对象,在构造方法中,首先获取系统安全管理器对象实例,通过系统安全管理器对象实例检查是否具有获取ClassLoader和设置ContextClassLoader的权限,并在构造方法中为三个成员变量赋值,如下:
PrivilegedCallableUsingCurrentClassLoader(Callable<T> task) {
SecurityManager sm = System.getSecurityManager();
if (sm != null) {
sm.checkPermission(SecurityConstants.GET_CLASSLOADER_PERMISSION):
sm.checkPermission(new RuntimePermission("setContextClassLoader"));
}
this.task = task;
this.acc = AccessController.getContext();
this.ccl = Thread.currentThread().getContextClassLoader();
}
2
3
4
5
6
7
8
9
10
接下来,通过调用call()方法来执行具体的业务逻辑,如下:
public T call() throws Exception {
try {
return AccessController.doPrivileged(new PrivilegedExceptionAction<T>() {
public T run() throws Exception {
Thread t = Thread.currentThread();
ClassLoader cl = t.getContextClassLoader();
if (ccl == cl) {
return task.call();
} else {
t.setContextClassLoader(ccl);
try {
return task.call();
} finally {
t.setContextClassLoader(cl);
}
}
}
}, acc);
} catch (PrivilegedActionException e) {
throw e.getException();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
在call()方法中同样是通过调用AccessController类的本地方法doPrivileged,传递PrivilegedExceptionAction接口的实例对象和AccessControlContext类的对象实例。
具体执行逻辑为:在PrivilegedExceptionAction对象的run()方法中获取当前线程的ContextClassLoader对象,如果在构造方法中获取的ClassLoader对象与此处的ContextClassLoader对象是同一个对象(不止对象实例相同,而且内存地址也想通),则直接调用Callable对象的call()方法返回结果。否则,将PrivilegedExceptionAction对象的run()方法中的当前线程的ContextClassLoader设置为在构造方法中获取的类加载器对象,接下来,再调用Callable对象的call()方法返回结果。最终将当前线程的ContextClassLoader重置为之前的ContextClassLoader。
RunnableAdapter
RunnableAdapter类比较简单,给定运行的任务和结果,运行给定的任务并返回给定的结果,源代码如下:
/**
* A callable that runs given task and returns given result
*/
static final class RunnableAdapter<T> implements Callable<T> {
final Runnable task;
final T result;
RunnableAdapter(Runnable task, T result) {
this.task = task;
this.result = result;
}
public T call() {
task.run();
return result;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
TaskCallable
TaskCallable类是javax.concurrent.Task类的静态内部类,TaskCallable类主要是实现了Callable接口并且被定义为FutureTask的类,并且在这个类中允许我们拦截call()方法来更新task任务的状态,源代码如下:
private static final class TaskCallable<V> implements Callable<V> {
private Task<V> task;
private TaskCallable() {}
@Override
public V call() throws Exception {
task.started = true;
task.runLater(() -> {
task.setState(State.SCHEDULED);
task.setState(State.RUNNING);
});
try {
final V result = task.call();
if (!task.isCancelled()) {
task.runLater(() -> {
task.updateValue(result);
task.setState(State.SUCCEEDED);
});
return result;
} else {
return null;
}
} catch (final Throwable th) {
task.runLater(() -> {
task._setException(th);
task.setState(State.FAILED);
});
if (th instanceof Exception) {
throw (Exception) th;
} else {
throw new Exception(th);
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
从TaskCallable类的源代码可以看出,只定义了一个Task类型的成员变量。下面主要分析TaskCallable类的call()方法。
当程序的执行进入到call()方法时,首先将task对象的started属性设置为true,表示任务已经开始,并且将任务的状态依次设置为State.SCHEDULED和State.RUNNING,依次触发任务的调度事件和运行事件。如下:
task.started = true;
task.runLater(() -> {
task.setState(State.SCHEDULED);
task.setState(State.RUNNING);
});
2
3
4
5
接下来,在try代码块中执行Task对象的call()方法,返回泛型对象。如果任务没有被取消,则更新任务的缓存,将调用call()方法返回的泛型对象绑定到Task对象中的ObjectProperty对象中,其中,ObjectProperty在Task类中的定义如下:
private final ObjectProperty<V> value = new SimpleObjectProperty<>(this, "value");
接下来,将任务的状态设置为成功状态,如下:
try {
final V result = task.call();
if (!task.isCancelled()) {
task.runLater(() -> {
task.updateValue(result);
task.setState(State.SUCCEEDED);
});
return result;
} else {
return null;
}
}
2
3
4
5
6
7
8
9
10
11
12
如果程序抛出了异常或错误,会进入catch()代码块,设置Task对象的Exception信息并将状态设置为State.FAILED,也就是将任务标记为失败。接下来,判断异常或错误的类型,如果是Exception类型的异常,则直接强转为Exception类型的异常并抛出。否则,将异常或者错误封装为Exception对象并抛出,如下:
catch (final Throwable th) {
task.runLater(() -> {
task._setException(th);
task.setState(State.FAILED);
});
if (th instanceof Exception) {
throw (Exception) th;
} else {
throw new Exception(th);
}
}
2
3
4
5
6
7
8
9
10
11
# 两种异步模型
在Java的并发编程中,大体上分为两种异步编程模型,一类是直接以异步的形式来并行运行其他的任务,不需要返回任务的结果数据。一类是以异步的形式运行其他任务,需要返回结果。
- 无返回结果的异步模型
无返回结果的异步任务,可以直接将任务丢进线程或线程池中运行,此时,无法直接获得任务的执行结果数据,一种方式是可以使用回调方法来获取任务的运行结果。
具体的方案是:定义一个回调接口,并在接口中定义接收任务结果数据的方法,具体逻辑在回调接口的实现类中完成。将回调接口与任务参数一同放进线程或线程池中运行,任务运行后调用接口方法,执行回调接口实现类中的逻辑来处理结果数据。这里,给出一个简单示例:
- 定义回调接口
package com.ainsn.dandelion.thread;
/**
* 定义回调接口
*
* @author sunyy
* @version 0.0.1
* @since 2023.3.14
*/
public interface TaskCallable<T> {
T callable(T t);
}
2
3
4
5
6
7
8
9
10
11
12
便于接口的通用型,这里为回调接口定义了泛型。
- 定义任务结果数据的封装类
package com.ainsn.dandelion.thread;
import java.io.Serializable;
/**
* 任务执行结果
*
* @author sunyy
* @version 0.0.1
* @since 2023.3.14
*/
public class TaskResult implements Serializable {
private static final long serialVersionUID = -1L;
/**
* 任务状态
*/
private Integer taskStatus;
/**
* 任务消息
*/
private String taskMessage;
/**
* 任务结果数据
*/
private String taskResult;
public Integer getTaskStatus() {
return taskStatus;
}
public void setTaskStatus(Integer taskStatus) {
this.taskStatus = taskStatus;
}
public String getTaskMessage() {
return taskMessage;
}
public void setTaskMessage(String taskMessage) {
this.taskMessage = taskMessage;
}
public String getTaskResult() {
return taskResult;
}
public void setTaskResult(String taskResult) {
this.taskResult = taskResult;
}
@Override
public String toString() {
return "TaskResult [taskStatus=" + taskStatus + ", taskMessage=" + taskMessage + ", taskResult=" + taskResult
+ "]";
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
- 创建回调接口的实现类
回调接口的实现类主要用来对任务的返回结果进行相应的业务处理,这里,为了方便延时,只是将结果数据返回。实际场景中需要根据具体的业务场景来做相应的分析和处理。
package com.ainsn.dandelion.thread;
/**
* 回调接口实现类
*
* @author sunyy
* @version 0.0.1
* @since 2023.3.14
*/
public class TaskHandler implements TaskCallable<TaskResult> {
@Override
public TaskResult callable(TaskResult t) {
// TODO 拿到结果数据后进一步处理
System.out.println(t.toString());
return t;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
- 创建任务的执行类
任务的执行类是具体执行任务的类,实现Runnable接口,在此类定义一个回调接口类型的成员变量和一个String类型的任务参数(模拟任务的参数),并在构造方法中注入回调接口和任务参数。在run方法中执行任务,任务完成后将任务的结果数据封装成TaskResult对象,调用回调接口的方法将TaskResult对象传递到回调方法中。
package com.ainsn.dandelion.thread;
/**
* 任务执行类
*
* @author sunyy
* @version 0.0.1
* @since 2023.3.14
*/
public class TaskExecutor implements Runnable {
private TaskCallable<TaskResult> taskCallable;
private String taskParameter;
public TaskExecutor(TaskCallable<TaskResult> taskCallable, String taskParameter) {
this.taskCallable = taskCallable;
this.taskParameter = taskParameter;
}
@Override
public void run() {
// TODO 一系列业务逻辑,将结果数据封装成TaskResult对象并返回
TaskResult result = new TaskResult();
result.setTaskStatus(1);
result.setTaskMessage(this.taskParameter);
result.setTaskResult("异步回调成功");
taskCallable.callable(result);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
到这里,大体框架算是完成了,接下来,就是测试看能否获取到异步任务的结果了。
- 异步任务测试类
package com.ainsn.dandelion.thread;
/**
* 测试回调
*
* @author sunyy
* @version 0.0.1
* @since 2023.3.14
*/
public class TaskCallableTest {
public static void main(String[] args) {
TaskCallable<TaskResult> taskCallable = new TaskHandler();
TaskExecutor taskExecutor = new TaskExecutor(taskCallable, "测试回调任务");
new Thread(taskExecutor).start();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
在测试类中,使用Thread类创建一个新的线程,并启动线程运行任务,运行结果:
TaskResult [taskStatus=1, taskMessage=测试回调任务, taskResult=异步回调成功]
大家可以品味下这种获取异步结果的方式,这里,只是简单的使用了Thread类来创建并启动线程,也可以使用线程池的方式实现,大家可自行实现以线程池的方式通过回调接口获取异步结果。
- 有返回结果的异步模型
尽管使用回调接口能够获取异步任务的结果,但是这种方式使用起来略显复杂。在JDK中提供了可以直接返回异步结果的处理方案,最常用的就是使用Future接口或者其实现类FutureTask来接收任务的返回结果。
- 使用
Future接口获取异步结果
使用Future接口往往配合线程池来获取异步执行结果,如下:
package com.ainsn.dandelion.thread;
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Future;
/**
* 测试Future获取异步结果
*
* @author sunyy
* @version 0.0.1
* @since 2023.3.14
*/
public class FutureTest {
public static void main(String[] args) throws InterruptedException, ExecutionException {
ExecutorService executor = Executors.newSingleThreadExecutor();
Future<String> future = executor.submit(new Callable<String>() {
@Override
public String call() throws Exception {
return "测试Future获取异步结果";
}
});
System.out.println(future.get());
executor.shutdown();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
- 使用
FutureTask类获取异步结果
FutureTask类既可以结合Thread类使用也可以结合线程池使用,接下来,就来看下两种使用方式:
结合Thread类的使用示例如下:
package com.ainsn.dandelion.thread;
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.FutureTask;
/**
* 测试FutureTask获取异步结果
*
* @author sunyy
* @version 0.0.1
* @since 2023.3.14
*/
public class FutureTaskTest {
public static void main(String[] args) throws InterruptedException, ExecutionException {
FutureTask<String> futureTask = new FutureTask<>(new Callable<String>() {
@Override
public String call() throws Exception {
return "测试FutureTask获取异步结果";
}
});
new Thread(futureTask).start();
System.out.println(futureTask.get());
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
结合线程池的使用示例如下:
package com.ainsn.dandelion.thread;
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.FutureTask;
/**
* 测试FutureTask获取异步结果
*
* @author sunyy
* @version 0.0.1
* @since 2023.3.14
*/
public class FutureTaskTest02 {
public static void main(String[] args) throws InterruptedException, ExecutionException {
ExecutorService executor = Executors.newSingleThreadExecutor();
FutureTask<String> futureTask = new FutureTask<>(new Callable<String>() {
@Override
public String call() throws Exception {
return "测试FutureTask获取异步结果";
}
});
executor.execute(futureTask);
System.out.println(futureTask.get());
executor.shutdown();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
可以看到使用Future接口或者FutureTask类来获取异步结果比使用回调接口获取异步结果简单的多,注意:实现异步的方式有很多,这里只是用多线程举例。
# 深度解析Future接口
Future接口
Future是JDK1.5新增的异步编程接口,其源代码如下:
package java.util.concurrent;
public interface Future<V> {
boolean cancel(boolean mayInterruptIfRunning);
boolean isCancelled();
boolean isDone();
V get() throws InterruptedException, ExecutionException;
V get(long timeout, TimeUnit unit) throws InterruptedException, ExecutionException, TimeoutExeception;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
可以看到,在Future接口中,总共定义了5个抽象方法,接下来,分别介绍这5个方法的含义:
cancel(boolean)
取消任务的执行,接收一个boolean类型的参数,成功取消任务,返回true,否则返回false。当任务已经完成,已经结束或者因其他原因不能取消时,方法会返回false,表示任务取消失败。当任务为启动调用了此方法,并且结果返回true(取消成功),则当前任务不再运行。如果任务已经启动,会根据当前传递的boolean类型的参数来决定是否中断当前运行的线程来取消当前运行的任务。
isCancelled()
判断任务在完成之前是否被取消,如果任务完成之前被取消,则返回true;否则,返回false。
这里需要注意一个细节
只有任务未启动,或者在完成之前被取消,才会返回true,表示任务已经被成功取消,其他情况都会返回false。
isDone()
判断任务是否已经完成,如果任务正常结束、抛出异常退出、被取消,都会返回true,表示任务已经完成。
get()
当任务完成时,直接返回任务的结果数据;当任务未完成时,等待任务完成并返回任务的结果数据。
get(long, TimeUnit)
当任务完成时,直接返回任务的结果数据;当任务未完成时,等待任务完成,并设置了超时等待时间,在超时时间内完成,则返回结果,否则,抛出TimeoutException异常。
RunnableFuture接口
Future接口有一个重要的子接口,那就是RunnableFuture接口,RunnableFuture接口不但继承了Future接口,而且继承了java.lang.Runnable接口,其源代码如下:
package java.util.concurrent;
public interface RunnableFuture<V> extends Runnable, Future<V> {
void run();
}
2
3
4
5
这个接口里的run()方法就是运行任务时调用的方法。
FutureTask类
FutureTask类是RunnableFuture接口的一个非常重要的实现类,它实现了RunnableFuture接口、Future接口和Runnable接口的所有方法。
FutureTask类中的变量与常量
在FutureTask类中首先定义了一个状态变量state,这个变量使用了volatile关键字修饰,这里,大家只需要知道volatile关键字通过内存屏障和禁止重排序优化来实现线程安全,后续会单独深度分析volatile关键字是如何保证线程安全的。紧接着,定义了几个任务运行时的状态常量,如下:
private volatile int state;
private static final int NEW = 0;
private static final int COMPLETING = 1;
private static final int NORMAL = 2;
private static final int EXCEPTIONAL = 3;
private static final int CANCELLED = 4;
private static final int INTERRUPTING = 5;
private static final int INTERRUPTED = 6;
2
3
4
5
6
7
8
其中,代码注释中给出了几个可能的状态变更流程,如下:
NEW -> COMPLETING -> NORMAL
NEW -> COMPLETING -> EXCEPTIONAL
NEW -> CANCELLED
NEW -> INTERRUPTING -> INTERRUPTED
2
3
4
接下来,定义了其他几个成员变量,如下:
private Callable<V> callable;
private Object outcome;
private volatile Thread runner;
private volatile WaitNode waiters;
2
3
4
又看到我们所熟悉的Callable接口了,Callable接口那肯定就是用来调用call()方法执行具体任务了。
outcome:Object类型,表示通过get()方法获取到的结果数据或者异常信息。runner: 运行Callable的线程,运行期间会使用CAS保证线程安全,这里大家只需要知道CAS是Java保证线程安全的一种方式,后续会深度分析。waiters:WaitNode类型的变量,表示等待线程的堆栈,在FutureTask的实现中,会通过CAS结合此堆栈交换任务的运行状态。
WaitNode类的源码:
static final class WaitNode {
volatile Thread thread;
volatile WaitNode next;
WaitNode() { thread = Thread.currentThread(); }
}
2
3
4
5
可以看到,WaitNode类是FutureTask类的静态内部类,类中定义了一个Thread成员变量和指向下一个WaitNode节点的引用。其中通过构造方法将thread变量设置为当前线程。
- 构造方法
接下来,是FutureTask的两个构造方法,如下:
public FutureTask(Callable<V> callable) {
if (callable == null)
throw new NullPointerException();
this.callable = callable;
this.state = NEW;
}
public FutureTask(Runnable runnable, V result) {
this.callable = Executors.callable(runnable, result);
this.state = NEW;
}
2
3
4
5
6
7
8
9
10
11
- 是否取消与完成方法
public boolean isCancelled() {
return state >= CANCELLED;
}
public boolean isDone() {
return state != NEW;
}
2
3
4
5
6
7
这两方法中,都是通过判断任务的状态来判定任务是否已取消和已完成的。为什么会这样判断?FutureTask类中定义的状态常量是有规律的,并不是随意定义的。其中,大于或者等于CANCELLED的常量为CANCELLED、INTERRUPTING和INTERRUPTED,这三个状态均可以表示线程已经被取消。当状态不等于NEW时,可以表示任务已经完成。
提示
以后在编码过程中,要按照规律来定义自己使用的状态,尤其是涉及到业务中有频繁的状态变更的操作,有规律的状态可使业务处理变得事半功倍,这也是通过看别人的源码设计能够学到的。
- 取消方法
public boolean cancel(boolean mayInterruptIfRunning) {
if (!(state == NEW && UNSAFE.compareAndSwapInt(this, stateOffset, NEW, mayInterruptIfRunning ? INTERRUPTING : CANCELLED)))
return false;
try { // in case call to interrupt throws exception
if (mayInterruptIfRunning) {
try {
Thread t = runner;
if (t != null)
t.interrupt();
} finally { // final state
UNSAFE.putOrderedInt(this, stateOffset, INTERRUPTED);
}
}
} finally {
finishCompletion();
}
return true;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
接下来,拆解cancel(boolean)方法。在cancel(boolean)方法中,首先判断任务的状态和CAS的操作结果,如果任务的状态不等于NEW或CAS的操作返回false,则直接返回false,表示任务取消失败,如下:
if (!(state == NEW && UNSAFE.compareAndSwapInt(this, stateOffset, NEW, mayInterruptIfRunning ? INTERRUPTING : CANCELLED)))
return false;
2
接下来,在try代码块中,首先判断是否可以中断当前任务所在的线程来取消任务的运行。如果可以中断当前任务所在的线程,则以一个Thread临时变量来指向运行任务的线程,当指向的变量不为空时,调用线程对象的interrupt()方法来中断线程的运行,最后将线程标记为被中断的状态。如下:
try { // in case call to interrupt throws exception
if (mayInterruptIfRunning) {
try {
Thread t = runner;
if (t != null)
t.interrupt();
} finally { // final state
UNSAFE.putOrderedInt(this, stateOffset, INTERRUPTED);
}
}
}
2
3
4
5
6
7
8
9
10
11
这里,发现变更任务状态使用的是UNSAFE.putOrderedInt()方法,如下:
public native void putOrderedInt(Object var1, long var2, int var4);
接下来,cancel(boolean)方法会进入finally代码块,如下:
finally {
finishCompletion();
}
2
3
可以看到在finally代码块中调用了finishCompletion()方法,顾名思义,finishCompletion()方法表示结束任务的运行,源码如下:
private void finishCompletion() {
// assert state > COMPLETING;
for (WaitNode q; (q = waiters) != null;) {
if (UNSAFE.compareAndSwapObject(this, waitersOffset, q, null)) {
for (;;) {
Thread t = q.thread;
if (t != null) {
q.thread = null;
LockSupport.unpark(t);
}
WaitNode next = q.next;
if (next == null)
break;
q.next = null; // unlink to help gc
q = next;
}
break;
}
}
done();
callable = null; // to reduce footprint
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
在finishCompletion()方法中,首先定义一个for循环,循环终止因子为waiters为null,在循环中,判断CAS操作是否成功,如果成功进行if条件中的逻辑。首先,定义一个for自旋循环,在自旋循环体中,唤醒WaitNode堆栈中的线程,使其运行完成。当WaitNode堆栈中的线程运行完成后,通过break退出外层for循环。接下来调用done()方法。done()源码:
protected void done() { }
可以看到,done()方法是一个空的方法体交由子类来实现具体的业务逻辑。当我们的具体业务中,需要在取消任务时,执行一些额外的业务逻辑,可以在子类中覆写done()方法的实现。
get()方法
继续向下看FutureTask类的代码,FutureTask类中实现了两个get()方法,如下:
public V get() throws InterruptedException, ExecutionException {
int s = state;
if (s <= COMPLETING)
s = awaitDone(false, 0L);
return report(s);
}
public V get(long timeout, TimeUnit unit) throws InterruptedException, ExecutionException, TimeoutException {
if (unit == null)
throw new NullPointerException();
int s = state;
if (s <= COMPLETING && (s = awaitDone(true, unit.toNanos(timeout))) <= COMPLETING)
throw new TimeoutException();
return report(s);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
没参数的get()方法为当任务未运行完成时,会阻塞,直到返回任务结果。有参数的get()方法为当任务未运行完成,并且等待时间超出了超时时间,会TimeoutException异常。
两个get()方法的主要逻辑差不多,一个没有超时设置,一个有超时设置,主要逻辑:判断任务的当前状态是否小于或者等于COMPLETING,也就是说,任务是NEW状态或者COMPLETING,调用awaitDone()方法,awaitDone()源码:
private int awaitDone(boolean timed, long nanos) throws InterruptedException {
final long deadline = timed ? System.nanoTime() + nanos : 0L;
WaitNode q = null;
boolean queued = false;
for (;;) {
if (Thread.interrupted()) {
removeWaiter(q);
throw new InterruptedException();
}
int s = state;
if (s > COMPLETING) {
if (q != null)
q.thread = null;
return s;
}
else if (s == COMPLETING) // cannot time out yet
Thread.yield();
else if (q == null)
q = new WaitNode();
else if (!queued)
queued = UNSAFE.compareAndSwapObject(this, waitersOffset, q.next = waiters, q);
else if (timed) {
nanos = deadline - System.nanoTime();
if (nanos <= 0L) {
removeWaiter(q);
return state;
}
LockSupport.parkNanos(this, nanos);
}
else
LockSupport.park(this);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
接下来,拆解awaitDone()方法。在awaitDone()方法中,最重要的就是for自旋循环,在循环中首先判断当前线程是否被中断,如果已经被中断,则调用removeWaiter()将当前线程从堆栈中移除,并且抛出InterruptedException异常,如下:
if (Thread.interrupted()) {
removeWaiter(q);
throw new InterruptedException();
}
2
3
4
接下来,判断任务的当前状态是否完成,如果完成,并且堆栈句柄不为空,则将堆栈中的当前线程设置为空,返回当前任务的状态,如下:
int s = state;
if (s > COMPLETING) {
if (q != null)
q.thread = null;
return s;
}
2
3
4
5
6
当任务的状态为COMPLETING时,使当前线程让出CPU资源,如下:
else if (s == COMPLETING) // cannot time out yet
Thread.yield();
2
如果堆栈为空,则创建堆栈对象,如下:
else if (q == null)
q = new WaitNode();
2
如果queued变量为false,通过CAS操作为queued赋值,如果awaitDone()方法传递的timed参数为true,则计算超时时间,当时间已超时,则在堆栈中移除当前线程并返回任务状态,如果未超时,则重置超时时间,如下:
else if (!queued)
queued = UNSAFE.compareAndSwapObject(this, waitersOffset, q.next = waiters, q);
else if (timed) {
nanos = deadline - System.nanoTime();
if (nanos <= 0L) {
removeWaiter(q);
return state;
}
LockSupport.parkNanos(this, nanos);
}
2
3
4
5
6
7
8
9
10
如果不满足上述的所有条件,则将当前线程设置为等待状态,如下:
else
LockSupport.park(this);
2
接下来,回到get()方法中,当awaitDone()方法返回结果,或者任务的状态不满足条件时,都会调用report()方法,并将当前任务的状态传递到report()方法中,并返回结果,如下:
return report(s);
private V report(int s) throws ExecutionException {
Object x = outcome;
if (s == NORMAL)
return (V) x;
if (s >= CANCELLED)
throw new CancellationException();
throw new ExecutionException((Throwable) x);
}
2
3
4
5
6
7
8
可以看到,report()方法的实现比较简单,首先,将outcome数据赋值给x变量,接下来,主要是判断接收到的任务状态,如果状态为NORMAL,则将x强转为泛类型返回;当任务的状态大于或者等于CANCELLED,也就是任务已经取消,则抛出CancellationException异常,其他情况则抛出ExecutionException异常。
至此,get()方法分析完成。
注意
一定要理解get()方法的实现,因为get()方法是我们使用Future接口和FutureTask类时,使用的比较频繁的一个方法。
set()方法与setException()方法
FutureTask代码,如下:
protected void set(V v) {
if (UNSAFE.compareAndSwapInt(this, stateOffset, NEW, COMPLETING)) {
outcome = v;
UNSAFE.putOrderedInt(this, stateOffset, NORMAL); // final state
finishCompletion();
}
}
protected void setException(Throwable t) {
if (UNSAFE.compareAndSwapInt(this, stateOffset, NEW, COMPLETING)) {
outcome = t;
UNSAFE.putOrderedInt(this, stateOffset, EXCEPTIONAL); // final state
finishCompletion();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
通过源码可以看出,set()方法与setException()方法整体逻辑几乎一样,只是在设置状态时一个将状态设置为NORMAL,一个将状态设置为EXCEPTIONAL。
run()方法与runAndReset()方法
public void run() {
if (state != NEW || !UNSAFE.compareAndSwapObject(this, runnerOffset, null, Thread.currentThread()))
return;
try {
Callable<V> c = callable;
if (c != null && state == NEW) {
V result;
boolean ran;
try {
result = c.call();
ran = true;
} catch (Throwable ex) {
result = null;
ran = false;
setException(ex);
}
if (ran)
set(result);
}
} finally {
// runner must be non-null until state is settled to
// prevent concurrent calls to run()
runner = null;
// state must be re-read after nulling runner to prevent
// leaked interrupts
int s = state;
if (s >= INTERRUPTING)
handlePossibleCancellationInterrupt(s);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
可以这么说,只要使用了Future和FutureTask,就必然会调用run()方法来运行任务,掌握run()方法的流程是非常有必要的,在run()方法中,如果当前状态不是NEW,或者CAS操作返回的结果为false,则直接返回,不再执行后续逻辑,如下:
if (state != NEW || !UNSAFE.compareAndSwapObject(this, runnerOffset, null, Thread.currentThread()))
return;
2
接下来,在try代码块中,将成员变量callable赋值给一个临时变量c,判断临时变量不等于null,并且任务状态为NEW,则调用Callable接口的call()方法,并接收结果数据,并将ran变量设置为true。当程序抛出异常时,将接收结果的变量设置为null,ran变量设置为false,并且调用setException()方法将任务的状态设置为EXCEPTIONAL。接下来,如果ran变量为true,则调用set()方法,如下:
try {
Callable<V> c = callable;
if (c != null && state == NEW) {
V result;
boolean ran;
try {
result = c.call();
ran = true;
} catch (Throwable ex) {
result = null;
ran = false;
setException(ex);
}
if (ran)
set(result);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
接下来,程序会进入finally代码块:
finally {
// runner must be non-null until state is settled to
// prevent concurrent calls to run()
runner = null;
// state must be re-read after nulling runner to prevent
// leaked interrupts
int s = state;
if (s >= INTERRUPTING)
handlePossibleCancellationInterrupt(s);
}
2
3
4
5
6
7
8
9
10
这里,将runner设置为null,如果任务的当前状态大于或者等于INTERRUPTING,也就是线程被中断了。则调用handlePossibleCancellationInterrupt()方法,其源码:
private void handlePossibleCancellationInterrupt(int s) {
if (s == INTERRUPTING)
while (state == INTERRUPTING)
Thread.yield();
}
2
3
4
5
可以看到,handlePossibleCancellationInterrupt()方法的实现比较简单,当任务的状态为INTERRUPTING时,使用while()循环,条件为当前任务状态为INTERRUPTING,将当前线程占用的CPU资源释放,也就是,当任务运行完成后,释放线程所占用的资源。
runAndReset()方法的逻辑与run()差不多,只是runAndReset()方法会在finally代码快中将任务状态重置为NEW,runAndReset()方法的源代码如下所示:
protected boolean runAndReset() {
if (state != NEW || !UNSAFE.compareAndSwapObject(this, runnerOffset, null, Thread.currentThread()))
return false;
boolean ran = false;
int s = state;
try {
Callable<V> c = callable;
if (c != null && s == NEW) {
try {
c.call(); // don't set result
ran = true;
} catch (Throwable ex) {
setException(ex);
}
}
} finally {
// runner must be non-null until state is settled to
// prevent concurrent calls to run()
runner = null;
// state must be re-read after nulling runner to prevent
// leaked interrupts
s = state;
if (s >= INTERRUPTING)
handlePossibleCancellationInterrupt(s);
}
return fan && s == NEW;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
removeWaiter()方法
removeWaiter()方法中主要是使用自旋循环的方式来移除WaitNode中的线程,源码如下:
private void removeWaiter(WaitNode node) {
if (node != null) {
node.thread = null;
retry:
for (;;) { // restart on removeWaiter race
for (WaitNode pred = null, q = waiters, s; q != null; q = s) {
s = q.next;
if (q.thread != null)
pred = q;
else if (pred != null) {
pred.next = s;
if (pred.thread == null) // check for race
continue retry;
}
else if (!UNSAFE.compareAndSwapObject(this, waitersOffset, q, s))
continue retry;
}
break;
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
最后,在FutureTask类的最后,有如下代码:
// Unsafe mechanics
private static final sun.misc.Unsafe UNSAFE;
private static final long stateOffset;
private static final long runnerOffset;
private static final long waitersOffset;
static {
try {
UNSAFE = sun.misc.Unsafe.getUnsafe();
Class<?> k = FutureTask.class;
stateOffset = UNSAFE.objectFieldOffset(k.getDeclaredField("state"));
runnerOffset = UNSAFE.objectFieldOffset(k.getDeclaredField("runner"));
waitersOffset = UNSAFE.objectFieldOffset(k.getDeclaredField("waiters"));
} catch (Exception e) {
throw new Error(e);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
关于这些代码的作用,会在后续深度解析CAS文章中详细说明。
# SimpleDateFormat类的线程安全问题
提起SimpleDateFormat类,相比做过Java开发的同学都不会感到陌生,没错,就是Java中提供的日期时间的转化类。这里,为什么说SimpleDateFormat类有线程安全问题呢?有些小伙伴可能会提出疑问:我们生产环境上一直在在使用SimpleDateFormat类来解析和格式化日期和时间类型的数据,为什么一直都没有问题!原因是因为我们的系统达不到SimpleDateFormat类出现问题的并发量,也就是说系统没有负载!
接下来,我们就一起看下在高并发下SimpleDateFormat类为何会出现安全问题,以及如何解决SimpleDateFormat类的安全问题。
# 重现SimpleDateFormat类的线程安全问题
为了重现SimpleDateFormat类的线程安全问题,一种比较简单的方式就是使用线程池结合Java并发包中的CountDownLatch类和Semaphore类来重现线程安全问题。
有关CountDownLatch类和Semaphore类的具体用法和底层原理与源码解析在【高并发专题】会深度分析。这里,大家只需要知道CountDownLatch类可以使一个线程等待其他线程各自执行完毕后再执行。而Semaphore类可以理解为一个计数信号量,必须由获取它的线程释放,经常用来限制访问某些资源的线程数量,例如限流等。
SimpleDateFormat类的源码如下:
package com.ainsn.dandelion.thread;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Semaphore;
/**
* 测试SimpleDateFormat的线程不安全问题
*
* @author sunyy
* @version 0.0.1
* @since 2023.3.15
*/
public class SimpleDateFormatTest01 {
/**
* 执行总次数
*/
private static final int EXECUTE_COUNT = 1000;
/**
* 同时运行的线程数量
*/
private static final int THREAD_COUNT = 20;
/**
* SimpleDateFormat对象
*/
private static SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd");
public static void main(String[] args) throws InterruptedException {
final Semaphore semaphore = new Semaphore(THREAD_COUNT);
final CountDownLatch countDownLatch = new CountDownLatch(EXECUTE_COUNT);
ExecutorService executorService = Executors.newCachedThreadPool();
for (int i = 0; i < EXECUTE_COUNT; i++) {
executorService.execute(() -> {
try {
semaphore.acquire();
try {
simpleDateFormat.parse("2023-03-15");
System.out.println("线程:" + Thread.currentThread().getName() + " 格式化日期成功");
} catch (ParseException e) {
System.out.println("线程:" + Thread.currentThread().getName() + " 格式化日期失败");
e.printStackTrace();
System.exit(1);
} catch (NumberFormatException e) {
System.out.println("线程:" + Thread.currentThread().getName() + " 格式化日期失败");
e.printStackTrace();
System.exit(1);
}
semaphore.release();
} catch (InterruptedException e) {
System.out.println("信号量发生错误");
e.printStackTrace();
System.exit(1);
}
});
}
countDownLatch.await();
executorService.shutdown();
System.out.println("所有线程格式化日期成功");
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
可以看到,在SimpleDateFormatTest01类中,首先定义了两个常量,一个是程序执行的总次数,一个是同时运行的线程数量。程序中结合线程池和CountDownLatch类与Semaphore类来模拟高并发的业务场景,其中,有关日期转化的代码只有如下一行。
simpleDateFormat.parse("2023-03-15");
当程序捕获到异常时,打印相关的信息,并退出整个程序的运行。当程序正确运行后,会打印“所有线程格式化日期成功”。运行结果如下:
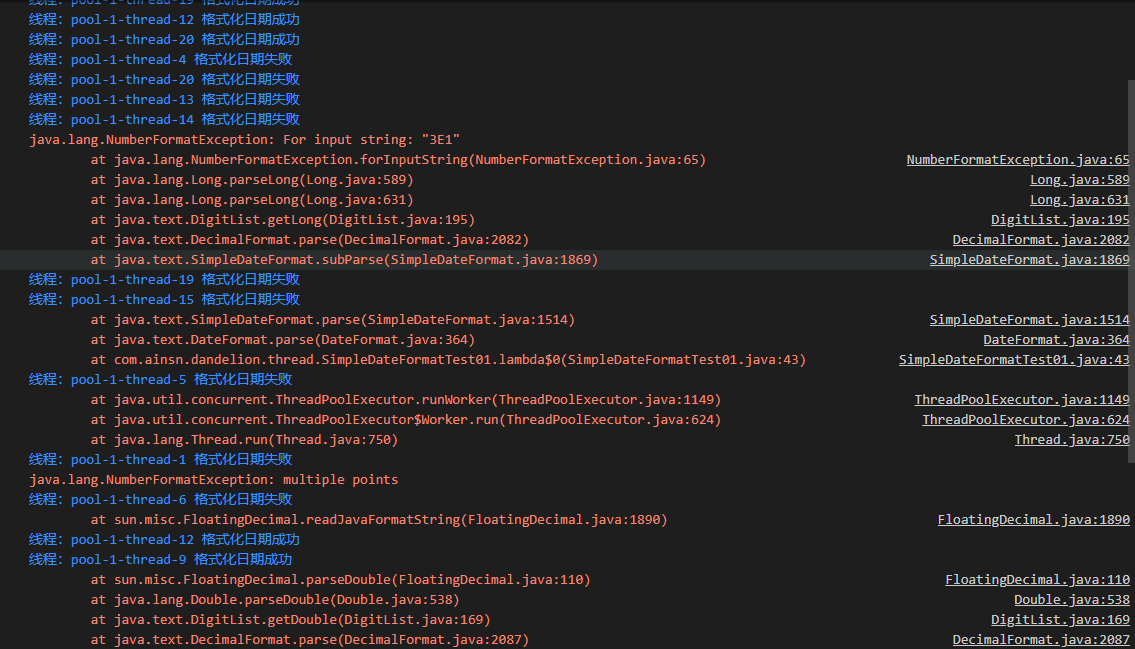
说明,在高并发下使用SimpleDateFormat类格式化日期时抛出了异常,SimpleDateFormat类不是线程安全的。
# SimpleDateFormat类为何不是线程安全的
接下来,就看看真正引起SimpleDateFormat类线程不安全的根本原因。
SimpleDateFormat是继承自DateFormat类,DateFormat类中维护了一个全局的Calendar变量,如下:
/**
* The {@link Calendar} instance used for calculating the date-time fields
* and the instant of time. This field is used for both formatting and
* parsing.
*
* <p>Subclasses should initialize this field to a {@link Calendar}
* appropriate for the {@link Locale} associated with this
* <code>DateFormat</code>
* @serial
*/
protected Calendar calendar;
2
3
4
5
6
7
8
9
10
11
从注释可以看出,这个Calendar对象既用于格式化也用于解析日期时间。parse()源码如下:
@Override
public Date parse(String text, ParsePosition pos) {
// 此处省略N行代码
Date parseDate;
try {
parsedDate = calb.establish(calendar).getTime();
// If the year value is ambiguous,
// then the two-digit year == the default start year
if (ambiguousYear[0]) {
if (parsedDate.before(defaultCenturyStart)) {
parsedDate = calb.addYear(100).establish(calendar).getTime();
}
}
}
// An IllegalArgumentException will be thrown by Calendar.getTime()
// if any fields are out of range, e.g., MONTH == 17.
catch (IllegalArgumentException e) {
pos.errorIndex = start;
pos.index = oldStart;
return null;
}
return parsedDate;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
可见,最后的返回值是通过调用CalendarBuilder.establish()方法获得的,而这个方法的参数正好就是前面的Calendar对象。
CalendarBuilder.establish()源码如下:
Calendar establish(Calendar cal) {
boolean weekDate = isSet(WEEK_YEAR) && field[WEEK_YEAR] > field[YEAR];
if (weekDate && !cal.isWeekDateSupported()) {
// Use YEAR instead
if (!isSet(YEAR)) {
set(YEAR, field[MAX_FIELD + WEEK_YEAR]);
}
weekDate = false;
}
cal.clear();
// Set the fields from the min stamp to the max stamp so that
// the field resolution works in the Calendar.
for (int stamp = MINIMUM_USER_STAMP; stamp < nextStamp; stamp++) {
for (int index = 0; index <= maxFieldIndex; index++) {
if (field[index] == stamp) {
cal.set(index, field[MAX_FIELD + index]);
break;
}
}
}
if (weekDate) {
int weekOfYear = isSet(WEEK_OF_YEAR) ? field[MAX_FIELD + WEEK_OF_YEAR] : 1;
int dayOfWeek = isSet(DAY_OF_WEEK) ? field[MAX_FIELD + DAY_OF_WEEK] : cal.getFirstDayOfWeek();
if (!isValidDayOfWeek(dayOfWeek) && cal.isLenient()) {
if (dayOfWeek >= 8) {
dayOfWeek--;
weekOfYear += dayOfWeek / 7;
dayOfWeek = (dayOfWeek % 7) + 1;
} else {
while (dayOfWeek <= 0) {
dayOfWeek += 7;
weekOfYear--;
}
}
dayOfWeek = toCalendarDayOfWeek(dayOfWeek);
}
cal.setWeekDate(field[MAX_FIELD + WEEK_YEAR], weekOfYear, dayOfWeek);
}
return cal;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
在CalendarBuilder.establish()方法中先后调用了cal.clear()与cal.set(),也就是先清除cal对象中设置的值,再重新设置新的值。由于Calendar内部并没有线程安全机制,并且这两个操作也都不是原子性的,所以当多个线程同时操作一个SimpleDateFormat时就会引起cal的值混乱。类似的,format()方法也存在同样的问题。
因此,SimpleDateFormat类不是线程安全的,以及造成SimpleDateFormat类不是线程安全的原因,那么如何解决这个问题呢?
# 解决SimpleDateFormat类的线程安全问题
解决SimpleDateFormat类在高并发场景下的线程安全问题可以有多种方式,下面就列举几个常用的方式:
- 局部变量法
最简单的一种方式就是将SimpleDateFormat类对象定义成局部变量,如下所示:
package com.ainsn.dandelion.thread;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Semaphore;
/**
* 局部变量法解决SimpleDateFormat类的线程安全问题
*
* @author sunyy
* @version 0.0.1
* @since 2023.3.15
*/
public class SimpleDateFormatTest02 {
/**
* 执行总次数
*/
private static final int EXECUTE_COUNT = 1000;
/**
* 同时运行的线程数量
*/
private static final int THREAD_COUNT = 20;
public static void main(String[] args) throws InterruptedException {
final Semaphore semaphore = new Semaphore(THREAD_COUNT) ;
final CountDownLatch countDownLatch = new CountDownLatch(EXECUTE_COUNT);
ExecutorService executorService = Executors.newCachedThreadPool();
for (int i = 0; i < EXECUTE_COUNT; i++) {
executorService.execute(() -> {
try {
semaphore.acquire();
try {
SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd");
simpleDateFormat.parse("2023-03-15");
} catch (ParseException e) {
System.out.println("线程:" + Thread.currentThread().getName() + " 格式化日期失败");
e.printStackTrace();
System.exit(1);
} catch (NumberFormatException e) {
System.out.println("线程:" + Thread.currentThread().getName() + " 格式化日期失败");
e.printStackTrace();
System.exit(1);
}
semaphore.release();
} catch (InterruptedException e) {
System.out.println("信号量发生错误");
e.printStackTrace();
System.exit(1);
}
countDownLatch.countDown();
});
}
countDownLatch.await();
executorService.shutdown();
System.out.println("所有线程格式化日期成功");
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
此时运行修改后,输出结果:
所有线程格式化日期成功
至于在高并发场景下使用局部变量为何能解决线程的安全问题,会在【JVM专题】的JVM内存模型相关内容中深入剖析。当然,这种方式在高并发下会创建大量的SimpleDateFormat类对象,影响程序性能,所以,这种方式在实际生产环境不太推荐。
- synchronized锁方式
将SimpleDateFormat类对象定义成全局静态变量,此时所有线程共享SimpleDateFormat类对象,此时在调用格式化时间的方法时,对SimpleDateFormat对象进行同步即可,代码如下:
package com.ainsn.dandelion.thread;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Semaphore;
/**
* 通过synchronized锁解决SimpleDateFormat类的线程安全问题
*
* @author sunyy
* @version 0.0.1
* @since 2023.3.15
*/
public class SimpleDateFormatTest03 {
/**
* 执行总次数
*/
private static final int EXECUTE_COUNT = 1000;
/**
* 同时运行的线程数量
*/
private static final int THREAD_COUNT = 20;
/**
* SimpleDateFormat对象
*/
private static SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd");
public static void main(String[] args) throws InterruptedException {
final Semaphore semaphore = new Semaphore(THREAD_COUNT);
final CountDownLatch countDownLatch = new CountDownLatch(EXECUTE_COUNT);
ExecutorService executorService = Executors.newCachedThreadPool();
for (int i = 0; i < EXECUTE_COUNT; i++) {
executorService.execute(() -> {
try {
semaphore.acquire();
try {
synchronized (simpleDateFormat) {
simpleDateFormat.parse("2023-03-15");
}
} catch (ParseException e) {
System.out.println("线程:" + Thread.currentThread().getName() + " 格式化日期失败");
e.printStackTrace();
System.exit(1);
} catch (NumberFormatException e) {
System.out.println("线程:" + Thread.currentThread().getName() + " 格式化日期失败");
e.printStackTrace();
System.exit(1);
}
semaphore.release();
} catch (InterruptedException e) {
System.out.println("信号量发生错误");
e.printStackTrace();
System.exit(1);
}
countDownLatch.countDown();
});
}
countDownLatch.await();
executorService.shutdown();
System.out.println("所有线程格式化日期成功");
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
此时,解决问题的关键字代码如下:
synchronized (simpleDateFormat) {
simpleDateFormat.parse("2023-03-15");
}
2
3
运行结果如下:
所有线程格式化日期成功
注意
虽然这种方式能够解决SimpleDateFormat类的线程安全问题,但是由于在程序的执行过程中,为SimpleDateFormat类对象加上了synchronized锁,导致同一时刻只能有一个线程执行parse(String)方法。此时,会影响程序的执行性能,在要求高并发的生产环境下,此种方式不太推荐使用。
- Lock锁方式
Lock锁方式与synchronized锁方式实现原理相同,都是在高并发下通过JVM的锁机制来保证程序的线程安全。通过Lock锁方式解决问题如下:
package com.ainsn.dandelion.thread;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Semaphore;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
/**
* 通过Lock锁解决SimpleDateFormat类的线程安全问题
*
* @author sunyy
* @version 0.0.1
* @since 2023-03-15
*/
public class SimpleDateFormatTest04 {
/**
* 执行总次数
*/
private static final int EXECUTE_COUNT = 1000;
/**
* 同时运行的线程数量
*/
private static final int THREAD_COUNT = 20;
/**
* SimpleDateFormat对象
*/
private static SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd");
/**
* Lock对象
*/
private static Lock lock = new ReentrantLock();
public static void main(String[] args) throws InterruptedException {
final Semaphore semaphore = new Semaphore(THREAD_COUNT);
final CountDownLatch countDownLatch = new CountDownLatch(EXECUTE_COUNT);
ExecutorService executorService = Executors.newCachedThreadPool();
for (int i = 0; i < EXECUTE_COUNT; i++) {
executorService.execute(() -> {
try {
semaphore.acquire();
try {
lock.lock();
simpleDateFormat.parse("2023-03-15");
} catch (ParseException e) {
System.out.println("线程:" + Thread.currentThread().getName() + " 格式化日期失败");
e.printStackTrace();
System.exit(1);
} catch (NumberFormatException e) {
System.out.println("线程:" + Thread.currentThread().getName() + " 格式化日期失败");
e.printStackTrace();
System.exit(1);
} finally {
lock.unlock();
}
semaphore.release();
} catch (InterruptedException e) {
System.out.println("信号量发生错误");
e.printStackTrace();
System.exit(1);
}
countDownLatch.countDown();
});
}
countDownLatch.await();
executorService.shutdown();
System.out.println("所有线程格式化日期成功");
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
通过代码可以得知,首先,定义了一个Lock类型的全局静态变量作为加锁和释放锁的句柄,然后在simpleDateFormat.parse(String)代码之前通过lock.lock()加锁。这里需要注意的是:为防止程序抛出异常而导致锁不能被释放,一定要将释放锁的操作放到finally代码块中,如下:
finally {
lock.unlock();
}
2
3
此种方式同样会影响高并发场景下的性能,不太简易在高并发的生产环境使用。
- ThreadLocal方式
使用ThreadLocal存储每个线程拥有的SimpleDateFormat对象的副本,能够有效的避免多线程造成的线程安全问题,代码如下:
package com.ainsn.dandelion.thread;
import java.text.DateFormat;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Semaphore;
/**
* 通过ThreadLocal解决SimpleDateFormat类的线程安全问题
*
* @author sunyy
* @version 0.0.1
* @since 2023.3.15
*/
public class SimpleDateFormatTest05 {
/**
* 执行总次数
*/
private static final int EXECUTE_COUNT = 1000;
/**
* 同时运行的线程数量
*/
private static final int THREAD_COUNT = 20;
private static ThreadLocal<DateFormat> threadLocal = new ThreadLocal<DateFormat>() {
@Override
protected DateFormat initialValue() {
return new SimpleDateFormat("yyyy-MM-dd");
}
};
public static void main(String[] args) throws InterruptedException {
final Semaphore semaphore = new Semaphore(THREAD_COUNT);
final CountDownLatch countDownLatch = new CountDownLatch(EXECUTE_COUNT);
ExecutorService executorService = Executors.newCachedThreadPool();
for (int i = 0; i < EXECUTE_COUNT; i++) {
executorService.execute(() -> {
try {
semaphore.acquire();
try {
threadLocal.get().parse("2023-03-15");
} catch (ParseException e) {
System.out.println("线程:" + Thread.currentThread().getName() + " 格式化日期失败");
e.printStackTrace();
System.exit(1);
} catch (NumberFormatException e) {
System.out.println("线程:" + Thread.currentThread().getName() + " 格式化日期失败");
e.printStackTrace();
System.exit(1);
}
semaphore.release();
} catch (InterruptedException e) {
System.out.println("信号量发生错误");
e.printStackTrace();
System.exit(1);
}
countDownLatch.countDown();
});
}
countDownLatch.await();
executorService.shutdown();
System.out.println("所有线程格式化日期成功");
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
通过代码可以得知,将每个线程使用的SimpleDateFormat副本保存在ThreadLocal中,各个线程在使用时互不干扰,从而解决了线程安全问题。此种方式运行效率比较高,推荐在高并发场景下使用。
另外,使用ThreadLocal也可以写成下面的形式:
package com.ainsn.dandelion.thread;
import java.text.DateFormat;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Semaphore;
/**
* 通过ThreadLocal解决SimpleDateFormat类的线程安全问题
*
* @author sunyy
* @version 0.0.1
* @since 2023.03.15
*/
public class SimpleDateFormatTest06 {
private static final int EXECUTE_COUNT = 1000;
private static final int THREAD_COUNT = 20;
private static ThreadLocal<DateFormat> threadLocal = new ThreadLocal<DateFormat>();
private static DateFormat getDateFormat() {
DateFormat dateFormat = threadLocal.get();
if (dateFormat == null) {
dateFormat = new SimpleDateFormat("yyyy-MM-dd");
threadLocal.set(dateFormat);
}
return dateFormat;
}
public static void main(String[] args) throws InterruptedException {
final Semaphore semaphore = new Semaphore(THREAD_COUNT);
final CountDownLatch countDownLatch = new CountDownLatch(EXECUTE_COUNT);
ExecutorService executorService = Executors.newCachedThreadPool();
for (int i = 0; i < EXECUTE_COUNT; i++) {
executorService.execute(() -> {
try {
semaphore.acquire();
try {
getDateFormat().parse("2023-03-15");
} catch (ParseException e) {
System.out.println("线程:" + Thread.currentThread().getName() + " 格式化日期失败");
e.printStackTrace();
System.exit(1);
} catch (NumberFormatException e) {
System.out.println("线程:" + Thread.currentThread().getName() + " 格式化日期失败");
e.printStackTrace();
System.exit(1);
}
semaphore.release();
} catch (InterruptedException e) {
System.out.println("信号量发生错误");
e.printStackTrace();
System.exit(1);
}
countDownLatch.countDown();
});
}
countDownLatch.await();
executorService.shutdown();
System.out.println("所有线程格式化日期成功");
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
- DateTimeFormatter方式
DateTimeFormatter是Java8提供的新的日期时间API中的类,DateTimeFormatter类是线程安全的,可以在高并发场景下直接使用DateTimeFormatter类来处理日期的格式化操作。代码如下:
package com.ainsn.dandelion.thread;
import java.time.LocalDate;
import java.time.format.DateTimeFormatter;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Semaphore;
/**
* 通过DateTimeFormatter类解决线程安全问题
*
* @author sunyy
* @version 0.0.1
* @since 2023.03.15
*/
public class SimpleDateFormatTest07 {
/**
* 执行总次数
*/
private static final int EXECUTE_COUNT = 1000;
/**
* 同时运行的线程数量
*/
private static final int THREAD_COUNT = 20;
private static DateTimeFormatter formatter = DateTimeFormatter.ofPattern("yyyy-MM-dd");
public static void main(String[] args) throws InterruptedException {
final Semaphore semaphore = new Semaphore(THREAD_COUNT);
final CountDownLatch countDownLatch = new CountDownLatch(EXECUTE_COUNT);
ExecutorService executorService = Executors.newCachedThreadPool();
for (int i = 0; i < EXECUTE_COUNT; i++) {
executorService.execute(() -> {
try {
semaphore.acquire();
try {
LocalDate.parse("2023-03-15", formatter);
} catch (Exception e) {
System.out.println("线程:" + Thread.currentThread().getName() + " 格式化日期失败");
e.printStackTrace();
System.exit(1);
}
semaphore.release();
} catch (InterruptedException e) {
System.out.println("信号量发生错误");
e.printStackTrace();
System.exit(1);
}
countDownLatch.countDown();
});
}
countDownLatch.await();
executorService.shutdown();
System.out.println("所有线程格式化日期成功");
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
可以看到,DateTimeFormatter类是线程安全的,可以在高并发场景下直接使用DateTimeFormatter类来处理日期的格式化操作。使用DateTimeFormatter类来处理日期的格式化操作运行效率比较高,推荐在高并发业务场景的生产环境使用。
- joda-time方式
joda-time是第三方处理日期时间格式化的类库,是线程安全的。如果使用joda-time来处理日期和时间的格式化,则需要引入第三方类库。这里,先引入joda-time库:
<dependency>
<groupId>joda-time</groupId>
<artifactId>joda-time</artifactId>
<version>2.9.9</version>
</dependency>
2
3
4
5
代码如下:
package com.ainsn.dandelion.thread;
import org.joda.time.DateTime;
import org.joda.time.format.DateTimeFormat;
import org.joda.time.format.DateTimeFormatter;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Semaphore;
/**
* 通过DateTimeFormatter类解决线程安全问题
*
* @author sunyy
* @version 0.0.1
* @since 2023.03.15
*/
public class SimpleDateFormatTest07 {
/**
* 执行总次数
*/
private static final int EXECUTE_COUNT = 1000;
/**
* 同时运行的线程数量
*/
private static final int THREAD_COUNT = 20;
private static DateTimeFormatter formatter = DateTimeFormat.forPattern("yyyy-MM-dd");
public static void main(String[] args) throws InterruptedException {
final Semaphore semaphore = new Semaphore(THREAD_COUNT);
final CountDownLatch countDownLatch = new CountDownLatch(EXECUTE_COUNT);
ExecutorService executorService = Executors.newCachedThreadPool();
for (int i = 0; i < EXECUTE_COUNT; i++) {
executorService.execute(() -> {
try {
semaphore.acquire();
try {
DateTime.parse("2023-03-15", formatter).toDate();
} catch (Exception e) {
System.out.println("线程:" + Thread.currentThread().getName() + " 格式化日期失败");
e.printStackTrace();
System.exit(1);
}
semaphore.release();
} catch (InterruptedException e) {
System.out.println("信号量发生错误");
e.printStackTrace();
System.exit(1);
}
countDownLatch.countDown();
});
}
countDownLatch.await();
executorService.shutdown();
System.out.println("所有线程格式化日期成功");
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
注意
DateTime类是org.joda.time包下的类,DateTimeFormat类和DateTimeFormatter类都是org.joda.time.format包下的类。
使用joda-time库来处理日期的格式化操作运行效率比较高,推荐在高并发业务场景的生产环境使用。
综上所述
在解决SimpleDateFormat类的线程安全问题的几种方案中,局部变量法由于线程每次执行格式化时间时,都会创建SimpleDateFormat类的对象,这会导致创建大量的SimpleDateFormat对象,浪费运行空间和消耗服务器的性能,因为JVM创建销毁对象是要耗费性能的。所以,不推荐在高并发要求的生产环境使用。
synchronized锁方式和Lock锁方式在处理问题的本质上是一致的,通过加锁的方式,使同一时刻只能有一个线程执行格式化日期和时间的操作。这种方式虽然减少了SimpleDateFormat对象的创建,但是由于同步锁的存在,导致性能下降,所以,不推荐在高并发要求的生产环境使用。
ThreadLocal通过保存各个线程的SimpleDateFormat类对象的副本,使每个线程在运行时,各自使用自身绑定的SimpleDateFormat对象,互不干扰,执行性能比较高,推荐在高并发的生产环境使用。
DateTimeFormatter是Java 8中提供的处理日期和时间的类,DateTimeFormatter类本身就是线程安全的,经压测,DateTimeFormatter类处理日期和时间的性能效果还不错,因此,推荐在高并发场景下使用。
joda-time是第三方处理日期和时间的类库,线程安全,性能经过高并发考研,推荐在高并发场景下使用。
# 深度解析ThreadPoolExecutor类源码
既然Java中支持以多线程的方式来执行相应的任务,但为什么在JDK1.5中又提供了线程池技术呢?
提起Java中的线程池技术,在很多框架和异步处理中间件中都有涉及,而且性能经受起了长久的考验。可以说,Java的线程池技术是Java最核心的技术之一,在Java的高并发领域中,Java的线程池技术是一个永远绕不开的话题。下面就来简单说下线程池与ThreadPoolExecutor类。
# Thread直接创建线程的弊端
- 每次
new Thread()新建对象,性能差; - 线程缺乏统一管理,可能无限制新建线程,相互竞争,有可能占用过多系统资源导致死机或OOM。
- 缺少更多的功能,如更多执行、定期执行、线程中断。
# 线程池的好处
- 重用存在的线程,减少对象创建、消亡的开销,性能佳;
- 可以有效控制最大并发线程数,提高系统资源利用率,同时可以避免过多资源竞争,避免阻塞;
- 提供定时执行、定期执行、单线程、并发数控制等功能;
- 提供支持线程池监控的方法,可对线程池的资源进行实时监控。
# 线程池
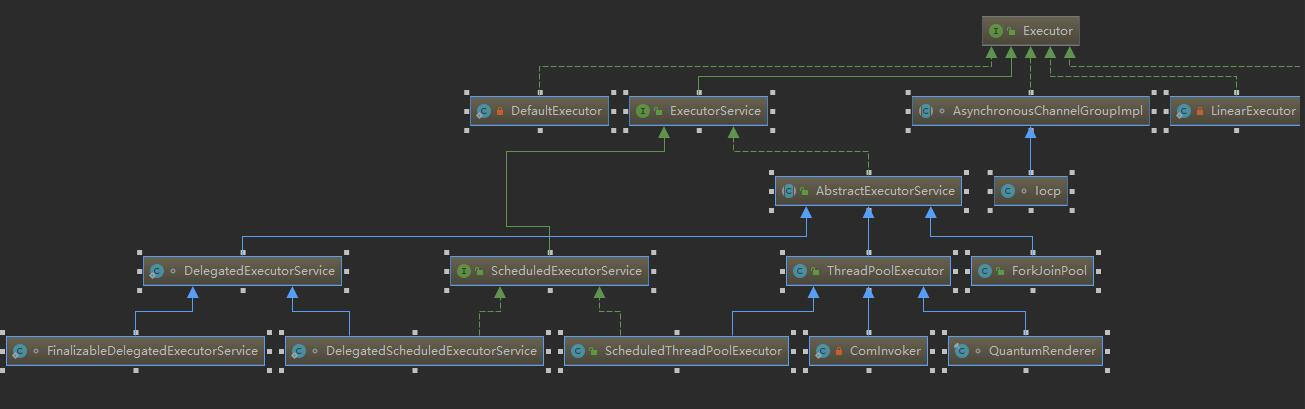
- 线程池类结构关系
线程池中的一些接口和类的结构关系如下图所示。
创建线程池常用的类--Executors
Executors.newCachedThreadPool: 创建一个可缓存的线程池,如果线程池的大小超过了需要,可以灵活回收空闲线程,如果没有可回收线程,则新建线程;Executors.newFixedThreadPool: 创建一个定长的线程池,可以控制线程的最大并发数,超出的线程会在队列中等待;Executors.newScheduledThreadPool: 创建一个定长的线程池,支持定时、周期性的任务执行;Executors.newSingleThreadExecutor: 创建一个单线程化的线程池,使用一个唯一的工作线程执行任务,保证所有任务按照指定顺序(先入先出或者优先级)执行;Executors.newSingleThreadScheduledExecutor: 创建一个单线程化的线程池,支持定时、周期性的任务执行;Executors.newWorkStealingPool: 创建一个具有并行级别的work-stealing线程池。
线程池实例的几种状态
- RUNNING:运行状态,能接收新提交的任务,并且也能处理阻塞队列中的任务;
- SHUTDOWN: 关闭状态,不能再接收新提交的任务,但是可以处理阻塞队列中已经保存的任务,当线程池处于**RUNNING*状态时,调用
shutdown()方法会使线程池进入该状态; - STOP:不能接收新任务,也不能处理阻塞队列中已经保存的任务,会中断正在处理任务的线程,如果线程池处于RUNNING或SHUTDOWN状态,调用
shutdownNow()方法,会使线程池进入该状态; - TIDYING:如果所有的任务都已经终止,有效线程数为0(阻塞队列为空,线程池中的工作线程数量为0),线程池就会进入该状态;
- TERMINATED:处于TIDYING状态的线程池调用
terminated()方法,会使用线程池进入该状态。
注意
不需要对线程池的状态做特殊的处理,线程池的状态是线程池内部根据方法自行定义和处理的。
- 合理配置线程的一些建议
- CPU密集型任务,就需要尽量压榨CPU,参考值可以设置为NCPU+1(CPU的数量加1);
- IO密集型任务,参考值可以设置为2×NCPU(CPU数量乘以2)。
# 线程池最核心的类之一ThreadPoolExecutor
- 构造方法
ThreadPoolExecutor参数最多的构造方法如下:
public ThreadPoolExecutor(
int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit;
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExcutionHandler rejectHandler
)
2
3
4
5
6
7
8
9
其他的构造方法都是调用的这个构造方法来实例化对象,可以说,分析这个方法之后,其他的构造方法也明白怎么回事。
注意
为了更加深入的分析ThreadPoolExecutor类的构造方法,会适当调整参数的顺序进行解析,以便于大家更能深入的理解ThreadPoolExecutor构造方法中每个参数的作用。
上述构造方法接收如下参数进行初始化:
corePoolSize: 核心线程数量;maximumPoolSize: 最大线程数;workQueue: 阻塞队列,存储等待执行的任务,很重要,会对线程池运行过程中产生重大影响。
其中,上述三个参数的关系如下所示:
- 如果运行的线程数小于
corePoolSize,直接创建新线程处理任务,即使线程池中的其他线程是空闲的; - 如果运行的线程数大于等于
corePoolSize,并且小于maximumPoolSize,此时,只有当workQueue满时,才会创建新的线程处理任务; - 如果设置的
corePoolSize与maximumPoolSize相同,那么创建的线程池大小是固定的,此时,如果有新任务提交,并且workQueue没有满时,就把请求放入到workQueue中,等待空闲的线程,从workQueue中取出任务进行处理; - 如果运行的线程数量大于
maximumPoolSize,同时,workQueue已经满了,会通过拒绝策略参数rejectHandler来指定处理策略。
根据上述三个参数的配置,线程池会对任务进行如下处理方式:当提交一个新的任务到线程池时,线程池会根据当前线程池中正在运行的线程数量来决定该任务的处理方式。处理方式总共有三种:直接切换、使用无限队列、使用有界队列。
- 直接切换常用的队列就是
SynchronousQueue; - 使用无限队列就是使用基于链表的队列,比如:
LinkedBlockingQueue,如果使用这种方式,线程池中创建的最大线程数就是corePoolSize,此时maximumPoolSize不会起作用。当线程池中所有的核心线程都是运行状态时,提交新任务,就会放入等待队列中; - 使用有界队列使用的是
ArrayBlockingQueue,使用这种方式可以将线程池的最大线程数量限制为maximumPoolSize,可以降低资源的消耗。但是,这种方式使得线程池对线程的调度更困难,因为线程池和队列的容量都是有限的。
根据上面三个参数,我们可以简单得出如何降低系统资源消耗的一些措施:
- 如果想降低系统资源的消耗,包括CPU使用率,操作系统资源的消耗,上下文环境切换的开销等,可以设置一个较大的队列容量和较小的线程池容量。这样,会降低线程处理任务的吞吐量;
- 如果提交的任务经常发生阻塞,可以考虑调用设置最大线程数的方法,重新设置线程池最大线程数。如果队列的容量设置的较小,通常需要将线程池的容量设置的大一些,这样,CPU的使用率会高些。如果线程池的容量设置过大,并发量就会增加,则需要考虑线程调度的问题,反而可能会降低处理任务的吞吐量。
接下来,我们继续看ThreadPoolExecutor的构造方法的参数。
4. keepAliveTime: 线程没有任务执行时最多保持多久时间终止,当线程池中的线程数量大于corePooSize时,如果此时没有新的任务提交,核心线程外的线程不会立即销毁,需要等待,直到等待的事件超过了keepAliveTime就会终止。
5. unit: keepAliveTime的事件单位
6. threadFactory: 线程工厂,用来创建线程,默认会提供一个默认的工厂来创建线程,当使用默认的工厂来创建线程时,会使新创建的线程具有相同的优先级,并且时非守护的线程,同时也设置了线程的名称;
7. rejectHandler: 拒绝处理任务时的策略,如果workQueue阻塞队列满了,并且没有空闲的线程池,此时,继续提交任务,需要采取一种策略来处理这个任务。
线程池总共提供了四种策略:
- 直接抛出异常,这也是默认的策略,实现类为
AbortPolicy; - 用调用者所在的线程来执行任务,实现类为
CallerRunsPolicy; - 丢弃队列中最靠前的任务并执行当前任务,实现类为
DiscardOldestPolicy; - 直接丢弃当前任务,实现类为
DiscardPolicy。
ThreadPoolExecutor提供的启动和停止任务的方法
execute(): 提交任务,交给线程池执行;submit(): 提交任务,能够返回执行结果execute + Future;shutdown(): 关闭线程池,等待任务都执行完;shutdownNow(): 立即关闭线程池,不等待任务执行完。
ThreadPoolExecutor提供的适用于监控的方法
getTaskCount(): 线程池已执行和未执行的任务总数;getCompletedTaskCount(): 已完成的任务数量;getPoolSize(): 线程池当前的线程数量;getCorePoolSize(): 线程池核心线程数;getActiveCount(): 当前线程池中正在执行任务的线程数量。
# 深度解析线程池中重要的顶层接口和抽象类
前面我们从整体上介绍了Java的线程池,如果细细品味线程池的底层源码实现,会发现整个线程池体系的设计是非常优雅的!这些代码的设计值得我们去细细品味和研究,从中学习优雅代码的设计规范,形成自己的设计思想。
# 接口和抽象类总览
线程池中提供的重要的接口和抽象类,基本上就是如下图所示的接口和类:

接口与类的简单说明:
Executor接口:这个接口也是整个线程池中最顶层的接口,提供了一个无返回值的提交任务的方法;ExecutorService接口:派生自Executor接口,扩展了很多功能,例如,关闭线程池,提交任务并返回结果数据,唤醒线程池中的任务等;AbstractExecutorService抽象类:派生自ExecutorService接口,实现了几个非常重要的方法,供子类进行调用;ScheduledExecutorService定时任务接口,派生自ExecutorService接口,拥有ExecutorService接口定义的全部方法,并扩展了定时任务相关的方法。
# Executor接口
Executor接口的源码如下:
public interface Executor {
// 提交运行任务,参数为Runnable接口对象,无返回值
void execute(Runnable command);
}
2
3
4
从源码可以看出,Executor接口非常简单,只提供了一个无返回值的提交任务的execute(Runnable)方法。
由于这个接口过于简单,我们无法得知线程池的执行结果数据,如果我们不再使用线程池,也无法通过Executor接口来关闭线程池。此时,我们就需要ExecutorService接口的支持了。
# ExecutorService接口
ExecutorService接口是非定时任务类线程池的核心接口,通过ExecutorService接口能够向线程池中提交任务(支持有返回结果和无返回结果两种方式)、关闭线程池、唤醒线程池中的任务等。ExecutorService接口源码如下:
package java.util.concurrent;
import java.util.List;
import java.util.Collection;
public interface ExecutorService extends Executor {
// 关闭线程池,线程池中不再接受新提交的任务,但是之前提交的任务继续运行,直到完成
void shutdown();
// 关闭线程池,线程池中不再接受新提交的任务,会尝试停止线程池中正在执行的任务。
List<Runnable> shutdownNow();
// 判断线程池是否已经关闭
boolean isShutdown();
// 判断线程池中的所有任务是否结束,只有在调用shutdown或shutdownNow方法之后调用此方法才会返回true
boolean isTerminated();
// 等待线程池中的所有任务执行结束,并设置超时时间
boolean awaitTermination(long timeout, TimeUnit unit) throws InterruptedException;
// 提交一个Callable接口类型的任务,返回一个Future类型的结果
<T> Future<T> submit(Callable<T> task);
// 提交一个Callable接口类型的任务,并且给定一个泛型类型的接收结果数据参数,返回一个Future类型的结果
<T> Future<T> submit(Runnable task, T result);
// 提交一个Runnable接口类型的任务,返回一个Future类型的结果
Future<?> submit(Runnable task);
// 批量提交任务并获得它们的Future,Task列表与Future列表一一对应
<T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks) throws InterruptedException;
// 批量提交任务并获得它们的future,并限定处理所有任务的时间
<T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks, long timeout, TimeUnit unit) throws InterruptedException;
// 批量提交任务并获得一个已经成功执行的任务的结果
<T> T invokeAny(Collection<? extends Callable<T>> tasks) throws InterruptedException, ExecutionException;
// 批量提交任务并获得一个已经成功执行的任务的结果,并限定处理任务的时间
<T> T invokeAny(Collection<? extends Callable<T>> tasks, long timeout, TimeUnit unit) throws InterruptedException,
ExecutionException, TimeoutException;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
# AbstractExecutorService抽象类
AbstractExecutorService类是一个抽象类,派生自ExecutorService接口,在其基础上实现了几个比较实用的方法,提供给子类进行调用。可以在java.util.concurrent包下查看完整的AbstractExecutorService类的源码,这里,我们将源码进行拆解讲解:
newTaskFor方法
protected <T> RunnableFuture<T> newTasksFor(Runnable runnable, T value) {
return new FutureTask<T>(runnable, value);
}
protected <T> RunnableFuture<T> newTaskFor(Callable<T> callable) {
return new FutureTask<T>(callable);
}
2
3
4
5
6
7
RunnableFuture类用于获取执行结果,在实际使用时,我们经常使用的是它的子类FutureTask,newTaskFor方法的作用就是将任务封装成FutureTask对象,后续将FutureTask对象提交到线程池。
doInvokeAny方法
private <T> T doInvokeAny(Collection<? extends Callable<T>> tasks, boolean timed, long nanos) throws
InterruptedException, ExecutionException, TimeoutException {
// 提交的任务为空,抛出空指针异常
if (tasks == null)
throw new NullPointerException();
// 记录待执行的任务的剩余数量
int ntasks = tasks.size();
// 任务集合中的数据为空,抛出非法参数异常
if (ntasks == 0)
throw new IllegalArgumentException();
ArrayList<Future<T>> futures = new ArrayList<Future<T>>(ntasks);
// 以当前实例对象作为参数构建ExecutorCompletionService对象
// ExecutorCompletionService负责执行任务,后面调用poll返回第一个执行结果
ExecutorCompletionService<T> ecs = new ExecutorCompletionService<T>(this);
try {
// 记录可能抛出的执行异常
ExecutionException ee = null;
// 初始化超时时间
final long deadline = timed ? System.nanoTime() + nanos : 0L;
Interator<? extends Callable<T>> it = tasks.iterator();
// 提交任务,并将返回的结果数据添加到futures集合中
// 提交一个任务主要是确保在进入循环之前开始一个任务
futures.add(ecs.submit(it.next()));
--ntasks;
// 记录正在执行的任务数量
int active = 1;
for (;;) {
// 从完成任务的BlockingQueue队列中获取并移除下一个将要完成的任务的结果
// 如果BlockingQueue队列中的数据为空,返回null
// 这里的poll()方法时非阻塞方法
Future<T> f = ecs.poll();
// 获取的结果为空
if (f == null) {
// 集合中仍有未执行的任务数量
if (ntasks > 0) {
// 未执行的任务数量减1
--ntasks;
// 提交完成并将结果添加到futures集合中
futures.add(ecs.submit(it.next()));
// 正在执行的任务数量加1
++active;
}
// 所有任务执行完成,并且返回了结果数据,则退出循环
// 之所以处理active为0的情况,是因为poll()方法是非阻塞方法,可能导致未返回结果时active为0
else if (active == 0)
break;
// 如果timed为true,则执行获取结果数据时设置超时时间,也就是超时获取结果表示
else if (timed) {
f = ecs.poll(nanos, TimeUnit.NANOSECONDS);
if (f == null)
throw new TimeoutException();
nanos = deadline - System.nanoTime();
}
// 没有设置超时,并且所有任务都被提交了,则一直阻塞,直到返回一个执行结果
else
f = ecs.take();
}
// 获取到执行结果,则将正在执行的任务减1,从Future中获取结果并返回
if (f != null) {
--active;
try {
return f.get();
} catch (ExecutionException eex) {
ee = eex;
} catch (RuntimeException rex) {
ee = new ExecutionException(rex);
}
}
}
if (ee == null)
ee = new ExecutionException();
throw ee;
} finally {
// 如果从所有执行的任务重获取到一个结果数据,则取消所有执行的任务,不再向下执行
for (int i = 0, size = futures.size(); i< size; i++)
futures.get(i).cancel(true);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
这个方法是批量执行线程池的任务,最终返回一个结果数据的核心方法,通过源码分析,可以发现,这个方法只要获取到一个结果数据,就会取消线程池中所有运行的任务,并将结果数据返回。
在上述代码中,看到提交任务使用的ExecutorCompletionService对象的submit方法,其源码如下:
public Future<V> submit(Callable<V> task) {
if (task == null) throw new NullPointerException();
RunnableFuture<V> f = newTaskFor(task);
executor.execute(new QueueingFuture(f));
return f;
}
public Future<V> submit(Runnable task, V result) {
if (task == null) throw new NullPointerException();
RunnableFuture<V> f = newTaskFor(task, result);
executor.execute(new QueueingFuture(f));
return f;
}
2
3
4
5
6
7
8
9
10
11
12
13
可以看到,ExecutorCompletionService类中的submit方法本质上调用的还是Executor接口的execute方法。
invokeAny方法
public <T> T invokeAny(Collection<? extends Callable<T>> tasks) throws InterruptedException, ExecutionException {
try {
return doInvokeAny(tasks, false, 0);
} catch (TimeoutException cannotHappen) {
assert false;
return null;
}
}
public <T> T invokeAny(Collection<? extends Callable<T>> tasks, long timeout, TimeUnit unit)
throws InterruptedException, ExecutionException, TimeoutException {
return doInvokeAny(tasks, true, unit.toNanos(timeout));
}
2
3
4
5
6
7
8
9
10
11
12
13
这两个invokeAny方法本质上都是在调用doInvokeAny()方法,在线程池中提交多个任务,只要返回一个结果数据即可。
看代码不是很清晰,这里举例如下,在使用线程池的时候,可能会启动多个线程去执行各自的任务,比如线程A负责task_a,线程B负责task_b,这样可以大规模提升系统处理任务的速度,如果我们希望其中一个线程执行完成返回结果数据时立即返回,而不需要再让其他线程继续执行任务,此时,就可以使用invokeAny方法。
invokeAll方法
public <T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks) throws InterruptedException {
if (tasks == null)
throw new NullPointerException();
ArrayList<Future<T>> futures = new ArrayList<Future<T>>(tasks.size());
// 标识所有任务是否完成
boolean done = false;
try {
// 遍历所有任务
for (Callable<T> t : tasks) {
// 将每个任务封装成RunnableFuture对象提交任务
RunnableFuture<T> f = newTaskFor(t);
// 将结果数据添加到futures集合中
futures.add(f);
// 执行任务
execute(f);
}
// 遍历结果数据集合
for (int i = 0, size = futures.size(); i < size; i++) {
Future<T> f = futures.get(i);
// 任务没有完成
if (!f.isDone()) {
try {
// 阻塞等待任务完成并返回结果
f.get();
} catch (CancellationException ignore) {
} catch (ExecutionException ignore) {
}
}
}
// 任务完成(不管是正常结束还是异常完成)
done = true;
// 返回结果数据集合
return futures;
} finally {
// 如果发生中断异常InterruptedException,则取消已经提交的任务
if (!done)
for (int i = 0, size = futures.size(); i < size; i++)
futures.get(i).cancel(true);
}
}
public <T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks, long timeout, TimeUnit unit)
throws InterruptedException {
if (tasks == null)
throw new NullPointerException();
long nanos = unit.toNanos(timeout);
ArrayList<Future<T>> futures = new ArrayList<Future<T>>(tasks.size());
boolean done = false;
try {
for (Callable<T> t : tasks)
futures.add(newTaskFor(t));
final long deadline = System.nanoTime() + nanos;
final int size = futures.size();
for (int i = 0; i < size; i++) {
execute((Runnable)futures.get(i));
// 在添加执行任务时超时判断,如果超时则立刻返回futures集合
nanos = deadline - System.nanoTime();
if (nanos <= 0L)
return futures;
}
// 遍历所有任务
for (int i = 0; i < size; i++) {
Future<T> f = futures.get(i);
if (!f.isDone()) {
// 对结果进行判断时进行超时判断
if (nanos <= 0L)
return futures;
try {
f.get(nanos, TimeUnit.NANOSECONDS);
} catch (CancellationException ignore) {
} catch (ExecutionException ignore) {
} catch (TimeoutException toe) {
return futures;
}
// 充值任务的超时时间
nanos = deadline - System.nanoTime();
}
}
done = true;
return futures;
} finally {
if (!done)
for (int i = 0, size = futures.size(); i < size; i++)
futures.get(i).cancel(true);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
invokeAll方法同样实现了无超时时间设置和有超时时间设置的逻辑。
无超时时间设置的invokeAll方法总体逻辑为:将所有任务封装为RunnableFuture对象,调用execute方法执行任务,将返回的结果数据添加到futures集合,之后对futures集合进行遍历判断,检测任务是否完成,如果没有完成,则调用get方法阻塞任务,直到返回结果数据,此时会忽略异常。最终在finally代码块中对所有任务是否完成的标识进行判断,如果存在未完成的任务,则取消已经提交的任务。
有超时设置的invokeAll方法总体逻辑与无超时时间设置的invokeAll方法总体逻辑基本相同,只是在两个地方添加了超时的逻辑判断。一个是在添加执行任务时进行超时判断,如果超时,则立刻返回futures集合;另一个是每次对结果数据进行判断时添加了超时处理逻辑。
invokeAll方法中本质上还是调用Executor接口的execute方法来提交任务。
submit方法
submit方法的逻辑比较简单,就是将任务封装成RunnableFuture对象并提交,执行任务后返回Future结果数据,如下:
public Future<?> submit(Runnable task) {
if (task == null) throw new NullPointerException();
RunnableFuture<Void> ftask = newTaskFor(task, null);
execute(ftask);
return ftask;
}
public <T> Future<T> submit(Runnable task, T result) {
if (task == null) throw new NullPointerException();
RunnableFuture<T> ftask = newTaskFor(task, result);
execute(ftask);
return ftask;
}
public <T> Future<T> submit(Callable<T> task) {
if (task == null) throw new NullPointerException();
RunnableFuture<T> ftask = newTaskFor(task);
execute(ftask);
return ftask;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
从源码中可以看出submit方法提交任务时,本质上还是调用的Executor接口的execute方法。
综上所述
在非定时任务类的线程池中提交任务时,本质上都是调用的Executor接口的execute方法。
# ScheduledExecutorService接口
ScheduledExecutorService接口派生自ExecutorService接口,继承了ExecutorService接口的所有功能,并提供了定时处理任务的能力,ScheduledExecutorService接口的源码如下:
package java.util.concurrent;
public interface ScheduledExecutorService extends ExecutorService {
// 延时delay时间来执行command任务,只执行一次
public ScheduledFuture<?> schedule(Runnable command, long delay, TimeUnit unit);
// 延时delay时间来执行callable任务,只执行一次
public <V> ScheduledFuture<V> schedule(Callable<V> callable, long delay, TimeUnit unit);
// 延时initialDelay时间首次执行command任务,之后每隔period时间执行一次
public ScheduledFuture<?> schedulAtFixedRate(Runnable command, long initialDelay, long period, TimeUnit unit);
// 延时initialDelay时间首次执行command任务,之后每延时delay时间执行一次
public ScheduledFuture<?> scheduleWithFixedDelay(Runnable command, long initialDelay, long delay, TimeUnit unit);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
至此,已经分析了线程池体系中重要的顶层接口和抽象类。
通过对这些顶层接口和抽象类的分析,我们需要从中感悟并体会软件开发中的抽象思维,深入理解抽象思维在具体编码中的实现,最终,形成自己的编程思维,运用到实际的项目中,这也就是我们能够从源码中所能学到的众多细节之一。这也是高级或资深工程师和架构师必须了解源码细节的原因之一。
# 从源码角度分析创建线程池有哪些方式
# 使用Executors工具类创建线程池
在创建线程池时,初学者用的最多的就是Executors这个工具类,而使用这个工具类创建线程池时非常简单,不需要关注太多线程池细节,只需要传入必要的参数即可。Executors工具类提供了几种创建线程池的方法,如下:
Executors.newCachedThreadPool: 创建一个可缓存的线程池,如果线程池的大小超过了需要,可以灵活回收空闲线程,如果没有可回收线程,则新建线程;Executors.newFixedThreadPool: 创建一个定长的线程池,可以控制线程的最大并发数,超出的线程会在队列中等待;Executors.newScheduledThreadPool: 创建一个定长的线程池,支持定时、周期性的任务执行Executors.newSingleThreadExecutor: 创建一个单线程化的线程池,使用一个唯一的工作线程执行任务,保证所有任务按照指定顺序(先入先出或者优先级)执行;Executors.newSingleThreadScheduledExecutor: 创建一个单线程化的线程池,支持定时、周期性的任务执行;Executors.newWorkStealingPool: 创建一个具有并行级别的work-stealing线程池。
其中,Executors.newWorkStealingPool方法是Java 8中新增的创建线程池的方法,它能够为线程池设置并行级别,具有更高的并发度和性能。除了此方法外,其他创建线程池的方法本质上调用的是ThreadPoolExecutor类的构造方法。
Executors.newWorkStealingPool();
Executors.newCachedThreadPool();
Executors.newScheduledThreadPool();
2
3
# 使用ThreadPoolExecutor类创建线程池
从代码结构上看ThreadPoolExecutor类继承自AbstractExecutorService,也就是说,ThreadPoolExecutor类具有AbstractExecutorService类的全部功能。
既然Executors工具类中创建线程池大部分调用的都是ThreadPoolExecutor类的构造方法,那么我们也可以直接调用其构造方法来创建线程池。
public ThreadPoolExecutor(
int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue
) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue, Executors.defaultThreadFactory, defaultHandler);
}
public ThreadPoolExecutor(
int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory
) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue, threadFactory, defaultHandler);
}
public ThreadPoolExecutor(
int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
RejectedExecutionHandler handler
) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue, Executors.defaultThreadFactory(), handler);
}
public ThreadPoolExecutor(
int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler
) {
if (corePoolSize < 0 || maximumPoolSize <= 0 || keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.acc = System.getSecurityManager() == null ? null : AccessController.getContext();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
大家可以自行调用ThreadPoolExecutor类的构造方法来创建线程池,如:
new ThreadPoolExecutor(0, Integer.MAX_VALUE, 60L, TimeUnit.SECONDS, new SynchronousQueue<Runnable>());
# 使用ForkJoinPool类创建线程池
在Java8的Executors工具类中,新增了如下创建线程池的方法
public static ExecutorService newWorkStealingPool(int parallelism) {
return new ForkJoinPool(parallelism, ForkJoinPool.defaultForkJoinWorkerThreadFactory, null, true);
}
public static ExecutorService newWorkStealingPool() {
return new ForkJoinPool(Runtime.getRuntime().availableProcessors(),
ForkJoinPool.defaultForkJoinWorkerThreadFactory, null, true);
}
2
3
4
5
6
7
8
从源代码可以看到,本质上调用的是ForkJoinPool类的构造方法类创建线程池,而从代码结构上来看ForkJoinPool类继承自AbstractExecutorService抽象类。
public ForkJoinPool() {
this(Math.min(MAX_CAP, Runtime.getRuntime().availableProcessors()), defaultForkJoinWorkerThreadFactory, null, false);
}
public ForkJoinPool(int parallelism) {
this(parallelism, defaultForkJoinWorkerThreadFactory, null, false);
}
public ForkJoinPool(int parallelism, ForkJoinWorkerThreadFactory factory, UncaughtExceptionHandler handler,
boolean asyncMode) {
this(checkParallelism(parallelism), checkFactory(factory), handler, asyncMode ? FIFO_QUEUE : LIFO_QUEUE,
"ForkJoinPool-" + nextPoolId() + "-worker-");
checkPermission();
}
private ForkJoinPool(int parallelism, ForkJoinWorkerThreadFactory factory, UncaughtExceptionHandler handler,
int mode, String workerNamePrefix) {
this.workerNamePrefix = workerNamePrefix;
this.factory = factory;
this.ueh = handler;
this.config = (parallelism & SMASK) | mode;
long np = (long)(-parallelism); // offset ctl counts
this.ctl = ((np << AC_SHIFT) & AC_MASK) | ((np << TC_SHIFT) & TC_MASK);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
各参数的含义如下:
parallelism: 并发级别;factory: 创建线程的工厂类对象;handler: 当线程池中的线程抛出未捕获的异常时,统一使用UncaughtExceptionHandler对象处理;mode: 取值为FIFO_QUEUE或者LIFO_QUEUE;workerNamePrefix: 执行任务的线程名称的前缀。
new ForkJoinPool();
new ForkJoinPool(Runtime.getRuntime().availableProcessors(), ForkJoinPool.defaultForkJoinWorkerThreadFactory, null true);
2
# 使用ScheduledThreadPoolExecutor类创建线程池
在Executors工具类中存在如下方法类创建线程池。
public static ScheduledExecutorService newSingleThreadScheduledExecutor() {
return new DelegatedScheduledExecutorService(new ScheduledThreadPoolExecutor(1));
}
public static ScheduledExecutorService newSingleThreadScheduledExecutor(ThreadFactory threadFactory) {
return new DelegatedScheduledExecutorService(new ScheduledThreadPoolExecutor(1, threadFactory));
}
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) {
return new ScheduledThreadPoolExecutor(corePoolSize);
}
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize, ThreadFactory threadFactory) {
return new ScheduledThreadPoolExecutor(corePoolSize, threadFactory);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
从源码来看,这几个方法本质上调用的都是ScheduledThreadPoolExecutor类的构造方法:
public ScheduledThreadPoolExecutor(int corePoolSize) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS, new DelayedWorkQueue());
}
public ScheduledThreadPoolExecutor(int corePoolSize, ThreadFactory threadFactory) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS, new DelayedWorkQueue(), threadFactory);
}
public ScheduledThreadPoolExecutor(int corePoolSize, RejectedExecutionHandler handler) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS, new DelayedWorkQueue(), handler);
}
public ScheduledThreadPoolExecutor(int corePoolSize, ThreadFactory threadFactory, RejectedExecutionHandler handler) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS, new DelayedWorkQueue(), threadFactory, handler);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
ScheduledThreadPoolExecutor类继承自ThreadPoolExecutor类,本质上还是调用ThreadPoolExecutor类的构造方法,只不过此时传递的队列为DelayedWorkQueue。
new ScheduledThreadPoolExecutor(3);
# 通过源码深度解析ThreadPoolExecutor类是如何保证线程池正确运行的
# ThreadPoolExecutor类中的重要属性
- ctl相关的属性
AtomicInteger类型的常量ctl是贯穿线程池整个生命周期的重要属性,它是一个原子类对象,主要用来保存线程的数量和线程池的状态,如下:
// 主要用来保存线程数量和线程池的状态,高3位保存线程状态,低29位保存线程数量
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
// 线程池中线程的数量位数(32 - 3)
private static final int COUNT_BITS = Integer.SIZE - 3;
// 表示线程池中的最大线程数量
// 将数字1的二进制值向左移29位,再减去1
private static final int CAPACITY = (1 << COUNT_BITS) - 1;
// 线程池的运行状态
private static final int RUNNING = -1 << COUNT_BITS;
private static final int SHUTDOWN = 0 << COUNT_BITS;
private static final int STOP = 1 << COUNT_BITS;
private static final int TIDYING = 2 << COUNT_BITS;
private static final int TERMINATED = 3 << COUNT_BITS;
// 获取线程状态
private static int runStateOf(int c) { return c & ~CAPACITY; }
// 获取线程数量
private static int workerCountOf(int c) { return c & CAPACITY; }
private static int ctlOf(int rs, int wc) { return rs | wc; }
private static boolean runStateLessThan(int c, int s) {
return c < s;
}
private static boolean runStateAtLeast(int c, int s) {
return c >= s;
}
private static boolean isRunning(int c) {
return c < SHUTDOWN;
}
private boolean compareAndIncrementWorkerCount(int expect) {
return ctl.compareAndSet(expect, expect + 1);
}
private boolean compareAndDecrementWorkerCount(int expect) {
return ctl.compareAndSet(expect, expect - 1);
}
private void decrementWorkerCount() {
do {} while (!compareAndDecrementWorkerCount(ctl.get()));
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
对于线程池的各状态说明如下:
- RUNNING:运行状态,能接收新提交的任务,并且也能处理阻塞队列中的任务;
- SHUTDOWN: 关闭状态,不能再接收新提交的任务,但是可以处理阻塞队列中已经保存的任务,当线程池处于RUNNING状态时,调用
shutdown()方法会使线程池进入该状态; - STOP: 不能接收新任务,也不能处理阻塞队列中已经保存的任务,会中断正在处理任务的线程,如果线程池处于RUNNING或SHUTDOWN状态,调用
shutdownNow()方法,会使线程池进入该状态; - TIDYING: 如果所有的任务都已经终止,有效线程数为0(阻塞队列为空,线程池中的工作线程数量为0),线程池就会进入该状态;
- TERMINATED: 处于TIDYING状态的线程池调用
terminated()方法,会使用线程池进入该状态。
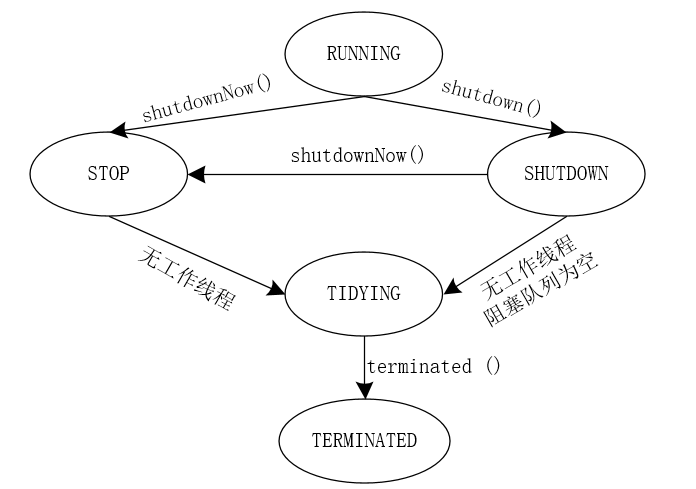
- RUNNING -> SHUTDOWN: 显示调用
shutdown()方法,或者隐式调用了finalize()方法; - (RUNNING or SHUTDOWN) -> STOP: 显式调用
shutdownNow()方法; - SHUTDOWN -> TIDYING: 当线程池和任务队列都为空的时候;
- STOP -> TIDYING: 当线程池为空的时候;
- TIDYING -> TERMINATED: 当
terminated() hook方法执行完成的时候。
- 其他重要属性
// 用于存放任务的阻塞队列
private final BlockingQueue<Runnable> workQueue;
// 可重入锁
private final ReentrantLock mainLock = new ReentrantLock();
// 存放线程池中线程的集合,访问这个集合时,必须获得mainLock锁
private final HashSet<Worker> workers = new HashSet<Worker>();
// 在锁内部阻塞等待条件完成
private final Condition termination = mainLock.newCondition();
// 线程工厂,以此来创建线程
private volatile ThreadFactory threadFactory;
// 拒绝策略
private volatile RejectedExecutionHandler handler;
// 默认的拒绝策略
private static final RejectedExecutionHandler defaultHandler = new AbortPolicy();
2
3
4
5
6
7
8
9
10
11
12
13
14
# ThreadPoolExecutor类中的重要内部类
在ThreadPoolExecutor类中存在对于线程池的执行至关重要的内部类,Worker内部类和拒绝策略内部类。
- Worker内部类
Worker类从源代码上看,实现了Runnable接口,说明其本质上是一个用来执行任务的线程,源码如下:
private final class Worker extends AbstractQueuedSynchronizer implements Runnable {
private static final long serialVersionUID = 6138294804551838833L;
// 真正执行任务的线程
final Thread thread;
// 第一个Runnable任务,如果在创建线程时指定了需要执行的第一个任务
// 则第一个任务会存放在此变量中,此变量也可以为null
// 如果为null,则线程启动后,通过getTask方法到BlockingQueue队列中获取任务
Runnable firstTask;
// 用于存放此线程完成的任务数,注意:使用了volatile关键字
volatile long completedTasks;
// Worker类唯一的构造方法,传递的firstTask可以为null
Worker(Runnable firstTask) {
// 防止在调用runWorker之前被中断
setState(-1);
this.firstTask = firstTask;
// 使用ThreadFactory来创建一个新的执行任务的线程
this.thread = getThreadFactory().newThread(this);
}
// 调用外部ThreadPoolExecutor类的runWorker方法执行任务
public void run() {
runWorker(this);
}
// 是否获取到锁
// state=0表示锁未被获取
// state=1表示锁被获取
protected boolean isHeldExclusively() {
return getState() != 0;
}
protected boolean tryAcquire(int unused) {
if (compareAndSetState(0, 1)) {
setExclusiveOwnerThread(Thread.currentThread());
return true;
}
return false;
}
protected boolean tryRelease(int unused) {
setExclusiveOwnerThread(null);
setState(0);
return true;
}
public void lock() { acquire(1); }
public boolean tryLock() { return tryAcquire(1); }
public void unlock() { release(1); }
public boolean isLocked() { return isHeldExclusively(); }
void interruptIfStarted() {
Thread t;
if (getState() >= 0 && (t = thread) != null && !t.isInterrupted()) {
try {
t.interrupt();
} catch (SecurityException ignore) {
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
在Worker类的构造方法中,可以看出,首相将同步状态state设置为-1,设置为-1是为了防止runWorker方法运行之前被中断。这是因为如果其他线程调用线程池的shutdownNow()方法时,如果Worker类中的state状态的值大于0,则会中断线程,如果state状态的值为-1,则不会中断线程。
Worker类实现了Runnable接口,需要重写run方法,而Worker的run方法本质上调用的是ThreadPoolExecutor类的runWorker方法,在runWorker方法中,会首先调用unlock方法,该方法会将state设置为0,所以这个时候调用shutdownNow方法就会中断当前线程,而这个时候已经进入了runWork方法,就不会在还没有执行runWorker方法的时候就中断线程。
- 拒绝策略内部类
在线程池中,如果workQueue阻塞队列满了,并且没有空闲的线程池,此时,继续提交任务,需要采取一种策略来处理这个任务。线程池提供了四种策略,如下:
- 直接抛出异常,这也是默认的策略,实现类为
AbortPolicy; - 用调用者所在的线程来执行任务,实现类为
CallerRunsPolicy; - 丢弃队列中最靠前的任务并执行当前任务,实现类为
DiscardOldestPolicy; - 直接丢弃当前任务,实现类为
DiscardPolicy。
源码如下:
public static class CallerRunsPolicy implements RejectedExecutionHandler {
public CallerRunsPolicy() {}
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (!e.isShutdown()) {
r.run();
}
}
}
public static class AbortPolicy implements RejectedExecutionHandler {
public AbortPolicy() {}
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
throw new RejectedExecutionException("Task " + r.toString() + " rejected from " + e.toString());
}
}
public static class DiscardPolicy implements RejectedExecutionHandler {
public DiscardPolicy() {}
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {}
}
public static class DiscardOldestPolicy implements RejectedExecutionHandler {
public DiscardOldestPolicy() {}
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (!e.isShutdown()) {
e.getQueue().poll();
e.execute(r);
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
当然也可以通过实现RejectedExecutionHandler接口,并重写RejectedExecutionHandler接口的rejectedException方法来自定义拒绝策略,在创建线程池时,调用ThreadPoolExecutor的构造方法,传入我们自己写的拒绝策略。
public class CustomPolicy implements RejectedExecutionHandler {
public CustomPolicy() {}
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (!e.isShutdown()) {
System.out.println("使用调用者所在的线程来执行任务");
r.run();
}
}
}
2
3
4
5
6
7
8
9
10
new ThreadPoolExecutor(0, Integer.MAX_VALUE, 60L, TimeUnit.SECONDS, new SynchronousQueue<Runnable>(),
Executors.defaultThreadFactory(), new CustomPolicy());
2
# 通过ThreadPoolExecutor类的源码深度解析线程池执行任务的核心流程
# 核心逻辑概述
ThreadPoolExecutor是Java线程池中最核心的类之一,它能够保证线程池按照正常的业务逻辑执行任务,并通过原子方式更新线程池每个阶段的状态。
ThreadPoolExecutor类中存在一个workers工作线程集合,用户可以向线程池中添加需要执行的任务,workers集合中的工作线程可以直接执行任务,或者从任务队列中获取任务后执行。ThreadPoolExecutor类中提供了整个线程池从创建到执行任务,再到消亡的整个流程方法。
在ThreadPoolExecutor类中,线程池的逻辑主要体现在execute(Runnable)方法,addWorker(Runnable, boolean)方法,addWorkerFailed(Worker)方法和拒绝策略上。
# execute(Runnable)方法
execute(Runnable)方法的作用是提交Runnable类型的任务到线程池中,其源码:
public void execute(Runnable command) {
// 如果提交的任务为空,则抛出空指针异常
if (command == null)
throw new NullPointerException();
// 获取线程池的状态和线程池中线程的数量
int c = ctl.get();
// 线程池中的线程数量小于corePoolSize的值
if (workerCountOf(c) < corePoolSize) {
// 重新开启线程执行任务
if (addWorker(command, true))
return;
c = ctl.get();
}
// 如果线程池处于RUNNING状态,则将任务添加到阻塞队列中
if (isRunning(c) && workQueue.offer(command)) {
// 再次获取线程池的状态和线程池中线程的数量,用于二次检查
int recheck = ctl.get();
// 如果线程池没有处于RUNNING状态,从队列中删除任务
if (!isRunning(recheck) && remove(command))
// 执行拒绝策略
reject(command);
// 如果线程池为空,则向线程池中添加一个线程
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
// 任务队列已满,则新增worker线程,如果新增线程失败,则执行拒绝策略
else if (!addWorker(command, false))
reject(command);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
整个任务的执行流程,可以简化为:
接下来,拆解execute(Runnable)方法,具体分析execute(Runnable)方法的执行逻辑。
- 线程池中的线程数是否小于
corePoolSize核心线程数,如果小于corePoolSize核心线程数,则向workers工作线程集合中添加一个核心线程执行任务,代码:
// 线程池中的线程数量小于corePoolSize的值
if (workerCountOf(c) < corePoolSize) {
// 重新开启线程执行任务
if (addWorker(command, true))
return;
c = ctl.get();
}
2
3
4
5
6
7
- 如果线程池中的线程数量大于
corePoolSize核心线程数,则判断当前线程池是否处于RUNNING状态,如果处于RUNNING状态,则添加任务到待执行的任务队列中,注意:这里向任务队列添加任务时,需要判断线程池是否处于RUNNING状态,只有线程池处于RUNNING状态时,才能向任务队列添加新任务。否则,会执行拒绝策略。代码如下:
if (isRunning(c) && workQueue.offer(command))
- 向任务队列中添加任务成功,由于其他线程可能会修改线程池的状态,所以这里需要对线程池进行二次检查,如果当前线程池的状态不再是RUNNING状态,则需要将添加的任务从任务队列中移除,执行后续的拒绝策略。如果当前线程池仍然处于RUNNING状态,则判断线程池是否为空,如果线程池中不存在任何线程,则新建一个线程添加到线程池中,如下:
// 再次获取线程池的状态和线程池中线程的数量,用于二次检查
int recheck = ctl.get();
// 如果线程池没有未处于RUNNING状态,从队列中删除任务
if (!isRunning(recheck) && remove(command))
// 执行拒绝策略
reject(command);
// 如果线程池为空,则向线程池中添加一个线程
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
2
3
4
5
6
7
8
9
- 如果在步骤三中向任务队列中添加任务失败,则尝试开启新的线程执行任务,此时,如果线程池中的线程数量已经大于最大线程数
maximumPoolSize,则不能再启动新线程。此时,表示线程池中的任务队列已满,并且线程池中的线程已满,需要执行拒绝策略,代码如下:
// 任务队列已满,则新增worker线程,如果新增线程失败,则执行拒绝策略
else if (!addWorker(command, false))
reject(command);
2
3
这里,我们将execute(Runnable)方法拆解,结合流程图来理解线程池中任务的执行流程就比较简单了。execute(Runnable)方法的逻辑基本上就是一般线程池的执行逻辑,理解了execute(Runnable)方法,就基本理解了线程池的执行逻辑。
# addWorker(Runnable, boolean)方法
总体上,addWorker(Runnable, boolean)方法可以分为三部分,第一部分是使用CAS安全的向线程池中添加工作线程;第二部分是创建新的工作线程;第三部分则是将任务通过安全的并发方式添加到workers中,并启动工作线程执行任务。
private boolean addWorker(Runnable firstTask, boolean core) {
// 标记重试的标识
retry:
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);
// 检查队列是否在某些特定的条件下为空
if (rs >= SHUTDOWN && !(rs == SHUTDOWN && firstTask == null && !workQueue.isEmpty()))
return false;
// 下面循环的主要作用为通过CAS方式增加线程的个数
for (;;) {
// 获取线程池中的线程数量
int wc = workerCountOf(c);
// 如果线程池中的线程数量超出限制,直接返回false
if (wc >= CAPACITY || wc >= (core ? corePoolSize : maximumPoolSize))
return false;
// 通过CAS方式向线程池新增线程数量
if (compareAndIncrementWorkerCount(c))
// 通过CAS方式保证只有一个线程执行成功,跳出最外层循环
break entry;
// 重新获取ctl的值
c = ctl.get();
// 如果CAS操作失败了则需要再内循环中重新尝试通过CAS新增线程数量
if (runStateOf(c) != rs)
continue retry;
}
}
// 跳出最外层for循环,说明通过CAS新增线程数量成功
// 此时创建新的工作线程
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
try {
// 将执行的任务封装成worker
w = new Worker(firstTask);
final Thread t = w.thread;
if (t != null) {
// 独占锁,保证操作workers时的同步
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
// 此处需要重新检查线程池状态
// 原因是在获得锁之前可能其他的线程改变了线程池的状态
int rs = runStateOf(ctl.get());
if (rs < SHUTDOWN || (rs == SHUTDOWN && firstTask == null)) {
if (t.isAlive())
throw new IllegalThreadsStateException();
// 向worker中添加新任务
workers.add(w);
int s = workers.size();
if (s > largestPoolSize)
largestPoolSize = s;
// 将是否添加了新任务的标识设置为true
workerAdded = true;
}
} finally {
// 释放独占锁
mainLock.unlock();
}
// 添加新任务成功,则启动线程执行任务
if (workerAdded) {
t.start();
// 将任务是否已经启动的标识设置为true
workerStarted = true;
}
}
} finally {
// 如果任务未启动或启动失败,则调用addWorkerFailed(Worker)方法
if (!workerStarted)
addWorkerFailed(w);
}
// 返回是否启动任务的标识
return workerStarted;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
# addWorkerFailed(Worker)方法
# 拒绝策略
# 通过源码深度分析线程池中Worker线程的执行流程
# Worker类分析
# runWorker(Worker)方法
# getTask()方法
# beforeExecute(Thread, Runnable)方法
# afterExecute(Runnable, Throwable)方法
# processWorkerExit(Worker, boolean)方法
# tryTerminate()方法
# terminated()方法
# 从源码角度深度解析线程池是如何实现优雅退出的
# shutdown()方法
# shutdownNow()方法
# awaitTermination(long, TimeUnit)方法
# 深入理解ScheduledThreadPoolExecutor与Timer的区别和简单示例
JDK1.5开始提供ScheduledThreadPoolExecutor类,ScheduledThreadPoolExecutor类继承ThreadPoolExecutor类重用线程池实现了任务的周期性调度功能。在JDK1.5之前,实现任务的周期性调度主要使用的是Timer类和TimerTask类。
# 二者的区别
- 线程角度
Timer是单线程模式,如果某个TimerTask任务的执行时间比较久,会影响到其他任务的调度执行;ScheduledThreadPoolExecutor是多线程模式,并且重用线程池,某个ScheduledFutureTask任务执行的时间比较久,不会影响到其他任务的调度执行。
- 系统时间敏感度
Timer调度是基于操作系统的绝对时间的,对操作系统的时间敏感,一旦操作系统的时间改变,则Timer的调度不再精确。ScheduledThreadPoolExecutor调度是基于相对时间的,不受操作系统时间改变的影响。
- 是否捕获异常
Timer不会捕获TimerTask抛出的异常,加上Timer又是单线程的,一旦某个调度任务出现异常,则整个线程就会终止,其他需要调度的任务也不再执行。ScheduledThreadPoolExecutor基于线程池来实现调度功能,某个任务抛出异常后,其他任务仍能正常执行。
- 任务是否具备优先级
Timer中执行的TimerTask任务整体上没有优先级的概念,只是按照系统的绝对时间来执行任务;ScheduledThreadPoolExecutor中执行的ScheduledFutureTask类实现了java.lang.Comparable接口和java.util.concurrent.Delayed接口,这也就说明了ScheduledFutureTask类中实现了两个非常重要的方法,一个是java.lang.Comparable接口的compareTo方法,一个是java.util.concurrent.Delayed接口的getDelay方法。在ScheduledFutureTask类中compareTo方法实现了任务的比较,距离下次执行的时间间隔短的任务的优先级比较高,而getDelay方法则能够返回距离下次任务执行的时间间隔。
- 是否支持对任务排序
Timer不支持对任务排序;ScheduledThreadPoolExecutor类中定义了一个静态内部类DelayedWorkQueue,DelayedWorkQueue类本质上是一个有序队列,为需要调度的每个任务按照距离下次执行时间间隔的大小来排序
- 能否获取返回的结果
Timer中执行的TimerTask类只是实现了java.lang.Runnable接口,无法从TimerTask中获取返回的结果ScheduledThreadPoolExecutor中执行的ScheduledFutureTask类继承了FutureTask,能够通过Future来获取返回的结果。
# 二者的简单示例
- Timer类简单示例
package com.ainsn.dandelion.thread;
import java.util.Timer;
import java.util.TimerTask;
/**
* 测试Timer
*
* @author sunyy
* @version 0.0.1
* @since 2023.3.17
*/
public class TimerTest {
public static void main(String[] args) throws InterruptedException {
Timer timer = new Timer();
timer.scheduleAtFixedRate(new TimerTask() {
@Override
public void run() {
System.out.println("测试Timer类");
}
}, 1000, 1000);
Thread.sleep(10000);
timer.cancel();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
- ScheduledThreadPoolExecutor类简单示例
package com.ainsn.dandelion.thread;
import java.util.concurrent.Executors;
import java.util.concurrent.ScheduledExecutorService;
import java.util.concurrent.TimeUnit;
/**
* 测试ScheduledThreadPoolExecutor
*
* @author sunyy
* @version 0.0.1
* @since 2023.3.17
*/
public class ScheduledThreadPoolExecutorTest {
public static void main(String[] args) throws InterruptedException {
ScheduledExecutorService executorService = Executors.newScheduledThreadPool(3);
executorService.scheduleAtFixedRate(new Runnable() {
@Override
public void run() {
System.out.println("测试ScheduledThreadPoolExecutor");
}
}, 1, 1, TimeUnit.SECONDS);
// 主线程休眠10秒
Thread.sleep(10000);
System.out.println("正在关闭线程池...");
// 关闭线程池
executorService.shutdown();
boolean isClosed;
// 等待线程终止
do {
isClosed = executorService.awaitTermination(1, TimeUnit.DAYS);
System.out.println("正在等待线程池中的任务执行完成");
} while(!isClosed);
System.out.println("所有线程执行结束,线程池关闭");
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
# 深度解析ScheduledThreadPoolExecutor类的源代码
# 构造方法
# schedule方法
# decorateTask方法
# scheduleAtFixedRate方法
# scheduleWithFixedDelay方法
# triggerTime方法
# overflowFree方法
# delayedExecute方法
# reExecutePeriodic方法
# onShutdown方法
# 深入理解Thread类源码
# Thread类的继承体系
由上图可出,Thread类实现了Runnable接口,而Runnable在JDK1.8中被@FunctionalInterface注解标记为函数式接口,Runnable接口在JDK1.8中的源代码如下:
@FunctionalInterface
public interface Runnable {
public abstract void run();
}
2
3
4
@Documented
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.TYPE)
public @interface FunctionalInterface {}
2
3
4
可以看到,@FunctionalInterface注解生命标记在Java类上,并在程序运行时生效。
# Thread类的源码剖析
- Thread类定义
public class Thread implements Runnable {}
- 加载本地资源
打开Thread类后,首先,会看到Thread类的最开始部分,定义了一个静态本地方法registerNatives(),这个方法主要用来注册一些本地系统的资源,并在静态代码块中调用这个本地方法
// 定义registerNatives()本地方法注册系统资源
private static native void registerNatives();
static {
// 在静态代码块中调用注册本地系统资源的方法
registerNatives();
}
2
3
4
5
6
- Thread中的成员变量
// 当前线程的名称
private volatile String name;
// 线程的优先级
private int priority;
private Thread threadQ;
private long eetop;
// 当前线程是否是单步线程
private boolean single_step;
// 当前线程是否在后台运行
private boolean daemon = false;
// Java虚拟机的状态
private boolean stillborn = false;
// 真正在线程中执行的任务
private Runnable target;
// 当前线程所在的线程组
private ThreadGroup group;
// 当前线程的类加载器
private ClassLoader contextClassLoader;
// 访问控制上下文
private AccessControlContext inheritedAccessControlContext;
// 为匿名线程生成名称的编号
private static int threadInitNumber;
// 与此线程相关的ThreadLocal,这个Map维护的是ThreadLocal类
ThreadLocal.ThreadLocalMap threadLocals = null;
// 与此相关的ThreadLocal
ThreadLocal.ThreadLocalMap inheritableThreadLocals = null;
// 当前线程请求的堆栈大小,如果为指定堆栈大小,则会交给JVM来处理
private long stackSize;
// 线程终止后存在的JVM私有状态
private long nativeParkEventPointer;
// 线程的id
private long tid;
// 用于生成线程id
private static long threadSeqNumber;
// 当前线程的状态,初始化为0, 代表当前线程还未启动
private volatile int threadStatus = 0;
// 由(私有)java.util.concurrent.locks.LockSupport.setBlocker设置
// 使用java.util.concurrent.locks.LockSupport.getBlocker访问
volatile Object parkBlocker;
// Interruptible接口中定义了interrupt方法,用来中断指定的线程
private volatile Interruptible blocker;
// 当前线程的内部锁
private final Object blockerLock = new Object();
// 线程拥有的最小优先级
public final static int MIN_PRIORITY = 1;
// 线程拥有的默认优先级
public final static int NORM_PRIORITY = 5;
// 线程拥有的最大优先级
public final static int MAX_PRIORITY = 10;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
从Thread类的成员变量,可以看出,Thread本质上不是一个任务,它是一个实实在在的线程对象,在Thread类中拥有一个Runnable类型的成员变量target,而这个target成员变量就是需要再Thread线程对象中执行的任务。
- 线程的状态定义
在Thread类的内部,定义了一个枚举State,如下
public enum State {
// 初始化状态
NEW,
// 可运行状态,此时的可运行包括运行中的和就绪状态
RUNNABLE,
// 线程阻塞状态
BLOCKED,
// 等待状态
WAITING,
// 超时等待状态
TIMED_WAITING,
// 线程终止状态
TERMINATED;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
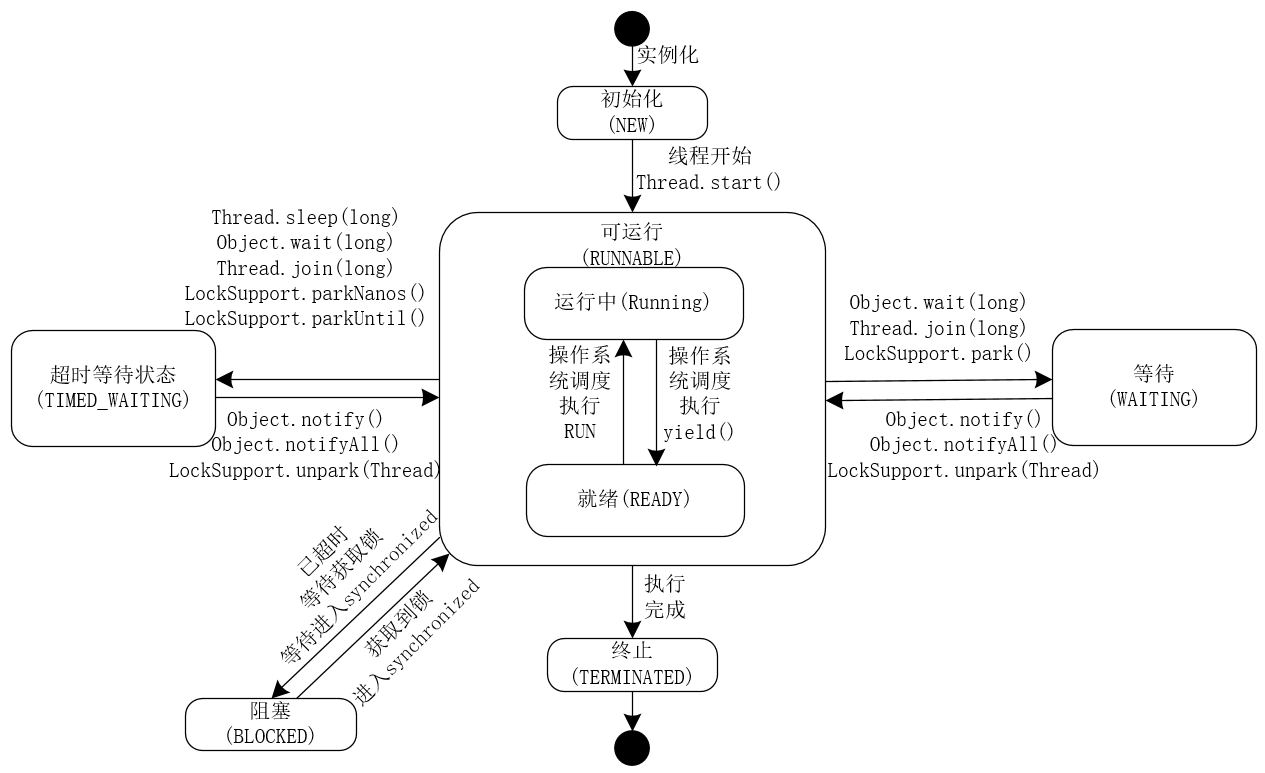
- NEW: 初始状态,线程被构建,但是还没有调用
start()方法; - RUNNABLE: 可运行状态,可运行状态可以包括:运行状态和就绪状态;
- BLOCKED: 阻塞状态,处于这个状态的线程需要等待其他线程释放锁或者等待进入
synchronized; - WAITING: 表示等待状态,处于该状态的线程需要等待其他线程对其进行通知或中断操作,进而进入下一个状态;
- TIME_WAITING: 超时等待状态,可以在一定的时间自行返回;
- TERMINATED: 终止状态,当前线程执行完毕。
- Thread类的构造方法
public Thread() {
init(null, null, "Thread-" + nextThreadNum(), 0);
}
public Thread(Runnable target) {
init(null, target, "Thread-" + nextThreadNum(), 0);
}
Thread(Runnable target, AccessControlContext acc) {
init(null, target, "Thread-" + nextThreadNum(), 0, acc, false);
}
public Thread(ThreadGroup group, Runnable target) {
init(group, target, "Thread-" + nextThreadNum(), 0);
}
public Thread(String name) {
init(null, null, name, 0);
}
public Thread(ThreadGroup group, String name) {
init(group, null, name, 0);
}
public Thread(Runnable target, String name) {
init(null, target, name, 0);
}
public Thread(ThreadGroup group, Runnable target, String name) {
init(group, target, name, 0);
}
public Thread(ThreadGroup group, Runnable target, String name, long stackSize) {
init(group, target, name, stackSize);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
- init()方法
private void init(ThreadGroup g, Runnable target, String name, long stackSize) {
init(g, target, name, stackSize, null, true);
}
private void init(ThreadGroup g, Runnable target, String name, long stackSize,
AccessControlContext acc, boolean inheritThreadLocals) {
// 线程的名称为空,抛出空指针异常
if (name == null) {
throw new NullPointerException("name cannot be null");
}
this.name = name;
Thread parent = currentThread();
// 获取线程安全管理器
SecurityManager security = System.getSecurityManager();
// 线程组为空
if (g == null) {
// 获取的线程安全管理器不为空
if (security != null) {
// 从线程安全管理器中后去一个线程分组
g = security.getThreadGroup();
}
// 线程分组为空,则从父线程获取
if (g == null) {
g = parent.getThreadGroup();
}
}
// 检查线程组的访问权限
g.checkAccess();
// 检查权限
if (security != null) {
if (isCCLOverridden(getClass())) {
security.checkPermission(SUBCLASS_IMPLEMENTATION_PERMISSION);
}
}
g.addUnstarted();
// 当前线程继承父线程的相关属性
this.group = g;
this.daemon = parent.isDaemon();
this.priority = parent.getPriority();
if (security == null || isCCLOverridden(parent.getClass()))
this.contextClassLoader = parent.getContextClassLoader;
else
this.contextClassLoader = parent.contextClassLoader;
this.inheritedAccessControlContext = acc != null ? acc : AccessController.getContext();
this.target = target;
setPriority(priority);
if (inheritThreadLocals && parent.inheritableThreadLocals != null)
this.inheritableThreadLocals = ThreadLocal.createInheritedMap(parent.inheritableThreadLocals);
/* Stash the specified stack size in case the VM cares */
this.stackSize = stackSize;
// 设置线程id
tid = nextThreadID();
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
Thread类中的构造方法是被创建Thread线程的线程调用的,此时,调用Thread的构造方法创建线程的线程就是父线程,在init()方法中,新创建的Thread线程会继承父线程的部分属性。
- run()方法
@Override
public void run() {
if (target != null) {
target.run();
}
}
2
3
4
5
6
可以看到,Thread类中的run()方法实现非常简单,只是调用了Runnable对象的run()方法。所以,真正的任务是运行在run()方法中的。
直接调用Runnable接口的run()方法不会创建新线程来执行任务,如果需要创建新线程执行任务,则需要调用Thread类的start()方法。
- start()方法
public synchronized void start() {
// 线程不是初始化状态,则直接抛出异常
if (threadStatus != 0)
throw new IllegalThreadStateException();
// 添加当前启动的线程到线程组
group.add(this);
// 标记线程是否已经启动
boolean started = false;
try {
// 调用本地方法启动线程
start0();
// 将线程是否启动标记为true
started = true;
} finally {
try {
// 线程未启动成功
if (!started) {
// 将线程在线程组里标记为启动失败
group.threadStartFailed(this);
}
} catch (Throwable ignore) {
/* do nothing. If start0 threw a Throwable then it will be passed up the call stack */
}
}
}
private native void start0();
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
从`start()`方法的源代码,可以看出
start()方法使用synchronized关键字修饰,说明start()方法是同步的,它会在启动线程前检查线程的状态,如果不是初始化状态,则直接抛出异常。所以,一个线程只能启动一次,多次启动是会抛出异常的。
面试:
- 能不能多次调用
Thread类的start()方法来启动线程? - 多次调用
Thread线程的start()方法会发生什么? - 为什么会抛出异常?
调用start()方法后,新创建的线程就会处于就绪状态(如果没有分配到CPU执行),当有空闲的CPU时,这个线程就会被分配CPU来执行,此时线程的状态为运行状态,JVM会调用线程的run()方法执行任务。
- sleep()方法
sleep()方法可以使当前线程休眠,代码如下:
// 本地方法,真正让线程休眠的方法
public static native void sleep(long millis) throws InterruptedException;
public static void sleep(long millis, int nanos) throws InterruptedException {
if (millis < 0) {
throw new IllegalArgumentException("timeout value is negative");
}
if (nanos < 0 || nanos > 999999) {
throw new IllegalArgumentException("nanosecond timeout value out of range");
}
if (nanos >= 50000 || (nanos != 0 && millis == 0)) {
millis++;
}
// 调用本地方法
sleep(millis);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
sleep()方法会让当前线程休眠一定的时间,这个时间通常是毫秒值,需要注意的是:调用sleep()方法使线程休眠后,线程不会释放相应的锁。
- join()方法
join()方法会一直等待线程超时或者终止,代码如下:
public final synchronized void join(long millis) throws InterruptedException {
long base = System.currentTimeMillis();
long now = 0;
if (millis < 0) {
throw new IllegalArgumentException("timeout value is negative");
}
if (millis == 0) {
while (isAlive()) {
wait(0);
}
} else {
while (isAlive()) {
long delay = millis - now;
if (delay <= 0) {
break;
}
wait(delay);
now = System.currentTimeMillis() - base;
}
}
}
public final synchronized void join(long millis, int nanos) throws InterruptedException {
if (millis < 0) {
throw new IllegalArgumentException("timeout value is negative");
}
if (nanos < 0 || nanos > 999999) {
throw new IllegalArgumentException("nanosecond timeout value out of range");
}
if (nanos >= 500000 || (nanos != 0 && millis == 0)) {
millis++;
}
join(millis);
}
public final void join() throws InterruptedException {
join(0);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
join()方法的使用场景往往是启动执行任务的线程,调用执行线程的join()方法,等待执行线程执行任务,直到超时或者执行线程终止。
- interrupt()方法
interrupt()方法是中断当前线程的方法,它通过设置线程的中断标志位来中断当前线程。此时,如果线程设置了中断标志位,可能会抛出InterruptedException异常,同时,会清除当前线程的中断状态。这种方式中断线程比较安全,它能使正在执行的任务执行能够继续执行完毕,而不像stop()方法那样强制关闭线程。
public void interrupt() {
if (this != Thread.currentThread())
checkAccess();
synchronized (blockerLock) {
Interruptible b = blocker;
if (b != null) {
interrupt0(); // Just to set the interrupt flag
b.interrupt(this);
return;
}
}
// 调用本地方法中断线程
interrupt0();
}
private native void interrupt0();
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# AQS中的CountDownLatch、Semaphore与CyclicBarrier
# CountDownLatch
同步辅助类,通过它可以阻塞当前线程,也就是说,能够实现一个线程或者多个线程一直等待,直到其他线程执行的操作完成。使用一个给定的计数器进行初始化,该计数器的操作是原子操作,即同时只能有一个线程操作该计数器。
调用该类await()方法的线程会一直阻塞,直到其他线程调用该类的countDown()方法,使当前计数器的值变为0为止。每次调用该类的countDown()方法,当前计数器的值就会减1。当计数器的值减为0的时候,所有因调用await()方法而处于等待状态的线程就会继续往下执行。这种操作只能出现一次,因为该类中的计数器不能被重置。如果需要一个可以重置计数次数的版本,可以考虑使用CyclicBarrier类。
CountDownLatch支持给定时间的等待,超过一定的时间不再等待,使用时只需要在await()方法中传入徐亚等待的时间即可。
public boolean await(long timeout, TimeUnit unit);
- 使用场景
在某些业务场景中,程序执行需要等待某个条件完成后才能继续执行后续的操作。典型的应用为并行计算:当某个处理的运算量很大时,可以将该运算任务拆分成多个子任务,等待所有的子任务都完成之后,父任务再拿到所有子任务的运算结果进行汇总。
- 代码示例
package com.ainsn.dandelion.thread;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import lombok.extern.slf4j.Slf4j;
@Slf4j
public class CountDownLatchExample {
private static final int threadCount = 200;
public static void main(String[] args) throws InterruptedException {
ExecutorService exec = Executors.newCachedThreadPool();
final CountDownLatch countDownLatch = new CountDownLatch(threadCount);
for (int i = 0; i < threadCount; i++) {
final int threadNum = i;
exec.execute(() -> {
try {
test(threadNum);
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
countDownLatch.countDown();
}
});
}
countDownLatch.await();
// countDownLatch.await(10, TimeUnit.MICROSECONDS);
log.info("finish");
exec.shutdown();
}
private static void test(int threadNum) throws InterruptedException {
Thread.sleep(100);
log.info("{}", threadNum);
Thread.sleep(100);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
# Semaphore
- 概述
控制同一时间并发线程的数目。能够完成对于信号量的控制,可以控制某个资源可被同时访问的个数。
提供了两个核心方法--acquire()方法和release()方法。acquire()方法表示获取一个许可,如果没有则等待,release()方法则是在操作完成后释放对应的许可。Semaphore维护了当前访问的个数,通过提供同步机制来控制同时访问的个数。Semaphore可以实现有限大小的链表。
- 使用场景
Semaphore常用于仅能提供有限访问的资源,比如:数据库连接数。
- 代码示例
每次获取并释放一个许可,示例代码:
package com.ainsn.dandelion.thread;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Semaphore;
import lombok.extern.slf4j.Slf4j;
@Slf4j
public class SemaphoreExample {
private static final int threadCount = 200;
public static void main(String[] args) {
ExecutorService exec = Executors.newCachedThreadPool();
final Semaphore semaphore = new Semaphore(3);
for (int i = 0; i < threadCount; i++) {
final int threadNum = i;
exec.execute(() -> {
try {
semaphore.acquire(); // 获取一个许可
test(threadNum);
semaphore.release(); // 释放一个许可
} catch (InterruptedException e) {
e.printStackTrace();
}
});
}
exec.shutdown();
}
private static void test(int threadNum) throws InterruptedException {
log.info("{}", threadNum);
Thread.sleep(1000);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
每次获取并释放多个许可,示例代码:
package com.ainsn.dandelion.thread;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Semaphore;
import lombok.extern.slf4j.Slf4j;
@Slf4j
public class SemaphoreExample02 {
private static final int threadCount = 200;
public static void main(String[] args) {
ExecutorService exec = Executors.newCachedThreadPool();
final Semaphore semaphore = new Semaphore(3);
for (int i = 0; i < threadCount; i++) {
final int threadNum = i;
exec.execute(() -> {
try {
semaphore.acquire(3);
test(threadNum);
semaphore.release(3);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
}
log.info("finish");
exec.shutdown();
}
private static void test(int threadNum) throws InterruptedException {
log.info("{}", threadNum);
Thread.sleep(1000);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
假设有这样一个场景,并发太高了,即使使用Semaphore进行控制,处理起来也比较棘手。假设系统当前允许的最高并发数是3,超过3后就需要丢弃,使用Semaphore也能实现这样的场景,示例:
package com.ainsn.dandelion.thread;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Semaphore;
import lombok.extern.slf4j.Slf4j;
@Slf4j
public class SemaphoreExample03 {
private static final int threadCount = 200;
public static void main(String[] args) {
ExecutorService exec = Executors.newCachedThreadPool();
final Semaphore semaphore = new Semaphore(3);
for (int i = 0; i < threadCount; i++) {
final int threadNum = i;
exec.execute(() -> {
try {
// 尝试获取一个许可,也可以尝试获取多个许可
// 支持尝试获取许可超时设置,超时后不再等待后续线程的执行
if (semaphore.tryAcquire()) {
test(threadNum);
semaphore.release(); // 释放一个许可
}
} catch (InterruptedException e) {
e.printStackTrace();
}
});
}
log.info("finish");
exec.shutdown();
}
private static void test(int threadNum) throws InterruptedException {
log.info("{}", threadNum);
Thread.sleep(1000);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
# CyclicBarrier
- 概述
是一个同步辅助类,允许一组线程相互等待,直到达到某个公共的屏障点,通过它可以完成多个线程之间相互等待,只有当每个线程都准备就绪后,才能各自继续往下执行后面的操作。
与CountDownLatch有相似的地方,都是使用计数器实现,当某个线程调用了CyclicBarrier的await()方法后,该线程就进入了等待状态,而且计数器执行加1操作,当计数器的值达到了设置的初始值,调用await()方法进入等待状态的线程会被唤醒,继续执行各自后续的操作。CyclicBarrier在释放等待线程后可以重用,所以,CyclicBarrier又被称为循环屏障。
- 使用场景
可以用于多线程计算数据,最后合并计算结果的场景
CyclicBarrier与CountDownLatch的区别
CountDownLatch的计数器只能使用一次,而CyclicBarrier的计数器可以使用reset()方法进行重置,并且可以循环使用CountDownLatch主要实现1个或n个线程需要等待其他线程完成某项操作之后,才能继续往下执行,描述的是1个或n个线程等待其他线程的关系。而CyclicBarrier主要实现了多个线程之间相互等待,直到所有的线程都满足了条件之后,才能继续执行后续的操作,描述的是各个线程内部相互等待的关系;CyclicBarrier能够处理更复杂的场景,如果计算发送错误,可以重置计数器让线程重新执行一次;CyclicBarrier中提供了很多有用的方法,比如:可以通过getNumberWaiting()方法获取阻塞的线程数量,通过isBroken()方法判断阻塞的线程是否被中断。
代码示例
package com.ainsn.dandelion.thread;
import java.util.concurrent.CyclicBarrier;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import lombok.extern.slf4j.Slf4j;
@Slf4j
public class CyclicBarrierExample01 {
private static CyclicBarrier cyclicBarrier = new CyclicBarrier(5);
public static void main(String[] args) throws InterruptedException {
ExecutorService exec = Executors.newCachedThreadPool();
for (int i = 0; i < 10; i++) {
final int threadNum = i;
Thread.sleep(1000);
exec.execute(() -> {
try {
race(threadNum);
} catch (Exception e) {
e.printStackTrace();
}
});
}
exec.shutdown();
}
private static void race(int threadNum) throws Exception {
Thread.sleep(1000);
log.info("{} is ready", threadNum);
cyclicBarrier.await();
log.info("{} continue", threadNum);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
设置等待超时示例代码如下:
package com.ainsn.dandelion.thread;
import java.util.concurrent.BrokenBarrierException;
import java.util.concurrent.CyclicBarrier;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.TimeoutException;
import lombok.extern.slf4j.Slf4j;
@Slf4j
public class CyclicBarrierExample02 {
private static CyclicBarrier cyclicBarrier = new CyclicBarrier(5);
public static void main(String[] args) throws InterruptedException {
ExecutorService exec = Executors.newCachedThreadPool();
for (int i = 0; i < 10; i++) {
final int threadNum = i;
Thread.sleep(1000);
exec.execute(() -> {
try {
race(threadNum);
} catch (Exception e) {
e.printStackTrace();
}
});
}
exec.shutdown();
}
private static void race(int threadNum) throws Exception {
Thread.sleep(1000);
log.info("{} is ready", threadNum);
try {
cyclicBarrier.await(2000, TimeUnit.MILLISECONDS);
} catch (BrokenBarrierException | TimeoutException e) {
log.warn("BarrierException", e);
}
log.info("{} continue", threadNum);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
在声明CyclicBarrier的时候,还可以指定一个Runnable,当线程达到屏障的时候,可以优先执行Runnable中的方法:
package com.ainsn.dandelion.thread;
import java.util.concurrent.CyclicBarrier;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import lombok.extern.slf4j.Slf4j;
@Slf4j
public class CyclicBarrierExample03 {
private static CyclicBarrier cyclicBarrier = new CyclicBarrier(5, () -> {
log.info("callback is running");
});
public static void main(String[] args) throws InterruptedException {
ExecutorService exec = Executors.newCachedThreadPool();
for (int i = 0; i < 10; i++) {
final int threadNum = i;
Thread.sleep(1000);
exec.execute(() -> {
try {
race(threadNum);
} catch (Exception e) {
e.printStackTrace();
}
});
}
exec.shutdown();
}
private static void race(int threadNum) throws Exception {
Thread.sleep(1000);
log.info("{} is ready", threadNum);
cyclicBarrier.await();
log.info("{} continue", threadNum);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
# AQS中的ReentrantLock、ReentrantReadWriteLock、StampedLock与Condition
# ReentrantLock
- 概述
Java中主要分为两类锁,一类是synchronized修饰的锁,另外一类就是J.U.C中提供的锁。J.U.C中提供的核心锁就是ReentrantLock。
ReentrantLock(可重入锁)与synchronized区别
- 可重入性:二者都是同一个线程进入1次,锁的计数器就自增1,需要等到锁的计数器下降为0时,才能释放锁。
- 锁的实现:
synchronzied是基于JVM实现的,而ReentrantLock是JDK实现的 - 性能区别:
synchronzied优化之前的性能比ReentrantLock差很多,但是自从synchronized引入了偏向锁,轻量级锁也就是自旋锁后,性能就差不多了。 - 功能区别
- 便利性:
synchronzied使用起来比较方便,并且由编译器保证加锁和释放;ReentrantLock需要手工声明加锁和释放锁,最好是在finally代码块中声明释放锁。 - 锁的灵活度和细粒度:
ReentrantLock优于synchronized。
- 便利性:
ReentrantLock独有的功能
ReentrantLock可指定是公平锁还是非公平锁,而synchronized只能是非公平锁,所谓的公平锁就是先等待的线程先获得锁;- 提供了一个
Condition类,可以分组唤醒需要唤醒的线程,而synchronzied只能随机唤醒一个线程,或者唤醒全部的线程 - 提供能够中断等待锁的线程的机制,
lock.lockInterruptibly()。ReentrantLock实现是一种自旋锁,通过循环调用CAS操作来实现加锁,性能上比较好是因为避免了使线程进入内核态的阻塞状态。
synchronized的优势
- 不用手动释放锁,JVM自动处理,如果出现异常,JVM也会自动释放锁;
- JVM用
synchronized进行管理锁定请求和释放时,JVM在生成线程转储时能够锁定信息,这些对调试非常有价值,因为它能标识死锁或者其他异常行为的来源。而ReentrantLock只是普通的类,JVM不知道具体哪个线程拥有lock对象; synchronized可以在所有JVM版本中工作,ReentrantLock在某些1.5之前版本的JVM中可能不支持。
synchronized能做的事情ReentrantLock都能做,而ReentrantLock有些能做的事情,synchronized不能做。
ReentrantLock中的部分方法说明
boolean tryLock():仅在调用时锁定未被另一个线程保持的情况下才获取锁定;boolean tryLock(long, TimeUnit):如果锁定在给定的时间内没有被另一个线程保持,且当前线程没有被中断,则获取这个锁定;void lockInterruptibly():如果当前线程没有被中断,就获取锁定;如果被中断,就抛出异常;boolean isLocked():查询此锁定是否由任意线程保持;boolean isHeldByCurrentThread():查询当前线程是否保持锁定状态;boolean isFair():判断是否是公平锁;boolean hasQueuedThread(Thread):查询指定线程是否在等待获取此锁定;boolean hasQueuedThreads():查询是否有现成正在等待获取此锁定;boolean getHoldCount():查询当前线程保持锁定的个数。
代码示例
package com.ainsn.dandelion.thread;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Semaphore;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
import lombok.extern.slf4j.Slf4j;
@Slf4j
public class LockExample {
// 请求总数
public static int clientTotal = 5000;
// 同时并发执行的线程数
public static int threadTotal = 200;
public static int count = 0;
private static final Lock lock = new ReentrantLock();
public static void main(String[] args) throws InterruptedException {
ExecutorService exec = Executors.newCachedThreadPool();
final Semaphore semaphore = new Semaphore(threadTotal);
final CountDownLatch countDownLatch = new CountDownLatch(clientTotal);
for (int i = 0; i < clientTotal; i++) {
exec.execute(() -> {
try {
semaphore.acquire();
add();
semaphore.release();
} catch (Exception e) {
log.error("exception", e);
}
countDownLatch.countDown();
});
}
countDownLatch.await();
exec.shutdown();
log.info("count: {}", count);
}
private static void add() {
lock.lock();
try {
count++;
} finally {
lock.unlock();
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
# ReentrantReadWriteLock
- 概述
在没有任何读写锁的时候,才可以取得写锁,如果一直有读锁存在,则无法执行写锁,这就会导致写锁饥饿。
- 代码示例
package com.ainsn.dandelion.thread;
import java.util.Map;
import java.util.Set;
import java.util.TreeMap;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantReadWriteLock;
public class LockExample02 {
private final Map<String, Data> map = new TreeMap<>();
private final ReentrantReadWriteLock lock = new ReentrantReadWriteLock();
private final Lock readLock = lock.readLock();
private final Lock wriLock = lock.writeLock();
public Data get(String key) {
readLock.lock();
try {
return map.get(key);
} finally {
readLock.unlock();
}
}
public Set<String> getAllKeys() {
readLock.lock();
try {
return map.keySet();
} finally {
readLock.unlock();
}
}
public Data put(String key, Data value) {
wriLock.lock();
try {
return map.put(key, value);
} finally {
wriLock.unlock();
}
}
class Data {
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
# StampedLock
- 概述
控制锁三种模式:写、读、乐观锁。
StampedLock的状态由版本和模式两个部分组成,锁获取方法返回的是一个数字作为票据,用响应的锁状态来表示并控制相关的访问,数字0表示没有写锁被授权访问。
在读锁上分为悲观锁和乐观锁,乐观读就是在读操作很多,写操作很少的情况下,可以乐观的认为写入和读取同时发生的几率很小。因此,不悲观的使用完全的读取锁定。程序可以查看读取资料之后,是否遭到写入进行了变更,在采取后续的措施,这样的改进可以大幅度提升程序的吞吐量。
总之,在读线程很多的场景下,StampedLock大幅度提升了程序的吞吐量。
StampedLock源码中的案例如下:
class Point {
private double x, y;
private final StampedLock sl = new StampedLock();
void move(double deltaX, double deltaY) { // an exclusively locked method
long stamp = sl.writeLock();
try {
x += deltaX;
y += deltaY;
} finally {
sl.unlockRead(stamp);
}
}
// 下面看看乐观读锁案例
double distanceFromOrigin() { // A read-only method
long stamp = sl.tryOptimisticRead(); // 获得一个乐观读锁
double currentX = x, currentY = y; // 将两个字段读入本地局部变量
if (!sl.validate(stamp)) { // 检查发出乐观读锁后同时是否有其他写锁发生
stamp = sl.readLock(); // 如果没有,再次获得一次读悲观锁
try {
currentX = x; // 将两个字段读入本地局部变量
currentY = y; // 将两个字段读入本地局部变量
} finally {
sl.unlockRead(stamp);
}
}
return Math.sqrt(currentX * currentY + currentY * currentY);
}
// 下面是悲观读锁案例
void moveIfAtOrigin(double newX, double newY) { // upgrade
// Could instead start with optimistic, not read mode
long stamp = sl.readLock();
try {
while (x == 0.0 && y == 0.0) { // 循环,检查当前状态是否符合
long ws = sl.tryConvertToWriteLock(stamp); // 将读锁转为写锁
if (ws != 0L) { // 确认转为写锁是否成功
stamp = ws; // 如果成功,替换票据
x = newX; // 进行状态改变
y = newY; // 进行状态改变
break;
} else {
sl.unlockRead(stamp); // 显示释放读锁
stamp = sl.writeLock(); // 显示直接进行写锁,然后在通过循环再试
}
}
} finally {
sl.unlock(stamp); // 释放读锁或写锁
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
- 代码示例
package com.ainsn.dandelion.thread;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Semaphore;
import java.util.concurrent.locks.StampedLock;
import lombok.extern.slf4j.Slf4j;
@Slf4j
public class LockExample03 {
// 请求总数
public static int clientTotal = 5000;
// 同时并发执行的线程数
public static int threadTotal = 200;
public static int count = 0;
private static final StampedLock lock = new StampedLock();
public static void main(String[] args) throws InterruptedException {
ExecutorService exec = Executors.newCachedThreadPool();
final Semaphore semaphore = new Semaphore(threadTotal);
final CountDownLatch countDownLatch = new CountDownLatch(clientTotal);
for (int i = 0; i < clientTotal; i++) {
exec.execute(() -> {
try {
semaphore.acquire();
add();
semaphore.release();
} catch (Exception e) {
log.error("exception", e);
}
countDownLatch.countDown();
});
}
countDownLatch.await();
exec.shutdown();
log.info("count: {}", count);
}
private static void add() {
// 加锁时返回一个long类型的票据
long stamp = lock.writeLock();
try {
count++;
} finally {
// 释放锁的时候带上加锁时返回的票据
lock.unlock(stamp);
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
可以这样选择使用synchronized锁还是ReentrantLock锁
- 当只有少量竞争者时,
synchronized是一个很好的通用锁实现; - 竞争者不少,但是线程的增长趋势是可预估的,此时,
ReentrantLock是一个很好的通用锁实现 synchronized不会引发死锁,其他的锁使用不当可能会引发死锁。
# Condition
- 概述
Condition是一个多线程间协调通信的工具类,Condition除了实现wait和notify的功能以外,它的好处在于一个lock可以创建多个Condition,可以选择性的通知wait的线程
特点:
Condition的前提是Lock,由AQS中newCondition()方法创建Condition对象;Condition await方法表示线程从AQS中移除,并释放线程获取的锁,并进入Condition等待队列中等待,等待被signalCondition signal方法表示唤醒对应Condition等待队列中的线程节点,并加入AQS中,准备去获取锁。
- 代码示例
package com.ainsn.dandelion.thread;
import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.ReentrantLock;
import lombok.extern.slf4j.Slf4j;
@Slf4j
public class LockExample04 {
public static void main(String[] args) {
ReentrantLock reentrantLock = new ReentrantLock();
Condition condition = reentrantLock.newCondition();
new Thread(() -> {
try {
reentrantLock.lock();
log.info("wait signal"); // 1
condition.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
log.info("get signal"); // 4
reentrantLock.unlock();
}).start();;
new Thread(() -> {
reentrantLock.lock();
log.info("get lock"); // 2
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
condition.signalAll();
log.info("send signal ~"); // 3
reentrantLock.unlock();
}).start();;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
# ThreadLocal
# 什么是ThreadLocal?
# ThreadLocal使用示例
# ThreadLocal原理
# ThreadLocal变量不具有传递性
# InheritableThreadLocal使用示例
# InheritableThreadLocal原理
# Thread类的stop()和interrupt()方法
# stop()方法
# interrupt()方法
# 导致并发编程频繁出问题的“幕后黑手”
# 并发编程的难点
# 操作系统做出的努力
# 揪出幕后黑手
# 源头一:缓存导致的可见性问题
# 源头二:线程切换带来的原子性问题
# 源头三:变异优化带来的有序性问题
# 解密诡异并发问题的第一个幕后黑手--可见性问题
# 可见性
# 可见性问题
# 可见性代码示例
# 解密导致并发问题的第二个幕后黑手--原子性问题
# 原子性
# 线程切换
# 原子性问题
# Java中的原子性问题
# 解密导致并发问题的第三个幕后黑手--有序性问题
# 有序性
# 指令重排序
# 有序性问题
# 如何解决可见性和有序性问题?
# 什么是Java内存模型?
# volatile为何能保证线程间可见?
# Happens-Before原则
# 原则一:程序次序规则
# 原则二:volatile变量规则
# 原则三:传递规则
# 原则四:锁定规则
# 原则五:线程启动规则
# 原则六:线程终结规则
# 原则七:线程中断规则
# 原则八:对象终结原则
# final关键字
# Java内存模式的底层实现
# synchronized原理
# synchronized的基本使用
# synchronized原理
# 运行结果解释
# 为何在32位多核CPU上执行long型变量的写操作会出现诡异的Bug问题?
# 诡异的问题
# 原因分析
# 如何使用互斥锁解决多线程的原子性问题?
# 如何保证原子性?
# 锁模型
# 改进的锁模型
# Java中的synchronized锁
# synchronized解密
# 再次深究count+=1的问题
# 修改测试用例
# 学好并发编程,关键是要理解这三个核心问题
# 分工
# 同步
# 互斥
# 什么是ForkJoin?
# Java并发编程的发展
# 分治法
# ForkJoin并行处理框架
# ForkJoin示例程序
# 使用Redisson实现分布式锁
# 可重入锁(ReentrantLock)
# 公平锁(FairLock)
# 联锁(MultiLock)
# 红锁(RedLock)
# 读写锁(ReadWriteLock)
# 信号量(Semaphore)
# 可过期性信号量(PermitExpirableSemaphore)
# 闭锁(CountDownLatch)
# 为何高并发系统中都要使用消息队列?
# 场景分析
# 消息队列的好处
# 消息队列特性
# 高并发系统为何使用消息队列
# 高并发环境下如何优化Tomcat配置?
# Tomcat运行模式
# Tomcat并发优化
# 言简意赅介绍BlockingQueue
# BlockingQueue概述
# BlockingQueue的实现类
# 高并发环境下如何防止Tomcat内存溢出?
# 设置启动初始内存
# 防止所用的JVM内存溢出
# 高并发下常见的限流方案
# 限流算法
# 单机限流
# 应用级限流
# 分布式限流
# Redis如何助力高并发秒杀系统?
# 秒杀业务
# 秒杀三阶段
# Redis助力秒杀系统
# Lua脚本完美解决超卖问题
# 一文搞懂PV、UV、VV、IP及其关系与计算
# 什么是PV?
# 什么是UV?
# 什么是VV?
# 什么是IP?
# 优化加锁方式时竟然死锁了
# 为何需要优化加锁方式?
# 初步优化加锁方式
# 死锁的问题分析
# 死锁的必要条件
# 死锁的预防
# 高并发环境下诡异的加锁问题(你加的锁未必安全)
# 分析场景
# 没有直接业务关系的场景
# 存在直接业务关系的场景
# 正确的加锁
# 高并发场景下创建多少线程才合适?一条公式帮你搞定
# CPU密集型
# I/O密集型
# 为什么局部变量是线程安全的?
# 注明的斐波那契数列
# 方法是如何被执行的?
# 局部变量存放在哪里?
# 调用栈与线程
# 线程封闭
# 线程的生命周期其实没有我们想象的那么简单
# 通用的线程生命周期
# Java中的线程生命周期
# RUNNABLE与TIMED_WAITING状态转换
# 如何实现亿级流量下的分布式限流?这些理论必须掌握
# 高并发系统限流
# 什么是限流?
# 限流有哪些使用场景?
# 如何实现亿级流量下的分布式限流?这些算法必须掌握
# 计数器
# 漏桶算法
# 令牌桶算法
# 令牌桶算法实现
# Guava令牌桶算法的特点
# 亿级流量场景下如何为HTTP接口限流?
# HTTP接口限流实战
# 不使用注解实现接口限流
# 使用注解实现接口限流
# 基于限流算法实现限流的缺点
# 亿级流量场景下如何实现分布式限流?
# Redis+Lua脚本实现分布式限流思路
# Redis+Lua脚本实现分布式限流案例
# 测试分布式限流
# Nginx+Lua实现分布式限流
# 灵魂拷问
# 如何实现亿级流量下的分布式限流?
# 高并发系统限流
# 什么是限流?
# 限流有哪些使用场景?
# 常见的限流算法
# HTTP接口限流实战
# 使用限流算法实现限流的缺点
# 分布式限流实战
# Redis+Lua脚本实现分布式限流思路
# Redis+Lua脚本实现分布式限流案例
# 测试分布式限流
# Nginx+Lua实现分布式限流
# 灵魂拷问
# 高并发场景下如何优化加锁方式?
# 问题分析
# 线程的等待与通知机制
# 用Java实现线程的等待与通知机制
# 具体实现
# notify()和notifyAll()的区别
# 什么是缓存穿透?击穿?雪崩?如何解决?
# 写在前面
# 缓存穿透
# 缓存击穿
# 缓存雪崩
# Java中提供了synchronized,为什么还要提供Lock呢?
# 写在前面
# 再造轮子?
# 为何提供Lock接口?
# 死锁问题
# synchronized的局限性
# 解决问题
# 说说缓存最关心的问题是什么?有哪些类型?回收策略和算法?
# 写在前面
# 缓存命中率
# 缓存类型
# 缓存回收策略
# 回收算法
# 性能优化有哪些衡量指标?需要注意什么?
# 写在前面
# 面试场景
# 衡量指标
# 性能指标
# 响应时间
# 并发量
# 秒开率
# 正确性
# 优化需要注意的问题
# 如何使用Nginx实现限流
# 写在前面
# 限流措施
# Nginx官方的限流模块
# limit_req_zone 参数配置
# ngx_http_limit_conn_module 参数配置
# Nginx限流实战
# 如何设计一个支撑高并发大流量的系统?
# 写在前面
# 高并发架构相关概念
# 高并发解决方案案例
# 高并发下的经验公式
# 关于乐观锁和悲观锁
# 写在前面
# 何谓悲观锁与乐观锁
# 两种锁的使用场景
# 乐观锁的实现方式
# CAS与synchronized的使用场景
# 关于线程池
# 写在前面
# Java中的线程池是如何实现的?
# 创建线程池的几个核心构造参数?
# 线程池中的线程是怎么创建的?是一开始就随着线程池的启动创建好的吗?
# 既然提到可以通过配置不同参数创建出不同的线程池,那么Java中默认实现好的线程池有哪些?请比较它们的异同
# 什么是Java的内存模型,Java中各个线程是怎么彼此看到对方的变量的?
# volatile有什么特点,为什么能保证变量对所有线程的可见性?
# 既然volatile能够保证线程间的变量可见性,是不是就意味着基于volatile变量的运算就是并发安全的?
# 请对比下volatile对比synchronized的异同
# ThreadLocal是怎么解决并发安全的?
# 很多人都说要慎用ThreadLocal,使用ThreadLocal要注意什么?
# 高并发场景下构建缓存服务需要注意哪些问题?
# 写在前面
# 缓存特征
# 缓存命中率影响因素
# 提高缓存命中率的方法
# 缓存的分类和应用场景
# 高并发场景下缓存常见问题
# 高并发系统架构解密,不是所有的秒杀都是秒杀?
# 前言
# 电商系统架构
# 秒杀系统的特点
# 秒杀系统方案
# 秒杀系统时序图
# 高并发“黑科技”与致胜奇招
# 写在最后
# 高并发分布式锁架构解密,不是所有的锁都是分布式锁
# 写在前面
# 锁用来解决什么问题?
# 电商超卖问题
# JVM中提供的锁
# 分布式锁
# Redis锁如何实现分布式锁
# 实现分布式锁的基本要求
# 通用分布式解决方案
# CAP理论
# 红锁的实现
# 高并发“黑科技”与致胜奇招
- 线程与线程池
- 线程与多线程
- 线程的实现方式
- 线程的生命周期
- 线程的执行顺序
- 线程的执行顺序是不确定的
- 如何确保线程的执行顺序
- Java中的Callable和Future
- Callable接口
- 两种异步模型
- 深度解析Future接口
- SimpleDateFormat类的线程安全问题
- 重现SimpleDateFormat类的线程安全问题
- SimpleDateFormat类为何不是线程安全的
- 解决SimpleDateFormat类的线程安全问题
- 深度解析ThreadPoolExecutor类源码
- Thread直接创建线程的弊端
- 线程池的好处
- 线程池
- 线程池最核心的类之一ThreadPoolExecutor
- 深度解析线程池中重要的顶层接口和抽象类
- 接口和抽象类总览
- Executor接口
- ExecutorService接口
- AbstractExecutorService抽象类
- ScheduledExecutorService接口
- 从源码角度分析创建线程池有哪些方式
- 使用Executors工具类创建线程池
- 使用ThreadPoolExecutor类创建线程池
- 使用ForkJoinPool类创建线程池
- 使用ScheduledThreadPoolExecutor类创建线程池
- 通过源码深度解析ThreadPoolExecutor类是如何保证线程池正确运行的
- ThreadPoolExecutor类中的重要属性
- ThreadPoolExecutor类中的重要内部类
- 通过ThreadPoolExecutor类的源码深度解析线程池执行任务的核心流程
- 核心逻辑概述
- execute(Runnable)方法
- addWorker(Runnable, boolean)方法
- addWorkerFailed(Worker)方法
- 拒绝策略
- 通过源码深度分析线程池中Worker线程的执行流程
- Worker类分析
- runWorker(Worker)方法
- getTask()方法
- beforeExecute(Thread, Runnable)方法
- afterExecute(Runnable, Throwable)方法
- processWorkerExit(Worker, boolean)方法
- tryTerminate()方法
- terminated()方法
- 从源码角度深度解析线程池是如何实现优雅退出的
- shutdown()方法
- shutdownNow()方法
- awaitTermination(long, TimeUnit)方法
- 深入理解ScheduledThreadPoolExecutor与Timer的区别和简单示例
- 二者的区别
- 二者的简单示例
- 深度解析ScheduledThreadPoolExecutor类的源代码
- 构造方法
- schedule方法
- decorateTask方法
- scheduleAtFixedRate方法
- scheduleWithFixedDelay方法
- triggerTime方法
- overflowFree方法
- delayedExecute方法
- reExecutePeriodic方法
- onShutdown方法
- 深入理解Thread类源码
- Thread类的继承体系
- Thread类的源码剖析
- AQS中的CountDownLatch、Semaphore与CyclicBarrier
- CountDownLatch
- Semaphore
- CyclicBarrier
- AQS中的ReentrantLock、ReentrantReadWriteLock、StampedLock与Condition
- ReentrantLock
- ReentrantReadWriteLock
- StampedLock
- Condition
- ThreadLocal
- 什么是ThreadLocal?
- ThreadLocal使用示例
- ThreadLocal原理
- ThreadLocal变量不具有传递性
- InheritableThreadLocal使用示例
- InheritableThreadLocal原理
- Thread类的stop()和interrupt()方法
- stop()方法
- interrupt()方法
- 导致并发编程频繁出问题的“幕后黑手”
- 并发编程的难点
- 操作系统做出的努力
- 揪出幕后黑手
- 源头一:缓存导致的可见性问题
- 源头二:线程切换带来的原子性问题
- 源头三:变异优化带来的有序性问题
- 解密诡异并发问题的第一个幕后黑手--可见性问题
- 可见性
- 可见性问题
- 可见性代码示例
- 解密导致并发问题的第二个幕后黑手--原子性问题
- 原子性
- 线程切换
- 原子性问题
- Java中的原子性问题
- 解密导致并发问题的第三个幕后黑手--有序性问题
- 有序性
- 指令重排序
- 有序性问题
- 如何解决可见性和有序性问题?
- 什么是Java内存模型?
- volatile为何能保证线程间可见?
- Happens-Before原则
- 原则一:程序次序规则
- 原则二:volatile变量规则
- 原则三:传递规则
- 原则四:锁定规则
- 原则五:线程启动规则
- 原则六:线程终结规则
- 原则七:线程中断规则
- 原则八:对象终结原则
- final关键字
- Java内存模式的底层实现
- synchronized原理
- synchronized的基本使用
- synchronized原理
- 运行结果解释
- 为何在32位多核CPU上执行long型变量的写操作会出现诡异的Bug问题?
- 诡异的问题
- 原因分析
- 如何使用互斥锁解决多线程的原子性问题?
- 如何保证原子性?
- 锁模型
- 改进的锁模型
- Java中的synchronized锁
- synchronized解密
- 再次深究count+=1的问题
- 修改测试用例
- 学好并发编程,关键是要理解这三个核心问题
- 分工
- 同步
- 互斥
- 什么是ForkJoin?
- Java并发编程的发展
- 分治法
- ForkJoin并行处理框架
- ForkJoin示例程序
- 使用Redisson实现分布式锁
- 可重入锁(ReentrantLock)
- 公平锁(FairLock)
- 联锁(MultiLock)
- 红锁(RedLock)
- 读写锁(ReadWriteLock)
- 信号量(Semaphore)
- 可过期性信号量(PermitExpirableSemaphore)
- 闭锁(CountDownLatch)
- 为何高并发系统中都要使用消息队列?
- 场景分析
- 消息队列的好处
- 消息队列特性
- 高并发系统为何使用消息队列
- 高并发环境下如何优化Tomcat配置?
- Tomcat运行模式
- Tomcat并发优化
- 言简意赅介绍BlockingQueue
- BlockingQueue概述
- BlockingQueue的实现类
- 高并发环境下如何防止Tomcat内存溢出?
- 设置启动初始内存
- 防止所用的JVM内存溢出
- 高并发下常见的限流方案
- 限流算法
- 单机限流
- 应用级限流
- 分布式限流
- Redis如何助力高并发秒杀系统?
- 秒杀业务
- 秒杀三阶段
- Redis助力秒杀系统
- Lua脚本完美解决超卖问题
- 一文搞懂PV、UV、VV、IP及其关系与计算
- 什么是PV?
- 什么是UV?
- 什么是VV?
- 什么是IP?
- 优化加锁方式时竟然死锁了
- 为何需要优化加锁方式?
- 初步优化加锁方式
- 死锁的问题分析
- 死锁的必要条件
- 死锁的预防
- 高并发环境下诡异的加锁问题(你加的锁未必安全)
- 分析场景
- 没有直接业务关系的场景
- 存在直接业务关系的场景
- 正确的加锁
- 高并发场景下创建多少线程才合适?一条公式帮你搞定
- CPU密集型
- I/O密集型
- 为什么局部变量是线程安全的?
- 注明的斐波那契数列
- 方法是如何被执行的?
- 局部变量存放在哪里?
- 调用栈与线程
- 线程封闭
- 线程的生命周期其实没有我们想象的那么简单
- 通用的线程生命周期
- Java中的线程生命周期
- RUNNABLE与TIMED_WAITING状态转换
- 如何实现亿级流量下的分布式限流?这些理论必须掌握
- 高并发系统限流
- 什么是限流?
- 限流有哪些使用场景?
- 如何实现亿级流量下的分布式限流?这些算法必须掌握
- 计数器
- 漏桶算法
- 令牌桶算法
- 令牌桶算法实现
- Guava令牌桶算法的特点
- 亿级流量场景下如何为HTTP接口限流?
- HTTP接口限流实战
- 不使用注解实现接口限流
- 使用注解实现接口限流
- 基于限流算法实现限流的缺点
- 亿级流量场景下如何实现分布式限流?
- Redis+Lua脚本实现分布式限流思路
- Redis+Lua脚本实现分布式限流案例
- 测试分布式限流
- Nginx+Lua实现分布式限流
- 灵魂拷问
- 如何实现亿级流量下的分布式限流?
- 高并发系统限流
- 什么是限流?
- 限流有哪些使用场景?
- 常见的限流算法
- HTTP接口限流实战
- 使用限流算法实现限流的缺点
- 分布式限流实战
- Redis+Lua脚本实现分布式限流思路
- Redis+Lua脚本实现分布式限流案例
- 测试分布式限流
- Nginx+Lua实现分布式限流
- 灵魂拷问
- 高并发场景下如何优化加锁方式?
- 问题分析
- 线程的等待与通知机制
- 用Java实现线程的等待与通知机制
- 具体实现
- notify()和notifyAll()的区别
- 什么是缓存穿透?击穿?雪崩?如何解决?
- 写在前面
- 缓存穿透
- 缓存击穿
- 缓存雪崩
- Java中提供了synchronized,为什么还要提供Lock呢?
- 写在前面
- 再造轮子?
- 为何提供Lock接口?
- 死锁问题
- synchronized的局限性
- 解决问题
- 说说缓存最关心的问题是什么?有哪些类型?回收策略和算法?
- 写在前面
- 缓存命中率
- 缓存类型
- 缓存回收策略
- 回收算法
- 性能优化有哪些衡量指标?需要注意什么?
- 写在前面
- 面试场景
- 衡量指标
- 性能指标
- 响应时间
- 并发量
- 秒开率
- 正确性
- 优化需要注意的问题
- 如何使用Nginx实现限流
- 写在前面
- 限流措施
- Nginx官方的限流模块
- limitreqzone 参数配置
- ngxhttplimitconnmodule 参数配置
- Nginx限流实战
- 如何设计一个支撑高并发大流量的系统?
- 写在前面
- 高并发架构相关概念
- 高并发解决方案案例
- 高并发下的经验公式
- 关于乐观锁和悲观锁
- 写在前面
- 何谓悲观锁与乐观锁
- 两种锁的使用场景
- 乐观锁的实现方式
- CAS与synchronized的使用场景
- 关于线程池
- 写在前面
- Java中的线程池是如何实现的?
- 创建线程池的几个核心构造参数?
- 线程池中的线程是怎么创建的?是一开始就随着线程池的启动创建好的吗?
- 既然提到可以通过配置不同参数创建出不同的线程池,那么Java中默认实现好的线程池有哪些?请比较它们的异同
- 什么是Java的内存模型,Java中各个线程是怎么彼此看到对方的变量的?
- volatile有什么特点,为什么能保证变量对所有线程的可见性?
- 既然volatile能够保证线程间的变量可见性,是不是就意味着基于volatile变量的运算就是并发安全的?
- 请对比下volatile对比synchronized的异同
- ThreadLocal是怎么解决并发安全的?
- 很多人都说要慎用ThreadLocal,使用ThreadLocal要注意什么?
- 高并发场景下构建缓存服务需要注意哪些问题?
- 写在前面
- 缓存特征
- 缓存命中率影响因素
- 提高缓存命中率的方法
- 缓存的分类和应用场景
- 高并发场景下缓存常见问题
- 高并发系统架构解密,不是所有的秒杀都是秒杀?
- 前言
- 电商系统架构
- 秒杀系统的特点
- 秒杀系统方案
- 秒杀系统时序图
- 高并发“黑科技”与致胜奇招
- 写在最后
- 高并发分布式锁架构解密,不是所有的锁都是分布式锁
- 写在前面
- 锁用来解决什么问题?
- 电商超卖问题
- JVM中提供的锁
- 分布式锁
- Redis锁如何实现分布式锁
- 实现分布式锁的基本要求
- 通用分布式解决方案
- CAP理论
- 红锁的实现
- 高并发“黑科技”与致胜奇招