
LangChain 实战课
# AI应用开发的奇点
ChatGPT不仅是技术革命,还能为企业提供便捷的服务。在类似ChatGPT这样的模型基础上所开发的应用,可以助力企业优化客户服务、提升客户质量、加强市场营销、优化产品设计、改进供应链管理等等。ChatGPT所代表的大语言模型落地场景,覆盖千行百业的方方面面。
阿里巴巴集团董事会主席张勇: "AI大模型的出现是一个划时代的里程碑,就像工业革命一样,大模型将会被各行各业广泛应用,带来生产力的巨大提升,并深刻改变我们的生活方式"。
面向AI时代,所有产品都值得用大模型重新升级,未来的人工智能应用企业有可能会超过Apple、微软、谷歌等平台企业。
# 何谓LangChain?
释放大语言模型潜能的利器。一种专为开发基于语言模型的应用而设计的框架,通过LangChain不仅可以通过API调用如ChatGPT、GPT-4、Llama2等大预言模型,还可以实现更高级的功能。
真正有潜力且具有创新性的应用,不仅仅在于能通过API调用语言模型,更重要的是能够具备以下两个特性:
- 数据感知: 能够将语言模型与其他数据源连接起来,从而实现更丰富、更多样化数据的理解和利用。
- 代理性: 能够让语言模型与其环境进行交互,使得模型能够对其环境有更深入的理解,并能够进行有效的响应。
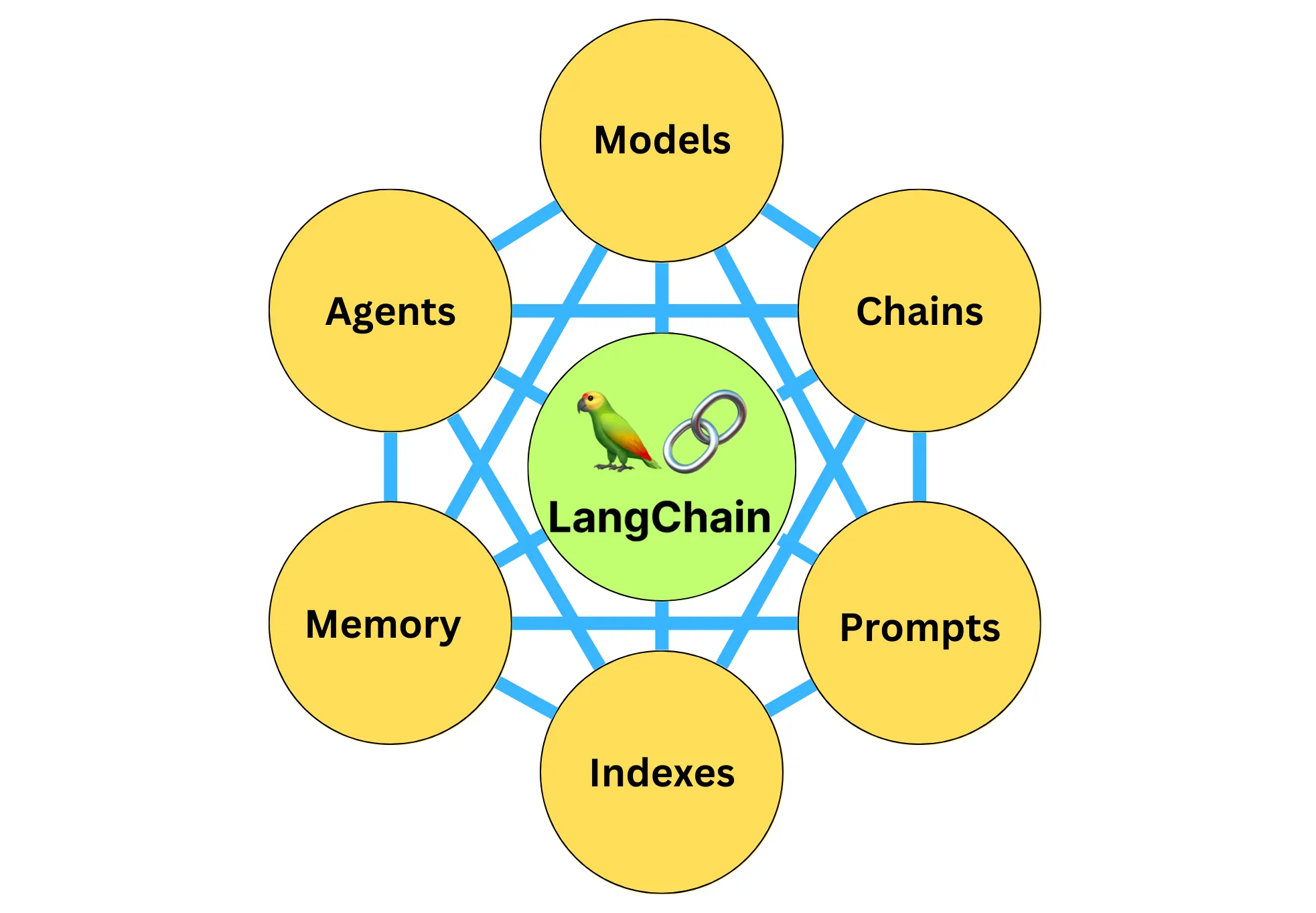
# 如何学习LangChain?
6大组件:
- 模型(Models): 包含各大语言模型的LangChain接口和调用细节,以及输出解析机制
- 提示模板(Prompts): 使提示工程流线化,进一步激化大语言模型的潜力
- 数据检索(Indexes): 构建并操作文档的方法,接受用户的查询并返回最相关的文档,轻松搭建本地知识库
- 记忆(Memory): 通过短时记忆和长时记忆,在对话过程中存储和检索数据,让ChatBot记住会话
- 链(Chains): 是LangChain的核心机制,以特定方式封装各种功能,并通过一系列的组合,自动而灵活地完成常见用例
- 代理(Agents): 是另一个LangChain的核心机制,通过代理让大模型自主调用外部工具和内部工具,使强大的智能化自主Agent称为可能
# LangChain 用例
应用1: 情人节玫瑰宣传语
需求: 情人节到啦,花店需要推销红色玫瑰,通过大语言模型生成一个简短的宣传语。
- 第一步: 创建requirements.txt依赖管理文件,并使用命令安装依赖
pillow
requests
transformers
langchain
langchain_ollama
torch
torchvision
2
3
4
5
6
7
pip install -r requirements.txt
- 计划使用Ollama本地部署Qwen2.5 14B的模型
ollama run qwen2.5:14b
- 编写代码
from langchain_ollama import ChatOllama
llm = ChatOllama(base_url="http://localhost:11434", model="qwen2.5:14b")
text = llm.invoke("请给我写一句情人节红玫瑰的中文宣传语")
print(text)
2
3
4
5
6


应用2: 海报文案生成器
花店已经制作好了一批鲜花的推广海报,希望为每一个海报的内容,生成一两句宣传文案。这个需求,特别适合用AI批量完成,但是,大语言模型一般不可能读图,这时就需要用LangChain的代理调用工具来完成大语言模型自己做不到的事情。

现在就可以用一段简单的代码实现上述功能,主要包含三个部分:
- 初始化图像字幕生成模型(HuggingFace中的image-caption模型)
- 定义LangChain图像字幕生成工具
- 初始化并运行LangChain Agent(代理),这个Agent是OpenAI的大语言模型,会自动进行分析,调用工具,完成任务。
这段代码需要的包比较多,在运行这段代码之前,需要先更新LangChain到最新版本,安装HuggingFace的Transformers库(开源大模型工具),并安装Pillow(Python图像处理工具包)和PyTorch(深度学习框架)。
pillow
requests
transformers
langchain
langchain_ollama
torch
torchvision
2
3
4
5
6
7
import requests
from PIL import Image
from transformers import BlipProcessor, BlipForConditionalGeneration
from langchain.tools import BaseTool
from langchain_ollama import ChatOllama
from langchain.agents import initialize_agent, AgentType
hf_model = "Salesforce/blip-image-captioning-large"
model_path = "./models/"
processor = BlipProcessor.from_pretrained(hf_model, cache_dir=model_path)
model = BlipForConditionalGeneration.from_pretrained(hf_model, cache_dir=model_path)
class ImageCapTool(BaseTool):
name: str = "Image captioner"
description: str = "为图片给出提示内容."
def _run(self, url: str):
image = Image.open(requests.get(url, stream=true).raw).convert('RGB')
inputs = processor(image, return_tensors="pt")
out = model.generate(**inputs, max_new_tokens=20)
caption = processor.decode(out[0], skip_special_tokens=True)
return caption
def _arun(self, query: str):
raise NotImplementedError("This tool does not support async")
llm = ChatOllama(base_url="http://localhost:11434", model="qwen2.5:14b")
tools = [ImageCapTool()]
agent = initialize_agent(
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
tools=tools,
llm=llm,
verbose=True
)
img_url = 'https://static001.geekbang.org/resource/image/f1/99/f1e55d0c8yy2189eb2d7d23978272699.png'
agent.invoke(input=f'{img_url}\n请创作合适的中文推广文案')
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39


针对上面的鲜花图片,程序进入了AgentExecutor链,开始思考推理,并采取星都--调用Image Cationer工具,接收该工具给出的结果,并根据其返回的内容,再次进行思考推理,最后给出生成的文案。这个过程中很多细节,比如大模型是怎么思考的?LangChain调用大模型时传入的具体提示文本是什么?AgentExecutor Chain是什么?它究竟是怎样调度工具的?
LangChain并不是生硬的去设计什么固定的逻辑,而是由语言模型通过理解和推理来决定执行什么操作以及执行的顺序。
# LangChain系统安装和快速入门
# 什么是大语言模型
大语言模型是一种人工智能模型,通常使用深度学习技术,比如神经网络,来理解和生成人类语言。这些模型的大在于他们的参数数量非常多,可以达到数十亿甚至更多,这使得他们能够理解和生成高度复杂的语言模式。
可以将大语言模型想象成一个巨大的预测机器,其训练过程主要基于"猜词": 给定一段文本的开头,他的任务就是预测下一个词是什么。模型会根据大量的训练数据(例如在互联网上爬取的文本),试图理解词语和词组在语言中的用法和含义,以及他们如何组成形成意义。他会通过不断地学习和调整参数,使得自己的预测越来越准确。
比如给模型一个句子: "今天的天气真",模型可能会预测出"好"作为下一个词,因为在它看过大量训练数据中,"今天的天气真好"是一个常见的句子。这种预测并不只基于词语的统计关系,还包括对上下文的理解,甚至有时能体现出对世界常识的认知,比如它会理解到,人们通常会在天气好的时候进行户外活动。因此也就能够继续生成或者说推出相关的内容。
但是,大语言模型并不完全理解语言,它们没有人类的情感、意识或理解力。它们只是通过复杂的数学函数学习到的语言模式,一个概率模型来做预测,所以有时候它们会犯错误,或者生成不合理甚至偏离主题的内容。
LangChain的预构建链功能,就像乐高积木一样,无论是新手还是经验丰富的开发者,都可以选择适合自己的部分快速构建项目。对于希望进行更深入工作的开发者,LangChain提供的模块化组件则允许根据需求定制和创建应用中的功能链条。
LangChain是一个全方位的、基于大语言模型这种预测能力的应用开发工具,它的灵活性和模块化特性使得处理语言模型变得极其简便。
LangChain支持Python和JavaScript两个开发版本。
# 安装LangChain
pip install langchain
这是安装LangChain的最低要求,需要注意的是,LangChain要与各种模型、数据存储库集成,比如说最重要的OpenAI的API接口,比如说开源大模型库HuggingFace Hub,再比如说对各种向量数据库的支持,默认情况下,是没有同时安装所需的依赖项。也就是说,当pip install langchain之后,可能还需要pip install openai,pip install chroma(一种向量数据库)
用下面两种方法,可以在安装LangChain的方法时,引入大多数依赖项。
安装LangChain时包括常用的开源LLM(大预言模型)库:
pip install langchain[llms]
安装完成之后,还需要更新到LangChain的最新版本,这样才能使用较新的工具。
pip install --upgrade langchain
如果想从源代码安装,可以克隆存储库并运行:
pip install -e
LangChain的Github,LangChain也提供了详尽的API文档
# OpenAI API
LangChain本质上就是对各种大模型提供的API的套壳,是为了方便我们使用这些API,搭建起来的一些框架、模块和接口。因此,要了解LangChain的底层逻辑,需要先了解大模型的API的基本设计思路,目前接口最完备的、同时也是最强大的大语言模型,当然是OpenAI提供的GPT家族模型。如果要使用OpenAI API,需要先用科学的方法进行注册,并得到一个 API Key。
有了OpenAI的账号和Key,可以在面板中看到各种信息,比如模型的费用、使用情况等。下面的图片显示了各种模型的访问数量限制信息。其中,TPM和RPM分别代表tokens-per-minute、requests-per-minute。
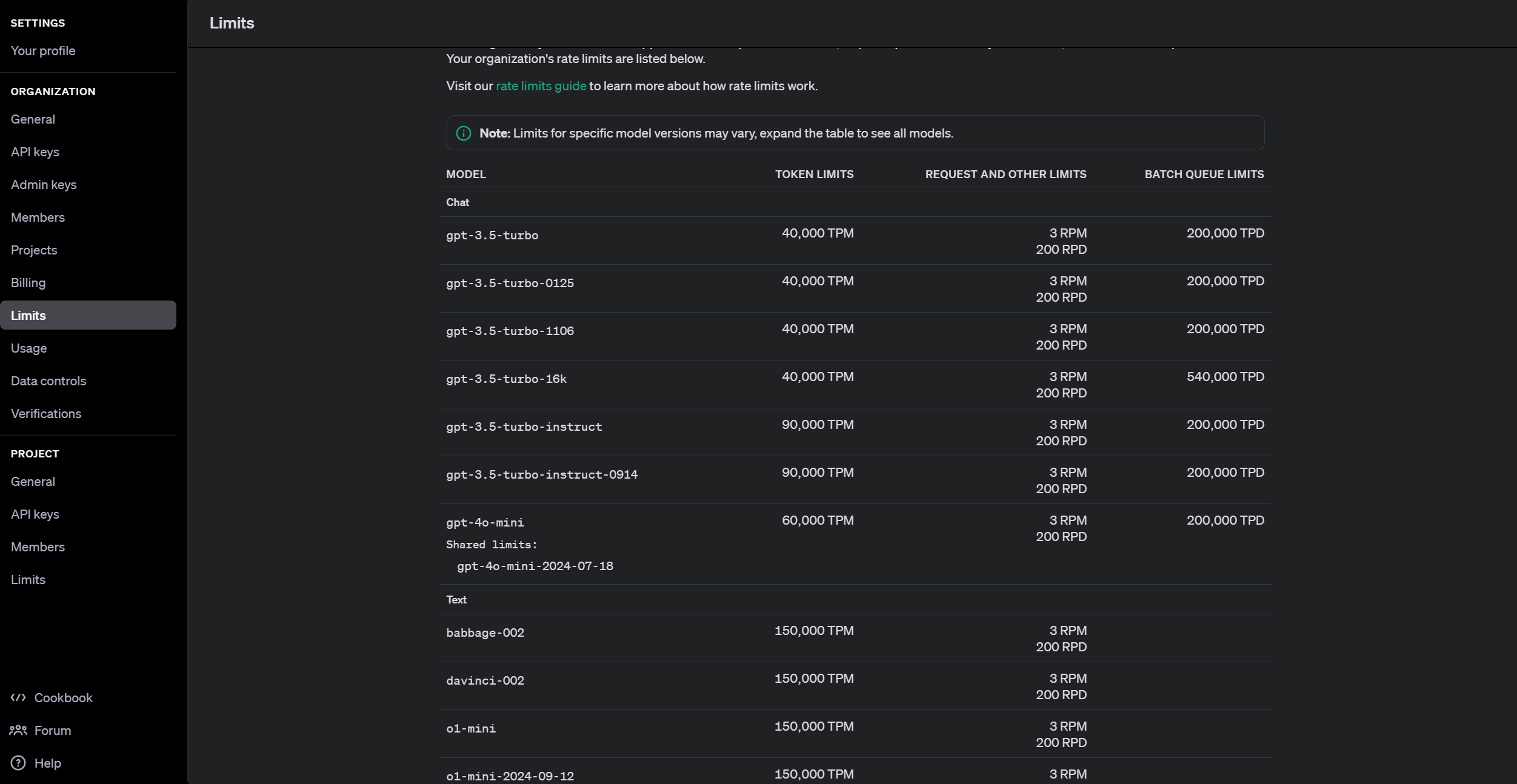
这里,需要重点说明的两类模型,就是图中的Chat Model和Text Model,这两类是大语言模型的代表。OpenAI还提供了Image、Audio和其他类型的模型,目前它们不是LangChain所支持的重点,模型数量也比较少。
- Chat Model,聊天模型: 用于产生人类和AI之间的对话,代表模型是gpt-3.5-turbo(也就是ChatGPT)和GPT-4。
- Text Model,文本模型: 在ChatGPT出来之前,大家都使用这种模型的API来调用GPT-3,文本模型的代表作是text-davinci-003(基于GPT3)。
上面这两种模型,提供的功能类似,都是接收对话输入(input,也叫prompt),返回回答文本(output,也叫response)。但是,它们的调用方式和要求的输入格式是有区别的。
# 调用Text模型
- 先注册好API Key
pip install openai命令安装OpenAI库- 导入OpenAI API Key
导入API Key有多种方式,如下:
import os
os.environ["OPENAI_API_KEY"] = '你的Open API Key'
2
也可以像这样导入OpenAI库,然后指定api_key的值
import openai
openai.api_key = '你的Open API Key'
2
当然,这种把Key直接放在代码里面的方法最不可取,因为不小心共享了代码,密钥就被别人获取了。因此,更好的方法是在操作系统中定义环境变量,比如在Linux系统的命令行中使用:
export OPENAI_API_KEY='Open API Key'
或者,也可以考虑把环境变量保存在.env文件中,使用python-dotenv库从文件中 读取它,这样也可以降低API密钥暴露在代码中的风险。
- 导入OpenAI库,并创建一个Client
from openai import OpenAI
client = OpenAI()
2
- 指定gpt-3.5-turbo-instruct(也就是Text模型)并调用completions方法,返回结果
response = client.completions.create(
model="gpt-3.5-turbo-instruct",
temperature=0.5
max_tokens=100,
prompt="请给我的花店起个名"
)
2
3
4
5
6
import os
from openai import OpenAI
os.environ["OPENAI_API_KEY"] = "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"
client = OpenAI()
response = client.completions.create(
model="gpt-3.5-turbo-instruct",
temperature=0.5,
max_tokens=100,
prompt="请给我的花店起个名"
)
print(response.choices[0].text.strip())
2
3
4
5
6
7
8
9
10
11
12
13
14
15
在使用OpenAI的文本生成模型时,可以通过一些参数来控制输出的内容和样式。

当调用OpenAI的Completion.create方法时,它会返回一个相应对象,该对象包含了模型生成的输出和其他一些信息,这个响应对象是一个字典结构,包含了多个字段。

choices字段是一个列表,因为在某些情况下,可以要求模型生成多个可能的输出,每个选择都是一个字典,其中包含以下字段:
text: 模型生成的文本finish_reason: 模型停止生成的原因,可能的值包括stop(遇到了停止标记)、length(达到了最大长度)或temperature(根据设定的温度参数决定停止)
所以,response.choices[0].text.strip()的含义是: 从响应中获取第一个(如果在调用大模型时,没有指定n参数,那么就只有唯一的一个响应)选择,然后获取该选择的文本,并移除其前后的空白字符。
因为,OpenAI API 需要收费,使用qwen2.5:14b模型试试上面的例子:
from langchain_ollama import ChatOllama
llm = ChatOllama(base_url="http://localhost:11434", model="qwen2.5:14b")
text = llm.invoke("请给我的花店起个名字")
print(text)
2
3
4
5
6

# 调用Chat模型
正题流程上,Chat模型和Text模型的调用是类似的,只是前面加了一个chat,然后输入(prompt)和输出(response)的数据格式有所不同。示例代码如下:
import os
from openai import OpenAI
os.environ["OPENAI_API_KEY"] = "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"
client = OpenAI()
response = client.chat.completions.create(
model="gpt-4",
messages=[
{"role": "system", "content": "You are a creative AI."},
{"role": "user", "content": "请给我的花店起个名字"}
],
temperature=0.8,
max_tokens=60
)
print(response.choices[0].text.strip())
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
这段代码中,除去刚才已经介绍过的temperature、max_tokens等参数之外,有两个专属于Chat模型的概念,一个是消息,一个是角色!
消息: 消息就是传入模型的提示,此处的messages参数是一个列表,包含了多个消息。每个消息都有一个role(可以是system、user或assistant)和content(消息的内容)。系统消息设定了对话的北京,然后用户消息提出了具体的请求,模型的任务是基于这些消息来生成回复。
角色: 在OpenAI的Chat模型中,system、user和assistant都是消息的角色,每一种角色都有不同的含义和作用。
system: 系统消息主要用于设定对话的背景或上下文,这可以帮助模型理解它在对话中的角色和任务。可以通过系统消息来设定一个场景,让模型知道它是在扮演一个医生、律师或者一个知识丰富的AI助手,系统消息通常在对话开始时给出。user: 用户消息是从用户或人类角色发出的,它们通常包含了用户想要模型回答或完成的请求,用户消息可以是一个问题、一段话,或者任何其他用户希望模型响应的内容。assistant: 助手消息是模型的回复,例如,在使用API发送多轮对话中新的对话请求时,可以通过助手消息提供先前对话的上下文,然而,需要注意在对话的最后一条消息应该始终为用户消息,因为模型总是要回应最后这条用户消息。
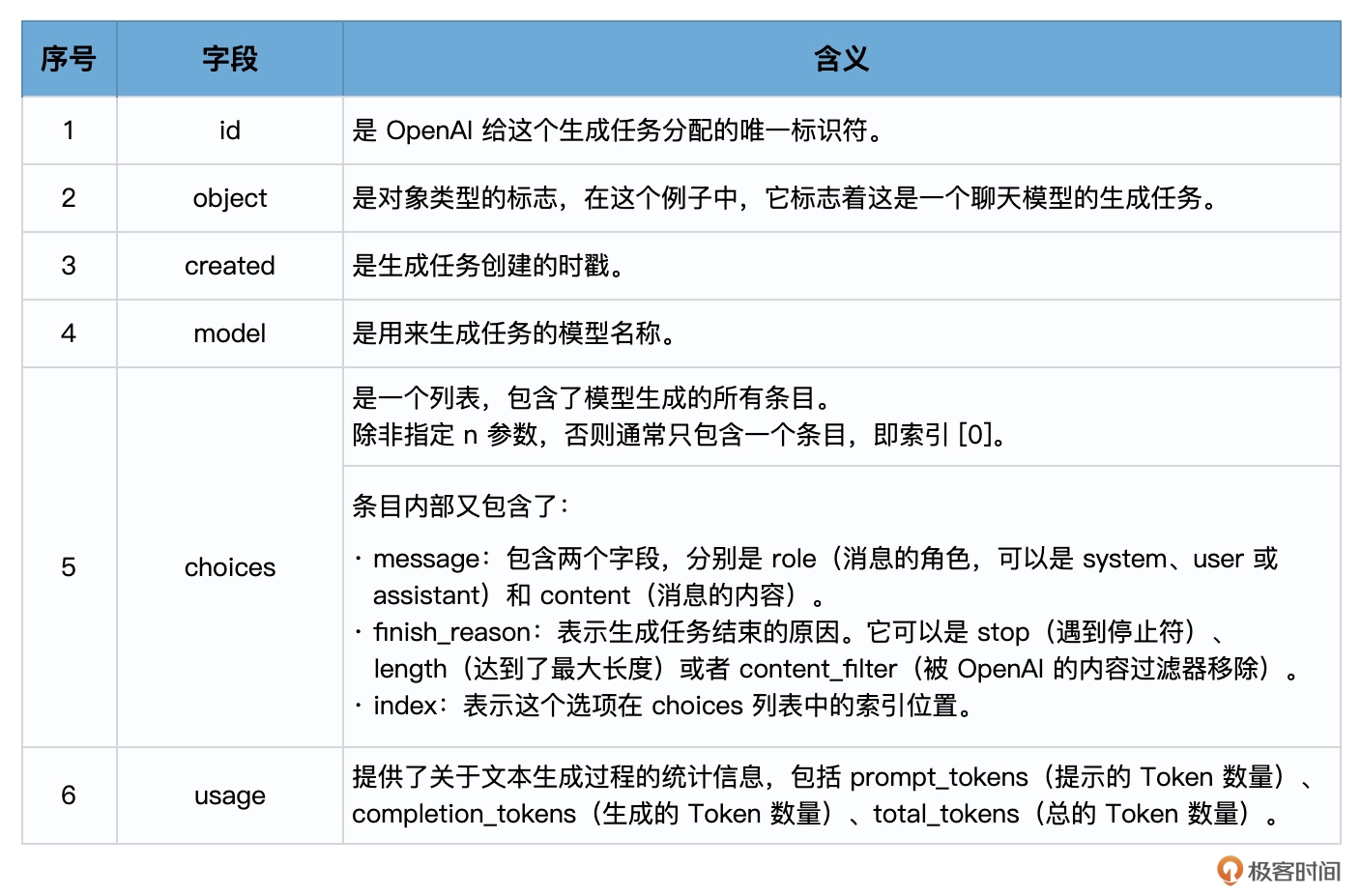
在使用Chat模型生成内容后,返回的响应,也就是response会包含一个或多个choices,每个choices都包含一个message,每个message也都包含一个role和content。role可以是system、user或assistant,表示该消息的发送者,content则包含了消息的实际内容。
一个典型的response对象可能如下:
{
"id": "chatcmpl-2nZI6v1cW9E3Jg4w2Xtoql0M3XHfH",
"object": "chat.completion",
"created": 1677649420,
"model": "gpt-4",
"usage": {"prompt_tokens": 56, "completion_tokens": 31, "total_tokens": 87},
"choices": [
{
"message": {
"role": "assistant",
"content": "你的花店可以叫做\"花香四溢\"。"
},
"finish_reason": "stop",
"index": 0
}
]
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# Chat模型 vs Text模型
相较于Text模型,Chat模型的设计更适合处理对话或者多轮次交互的情况,这是因为它可以接受一个消息列表作为输入,而不仅仅是一个字符串。这个消息列表可以包含system、user和assistant的历史信息,从而在处理交互式对话时提供更多的上下文信息。
- 对话历史的管理: 通过使用Chat模型,可以更方便地管理对话的历史,并在需要时向模型提供这些历史信息。
- 角色模拟: 通过system角色,可以设定对话的背景,给模型提供额外的指导信息,从而更好地控制输出结果。
# 通过LangChain调用Text和Chat模型
- 调用Text模型:
import os
os.environ["OPENAI_API_KEY"] = '你的Open API Key'
from langchain.llms import OpenAI
llm = OpenAI(
model="gpt-3.5-turbo-instruct",
temperature=0.8,
max_tokens=60,)
response = llm.predict("请给我的花店起个名")
print(response)
2
3
4
5
6
7
8
9
- 调用Chat模型:
import os
os.environ["OPENAI_API_KEY"] = '你的Open API Key'
from langchain.chat_models import ChatOpenAI
chat = ChatOpenAI(model="gpt-4",
temperature=0.8,
max_tokens=60)
from langchain.schema import (
HumanMessage,
SystemMessage
)
messages = [
SystemMessage(content="你是一个很棒的智能助手"),
HumanMessage(content="请给我的花店起个名")
]
response = chat(messages)
print(response)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
from langchain_ollama import ChatOllama
from langchain.schema import (
HumanMessage,
SystemMessage
)
llm = ChatOllama(base_url="http://localhost:11434", model="qwen2.5:14b")
messages = [
SystemMessage(content="你是一个很棒的智能助手"),
HumanMessage(content="请给我的花店起个名字")
]
response = llm.invoke(messages)
print(response)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 用LangChain快速构建本地知识库智能问答系统
# 项目及实现框架
项目名称: "易速鲜花"内部员工知识库问答系统
项目介绍: 作为一个大型在线鲜花销售平台,有自己的业务流程和规范,也拥有针对员工的SOP手册。新员工入职培训时,会分享相关的信息。但是,这些信息分散于内部网和HR部门目录各处,有时不便查询;有时因为文档过于冗长,员工无法第一时间找到想要的内容;有时公司政策已更新,但是员工手头的文档还是旧版内容。
基于上述需求,开发一套基于各种内部知识手册的"Doc-QA"系统,这个系统将充分利用LangChain框架,处理从员工手册中产生的各种问题。这个问答系统能够理解员工的问题,并基于最新的员工手册,给出精准的答案。
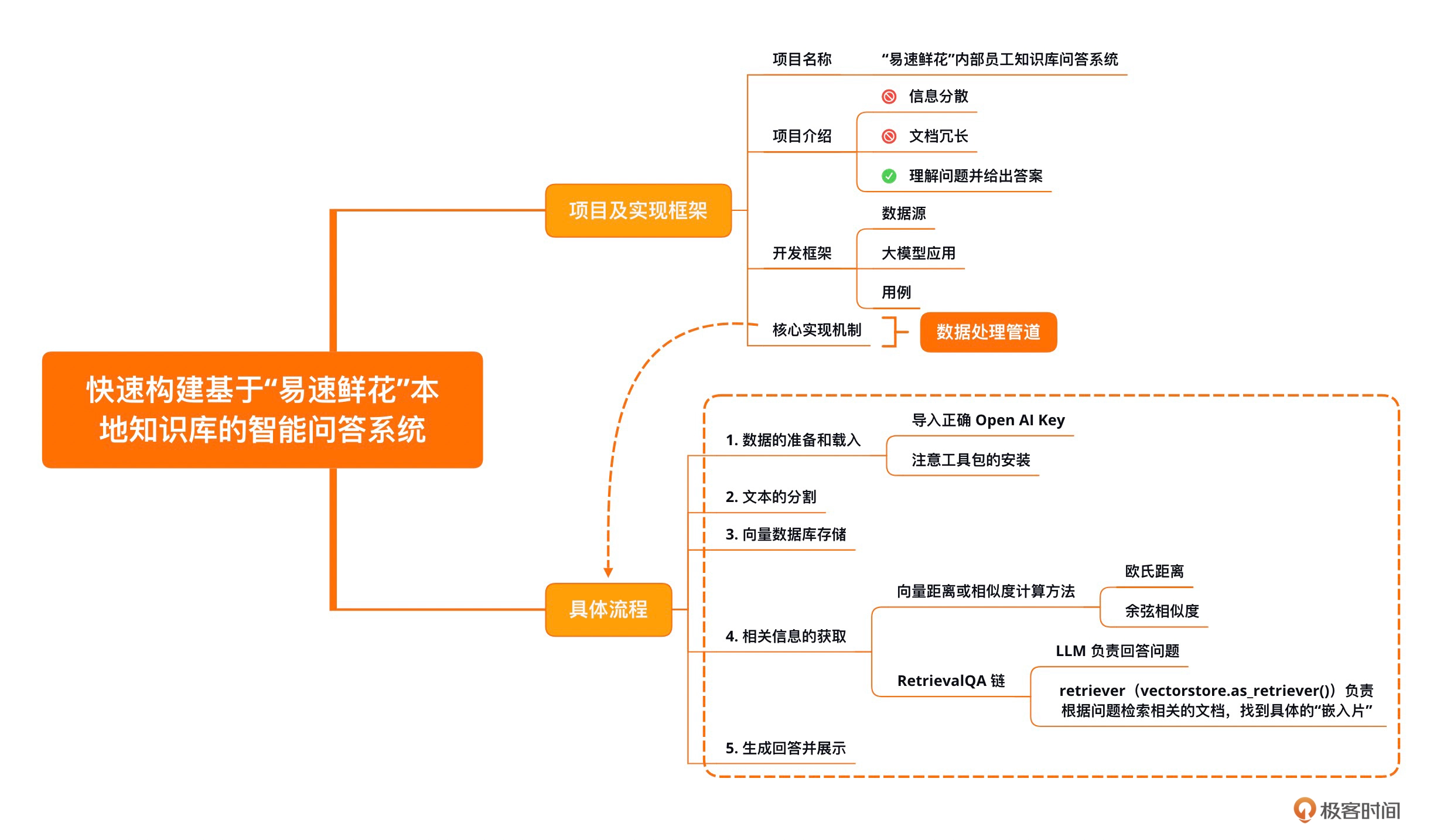
开发框架: 下面这张图片描述了通过LangChain框架实现了一个知识库文档系统的整体框架。
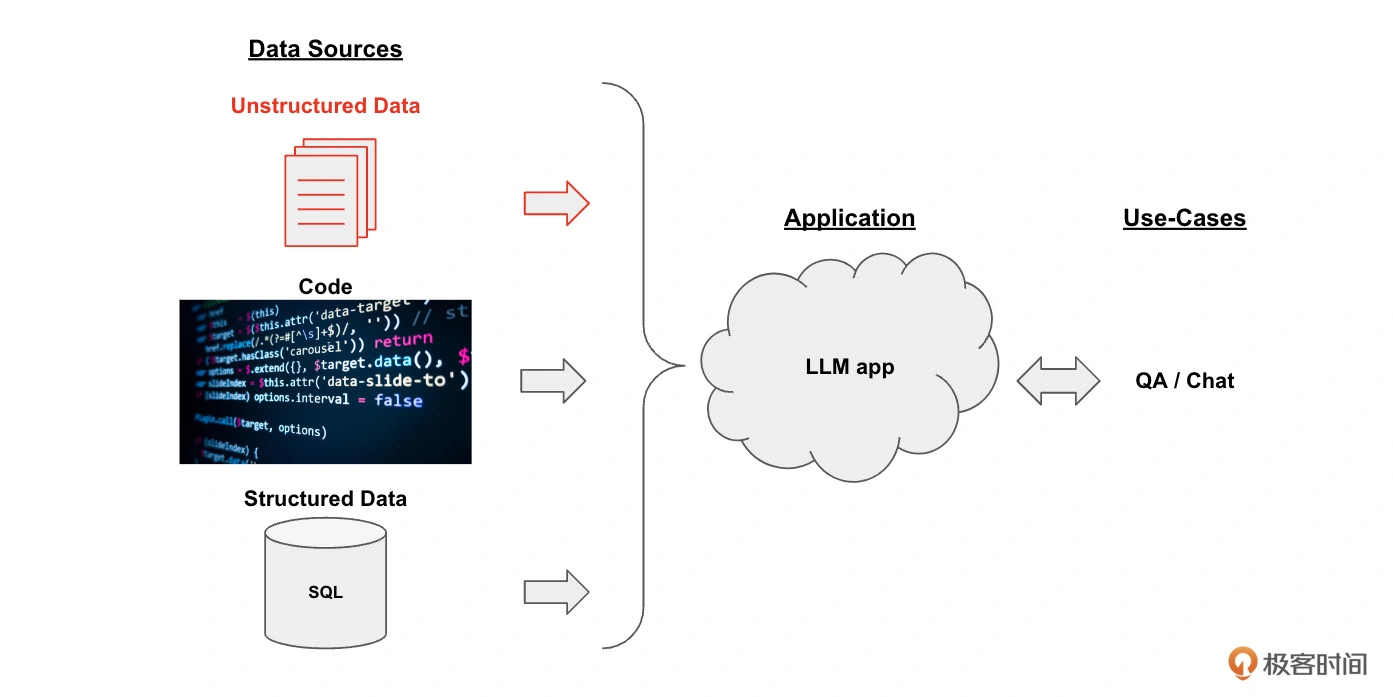
整个框架分为这样三个部分:
- 数据源(Data Sources): 数据可以有很多种,包括PDF在内的非结构化的数据(Unstructured Data)、SQL在内的结构化的数据(Structured Data)、以及Python、Java之类的代码(Code)、在此处,聚焦于对非结构化数据的处理。
- 大模型应用(Application,即LLM App): 以大模型为逻辑引擎,生成我们所需要的回答。
- 用例(Use-Cases): 大模型生成的回答可以构建出QA/聊天机器人等系统。
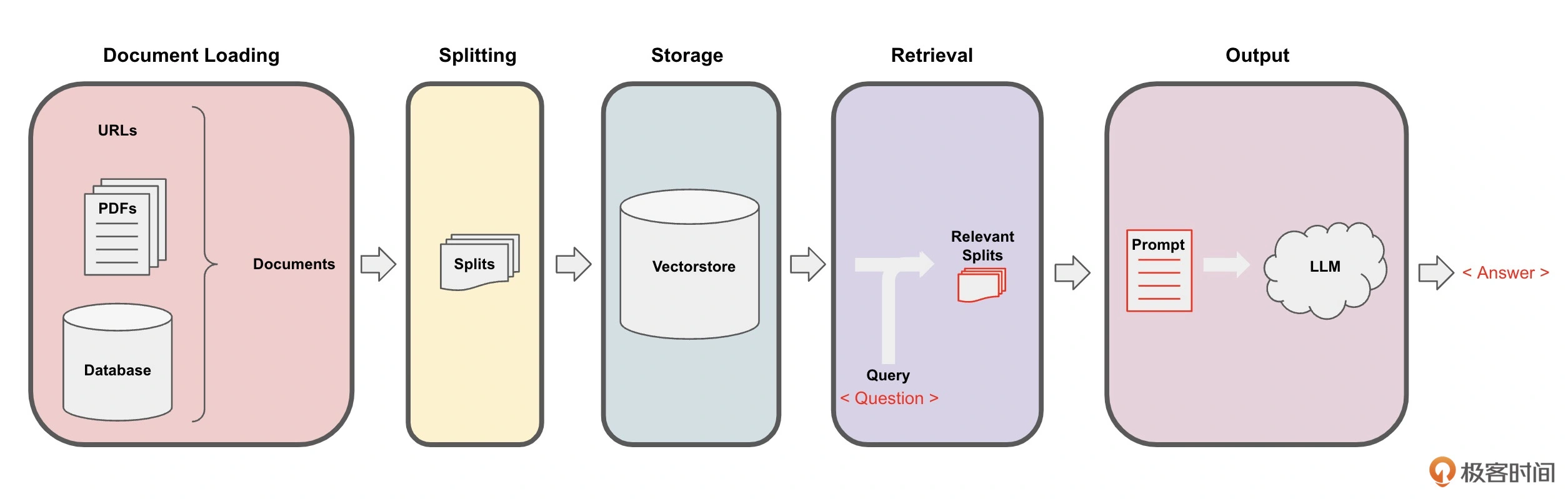
在这个管道的每一步中,LangChain都提供了相关工具,可以轻松实现基于文档的问答功能。具体流程分为下面5步:
- Loading: 文档加载器把Documents加载为以LangChain能够读取的形式
- Splitting: 文本分割器把Documents切分为指定大小的分割,把它们称为"文档块"或者"文档片"
- Storage: 将上一步中分割好的文档块以嵌入(Embedding)的形式存储到向量数据库(Vector DB)中,形成一个个的嵌入片
- Retrieval: 应用程序从存储中检索分割后的文档(例如通过比较余弦相似度,找到与输入问题类似的嵌入片)
- Output: 把问题和相似的嵌入片传递给语言模型(LLM),使用包含问题和检索的分割的提示生成答案。
# 数据的准备和载入
首先用LangChain中的document_loaders来加载各种格式的文本文件,在这一步中,从pdf、word和txt文件中加载文本,然后将这些文本存储在一个列表中。可能需要安装PyPDF、Docx2txt等等。
import os
from langchain.document_loaders import PyPDFLoader
from langchain.document_loaders import Docx2txtLoader
from langchain.document_loaders import TextLoader
base_dir = ".\\demos\\02\\docs"
documents = []
for file in os.listdir(base_dir):
file_path = os.path.join(base_dir, file)
if file.endswith(".pdf"):
loader = PyPDFLoader(file_path)
documents.extend(loader.load())
elif file.endswith(".docx"):
loader = Docx2txtLoader(file_path)
documents.extend(loader.load())
elif file.endswith(".txt"):
loader = TextLoader(file_path)
documents.extend(loader.load())
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 文本的分割
接下来需要将加载的文本分割成更小的块,以便进行嵌入和向量存储,这个步骤中,使用LangChain中的RecursiveCharacterTextSplitter来分割文本。
import os
from langchain_community.document_loaders import PyPDFLoader
from langchain_community.document_loaders import Docx2txtLoader
from langchain_community.document_loaders import TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter, TextSplitter
base_dir = ".\\demos\\02\\docs"
documents = []
for file in os.listdir(base_dir):
file_path = os.path.join(base_dir, file)
if file.endswith(".pdf"):
loader = PyPDFLoader(file_path)
documents.extend(loader.load())
elif file.endswith(".docx"):
loader = Docx2txtLoader(file_path)
documents.extend(loader.load())
elif file.endswith(".txt"):
loader = TextLoader(file_path)
documents.extend(loader.load())
text_splitter = RecursiveCharacterTextSplitter(chunk_size=200, chunk_overlap=10)
chunked_documents = text_splitter.split_documents(documents)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
文档被切成了一个个200字符左右的文档块,这一步,是为把它们存储进下面的向量数据库做准备。
# 向量数据库存储
import os
import chromadb
import logging
from langchain_community.document_loaders import PyPDFLoader
from langchain_community.document_loaders import Docx2txtLoader
from langchain_community.document_loaders import TextLoader
from langchain_ollama import OllamaEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_chroma import Chroma
logging.basicConfig()
logging.getLogger("langchain.retrievers.multi_query").setLevel(logging.INFO)
base_dir = ".\\docs"
documents = []
for file in os.listdir(base_dir):
file_path = os.path.join(base_dir, file)
if file.endswith(".pdf"):
loader = PyPDFLoader(file_path)
documents.extend(loader.load())
elif file.endswith(".docx"):
loader = Docx2txtLoader(file_path)
documents.extend(loader.load())
elif file.endswith(".txt"):
loader = TextLoader(file_path)
documents.extend(loader.load())
text_splitter = RecursiveCharacterTextSplitter(chunk_size=200, chunk_overlap=10)
chunked_documents = text_splitter.split_documents(documents)
embeddings = OllamaEmbeddings(base_url="http://localhost:11434", model="qwen2.5:14b")
chroma_client = chromadb.HttpClient(host="192.168.1.73", port=8000)
db = Chroma(
collection_name="flowers_shop",
embedding_function=embeddings,
client=chroma_client,
# persist_directory=None,
)
db.add_documents(chunked_documents)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
# 相关信息的获取
import logging
import chromadb
from langchain_ollama import ChatOllama, OllamaEmbeddings
from langchain.retrievers.multi_query import MultiQueryRetriever
from langchain_chroma import Chroma
from langchain.chains.combine_documents.stuff import create_stuff_documents_chain
from langchain.chains.retrieval import create_retrieval_chain
from langchain_core.prompts.chat import ChatPromptTemplate
logging.basicConfig()
logging.getLogger("langchain.retrievers.multi_query").setLevel(logging.INFO)
embeddings = OllamaEmbeddings(base_url="http://localhost:11434", model="qwen2.5:14b")
chroma_client = chromadb.HttpClient(host="192.168.1.73", port=8000)
db = Chroma(
collection_name="flowers_shop",
embedding_function=embeddings,
client=chroma_client
)
llm = ChatOllama(base_url="http://localhost:11434", model="qwen2.5:14b")
retriever_from_llm = MultiQueryRetriever.from_llm(retriever=db.as_retriever(), llm=llm)
template = ChatPromptTemplate(
[
("system", "你是一个花店经营助手,你的名字是易速鲜花。"),
("human", "{context}")
]
)
qa_chain = create_stuff_documents_chain(llm=llm, prompt=template)
rag_chain = create_retrieval_chain(retriever=db.as_retriever(), combine_docs_chain=qa_chain)
response = rag_chain.invoke({"input": "该如何宣传花店,如何保障销售额?"})
print(response)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
# 生成回答并展示

# 总结时刻(2)
流程: 先把本地知识切片后做Embedding,存储到向量数据库中,然后把用户的输入和从向量数据库中检索到的本地知识传递给大模型,最终生成回答。
# 思考题(2)
- 简述一下这个基于文档的QA(问答)系统的实现流程?
- LangChain支持很多中向量数据库,能否用另一种常用的向量数据库来实现这个任务?
- LangChain支持很多中大语言模型,能否用HuggingFace网站提供的开源模型
google/flan-t5-x1代替qwen2.5:14b完成这个任务?
# 延伸阅读(2)
- LangChain官方文档对Document QA 系统设计及实现的详细说明
- HuggingFace官网上的文档问答资源
- 论文开放式表格与文本问题回答
# 模型I/O: 输入提示、调用模型、解析输出
模型,位于LangChain框架的最底层,它是基于语言模型构建的应用的核心元素,因为所谓LangChain应用开发,就是以LangChain作为框架,通过API调用大模型来解决具体问题的过程。可以说,整个LangChain框架的逻辑都是由LLM这个发动机来驱动的。
# Model I/O
可以把对模型的使用过程拆解成三块,分别是输入提示(对应图中的Format)、调用模型(对应图中的Predict)和输出解析(对应图中的Parse),这三块形成了一个整体,这个过程被统称为Model I/O(Input/Output)
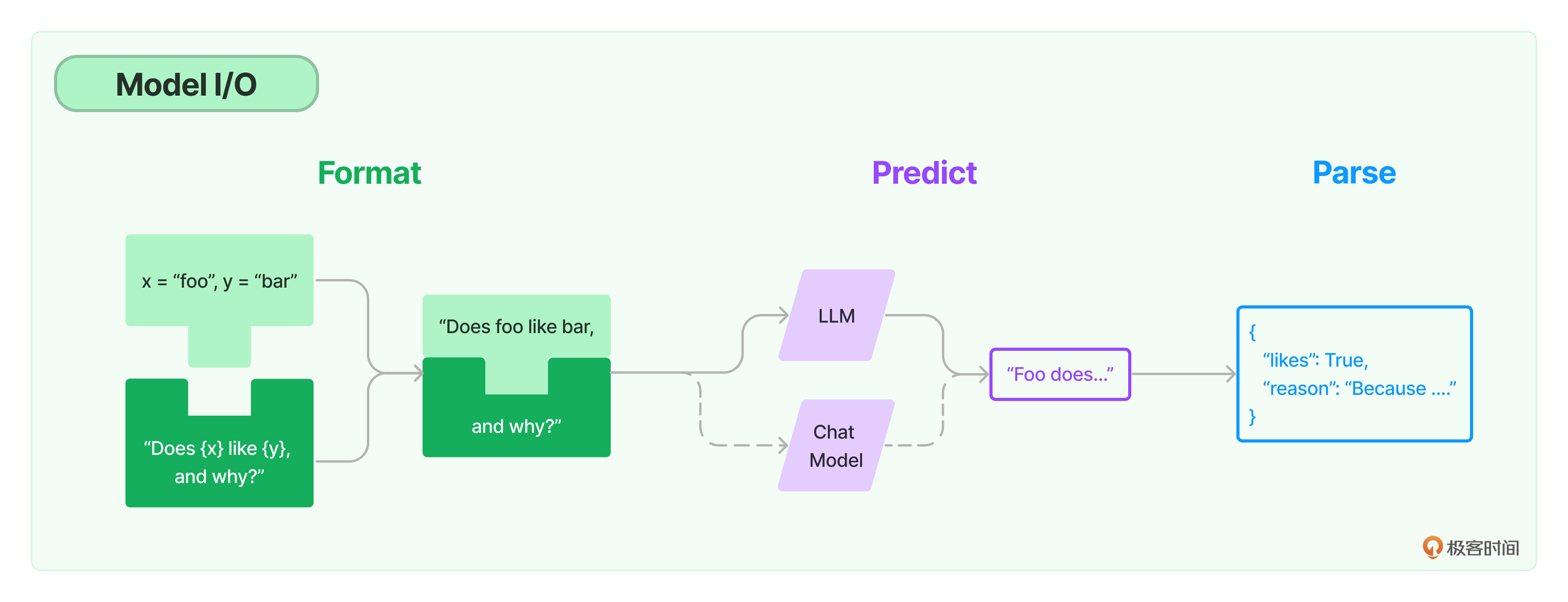
在模型I/O的每个环节,LangChain都提供了模板和工具:
- 提示模板: 使用模型的第一个环节是把提示信息输入到模型中,可以创建LangChain模板,根据实际需求动态选择不同的输入,针对特定的任务和应用调整输入。
- 语言模型: LangChain允许通过通用接口来调用语言模型,这意味着无论要使用哪种语言模型,都可以通过同一种方式进行调用,兼顾灵活和便利。
- 输出解析: LangChain还提供了从模型输出中提取信息的功能,通过输出解析器,可以精确地从模型的输出中获取需要的信息,而不需要处理冗余或不相关的数据,更重要的是还可以把大模型返回的非结构化文本,转换成程序可以处理的结构化数据。
# 提示模板
原则:
- 给予模型清晰明确的指示
- 让模型慢慢地思考
示例:
# 导入LangChain中的提示模板
from langchain.prompts import PromptTemplate
# 创建原始模板
template = """
您是一位专业的鲜花文案撰写员。对于售价为{price}元的{flower_name},您能提供一个吸引人的简短描述吗?
"""
# 根据原始模板创建LangChain提示模板
prompt = PromptTemplate.from_template(template=template)
# 打印LangChain提示模板的内容
print(prompt)
2
3
4
5
6
7
8
9
10
11
所谓模板就是一段描述某种鲜花的文本格式,他是一个f-string,其中有两个变量{flower_name}和{price}表示花的名称和价格,这两个值是模板里面的占位符,在实际使用模板生成提示时会被具体的值替换。
代码中的from_template是一个类方法,允许直接从一个字符串模板中创建一个PromptTemplate对象,打印出这个PromptTemplate对象,可以看到这个对象中的信息包括输入变量(flower_name和price)、输出解析器(这个例子中没有指定)、模板的格式(这个例子中为f-string)、是否验证模板(这个例子中设置为True)。

因此PromptTemplate的from_template方法就是将一个原始的模板字符串转化为一个更丰富、更方便操作的PromptTemplate对象,这个对象就是LangChain中的提示模板,LangChain提供了多个类和函数,也为各种应用场景设计了很多内置模板,使构建和使用提示变得容易。
# 语言模型
LangChain中支持的模型有三类:
- 大语言模型(LLM),也叫Text Model,这些模型将文本字符串作为输入,并返回文本字符串作为输出。
- 聊天模型(Chat Model),主要代表Open AI的ChatGPT系列模型,这些模型通常由语言模型支持,但它们的API更加结构化,具体说,这些模型将聊天信息列表作为输入,并返回聊天消息。
- 文本嵌入模型(Embedding Model),这些模型将文本作为输入并返回浮点数列表,也就是Embedding。文本嵌入模型负责把文档存入向量数据库。
# 导入LangChain中的提示模板
from langchain.prompts import PromptTemplate
from langchain_ollama import ChatOllama
# 创建原始模板
template = """
您是一位专业的鲜花文案撰写员。对于售价为{price}元的{flower_name},您能提供一个吸引人的简短描述吗?
"""
# 根据原始模板创建LangChain提示模板
prompt = PromptTemplate.from_template(template=template)
# 创建模型实例
llm = ChatOllama(base_url="http://localhost:11434", model="qwen2.5:14b")
# 输入提示
input = prompt.format(flower_name="玫瑰", price='50')
# 获取模型输出
output = llm.invoke(input)
# 打印输出内容
print(output)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22

input = prompt.format(flower_name="玫瑰", price='50')这行代码的作用是将模板实例化。
复用提示模板,可以同时生成多个鲜花的文案。
# 导入LangChain中的提示模板
from langchain.prompts import PromptTemplate
from langchain_ollama import ChatOllama
# 创建原始模板
template = """
您是一位专业的鲜花文案撰写员。对于售价为{price}元的{flower_name},您能提供一个吸引人的简短描述吗?
"""
# 根据原始模板创建LangChain提示模板
prompt = PromptTemplate.from_template(template=template)
# 创建模型实例
llm = ChatOllama(base_url="http://localhost:11434", model="qwen2.5:14b")
# 多种鲜花
flowers = ["玫瑰", "百合", "康乃馨"]
prices = ["50", "30", "20"]
# 生成多种花的文案
for flower, price in zip(flowers, prices):
# 使用提示模板生成输入
input_prompt = prompt.format(flower_name=flower, price=price)
# 得到模型输出
output = llm.invoke(input_prompt)
# 打印输出内容
print(output)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
使用LangChain与直接调用大语言模型的API都可以实现相同的功能,不过,LangChain的优势所在,只需要定义一次模板,就可以用它生成各种不同的提示。对比单纯使用f-string来格式化文本,这种方法更加简洁,也更容易维护。而LangChain在提示模板中,还整合了output_parser,template_format以及是否需要validate_template等功能。更重要的,使用LangChain提示模板,还可以方便地把程序切换到不同的模型,而不需要修改任何提示相关的代码。
可以重用模板,重用程序结构,通过LangChain框架调用任何模型,如果熟悉机器学习流程,这LangChain是不是可以联想到PyTorch和TensorFlow框架--模型可以自由选择、自主训练,而调用模型的框架往往是有章法、而且是可复用的。
使用LangChain和提示模板的好处是:
- 代码可读性: 使用模板的话,提示文本更易于阅读和理解,特别是对于复杂的提示或多变量的情况。
- 可复用性: 模板可以在多个地方被复用,让代码更简洁,不需要在每个需要生成提示的地方重新构造提示字符串。
- 维护: 如果后续需要修改提示,使用模板,只需要修改模板即可,不需要在代码中查找所有使用到该提示的地方进行修改。
- 变量处理: 如果提示中涉及到多个变量,模板可以自动处理变量的插入,不需要手动拼接字符串。
- 参数化: 模板可以根据不同的参数生成不同的提示。
# 输出解析
在开发具体应用时,我们不仅需要文字,更多情况是需要程序能够处理的、结构化的数据。
下面,通过LangChain的输出解析器重构程序,让模型有能力生成结构化的回答,同时对其进行解析,将解析好的数据存入CSV文档。
# 导入LangChain中的提示模板
from langchain.prompts import PromptTemplate
from langchain_ollama import ChatOllama
# 创建原始模板
template = """
您是一位专业的鲜花文案撰写员。对于售价为{price}元的{flower},您能提供一个吸引人的简短描述吗?
"""
# 创建模型实例
llm = ChatOllama(base_url="http://localhost:11434", model="qwen2.5:14b", format="json")
# 导入结构化输出解析器和ResponseSchema
from langchain.output_parsers import StructuredOutputParser, ResponseSchema
# 定义接收的响应模式
response_schema = [
ResponseSchema(name="description", description="鲜花的宣传文案"),
ResponseSchema(name="reason", description="文案的解释说明")
]
# 创建输出解析器
output_parser = StructuredOutputParser.from_response_schemas(response_schema)
# 获取格式指示
format_instructions = output_parser.get_format_instructions()
# 根据原始模板创建提示、同时在提示中加入输出解析器说明
# 根据原始模板创建LangChain提示模板
prompt = PromptTemplate.from_template(template=template, partial_variables={"format_instructions": format_instructions})
# 数据准备
flowers = ["玫瑰", "百合", "康乃馨"]
prices = ["50", "30", "20"]
# 创建一个空的DataFrame用于存储结果
# import pandas as pd
# df = pd.DataFrame(columns=["flower", "price", "description", "reason"])
for flower, price in zip(flowers, prices):
# 根据提示准备模型的输入
input = prompt.format(flower=flower, price=price)
# 获取模型的输出
output = llm.invoke(input)
print(output)
# 解析模型的输出(这是一个字典结构)
# parsed_output = output_parser.parse(output)
# 在解析后的输出中添加flower和price
# parsed_output['flower'] = flower
# parsed_output["price"] = price
# 将解析后的输出添加到DataFrame中
# df.loc[len(df)] = parsed_output
# 打印字典
# print(df.to_dict(orient="records"))
# 保存DataFrame到CSV文件
# df.to_csv("flowers_with_descriptions.csv", index=False)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56

这段代码中,首先定义输出结构,希望模型生成的答案包含两部分: 鲜花的描述文案(description)和撰写这个文案的原因(reason),所以定义了一个名为response_schemas的列表,其中包含两个ResponseSchema对象,分别对应这两部分的输出。根据这个列表,通过StructuredOutputParser.from_response_schemas方法创建了一个输出解析器。
然后,通过输出解析器对象的get_format_instructions()方法获取输出的格式说明(format_instructions),再根据原始的字符串模板和输出解析器格式说明创建新的提示模板(这个模板就整合了输出解析结构信息)。再通过新的模板生成模型的输入,得到模型的输出。此时模型的输出结构将尽最大可能遵循指示。
# 总结时刻(3)
LangChain框架的好处:
- 模板管理
- 变量提取和检查
- 模型切换
- 输出解析
# 思考题(3)
- 简述LangChain调用大模型做应用开发的优势
- 上面的示例,format_instructions,也就是输出格式是怎样用output_parser构建出来的,又是怎样传递到提示模板中的?
- 加入了partial_veriables,也就是输出解析器指定的format_instructions之后的提示,为什么能让模型生成结构化的输出?
- 使用输出解析器后,调用模型时有没有可能仍然得不到所希望的输出?模型有没有可能仍然返回格式不够完美的输出?
# 提示工程
思考题: 在提示模板的构建过程中加入了partial_variables,也就是输出解析器指定的format_instructions之后,为什么能够让模型生成结构化的输出?
针对大模型的提示工程如何做,吴恩达ChatGPT Prompt Engineering for Developers公开课中,给出了两大原则:
- 写出清晰而具体的指示
- 给模型思考的时间
在Open AI的官方文档GPT 最佳实践中,给出了6大策略,分别是:
- 写清晰的指示
- 给模型提供参考(也就是示例)
- 将复杂任务拆分成子任务
- 给GPT时间思考
- 使用外部工具
- 反复迭代问题
# 提示的结构

在这个提示框架中:
- 指令(Instuction): 告诉模型这个任务大概要做什么、怎么做,比如如何使用提供的外部信息、如何处理查询以及如何构造输出,这通常是一个提示模板中比较固定的部分。
- 上下文(Context): 充当模型的额外知识来源,这些信息可以手动插入到提示中,通过矢量数据库检索得来,或通过其他方式(如调用API、计算器等工具)拉入。
- 提示输入(Prompt Input): 通常是具体的问题或者需要大模型做的具体事情,这个部分和指令部分其实也可以合二为一。但是拆分出来成为一个独立的组件,就更加结构化,便于复用模板。这通常是作为变量,在调用模型之前传递给提示模板,以形成具体的展示。
- 输出指示器(Output Indicator):标记要生成的文本的开始。
# LangChain 提示模板的类型
LangChain中提供String (StringPromptTemplate)和Chat (BaseChatPromptTemplate)两种基本类型的模板,并基于它们构建了不同类型的提示模板:

from langchain.prompts import PromptTemplate
from langchain.prompts import FewShotPromptTemplate
from langchain.prompts.pipeline import PipelinePromptTemplate
from langchain.prompts import ChatPromptTemplate
from langchain.prompts import (
ChatMessagePromptTemplate,
SystemMessagePromptTemplate,
AIMessagePromptTemplate,
HumanMessagePromptTemplate
)
2
3
4
5
6
7
8
9
10
# 使用PromptTemplate
from langchain.prompts import PromptTemplate
template = """
你是业务咨询顾问。
请给一个销售{product}的电商公司,起一个好听的名字。
"""
prompt = PromptTemplate.from_template(template=template)
print(prompt.format(product="鲜花"))
2
3
4
5
6
7
8
9
10
在上面的示例中,LangChain中的模板的一个方便之处是from_template方法可以从传入的字符串中自动提取变量名称(如product),而无需刻意指定,上面程序中的product自动成为了format方法中的一个参数。
当然也可以通过提示模板的构造函数,在创建模板时手工指定input_variables,示例:
prompt = PromptTemplate(
input_variables=["product", "market"],
template="你是业务咨询顾问。对于一个面向{market}市场的,专注于销售{product}的公司,你会推荐哪个名字?"
)
print(prompt.format(product="鲜花", market="高端"))
2
3
4
5
# 使用ChatPromptTemplate
对于OpenAI推出的ChatGPT这一类的聊天模型,LangChain也提供了一系列的模板,这些模板的不同之处是它们有对应的角色。
from langchain_ollama import ChatOllama
from langchain.prompts import (
ChatPromptTemplate,
SystemMessagePromptTemplate,
HumanMessagePromptTemplate
)
llm = ChatOllama(base_url="http://localhost:11434", model="qwen2.5:14b")
template = "你是一位专业顾问,负责为专注于{product}的公司起名。"
system_message_prompt = SystemMessagePromptTemplate.from_template(template)
human_template="公司主打产品是{product_detail}。"
human_message_prompt = HumanMessagePromptTemplate.from_template(human_template)
prompt_template = ChatPromptTemplate.from_messages([system_message_prompt, human_message_prompt])
prompt = prompt_template.format_prompt(product="鲜花装饰", product_detail="创新的鲜花设计。")
result = llm.invoke(prompt)
print(result)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19

# FewShot的思想起源
Few-Shot(少样本)、One-Shot(单样本)和与之对应的Zero-Shot(零样本)的概念都起源于机器学习。
- 对于Few-Shot Learning,一个重要的参考文献是2016年Vinyals,O.的论文《小样本学习的匹配网络》。
- 这篇论文提出了一种新的学习模型--匹配网络(Matching Networks),专门针对单样本学习(One-Shot Learning)问题设计,而One-Shot Learning可以看作是一种最常见的Few-Shot学习情况。
- 对于Zero-Shot Learning,一个代表性的参考文献是Palatucci,M.在2009年提出的《基于语义输出编码的零样本学习(Zero-Shot Learning with semantic output codes)》,这篇论文提出了零样本学习(Zero-Shot Learning)的概念,其中的学习系统可以根据类的语义描述来识别之前未见过的类。
在提示工程(Prompt Engineering)中,Few-Shot和Zero-Shot学习的概念也被广泛应用
- 在Few-Shot学习设置中,模型会被给予几个示例,以帮助模型理解任务,并生成正确的响应。
- 在Zero-Shot学习设置中,模型只根据任务的描述生成响应,不需要任何示例
而OpenAI在介绍GPT-3模型的重要论文《Language models are Few-Shot learners(语言模型是少样本学习者)》中,指出: GPT-3模型,作为一个大模型的自我监督学习模型,通过提升模型规模,实现了出色的Few-Shot学习性能。
# 使用FewShotPromptTemplate
- 创建示例样本: 作为提示样本,其中每个示例都是一个字典,其中键是输入变量,值是这些输入变量的值
# 1. 创建一些示例
samples = [
{
"flower_type": "玫瑰",
"occasion": "爱情",
"ad_copy": "玫瑰,浪漫的象征,是你向心爱的人表达爱意的最佳选择。"
},
{
"flower_type": "康乃馨",
"occasion": "母亲节",
"ad_copy": "康乃馨代表着母爱的纯洁与伟大,是母亲节赠送给母亲的完美礼物。"
},
{
"flower_type": "百合",
"occasion": "庆祝",
"ad_copy": "百合象征着纯洁与高雅,是你庆祝特殊时刻的理想选择。"
},
{
"flower_type": "向日葵",
"occasion": "鼓励",
"ad_copy": "向日葵象征着坚韧和乐观,是你鼓励亲朋好友的最好方式。"
}
]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
samples这个列表,包含了四个字典,每个字典代表了一种花的类型、适合的场合,以及对应的广告文案,这些示例样本,就是构建FewShotPrompt时,作为例子传递给模型的参考信息。
- 创建提示模板: 将一个示例格式化为字符串,这个格式化程序应该是一个PromptTemplate对象
# 1. 创建一些示例
samples = [
{
"flower_type": "玫瑰",
"occasion": "爱情",
"ad_copy": "玫瑰,浪漫的象征,是你向心爱的人表达爱意的最佳选择。"
},
{
"flower_type": "康乃馨",
"occasion": "母亲节",
"ad_copy": "康乃馨代表着母爱的纯洁与伟大,是母亲节赠送给母亲的完美礼物。"
},
{
"flower_type": "百合",
"occasion": "庆祝",
"ad_copy": "百合象征着纯洁与高雅,是你庆祝特殊时刻的理想选择。"
},
{
"flower_type": "向日葵",
"occasion": "鼓励",
"ad_copy": "向日葵象征着坚韧和乐观,是你鼓励亲朋好友的最好方式。"
}
]
# 2. 创建一个提示模板
from langchain.prompts.prompt import PromptTemplate
template = "鲜花类型: {flower_type}\n场合: {occasion}\n文案: {ad_copy}"
prompt_sample = PromptTemplate(input_variables=["flower_type", "occasion", "ad_copy"], template=template)
print(prompt_sample.format(**samples[0]))
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31

上面的示例中,创建了一个PromptTemplate对象,这个对象根据指定的输入变量和模板字符串来生成提示,在这里,输入变量包括flower_type, occasion, ad_copy,模板是一个字符串,其中包含了用大括号包围的变量名,它们会被对应的变量值替换。到这里,就把字典中的示例格式转换成了提示模板,可以形成一个个具体可用的LangChain提示,比如用samples[0]中的数据替换模板中的变量,生成了一个完整的提示。
- 创建FewShotPromptTemplate对象: 通过使用上一步中创建的prompt_sample,以及samples列表中的所有示例,创建一个FewShotPromptTemplate对象,生成更复杂的提示。
# 1. 创建一些示例
samples = [
{
"flower_type": "玫瑰",
"occasion": "爱情",
"ad_copy": "玫瑰,浪漫的象征,是你向心爱的人表达爱意的最佳选择。"
},
{
"flower_type": "康乃馨",
"occasion": "母亲节",
"ad_copy": "康乃馨代表着母爱的纯洁与伟大,是母亲节赠送给母亲的完美礼物。"
},
{
"flower_type": "百合",
"occasion": "庆祝",
"ad_copy": "百合象征着纯洁与高雅,是你庆祝特殊时刻的理想选择。"
},
{
"flower_type": "向日葵",
"occasion": "鼓励",
"ad_copy": "向日葵象征着坚韧和乐观,是你鼓励亲朋好友的最好方式。"
}
]
# 2. 创建一个提示模板
from langchain.prompts.prompt import PromptTemplate
template = "鲜花类型: {flower_type}\n场合: {occasion}\n文案: {ad_copy}"
prompt_sample = PromptTemplate(input_variables=["flower_type", "occasion", "ad_copy"], template=template)
# print(prompt_sample.format(**samples[0]))
# 3. 创建一个FewShotPromptTemplate对象
from langchain.prompts.few_shot import FewShotPromptTemplate
prompt = FewShotPromptTemplate(
examples=samples,
example_prompt=prompt_sample,
suffix="鲜花类型: {flower_type}\n场合: {occasion}",
input_variables=["flower_type", "occasion"]
)
print(prompt.format(flower_type="野玫瑰", occasion="爱情"))
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
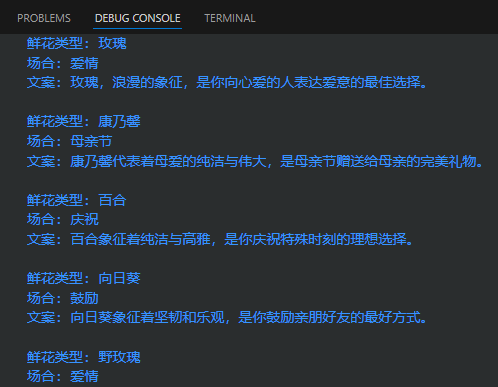
可以看到,FewShotPromptTemplate是一个更复杂的提示模板,它包含了多个示例和一个提示,这种模板可以使用多个示例来指导模型生成对应的输出。
- 调用大模型创建新文案
# 1. 创建一些示例
samples = [
{
"flower_type": "玫瑰",
"occasion": "爱情",
"ad_copy": "玫瑰,浪漫的象征,是你向心爱的人表达爱意的最佳选择。"
},
{
"flower_type": "康乃馨",
"occasion": "母亲节",
"ad_copy": "康乃馨代表着母爱的纯洁与伟大,是母亲节赠送给母亲的完美礼物。"
},
{
"flower_type": "百合",
"occasion": "庆祝",
"ad_copy": "百合象征着纯洁与高雅,是你庆祝特殊时刻的理想选择。"
},
{
"flower_type": "向日葵",
"occasion": "鼓励",
"ad_copy": "向日葵象征着坚韧和乐观,是你鼓励亲朋好友的最好方式。"
}
]
# 2. 创建一个提示模板
from langchain.prompts.prompt import PromptTemplate
template = "鲜花类型: {flower_type}\n场合: {occasion}\n文案: {ad_copy}"
prompt_sample = PromptTemplate(input_variables=["flower_type", "occasion", "ad_copy"], template=template)
# print(prompt_sample.format(**samples[0]))
# 3. 创建一个FewShotPromptTemplate对象
from langchain.prompts.few_shot import FewShotPromptTemplate
prompt = FewShotPromptTemplate(
examples=samples,
example_prompt=prompt_sample,
suffix="鲜花类型: {flower_type}\n场合: {occasion}",
input_variables=["flower_type", "occasion"]
)
# print(prompt.format(flower_type="野玫瑰", occasion="爱情"))
# 4. 把提示传递给大模型
from langchain_ollama import ChatOllama
llm = ChatOllama(base_url="http://localhost:11434", model="qwen2.5:14b")
result = llm.invoke(prompt.format(flower_type="蒲公英", occasion="爱情"))
print(result)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48

# 使用示例选择器
如果示例很多,那么一次性把所有示例发送给模型是不现实而且低效的,另外,每次都包含太多的Token也会浪费流量(OpenAI是按照Token数收取费用)。
LangChain提供了示例选择器,来选择最合适的样本。(注意,因为示例选择器使用向量相似度比较的功能,此处需要安装向量数据库,这里使用开源的Chroma,也可以选择之前用过的Qdrant)
# 1. 创建一些示例
samples = [
{
"flower_type": "玫瑰",
"occasion": "爱情",
"ad_copy": "玫瑰,浪漫的象征,是你向心爱的人表达爱意的最佳选择。"
},
{
"flower_type": "康乃馨",
"occasion": "母亲节",
"ad_copy": "康乃馨代表着母爱的纯洁与伟大,是母亲节赠送给母亲的完美礼物。"
},
{
"flower_type": "百合",
"occasion": "庆祝",
"ad_copy": "百合象征着纯洁与高雅,是你庆祝特殊时刻的理想选择。"
},
{
"flower_type": "向日葵",
"occasion": "鼓励",
"ad_copy": "向日葵象征着坚韧和乐观,是你鼓励亲朋好友的最好方式。"
}
]
# 2. 使用示例选择器
from langchain.prompts.example_selector import SemanticSimilarityExampleSelector
import chromadb
from langchain_chroma import Chroma
from langchain_ollama import OllamaEmbeddings
# 初始化示例选择器
embeddings = OllamaEmbeddings(base_url="http://localhost:11434", model="qwen2.5:14b")
chroma_client = chromadb.HttpClient(host="192.168.1.73", port=8000)
db = Chroma(
collection_name="flowers_shop",
embedding_function=embeddings,
client=chroma_client
)
example_selector = SemanticSimilarityExampleSelector.from_examples(
samples,
embeddings,
db,
k=1
)
# 创建一个使用示例选择器的FewShotPromptTemplate对象
from langchain.prompts.prompt import PromptTemplate
from langchain.prompts.few_shot import FewShotPromptTemplate
template = "鲜花类型: {flower_type}\n场合: {occasion}\n文案: {ad_copy}"
prompt_sample = PromptTemplate(input_variables=["flower_type", "occasion", "ad_copy"], template=template)
prompt = FewShotPromptTemplate(
example_selector=example_selector,
example_prompt=prompt_sample,
suffix="鲜花类型: {flower_type}\n场合: {occasion}",
input_variables=["flower_type", "occasion"]
)
print(prompt.format(flower_type="红玫瑰", occasion="爱情"))
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57

在这个步骤中,它首先创建了一个SemanticSimilarityExampleSelector对象,这个对象可以根据语义相似性选择最相关的示例。然后,它创建了一个新的FewShotPromptTemplate对象,这个对象使用了上一步创建的选择器来选择最相关的示例生成提示。
然后,用这个模板生成了一个新的提示,因为提示中需要创建的是红玫瑰的文案,所以,示例选择器example_selector会根据语义的相似度(余弦相似度)找到最相似的示例,也就是玫瑰,并用这个示例构建了FewShot模板。
# 总结时刻(4)

总的来说,提供示例对于解决某些任务至关重要,通常情况下,FewShot的方式能够显著提高模型回答的质量,不过,当少样本提示的效果不佳时,可能表示模型在任务上的学习不足。在这种情况下,建议对模型进行微调或尝试更高级的提示技术。
# 思考题(4)
- 如果观察LangChain中的prompt.py中的PromptTemplate的实现代码,会发现除了使用过的input_variables、template等初始化参数之外,还有template_format、validate_template等参数。举例来说,template_format可以指定除了f-string之外,其他格式的模板,比如jinja2。具体详情可以查看LangChain文档。

请尝试使用PipelinePromptTemplate和自定义Template
请你构想一个关于鲜花店运营场景中客户服务对话的少样本学习任务。在这个任务中,模型需要根据提供的示例,学习如何解答客户的各种问题,包括询问鲜花的价格、推荐鲜花、了解鲜花的保养方法等。
from langchain.chat_models import ChatOpenAI
from langchain import PromptTemplate
from langchain.prompts.chat import (
ChatPromptTemplate,
SystemMessagePromptTemplate,
AIMessagePromptTemplate,
HumanMessagePromptTemplate)
2
3
4
5
6
7
# 延伸阅读(4)
- 论文: Open AI 的 GPT-3 模型:大模型是少样本学习者, Brown, T. B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., … & Agarwal, S. (2020). Language models are few-shot learners. arXiv preprint arXiv:2005.14165.
- 论文: 单样本学习的匹配网络,Vinyals, O., Blundell, C., Lillicrap, T., & Wierstra, D. (2016). Matching networks for one shot learning. In Advances in neural information processing systems (pp. 3630-3638).
- 论文: 用语义输出编码做零样本学习,Palatucci, M., Pomerleau, D., Hinton, G. E., & Mitchell, T. M. (2009). Zero-shot learning with semantic output codes. In Advances in neural information processing systems (pp. 1410-1418).
- 论文: 对示例角色的重新思考:是什么使得上下文学习有效?Min, S., Lyu, X., Holtzman, A., Artetxe, M., Lewis, M., Hajishirzi, H., & Zettlemoyer, L. (2022). Rethinking the Role of Demonstrations: What Makes In-Context Learning Work? Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing (EMNLP 2022).
- 论文: 微调后的语言模型是零样本学习者,Wei, J., Bosma, M., Zhao, V. Y., Guu, K., Yu, A. W., Lester, B., Du, N., Dai, A. M., & Le, Q. V. (2022). Finetuned Language Models Are Zero-Shot Learners. Proceedings of the International Conference on Learning Representations (ICLR 2022).
# 什么是 Chain of Thought
思维链CoT(Chain of Thought),CoT的概念来源于学术界,是谷歌大脑的Jason Wei等人于2022年在论文《Chain-of-Thought Prompting Elicits Reasoning in Large Language Models》(自我一致性提升了语言模型中的思维链推理能力)中提出的概念。它提出,如果生成一系列的中间推理步骤,就能够显著提高大型语言模型进行复杂推理的能力。
# Few-Shot CoT
Few-Shot CoT简单的在提示中提供了一些链式思考示例(Chain-of-Thought Prompting),足够大的语言模型的推理能力就能够被增强,简单说,就是给出一两个示例,然后在示例中些清楚推导的过程。
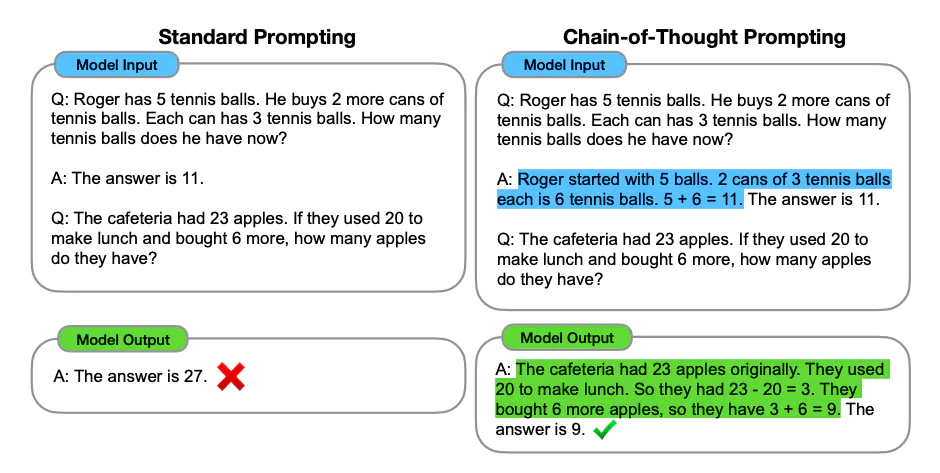
论文中给出了一个大模型通过思维链做数学题的示例,图左和图右,大模型都读入了OneShot示例,但是图左只给出了答案,而图右则在OneShot示例中给出了解题的具体思路。结果,只给出了答案的模型推理错误,而给出解题思路后,同一个模型生成了正确的答案。
在三种大型语言的实验中,CoT在一系列的算术、常识和符号推理任务中都提高了性能,在GSM8K数学问题基准测试中,通过CoT指导后,大模型的表现可以达到当时最先进的准确性。
假设需要开发一个AI花店助手,它的任务是帮助用户选择他们想要的花,并生成一个销售列表,在这个过程中,可以使用CoT来引导AI的推理过程。
问题理解: 首先,AI需要理解用户的需求。例如,用户可能会说: "今天要参加朋友的生日Party,想送一束花祝福她。"可以给AI一个提示模板,里面包含示例: "遇到XX问题,我先看自己有没有相关的知识,有的话就提供答案;没有,就调用工具搜索,有了知识后再试图解决。"--这就是给了AI一个思维链的示例。
信息搜索: 接下来,AI需要搜索相关信息,例如,它可能需要查找哪些花最适合生日派对。
决策制定: 基于收集到的信息,AI需要制定一个决策。可以通过思维链让他详细思考决策的流程,先做什么后做什么。例如,可以给他一个示例: "遇到生日派对送花的情况,我先考虑用户的需求,然后查看鲜花的库存,最后决定推荐一些玫瑰和百合,因为这些花通常适合生日派对。"--那么有了生日派对这个场景做示例,大模型就能把类似的思维流程运用到其他场景。
生成销售列表: 最后,AI使用OutputParser生成一个销售列表,包括推荐的花和价格。
在这个过程中,正题上,思维链引导AI从理解问题,到搜索信息,再到制定决策,最后生成销售列表。这种方法不仅能够使AI的推理过程更加清晰,也使得生成的销售列表更加符合用户的需求。具体到每一个步骤,也可以通过思维链来设计更为详细的提示模板,来引导模型每一步的思考都遵循清晰准确的逻辑。
其实,LangChain的核心组件Agent的本质就是进行好的提示工程,并大量地使用预置的FewShot和CoT模板。
# Zero-Shot CoT
下面的这两个CoT提示模板的例子,来自于Google Research和东京大学的论文《大语言模型是零样本推理者》
图中的示例非常有意思,在Zero-Shot CoT中,只要简单地告诉模型"Let's think step by step",模型就能够给出更好的答案。

这不由得让人联想起最简单的提示工程,角色设定--模型回答之前,先告诉它"你是一个很有经验的专家",模型就会在开始胡说八道之前三思。
Few-Shot CoT就是在带有示例的提示过程中,加入思考的步骤,从而引导模型给出更好的结果。而Zero-Shot CoT就是直接告诉模型要一步一步思考,慢慢推理。
# Chain of Thought 实战
项目需求: 在这个示例中,需要开发一个AI运营助手,目的是展示AI如何根据用户的需求推理和生成答案。然后,AI根据当前的用户请求进行推理,提供了具体的花卉建议并解释为什么选择这些建议。
# CoT模板设计
针对这个聊天机器人,设计下面的思维链模板:
作为一个为花店电商公司工作的AI助手,我的目标是帮助客户根据他们的喜好做出明智的决定。
我会按部就班的思考,先理解客户的需求,然后考虑各种鲜花的涵义,最后根据这个需求,给出我的推荐。
同时,我也会想客户解释我这样推荐的原因。
示例1:
人类: 我想找一种象征爱情的花。
AI: 首先,我理解你正在寻找一种可以象征爱情的花。在许多文化中,红玫瑰被视为爱情的象征,这是因为它们的红色通常于热情和浓烈的感情联系在一起。因此,考虑到这一点,我会推荐红玫瑰。红玫瑰不仅能够象征爱情,同时也可以传达出强烈的感情,这是你在寻找的。
示例2:
人类: 我想要一些独特和奇特的花。
AI: 从你的需求中,我理解你想要的是独一无二和引入注目的花朵。兰花是一种非常独特并且颜色鲜艳的花,它们在世界上的许多地方都被是为奢侈品和美的象征。因此,我建议你考虑兰花。选择兰花可以满足你对独特和奇特的要求,而且,兰花的美丽和它们所代表的力量和奢侈也可能会吸引你。
# 程序的完整框架
# 创建聊天模型
from langchain_ollama import ChatOllama
llm = ChatOllama(base_url="http://localhost:11434", model="qwen2.5:14b")
# 设定AI的角色和目标
role_template = "你是一个为花店电商公司工作的AI助手,你的目标是帮助客户根据她们的喜好做出明智的决定。"
# CoT的关键部分,AI 解释推理过程,并加入一些先前的对话示例(Few-Shot Learning)
cot_template = """
作为一个为花店电商公司工作的AI助手,我的目标是帮助客户根据他们的喜好做出明智的决定。
我会按部就班的思考,先理解客户的需求,然后考虑各种鲜花的涵义,最后根据这个需求,给出我的推荐。
同时,我也会向客户解释我这样推荐的原因。
示例 1:
人类:我想找一种象征爱情的花。
AI:首先,我理解你正在寻找一种可以象征爱情的花。在许多文化中,红玫瑰被视为爱情的象征,这是因为它们的红色通常与热情和浓烈的感情联系在一起。因此,考虑到这一点,我会推荐红玫瑰。红玫瑰不仅能够象征爱情,同时也可以传达出强烈的感情,这是你在寻找的。
示例 2:
人类:我想要一些独特和奇特的花。
AI:从你的需求中,我理解你想要的是独一无二和引人注目的花朵。兰花是一种非常独特并且颜色鲜艳的花,它们在世界上的许多地方都被视为奢侈品和美的象征。因此,我建议你考虑兰花。选择兰花可以满足你对独特和奇特的要求,而且,兰花的美丽和它们所代表的力量和奢侈也可能会吸引你。
"""
from langchain.prompts import ChatPromptTemplate, HumanMessagePromptTemplate, SystemMessagePromptTemplate
system_prompt_role = SystemMessagePromptTemplate.from_template(role_template)
system_prompt_cot = SystemMessagePromptTemplate.from_template(cot_template)
# 用户的询问
human_template = "{human_input}"
human_prompt = HumanMessagePromptTemplate.from_template(human_template)
# 将以上信息结合为一个聊天提示
chat_prompt = ChatPromptTemplate.from_messages([system_prompt_role, system_prompt_cot, human_prompt])
prompt = chat_prompt.format_prompt(human_input="我想为女朋友购买一些花。她喜欢粉色和紫色。你有什么建议吗?").to_messages()
# 接收用户的询问,返回回答结果
result = llm.invoke(prompt)
print(result)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37

通过调用ChatOllama类,创建了一个聊天模型。接着定义了AI的角色和目标,该AI为花店电商公司的助手,其目标是根据客户的喜好来提供购买的建议。紧接着,定义CoT模板,其中包括了AI的角色和目标描述、思考链条以及遵循思考链条的一些示例,显示了AI如何理解问题,并给出建议。之后,使用了PromptTemplate的from_template方法,来生成相应的询问模板。其中包括用于指导模型的SystemMessagePromptTemplate和用于传递人类问题的HumanMessagePromptTemplate。然后,使用ChatPromptTemplate.from_messages方法,整合上述定义的角色,CoT模板和用户询问,生成聊天提示。最后,将生成的聊天提示输入模型中,获得回答。
# Tree of Thought
CoT这种思想,为大模型带来了更好的答案,然而对于需要探索或预判战略的复杂任务来说,传统或简单的提示技巧是不够的。基于CoT思想,Yao和Long等人几乎在同一时间在论文《思维之树:使用大型语言模型进行深思熟虑的问题解决》和《大型语言模型指导的思维之树》中,进一步提出了思维树(Tree of Thoughts, ToT)框架,该框架基于思维链提示进行了总结,引导语言模型探索把思维作为中间步骤来解决通用问题。
ToT是一种解决复杂问题的框架,它在需要多步骤推理的任务中,引导语言模型搜索一棵由连贯的语言序列(解决问题的中间步骤)组成的思维树,而不是简单地生成一个答案。ToT框架的核心思想是: 让模型生成和评估其思维能力,并将其与搜索算法(如广度优先搜索和深度优先搜索)结合起来,进行系统地探索和验证。
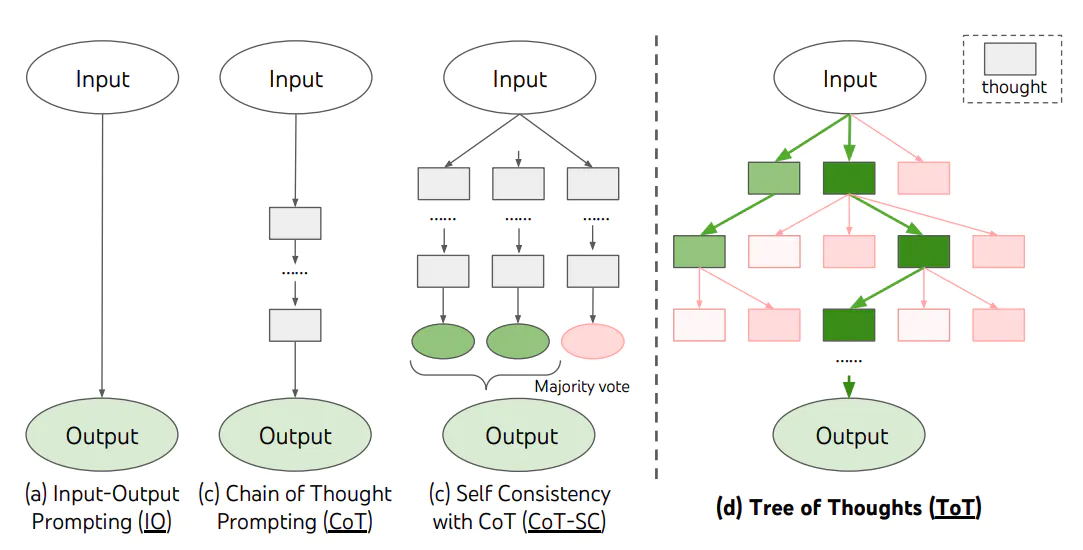
ToT框架为每个任务定义具体的思维步骤和每个步骤的候选项数量。例如,要解决一个数学推理任务,先把它分解为3个思维步骤,并为每个步骤提出多个方案,并保留最优的5个候选方案。然后在多条思维路径中搜寻最优的解决方案。
这种方法的优势在于,模型可以通过观察和评估其自身的思维过程,更好地解决问题,而不仅仅是基于输入生成输出。这对于深度推理的复杂任务非常有用。此外,通过引入强化学习、集束搜索等技术,可以进一步提高搜索策略的性能,并让模型在解决新问题或面临未知情况时有更好的表现。
基于ToT思想鲜花运营方面的示例:
假设一个顾客在鲜花网站上询问:“我想为我的妻子购买一束鲜花,但我不确定应该选择哪种鲜花。她喜欢淡雅的颜色和花香。”
AI(使用 ToT 框架):
思维步骤 1:理解顾客的需求。
顾客想为妻子购买鲜花。
顾客的妻子喜欢淡雅的颜色和花香。
思维步骤 2:考虑可能的鲜花选择。
候选 1:百合,因为它有淡雅的颜色和花香。
候选 2:玫瑰,选择淡粉色或白色,它们通常有花香。
候选 3:紫罗兰,它有淡雅的颜色和花香。
候选 4:桔梗,它的颜色淡雅但不一定有花香。
候选 5:康乃馨,选择淡色系列,它们有淡雅的花香。
思维步骤 3:根据顾客的需求筛选最佳选择。
百合和紫罗兰都符合顾客的需求,因为它们都有淡雅的颜色和花香。
淡粉色或白色的玫瑰也是一个不错的选择。
桔梗可能不是最佳选择,因为它可能没有花香。
康乃馨是一个可考虑的选择。
思维步骤 4:给出建议。
“考虑到您妻子喜欢淡雅的颜色和花香,我建议您可以选择百合或紫罗兰。淡粉色或白色的玫瑰也是一个很好的选择。希望这些建议能帮助您做出决策!”
这个例子,可以作为FewShot示例之一,传递给模型,让其实现ToT。
通过在具体的步骤中产生多条思考路径,ToT框架为解决复杂问题提供了一种新的方法,这种方法结合了语言模型的生成能力、搜索算法以及强化学习,以达到更好的效果。
# 总结时刻(5)
- CoT的核心思想是通过生成一系列中间推理步骤来增强模型的推理能力。在Few-Shot CoT和Zero-Shot CoT两种应用方法中,前者是通过提供链式思考示例传递给模型,后者则直接告诉模型进行按部就班的推理。
- ToT进一步扩展了CoT的思想,通过搜索由连贯的语言序列组成的思维树来解决复杂的问题。ToT GitHub Repo
# 思考题(5)
- CoT实战示例中使用的是Few-Shot CoT提示,请尝试使用Zero-Shot CoT完成一个示例看下效果
- 请设计一个工作场景中任务需求,使用ToT让大语言模型解决。
# 延伸阅读(5)
- 论文,自我一致性提升了语言模型中的思维链推理能力,Chain-of-Thought Prompting Elicits Reasoning in Large Language Models,Wang, X., Wei, J., Schuurmans, D., Le, Q., Chi, E., Narang, S., Chowdhery, A., & Zhou, D. (2023). Self-Consistency Improves Chain of Thought Reasoning in Language Models. Proceedings of the International Conference on Learning Representations (ICLR). arXiv preprint arXiv:2203.11171.
- 论文,大语言模型是零样本推理者,Large Language Models are Zero-Shot Reasoners,Kojima, T., Gu, S. S., Reid, M., Matsuo, Y., & Iwasawa, Y. (2023). Large Language Models are Zero-Shot Reasoners. arXiv preprint arXiv:2205.11916v4.
- 论文,思维之树:使用大型语言模型进行深思熟虑的问题解决,Tree of Thoughts: Deliberate Problem Solving with Large Language Models,Yao, S., Yu, D., Zhao, J., Shafran, I., Griffiths, T. L., Cao, Y., & Narasimhan, K. (2023). Tree of Thoughts: Deliberate Problem Solving with Large Language Models. arXiv preprint arXiv:2305.10601.
- 论文,大型语言模型指导的思维之树,Large Language Model Guided Tree-of-Thought,Long, J. (2023). Large Language Model Guided Tree-of-Thought. arXiv preprint arXiv:2305.08291.
- GitHub 链接,tree-of-thoughts,把 ToT 算法导入你的大模型应用,目前 3.3K 颗星
# 调用模型
问题: 大语言模型,不止ChatGPT,调用OpenAI的API,当然方便且高效,但是,如果想用其他的模型(比如说开源的Llama2或者ChatGLM),如何做?再进一步,如果想在本机上从头训练出一个模型,然后在LangChain中使用自己的模型,又该如何做?
关于大模型的微调(或称精调)、预训练、重新训练、乃至从头训练,是一个相当大的话题,不仅仅需要足够的知识和经验,还需要大量的语料数据、GPU和强大的工程能力。
# 大语言模型发展史
Google 2018年的论文名篇Attention is all you need,提出了Transformer架构,也给这一次AI的腾飞埋下了伏笔。Transformer几乎是所有预训练模型的核心底层架构。基于Transformer预训练所得到的大规模语言模型也被叫做基础模型(Foundation Model 或 Base Model)。
在这个过程中,模型学习了词汇、语法、句子结构以及上下文信息等丰富的语言知识。这种在大量数据上学到的知识,为后续的下游任务(如情感分析、文本分类、命名实体识别、问答系统等)提供了一个通用的、丰富的语言表示基础,为解决许多复杂的NLP问题提供了可能。
在预训练模型出现的早期,BERT毫无疑问是最具代表性的,也是影响力最大的模型。BERT通过同时学习文本的前向和后向上下文信息,实现对句子结构的深入理解。BERT之后,各种大型预训练模型如雨后春笋般地涌现,自然语言处理(NLP)领域进入了一个新时代。这些模型推动了NLP技术的快速发展,解决了许多以前难以应对的问题,比如翻译、文本总结、聊天对话等等。
现今的预训练模型的趋势是参数越来越多,模型也越来越大,训练一次的费用可达几百万美元。这样大的开销和资源消耗,只有世界顶级大厂才能负担起,普通的学术组织和高等院校很难在这个领域继续引领科技突破。
# 预训练 + 微调的模式
经过预训练的大模型中所习得的语义信息和所蕴含的语言知识,能够非常容易地向下游任务迁移。NLP应用人员可以对模型的头部或者部分参数根据自己的需要进行适应性的调整,这通常涉及在较小的有标注数据集上进行有监督学习,让模型适应特定任务的需求。这就是对预训练模型的微调(Fine-tuning)。
- 预训练: 在大规模无标注文本数据上进行模型的训练,目标是让模型学习自然语言的基础表达、上下文信息和语义知识,为后续任务提供一个通用的、丰富的语言表示基础。
- 微调: 在预训练模型的基础上,可以根据特定的下游任务对模型进行微调。领域知识,垂直领域,垂类模型,指的就是根据领域数据微调开源模型。
预训练 + 微调的大模型优势: 减少训练时间和数据需求,简化部署难度,有很强的扩展性。
# 用HuggingFace跑开源模型
# 注册并安装HuggingFace
- 登录HuggingFace,拿到Token
- 用
pip install transformers安装HuggingFace Library。详见这里 - 在命令行中运行
huggingface-cli login,设置API Token。
当然也可以在程序中设置API Token,但是不如在命令行中设置来得安全。
# 导入HuggingFace API Token
import os
os.environ['HUGGINGFACEHUB_API_TOKEN'] = '你的HuggingFace API Token'
2
3
# 申请使用Meta的Llama2模型
在HuggingFace的Model中,找到meta-llama/Llama-2-7b。
选择meta-llama/Llama-2-7b这个模型后,如果是第一次用,需要申请Access。
# 通过HuggingFace调用Llama
# 导入必要的库
from transformers import AutoTokenizer, AutoModelForCausalLM
# 加载预训练模型的分词器
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-7b-chat-hf")
# 加载预训练的模型
# 使用 device_map 参数将模型自动加载到可用的硬件设备上,例如GPU
model = AutoModelForCausalLM.from_pretrained(
"meta-llama/Llama-2-7b-chat-hf",
device_map = 'auto')
# 定义一个提示,希望模型基于此提示生成故事
prompt = "请给我讲个玫瑰的爱情故事?"
# 使用分词器将提示转化为模型可以理解的格式,并将其移动到GPU上
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
# 使用模型生成文本,设置最大生成令牌数为2000
outputs = model.generate(inputs["input_ids"], max_new_tokens=2000)
# 将生成的令牌解码成文本,并跳过任何特殊的令牌,例如[CLS], [SEP]等
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
# 打印生成的响应
print(response)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
上面的示例是一个很典型的HuggingFace的Transformers库的用例,该库提供了大量预训练的模型和相关的工具。
- 导入AutoTokenizer: 这是一个用于自动加载预训练模型的相关分词器的工具。分词器负责将文本转化为模型可以理解的数字格式。
- 导入AutoModelForCausalLM: 这是用于加载因果语言模型(用于文本生成)的工具。
- 使用from_pretrained方法来加载预训练的分词器和模型。其中,
device_map = 'auto'是为了自动地将模型加载到可用的设备上,例如GPU。 - 然后,给定一个提示(prompt): "请给我讲个玫瑰的爱情故事?",并使用分词器将该提示转换为模型可以接受的格式,
return_tensors="pt"表示返回PyTorch张量。语句中的to("cuda")是GPU设备格式转换。如果在GPU上跑,不用这个会报错,如果使用CPU,就删除一下试试。 - 最后使用模型的
.generate()方法生成响应。max_new_tokens=2000限制生成的文本的长度。使用分词器的.decode()方法将输出的数字转化回文本,并且跳过任何特殊的标记。
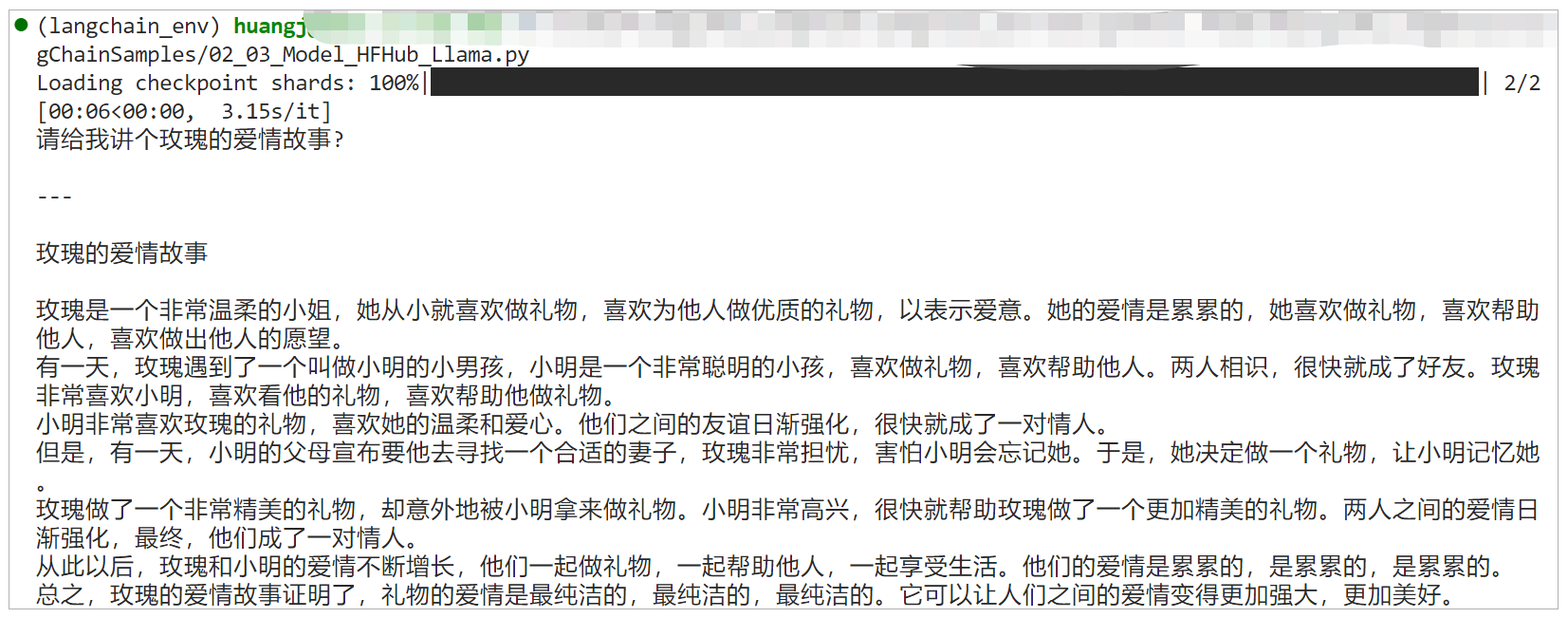
生成的内容明显把玫瑰理解成一个女孩的名字了,所以,开源模型尤其小模型和OpenAI的ChatGPT还有一定的差距。
# LangChain和HuggingFace的接口
# 通过HuggingFace Hub
HuggingFace Hub是一个开源模型中心化存储库,主要用于分享、协作和存储预训练模型、数据集以及相关组件。
# 导入HuggingFace API Token
import os
os.environ['HUGGINGFACEHUB_API_TOKEN'] = '你的HuggingFace API Token'
# 导入必要的库
from langchain import PromptTemplate, HuggingFaceHub, LLMChain
# 初始化HF LLM
llm = HuggingFaceHub(
repo_id="google/flan-t5-small",
#repo_id="meta-llama/Llama-2-7b-chat-hf",
)
# 创建简单的question-answering提示模板
template = """Question: {question}
Answer: """
# 创建Prompt
prompt = PromptTemplate(template=template, input_variables=["question"])
# 调用LLM Chain --- 我们以后会详细讲LLM Chain
llm_chain = LLMChain(
prompt=prompt,
llm=llm
)
# 准备问题
question = "Rose is which type of flower?"
# 调用模型并返回结果
print(llm_chain.run(question))
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
这个集成过程非常简单,只需要在HuggingFaceHub类的repo_id中指定模型名称,就可以直接下载并使用模型,模型会自动下载到HuggingFace的Cache目录,并不需要手工下载。
# 通过HuggingFace Pipeline
HuggingFace的Pipeline是一种高级工具,它简化了多种常见自然语言处理(NLP)任务的使用流程,使得用户不需要深入了解模型细节,也能够很容易地利用预训练模型来做任务。
# 指定预训练模型的名称
model = "meta-llama/Llama-2-7b-chat-hf"
# 从预训练模型中加载词汇器
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(model)
# 创建一个文本生成的管道
import transformers
import torch
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
max_length = 1000
)
# 创建HuggingFacePipeline实例
from langchain import HuggingFacePipeline
llm = HuggingFacePipeline(pipeline = pipeline,
model_kwargs = {'temperature':0})
# 定义输入模板,该模板用于生成花束的描述
template = """
为以下的花束生成一个详细且吸引人的描述:
花束的详细信息:
```{flower_details}```
"""
# 使用模板创建提示
from langchain import PromptTemplate, LLMChain
prompt = PromptTemplate(template=template,
input_variables=["flower_details"])
# 创建LLMChain实例
from langchain import PromptTemplate
llm_chain = LLMChain(prompt=prompt, llm=llm)
# 需要生成描述的花束的详细信息
flower_details = "12支红玫瑰,搭配白色满天星和绿叶,包装在浪漫的红色纸中。"
# 打印生成的花束描述
print(llm_chain.run(flower_details))
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44

# 用LangChain调用自定义语言模型
# 总结时刻(6)
大模型训练涉及在大量数据上使用深度学习算法,通常需要大量计算资源和时间。训练后,模型可能不完全适合特定任务,因此需要微调,即在特定数据上继续训练,以使模型更适合任务。为了减少部署模型的大小和加快推理速度,模型还会经过量化,即将模型参数从高精度格式减少到较低精度。
如果继续深入学习大模型,有几个工具需要研究:
- PyTorch是一个流行的深度学习框架,常用于模型训练和微调
- HuggingFace是一个开源社区,提供了大量预训练模型和微调工具,尤其是NLP任务
- LangChain则擅长于利用大语言模型的推理功能,开发新的工具或应用,完成特定任务。
# 思考题(6)
- 什么时候应该使用OpenAI的API?什么时候应该使用开源模型?或者自己开发/微调模型?
- 请使用HuggingFace的Transformers库,下载新的模型进行推理,比较它们的性能。
- 请在LangChain中,使用HuggingFaceHub和HuggingFace Pipeline这两种接口,调用当前最流行的大语言模型。
# 延伸阅读(6)
- Llama2,开源的可商用类ChatGPT模型,Facebook链接,GitHub链接
- HuggingFaceTransformer文档
- PyTorch官方教程,文档
- AutoGPTQ基于GPTQ算法的大模型量化工具包
- Llama CPP支持GGML,目标是在MacBook(或类似的非GPU的普通家用硬件环境)上使用4位整数量化运行Llama模型
# 输出解析
# LangChain 中的输出解析器
语言模型输出的是文本,供人类阅读,但很多时候,需要获得的是程序能够处理的结构化信息。这就需要输出解析器。输出解析器是一种专用于处理和构建语言模型响应的类。一个基本的输出解析器类通常需要实现两个核心方法。
get_format_instructions: 这个方法需要返回一个字符串,用于指导如何格式化语言模型的输出,告诉它应该如何组织并构建它的回答。parse: 这个方法接受一个字符串(也就是语言模型的输出)并将其解析为特定的数据结构或格式。这一步通常用于确保模型的输出符合我们的预期,并且能够以我们需要的形式进行后续处理。
还有一个可选方法:
parse_with_prompt: 这个方法接受一个字符串(也就是语言模型的输出)和一个提示(用于生成这个输出的提示),并将其解析为特定的数据结构,这样,可以根据原始提示来修正或重新解析模型的输出,确保输出的信息更加准确和贴合要求。
在LangChain中,通过实现get_format_instructions、parse和parse_with_prompt这些方法,针对不同的使用场景和目标,设计了各种输出解析器。
- 列表解析器(List Parser): 这个解析器用于处理模型生成的输出,当需要模型的输出是一个列表的时候使用,例如,如果询问模型"列出所有鲜花的库存",模型的回答应该是一个列表。
- 日期时间解析器(Datetime Parser): 这个解析器用于处理日期和时间相关的输出,确保模型的输出是正确的日期或时间格式。
- 枚举解析器(Enum Parser): 这个解析器用于处理预定义的一组值,当模型的输出应该是这组预定义值之一时使用。例如,如果定义了一个问题的答案只能是"是"或"否",那么枚举解析器可以确保模型的回答是这两个选项之一。
- 结构化输出解析器(Structured Output Parser): 这个解析器用于处理复杂的、结构化的输出。如果应用需要模型生成具有特定结构的复杂回答(例如一份报告、一篇文章等),那么可以使用结构化输出解析器来实现。
- Pydantic(JSON)解析器: 这个解析器用于处理模型的输出,当模型的输出应该是一个符合特定格式的JSON对象时使用。它使用Pydantic库,这是一个数据验证库,可以用于构建复杂的数据模型,并确保模型的输出符合预期的数据模型。
- 自动修复解析器(Auto-Fixing Parser): 这个解析器可以自动修复某些常见的模型输出错误。例如,如果模型的输出应该是一段文本,但是模型返回了一段包含语法或拼写错误的文本,自动修复解析器可以自动纠正这些错误。
- 重试解析器(RetryWithErrorOutputParser): 这个解析器用于在模型的初次输出不符合预期时,尝试修复或重新生成新的输出。例如,模型的输出应该是一个日期,但是返回了一个字符串,那么重试解析器可以重新提示模型生成正确的日期格式。
# Pydantic(JSON) 解析器实战
Pydantic是一个Python数据验证和设置管理库,主要基于Python类型提示。尽管它不是专为JSON设计的,但由于JSON是现代Web应用和API交互中的常见数据格式,Pydantic在处理和验证JSON数据时特别有用。
# 第一步: 创建模型实例
# 第一步: 创建模型实例
from langchain_ollama import ChatOllama
llm = ChatOllama(base_url="http://localhost:11434", model="qwen2.5:14b")
2
3
# 第二步: 定义输出数据的格式
先创建一个空的DataFrame,用于存储从模型生成的描述。接下来,通过一个名为FlowerDescription的Pydantic BaseMode类,定义了期望的数据格式(也就是数据的结构)。
# 第二步: 定义输出数据的格式
# 创建一个空的DataFrame用于存储结果
import pandas as pd
df = pd.DataFrame(columns=["flower_type", "price", "description", "reason"])
# 数据准备
flowers = ["玫瑰", "百合", "康乃馨"]
prices = ["50", "30", "20"]
# 定义我们想要接收的数据格式
from pydantic import BaseModel, Field
class FlowerDescription(BaseModel):
flower_type: str = Field(description="鲜花的种类")
price: int = Field(description="鲜花的价格")
description: str = Field(description="鲜花的描述文案")
reason: str = Field(description="为什么要这样写这个文案")
2
3
4
5
6
7
8
9
10
11
12
13
14
15
在这里用到了负责数据格式验证的Pydantic库来创建带有类型注解的类FlowerDescription,它可以自动验证输入数据,确保输入数据符合指定的类型和其他验证条件。
Pydantic有这样几个特点:
- 数据验证: 当向Pydantic类赋值时,它会自动进行数据验证。例如,如果创建了一个字段需要是整数,但试图向它赋予一个字符串,Pydantic会引发异常。
- 数据转换: Pydantic不仅进行数据验证,还可以进行数据转换。例如,如果有一个需要整数的字段,但提供了一个可以转换为整数的字符串,如"42",Pydantic会自动将这个字符串转换为整数42。
- 易于使用: 创建一个Pydantic类就像定义一个普通的Python类一样简单。只需要使用Python的类型注解功能,即可在类定义中指定每个字段的类型。
- JSON支持: Pydantic类可以很容易地从JSON数据创建,并可以将类的数据转换为JSON格式。
# 第三步: 创建输出解析器
在这一步中,创建输出解析器并获取输出格式指示。先使用LangChain库中的PydanticOutputParser创建了输出解析器,该解析器将用于解析模型的输出,以确保其符合FlowerDescription的格式。然后,使用解析器的get_format_instructions方法获取了输出格式的指示。
# 第三步: 创建输出解析器
from langchain.output_parsers import PydanticOutputParser
output_parser = PydanticOutputParser(pydantic_object=FlowerDescription)
# 获取输出格式提示
format_instructions = output_parser.get_format_instructions()
# 打印提示
print("输出格式: ", format_instructions)
2
3
4
5
6
7
8

上面的输出,是通过output_parser.get_format_instructions()方法生成的,这是Pydantic(JSON)解析器的核心价值,值得研究。同时它也算是一个很清晰的提示模板,能够为模型提供良好的指导,描述了模型输出应该符合的格式。(其中description中的中文被转换为了UTF-8编码)
它指示模型输出JSON Schema的形式,定义了一个有效的输出应该包含哪些字段,以及这些字段的数据类型。例如,它指定了flower_type字段应该是字符串类型,price字段应该是整数类型,这个指示中还提供了一个例子,说明了什么是一个格式良好的输出。
接下来,将内容传输到模型的提示中,让输入模型的提示和输出解析器的要求相互吻合,前后呼应。
# 第四步: 创建提示模板
定义提示模板,该模板将用于为模型生成输入提示。模板中包含了需要模型填充的变量(如价格和花的种类),以及之前获取的输出格式指示。
# 第四步: 创建提示模板
from langchain.prompts import PromptTemplate
prompt_template = """
您是一位专业的鲜花店文案撰写员。
对于售价{price}元的{flower},您能提供一个吸引人的简短中文描述吗?
{format_instructions}
"""
# 根据模板创建提示,同时在提示中加入输出解析器的说明
prompt = PromptTemplate.from_template(prompt_template, partial_variables={"format_instrctions": format_instructions})
# 打印提示
print("提示: ", prompt)
2
3
4
5
6
7
8
9
10
11
12

这就是包含了format_instructions信息的提示模板。
input_variables=['flower', 'price']: 这是一个包含想要在模板中使用的输入变量的列表。在模板中使用了flower和price两个变量,后面会用具体的值(如玫瑰、20元)来替换这两个变量。output_parser=None: 可以在选择在模板中使用一个输出解析器,此例,并没有选择在模板中使用输出解析器,而是在模型外部进行输出解析,因此这里是None。partial_variables: 包含了想要在模板中使用,但在生成模板时无法立即提供的变量。在这里,format_instructions传入输出格式的详细说明。template: 这是模板字符串本身,包含了想要模型生成的文本的结构,此例中,模板字符串是询问鲜花描述的问题,以及关于输出格式的说明。template_format='f-string': 这是一个表示模板字符串格式的选项。validate_template=True: 表示是否在创建模板时检查模板的有效性。
这个提示模板是一个用于生成模型输入的工具,可以在模板中定义需要的输入变量,以及模板字符串的格式和结构,然后使用这个模板为每种鲜花生成一个描述。
# 第五步: 生成提示,传入模型并解析输出
这部分是程序的主题,循环来处理所有的花和它们的价格,对于每种花,都根据提示模板创建了输入,然后获取模型的输出。然后使用之前创建的解析器来解析这个输出,并将解析后的输出添加到DataFrame中。最后,打印结果,也可以选择将其保存到CSV文件中。
# 第一步: 创建模型实例
from langchain_ollama import ChatOllama
llm = ChatOllama(base_url="http://localhost:11434", model="qwen2.5:14b")
# 第二步: 定义输出数据的格式
# 创建一个空的DataFrame用于存储结果
import pandas as pd
df = pd.DataFrame(columns=["flower_type", "price", "description", "reason"])
# 数据准备
flowers = ["玫瑰", "百合", "康乃馨"]
prices = ["50", "30", "20"]
# 定义我们想要接收的数据格式
from pydantic import BaseModel, Field
class FlowerDescription(BaseModel):
flower_type: str = Field(description="鲜花的种类")
price: int = Field(description="鲜花的价格")
description: str = Field(description="鲜花的描述文案")
reason: str = Field(description="为什么要这样写这个文案")
# 第三步: 创建输出解析器
from langchain.output_parsers import PydanticOutputParser
output_parser = PydanticOutputParser(pydantic_object=FlowerDescription)
# 获取输出格式提示
format_instructions = output_parser.get_format_instructions()
# 打印提示
# print("输出格式: ", format_instructions)
# 第四步: 创建提示模板
from langchain.prompts import PromptTemplate
prompt_template = """
您是一位专业的鲜花店文案撰写员。
对于售价{price}元的{flower},您能提供一个吸引人的简短中文描述吗?
{format_instructions}
"""
# 根据模板创建提示,同时在提示中加入输出解析器的说明
prompt = PromptTemplate.from_template(prompt_template, partial_variables={"format_instrctions": format_instructions})
# 打印提示
# print("提示: ", prompt)
# 第五步: 生成提示,传入模型并解析输出
for flower, price in zip(flowers, prices):
# 根据提示准备模型的输入
input = prompt.format(flower=flower, price=price, format_instructions=format_instructions)
# 打印提示
print("提示: ", input)
# 获取模型的输出
output = llm.invoke(input)
# print("输出的数据: ", output)
# 解析模型的输出
parsed_output = output_parser.parse(output.content)
parsed_output_dict = parsed_output.model_dump()
# 将解析后的输出添加到DataFrame中
df.loc[len(df)] = parsed_output.model_dump()
# 打印字典
print("输出的数据: ", df.to_dict(orient="split"))
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
这一步中,使用模型和输入提示(由鲜花种类和价格组成)生成了一个具体鲜花的文案需求(同时带有格式描述),然后传递给大模型,也就是,提示模板中的flower和price,此时都被具体的花取代了,而且模板中的{format_instructions},也被替换成了JSON Schema中指明的格式信息。
提示:
您是一位专业的鲜花店文案撰写员。
对于售价50元的玫瑰,您能提供一个吸引人的简短中文描述吗?
The output should be formatted as a JSON instance that conforms to the JSON schema below.
As an example, for the schema
2
3
4
5
6
{
"properties": {
"foo": {
"title": "Foo",
"description": "a list of strings",
"type": "array",
"items": {"type": "string"}
}
},
"required": ["foo"]
}
2
3
4
5
6
7
8
9
10
11
the object
{"foo": ["bar", "baz"]}
is a well-formatted instance of the schema. The object
{"properties": {"foo": ["bar", "baz"]}}
is not well-formatted.
Here is the output schema:
{"properties":
{"flower_type":
{"description": "鲜花的种类", "title": "Flower Type", "type": "string"},
"price": {"description": "鲜花的价格", "title": "Price", "type": "integer"},
"description": {"description": "鲜花的描述文案", "title": "Description", "type": "string"},
"reason": {"description": "为什么要这样写这个文案", "title": "Reason", "type": "string"}
},
"required": ["flower_type", "price", "description", "reason"]
}
2
3
4
5
6
7
8
9
提示:
您是一位专业的鲜花店文案撰写员。
对于售价30元的百合,您能提供一个吸引人的简短中文描述吗?
The output should be formatted as a JSON instance that conforms to the JSON schema below.
2
3
4
As an example, for the schema
{"properties":
{"foo": {"title": "Foo", "description": "a list of strings", "type": "array", "items": {"type": "string"}}},
"required": ["foo"]
}
2
3
4
the object
{"foo": ["bar", "baz"]}
is a well-formatted instance of the schema. The object
{"properties": {"foo": ["bar", "baz"]}}
is not well-formatted.
Here is the output schema:
{
"properties":
{
"flower_type":
{"description": "鲜花的种类", "title": "Flower Type", "type": "string"},
"price": {"description": "鲜花的价格", "title": "Price", "type": "integer"},
"description": {"description": "鲜花的描述文案", "title": "Description", "type": "string"},
"reason": {"description": "为什么要这样写这个文案", "title": "Reason", "type": "string"}
},
"required": ["flower_type", "price", "description", "reason"]
}
```text
提示:
您是一位专业的鲜花店文案撰写员。
对于售价20元的康乃馨,您能提供一个吸引人的简短中文描述吗?
The output should be formatted as a JSON instance that conforms to the JSON schema below.
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
As an example, for the schema
{
"properties": {
"foo": {"title": "Foo", "description": "a list of strings", "type": "array", "items": {"type": "string"}}
},
"required": ["foo"]
}
2
3
4
5
6
the object
{"foo": ["bar", "baz"]}
is a well-formatted instance of the schema. The object
{"properties": {"foo": ["bar", "baz"]}}
is not well-formatted.
Here is the output schema:
{
"properties": {
"flower_type": {"description": "鲜花的种类", "title": "Flower Type", "type": "string"},
"price": {"description": "鲜花的价格", "title": "Price", "type": "integer"},
"description": {"description": "鲜花的描述文案", "title": "Description", "type": "string"},
"reason": {"description": "为什么要这样写这个文案", "title": "Reason", "type": "string"}
},
"required": ["flower_type", "price", "description", "reason"]
}
2
3
4
5
6
7
8
9
输出的数据:
{
"index": [0, 1, 2],
"columns": ["flower_type", "price", "description", "reason"],
"data": [
[
"玫瑰",
50,
"倾城之恋,50元的精致红玫瑰,每朵都蕴含着深情与浪漫,为您的爱人献上一份无言的心意。",
"文案强调了玫瑰作为爱情象征的经典意义,并突出了价格亲民但品质不凡的特点,能够吸引注重情感表达又在意性价比的情侣和花友。"
],
[
"百合",
30,
"纯洁无瑕的百合,30元一份,以其高雅的姿态和清新的香气,为每一个角落增添了一份优雅。无论是送给亲爱的她,还是装点自己的小家,都是不错的选择。",
"通过突出百合花的特点(如纯洁、优雅),并强调其装饰性和送礼价值,能够吸引顾客的注意,并激发购买欲望。"
],
[
"康乃馨",
20,
"每束精选的康乃馨,不仅承载着温馨与甜蜜,更有象征永恒爱情的深意。以20元的价格将这份深情带回家,不论是送给心爱的人还是表达敬意,都是完美的选择。",
"此文案突出了康乃馨的情感价值,并强调了其作为礼物的完美属性和亲民价格,吸引注重情感传递与性价比的顾客。"
]
]
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
下面,程序解析模型的输出。在这一步中,使用之前定义的输出解析器(output_parser)将模型的输出解析成了一个FlowerDescription的实例。FlowerDescription是之前定义的一个Pydantic类,它包含了鲜花的类型、价格、描述以及描述的理由。然后,将解析后的输出添加到DataFrame中,在这一步中,将解析后的输出(即FlowerDescription实例)转换为一个字典,并将这个字典添加到DataFrame中。
# 自动修复解析器(OutputFixingParser)实战
# 导入所需要的库和模块
from langchain.output_parsers import PydanticOutputParser
from pydantic import BaseModel, Field
from typing import List
# 使用Pydantic创建一个数据格式,表示花
class Flower(BaseModel):
name: str = Field(description="name of a flower")
colors: List[str] = Field(description="the colors of this flower")
# 定义一个用于获取某种花的颜色列表的查询
flower_query = "Generate the charaters for a random flower."
# 定义一个格式不正确的输出
misformatted = "{'name': '康乃馨', 'colors': ['粉红色', '白色', '红色', '紫色', '黄色']}"
# 创建一个用于解析输出的Pydantic解析器,此处希望解析为Flower格式
parser = PydanticOutputParser(pydantic_object=Flower)
# 使用Pydantic解析器解析不正确的输出
parser.parse(misformatted)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
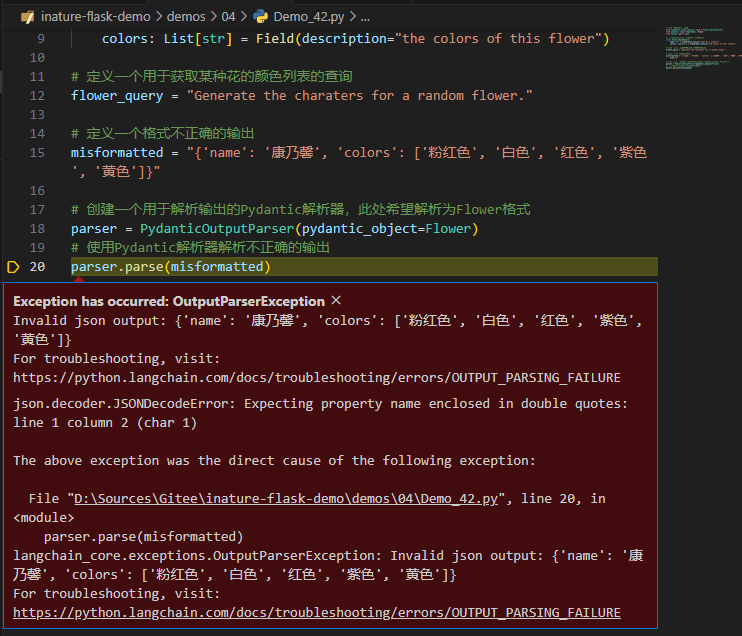
这个错误消息来自Python的内建JSON解析器发现输入的JSON格式不正确。尝试用PydanticOutputParser来解析JSON字符串时,Python期望属性名称被双引号包围,但在给定的JSON字符串中是单引号。
当这个错误被触发后,程序进一步引发了一个自定义异常: OutputParserException,它提供了更多关于错误的上下文。这个自定义异常的消息表示在尝试解析flower对象时遇到了问题,即单引号和双引号的问题。下面尝试使用OutputFixingParser来解决类似的格式错误。
# 导入所需要的库和模块
from langchain.output_parsers import PydanticOutputParser
from pydantic import BaseModel, Field
from typing import List
# 使用Pydantic创建一个数据格式,表示花
class Flower(BaseModel):
name: str = Field(description="name of a flower")
colors: List[str] = Field(description="the colors of this flower")
# 定义一个用于获取某种花的颜色列表的查询
flower_query = "Generate the charaters for a random flower."
# 定义一个格式不正确的输出
misformatted = "{'name': '康乃馨', 'colors': ['粉红色', '白色', '红色', '紫色', '黄色']}"
# 创建一个用于解析输出的Pydantic解析器,此处希望解析为Flower格式
parser = PydanticOutputParser(pydantic_object=Flower)
# 使用Pydantic解析器解析不正确的输出
# parser.parse(misformatted)
# 从langchain库导入所需的模块
from langchain_ollama import ChatOllama
llm = ChatOllama(base_url="http://localhost:11434", model="qwen2.5:14b")
from langchain.output_parsers import OutputFixingParser
# 使用OutputFixingParser创建一个新的解析器,该解析器能够纠正格式不正确的输出
new_parser = OutputFixingParser.from_llm(parser=parser, llm=llm)
# 使用新的解析器解析不正确的输出
result = new_parser.parse(misformatted)
print(result)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33

用new_parser代替parser解析,问题解决了。原因在于,在OutputFixingParser内部,调用了原有的PydanticOutputParser,如果成功,就返回;如果失败,它会将格式错误的输出以及格式化的指令传递给大模型,并要求LLM进行相关的修复。
# 重试解析器(RetryWithErrorOutputParser)实战
OutputFixingParser不错,但它只能做简单的格式修复,如果出错的不只是格式,比如,输出根本不完整,有缺失内容,那么仅仅根据输出和格式本身,是无法修复它的。
此时,通过实现输出解析器中的parse_with_prompt方法,LangChain提供的重试解析器可以利用大模型的推理能力根据原始提示找回相关信息。
# 定义一个模板字符串,这个模板用于生成提问
template = """
Based on the user question, provide an Action and Action Input for what step should be taken.
{format_instructions}
Question: {query}
Response:
"""
# 定义一个Pydantic数据格式,它描述了一个"行动"类及其属性
from pydantic import BaseModel, Field
class Action(BaseModel):
action: str = Field(description="action to take")
action_input: str = Field(description="input to the action")
# 使用Pydantic格式Action来初始化一个输出解析器
from langchain.output_parsers import PydanticOutputParser
parser = PydanticOutputParser(pydantic_object=Action)
# 定义一个提示模板,它将用于向模型提问
from langchain.prompts import PromptTemplate
prompt = PromptTemplate(
template="Answer the user query.\n{format_instructs}\n{query}\n",
input_variables=["query"],
partial_variables={"format_instructions": parser.get_format_instructions()}
)
prompt_value = prompt.format_prompt(query="What are the colors of Orchid?",format_instructs=parser.get_format_instructions())
# 定义一个错误格式的字符串
bad_response = '{"action": "search"}'
# 如果直接解析,会引发一个错误
# parser.parse(bad_response)
from langchain.output_parsers import OutputFixingParser
from langchain_ollama import ChatOllama
llm = ChatOllama(base_url="http://localhost:11434", model="qwen2.5:14b")
fix_parser = OutputFixingParser.from_llm(parser=parser, llm=llm)
parse_result = fix_parser.parse(bad_response)
print('OutputFixingParser的parse结果: ', parse_result)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
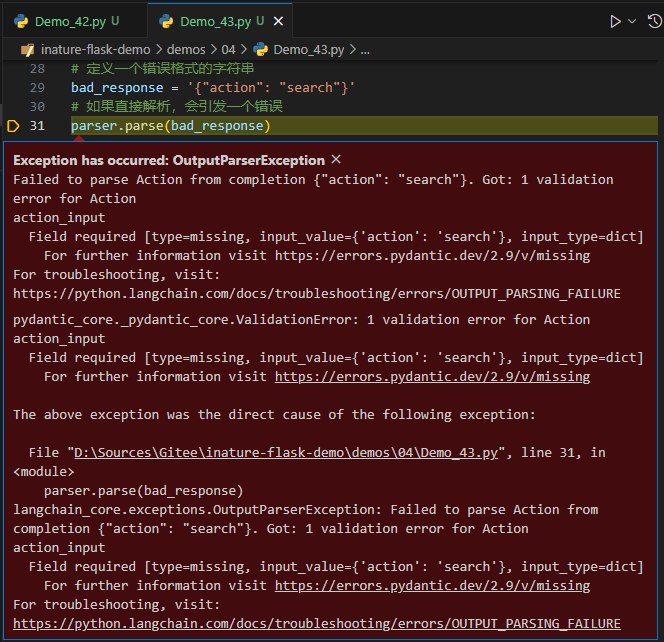

解决的问题:
- 不完整的数据,原始的bad_response只提供了action字段而没有action_input字段。OutputFixingParser已经填补了这个缺失,为action_input字段提供了值
query。
没解决的问题:
- 具体性: 尽管OutputFixingParser为action_input字段提供了默认值
query,但这并不具有描述性。真正的查询时"Orchid(兰花)的颜色是什么?"。所以,这个修复只是提供了一个通用的值,并没有真正地回答用户的问题。 - 可能的误导:
query可能被误解为一个指示,要求进一步查询某些内容,而不是作为实际的查询输入。
还有更鲁棒的选择,如下尝试RetryWithErrorOutputParser这个解析器:
# 定义一个模板字符串,这个模板用于生成提问
template = """
Based on the user question, provide an Action and Action Input for what step should be taken.
{format_instructions}
Question: {query}
Response:
"""
# 定义一个Pydantic数据格式,它描述了一个"行动"类及其属性
from pydantic import BaseModel, Field
class Action(BaseModel):
action: str = Field(description="action to take")
action_input: str = Field(description="input to the action")
# 使用Pydantic格式Action来初始化一个输出解析器
from langchain.output_parsers import PydanticOutputParser
parser = PydanticOutputParser(pydantic_object=Action)
# 定义一个提示模板,它将用于向模型提问
from langchain.prompts import PromptTemplate
prompt = PromptTemplate(
template="Answer the user query.\n{format_instructs}\n{query}\n",
input_variables=["query"],
partial_variables={"format_instructions": parser.get_format_instructions()}
)
prompt_value = prompt.format_prompt(query="What are the colors of Orchid?",format_instructs=parser.get_format_instructions())
# 定义一个错误格式的字符串
bad_response = '{"action": "search"}'
# 如果直接解析,会引发一个错误
# parser.parse(bad_response)
# from langchain.output_parsers import OutputFixingParser
from langchain_ollama import ChatOllama
llm = ChatOllama(base_url="http://localhost:11434", model="qwen2.5:14b")
# fix_parser = OutputFixingParser.from_llm(parser=parser, llm=llm)
# parse_result = fix_parser.parse(bad_response)
# print('OutputFixingParser的parse结果: ', parse_result)
# 初始化RetryWithErrorOutputParser,它会尝试再次提问来得到一个正确的输出
from langchain.output_parsers import RetryWithErrorOutputParser
retry_parser = RetryWithErrorOutputParser.from_llm(parser=parser, llm=llm)
parse_result = retry_parser.parse_with_prompt(bad_response, prompt_value)
print('RetryWithErrorOutputParser的parse结果: ', parse_result)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44

这个解析器成功地还原了格式,甚至也根据传入的原始提示,还原了action_input字段的内容。
# 总结时刻(7)
结构化解析器和Pydantic解析器都旨在从大型语言模型中获取格式化的输出。结构化解析器更适合简单的文本响应,而Pydantic解析器则提供了对复杂数据结构和类型的支持。选择哪种解析器取决于应用的具体需求和输出的复杂性。
自动修复解析器主要适用于纠正小的格式错误,它更加"被动",仅在原始输出出现问题时进行修复。重试解析器则可以处理更复杂的问题,包括格式错误和内容缺失。它通过重新与模型交互,使得输出更加完整和符合预期。在选择哪种解析器时,需要考虑具体的应用场景。如果仅面临格式问题,自动修复解析器即可;但如果输出的完整性和准确性至关重要,那么重试解析器可能更好。
# 思考题(7)
- 到目前为止,已经使用了哪些LangChain输出解析器?请比较它们的用法和异同,同时也请尝试使用其他类型的输出解析器。
- 为什么大模型能够返回JSON格式的数据,输出解析器用了什么魔法让大模型做到这一点?
- 自动修复解析器的"修复"功能具体来说是怎样实现的?请做debug,研究一下LangChain在调用大模型之前如何设计"提示"。
- 重试解析器的原理是什么?它主要实现了解析器类的哪个可选方法?
# 延伸阅读(7)
- 工具: Pydantic是一个Python库,用于数据验证,可以确保数据符合特定的格式
- 文档: LangChain中的各种Output Parsers
# 链
# 什么是Chain
如果想开发更复杂的应用程序,就需要通过"Chain"来链接LangChain的各个组件和功能--模型之间彼此链接,或模型与其他组件链接。
这种将多个组件相互链接,组合成一个链的想法简单但很强大,它简化了复杂应用程序的实现,并使之更加模块化,能够创建出单一的、连贯的应用程序,从而使调试、维护和改进应用程序变得容易。
链的实现和使用:
- 首先LangChain通过设计好的接口,实现一个具体的链的功能。例如,LLM链(LLMChain)能够接收用户输入,使用PromptTemplate对其进行格式化,然后将格式化的响应传递给LLM。这就相当于把整个Model I/O的流程封装到链里面。
- 实现了链的具体功能之后,可以通过将多个链组合在一起,或者将链与其他组件组合来构建更复杂的链。
链在内部把一系列的功能进行封装,而链的外部则又可以组合串联,链其实可以被视为LangChain中的一种基本功能单元。
LangChain中提供了很多种类的预置链,使各种各样的任务实现起来更加方便、规范。

# LLMChain: 最简单的链
LLMChain围绕着语言模型推理功能又添加了一些功能,整合了PromptTemplate、语言模型(LLM或聊天模型)和Output Parser,相当于把Model I/O放在一个链中整体操作。它使用提示模板格式化输入,将格式化的字符串传递给LLM,并返回LLM输出。
举例,如果希望大模型输出某种花的花语,如果不使用链,代码如下:
# ------ 第一步 ------
# 导入LangChain中的提示模板
from langchain.prompts import PromptTemplate
# 原始字符串模板
template = "{flower}的花语是?"
# 创建LangChain模板
prompt_temp = PromptTemplate.from_template(template)
# 根据模板创建提示
prompt = prompt_temp.format(flower="玫瑰")
# 打印提示的内容
print(prompt)
# ----- 第二步 ------
# 导入LangChain中的ollama模型接口
from langchain_ollama import ChatOllama
# 创建模型实例
llm = ChatOllama(base_url="http://localhost:11434", model="qwen2.5:14b")
# 传入提示、调用模型、返回结果
result = llm.invoke(prompt)
print(result)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20

此时Model I/O的实现分为两个部分,提示模板的构建和模型的调用独立处理。如果使用链,代码结构则显得更加简洁。
# 导入所需的库
from langchain.prompts import PromptTemplate
from langchain_ollama import ChatOllama
# 原始字符串模板
template = "{flower}的花语是?"
prompt = PromptTemplate(input_variables="flower", template=template)
# 创建模型实例
llm = ChatOllama(base_url="http://localhost:11434", model="qwen2.5:14b")
# 创建chain
chain = prompt | llm
result = chain.invoke("蒲公英")
print(result)
2
3
4
5
6
7
8
9
10
11
12

# 链的调用方式
注意
由于LangChain版本迭代很快,有很多方法被标记为弃用,或者最新版本已经无法找到,本章节后续补充吧
链有很多种调用方式
# 直接调用
刚才我们直接调用链对象,当像函数一样调用一个对象时,它实际上会调用该对象内部实现的__call__方法。
# Sequential Chain: 顺序链
目标:
- 第一步,假设大模型是一个植物学家,让他给出某种特定鲜花的知识和介绍。
- 第二步,假设大模型是一个鲜花评论者,让他参考上面植物学家的文字输出,对鲜花进行评论。
- 第三步,假设大模型是鲜花商店的社交媒体运营经理,让他参考上面植物学家和鲜花评论者的文字输出,来写一篇鲜花运营方案。
from langchain_ollama import ChatOllama
from langchain.prompts import PromptTemplate
# from langchain.chains.sequential import SequentialChain
from langchain.schema import StrOutputParser
from langchain.schema.runnable import RunnablePassthrough
# from operator import itemgetter
llm = ChatOllama(base_url="http://localhost:11434", model="qwen2.5:14b")
template = """
你是一个植物学家。给定花的名称和类型,你需要为这种花写一个200字的介绍。
花名: {name}
颜色: {color}
植物学家: 这是关于上述花的介绍:
"""
prompt_template1 = PromptTemplate(input_variables=["name", "color"], template=template)
introduction_chain = prompt_template1 | llm | StrOutputParser()
template = """
你是一位鲜花评论家。给定一种花的介绍,你需要为这种花写一篇200字左右的评论。
鲜花介绍:
{introduction}
花评人对上述花的评论:
"""
prompt_template2 = PromptTemplate(input_variables="introduction", template=template)
review_chain = prompt_template2 | llm | StrOutputParser()
template = """
你是一家花店的社交媒体经理。给定一种花的介绍和评论,你需要为这种花写一篇社交媒体的帖子,300字左右。
鲜花介绍:
{introduction}
花评人对上述花的评论:
{review}
社交媒体帖子:
"""
prompt_template3 = PromptTemplate(input_variables=["introduction", "review"], template=template)
social_chain = prompt_template3 | llm | StrOutputParser()
# overall_chain = SequentialChain(
# chains=[prompt_template1, prompt_template2, prompt_template3],
# input_variables=["name", "color"],
# output_variables=["introduction", "review", "social_post_text"],
# verbose=True
# )
overall_chain = (
{"introduction": introduction_chain} | RunnablePassthrough.assign(review=review_chain) | social_chain )
result = overall_chain.invoke({"name": "梅花", "color": "白色"})
print(result)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51

from langchain_ollama import ChatOllama
from langchain.prompts import PromptTemplate
from langchain.chains.sequential import SequentialChain
from langchain.chains.llm import LLMChain
# from langchain.schema import StrOutputParser
# from langchain.schema.runnable import RunnablePassthrough
llm = ChatOllama(base_url="http://localhost:11434", model="qwen2.5:14b")
template = """
你是一个植物学家。给定花的名称和类型,你需要为这种花写一个200字的介绍。
花名: {name}
颜色: {color}
植物学家: 这是关于上述花的介绍:
"""
prompt_template1 = PromptTemplate(input_variables=["name", "color"], template=template)
# introduction_chain = prompt_template1 | llm | StrOutputParser()
introduction_chain = LLMChain(llm=llm, prompt=prompt_template1, output_key="introduction")
template = """
你是一位鲜花评论家。给定一种花的介绍,你需要为这种花写一篇200字左右的评论。
鲜花介绍:
{introduction}
花评人对上述花的评论:
"""
prompt_template2 = PromptTemplate(input_variables="introduction", template=template)
# review_chain = prompt_template2 | llm | StrOutputParser()
review_chain = LLMChain(llm=llm, prompt=prompt_template2, output_key="review")
template = """
你是一家花店的社交媒体经理。给定一种花的介绍和评论,你需要为这种花写一篇社交媒体的帖子,300字左右。
鲜花介绍:
{introduction}
花评人对上述花的评论:
{review}
社交媒体帖子:
"""
prompt_template3 = PromptTemplate(input_variables=["introduction", "review"], template=template)
# social_chain = prompt_template3 | llm | StrOutputParser()
social_chain = LLMChain(llm=llm, prompt=prompt_template3, output_key="social_post_text")
overall_chain = SequentialChain(
chains=[introduction_chain, review_chain, social_chain],
input_variables=["name", "color"],
output_variables=["introduction", "review", "social_post_text"],
verbose=True
)
# overall_chain = (
# {"introduction": introduction_chain} | RunnablePassthrough.assign(review=review_chain) | social_chain )
result = overall_chain.invoke({"name": "梅花", "color": "白色"})
print(result)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
from langchain_ollama import ChatOllama
from langchain.prompts import PromptTemplate
from langchain.chains.sequential import SequentialChain
# from langchain.chains.llm import LLMChain
from langchain.schema import StrOutputParser
from langchain.schema.runnable import RunnablePassthrough
llm = ChatOllama(base_url="http://localhost:11434", model="qwen2.5:14b")
template = """
你是一个植物学家。给定花的名称和类型,你需要为这种花写一个200字的科普介绍。
花名: {name}
颜色: {color}
植物学家: 这是关于上述花的介绍:
"""
prompt_template1 = PromptTemplate(input_variables=["name", "color"], template=template)
introduction_chain = prompt_template1 | llm | StrOutputParser()
# introduction_chain = prompt_template1 | llm
# introduction_chain = LLMChain(llm=llm, prompt=prompt_template1, output_key="introduction")
template = """
你是一位鲜花评论家。给定一种花的介绍,你需要为这种花写一篇200字左右的评论。
鲜花介绍:
{introduction}
花评人对上述花的评论:
"""
prompt_template2 = PromptTemplate(input_variables="introduction", template=template)
review_chain = prompt_template2 | llm | StrOutputParser()
# review_chain = prompt_template2 | llm
# review_chain = LLMChain(llm=llm, prompt=prompt_template2, output_key="review")
template = """
你是一家花店的社交媒体经理。给定一种花的介绍和评论,你需要为这种花写一篇社交媒体的帖子,300字左右。
鲜花介绍:
{introduction}
花评人对上述花的评论:
{review}
社交媒体帖子:
"""
prompt_template3 = PromptTemplate(input_variables=["introduction", "review"], template=template)
social_chain = prompt_template3 | llm | StrOutputParser()
# social_chain = prompt_template3 | llm
# social_chain = LLMChain(llm=llm, prompt=prompt_template3, output_key="social_post_text")
# overall_chain = SequentialChain(
# chains=[introduction_chain, review_chain, social_chain],
# input_variables=["name", "color"],
# output_variables=["introduction", "review", "social_post_text"],
# verbose=True
# )
# overall_chain = (
# {"introduction": introduction_chain} | RunnablePassthrough.assign(review=review_chain) | social_chain )
overall_chain = (
RunnablePassthrough.assign(introduction=introduction_chain)
| RunnablePassthrough.assign(review=review_chain)
| social_chain
)
# result1 = introduction_chain.invoke({"name": "梅花", "color": "白色"})
# print(result1)
# result2 = review_chain.invoke({"introduction": result1})
# print(result2)
# result3 = social_chain.invoke({"introduction": result1, "review": result2})
# print (result3)
result = overall_chain.invoke({"name": "梅花", "color": "白色"})
print(result)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
# 总结时刻(8)
LangChain提供了很多好用的链,帮助开发者把多个组件像链条一样链接起来,这个链条其实就是一系列组件的调用顺序,这个顺序里还可以包括其他的链条。除去最常见的LLMChain和SequenceChain之外,LangChain中还自带大量其他类型的链,封装了各种各样的功能。
# 思考题(8)
- 在前面,曾经使用提示模板生成过一段鲜花的描述,如下:
for flower, price in zip(flowers, prices):
# 根据提示准备模型的输入
input = prompt.format(flower_name=flower, price=price)
# 获取模型的输出
output = model(input)
# 解析模型的输出
parsed_output = output_parser.parse(output)
2
3
4
5
6
7
请使用LLMChain重构提示的format和获取模型输出部分,完成相同的功能。
:::info 提示
llm_chain = LLMChain(llm=llm, prompt=prompt)
:::
- 在上一个题目中,要求把提示的format和获取模型输出部分整合到LLMChain中,其实还可以进一步,把output_parser也整合到LLMChain中,让程序进一步简化。
:::info 提示
llm_chain = LLMChain(llm=llm, prompt=prompt, output_parser=output_parser)
:::
- 选择一个LangChain中的链,舱室用它解决一个问题。
# 延伸阅读(8)
# 任务设定
假设鲜花运营智能客服ChatBot通常会接到两大类问题。
- 鲜花养护: 保持花的健康、如何浇水、施肥等
- 鲜花装饰: 如何搭配花、如何装饰场地等
需求: 如果街道第一类问题,给ChatBot A指示;如果接到第二类问题,给ChatBot B指示。
可以根据两个场景构建两个不同的目标链,遇到不同类型的问题,LangChain会通过RouterChain来自动引导大语言模型选择不同的模板。
# 整体框架
RouterChain,也叫路由链,能动态选择用于给定输入的下一个链。根据用户的问题内容,首先使用路由链确定问题适合哪个处理模板,然后将问题发送到该处理模板进行问答。如果问题不适合任何已定义的处理模板,则发送到默认链。
在这里,用LLMRouterChain和MultiPromptChain(也是一种路由链)组合实现路由功能,该MultiPromptChain会调用LLMRouterChain选择与给定问题最相关的提示,然后使用该提示回答问题。
具体步骤如下:
- 构建处理模板: 为鲜花护理和鲜花装饰分别定义两个字符串模板。
- 提示信息: 使用一个列表来组织和存储这两个处理模板的关键信息,如模板的键、描述和实际内容。
- 初始化语言模型: 导入并实例化语言模型。
- 构建目标链: 根据提示信息中的每个模板构建了对应的LLMChain,并存储在一个字典中。
- 构建LLM路由链: 这是决策的核心,首先,它根据提示信息构建了一个路由模板,然后使用这个模板创建了一个LLMRouterChain。
- 构建默认链: 如果输入不适合任何已定义的处理模板,这个默认链会被触发。
- 构建多提示链: 使用MultiPromptChain将LLM路由链、目标链和默认链组合在一起,形成一个完整的决策系统。
# 具体实现
# 构建提示信息的模板
# 构建两个场景的模板
flower_care_template = """
你是一个经验丰富的园丁,擅长解答关于养花育花的问题。
下面是需要你来回答的问题:
{input}
"""
flower_deco_template = """
你是一位网红插花大师,擅长解答关于鲜花装饰的问题。
下面是需要你来回答的问题:
{input}
"""
# 构建提示信息
prompt_infos = [
{
"key": "flower_care",
"description": "适合回答关于鲜花护理的问题",
"template": flower_care_template
},
{
"key": "flower_decoration",
"description": "适合回答关于鲜花装饰的问题",
"template": flower_deco_template
}
]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
# 初始化语言模型
# 初始化语言模型
from langchain_ollama import ChatOllama
llm = ChatOllama(base_url="http://localhost:11434", model="qwen2.5:14b")
2
3
# 构建目标链
循环prompt_infos这个列表,构建出两个目标链,分别负责处理不同的问题。
# 构建目标链
from langchain.prompts import PromptTemplate
from langchain.chains.llm import LLMChain
chain_map = {}
for info in prompt_infos:
prompt = PromptTemplate(template=info["template"], input_variables=["input"])
# print("目标提示:\n", prompt)
# chain = prompt | llm
chain = LLMChain(llm=llm, prompt=prompt, verbose=True)
chain_map[info["key"]] = chain
2
3
4
5
6
7
8
9
10

对于每个场景,创建一个LLMChain(语言模型链),每个链会根据其场景模板生成对应的提示,然后将这个提示送入语言模型获取答案。
# 构建路由链
构建路由链,负责查看用户输入的问题,确定问题的类型。
# 构建路由链
from langchain.chains.router.llm_router import LLMRouterChain, RouterOutputParser
from langchain.chains.router.multi_prompt_prompt import MULTI_PROMPT_ROUTER_TEMPLATE as RouterTemplate
destinations = [f"{p['key']}: {p['description']}" for p in prompt_infos]
router_tempate = RouterTemplate.format(destinations="\n".join(destinations))
print("路由模板:\n", router_tempate)
router_tempate = PromptTemplate(
template=router_tempate,
input_variables=["input"],
output_parser=RouterOutputParser()
)
print("路由提示:\n", router_tempate)
router_chain = LLMRouterChain.from_llm(llm, router_tempate, verbose=True)
2
3
4
5
6
7
8
9
10
11
12
13
下面解释一下路由链如何构造提示信息,来引导大模型查看用户输入的问题并确定问题的类型的。先看路由模板部分,这段模板字符串是一个指导性的说明,目的是引导语言模型正确处理用户的输入,并将其定向到适当的模型提示。
# 路由模板的解释
路由模板是路由功能得以实现的核心,下面详细分解一下这个模板的每个部分。
- 引言
Given a raw text input to a language model select the model prompt best suited for the input.
这是一个简单的引导语句,告诉模型将给它一个输入,它需要根据这个输入选择最适合的模型提示。
You will be given the names of the available prompts and a description of what the prompt is best suited for.
这里进一步提醒模型,它将获得各种模型提示的名称和描述。
You may also revise the original input if you think that revising it will ultimately lead to a better response from the language model.
这是一个可选的步骤,告诉模型它可以更改原始输入以获得更好的响应。
- 格式说米国(<< FORMATTING >>)
指导模型如何格式化其输出,使其以特定的方式返回结果。
Return a markdown code snippet with a JSON object formatted to look like:
表示模型的输出应该是一个Markdown代码片段,其中包含一个特定格式的JSON对象。下面的代码块显示了期望的JSON结构,其中destination是模型选择的提示名称(或"DEFAULT"),而next_inputs是可能被修订的原始输入。
{{
"destination": string \ name of the prompt to use or "DEFAULT"
"next_inputs": string \ a potentially modified version of the original input
}}
2
3
4
- 额外的说明和要求
REMEMBER: "destination" MUST be one of the candidate prompt names specified below OR it can be "DEFAULT" if the input is not well suited for any of the candidate prompts.
这是一个重要的指导,提醒模型"destination"字段的值必须是下面列出的提示之一或是"DEFAULT"。
REMEMBER: "next_inputs" can just be the original input if you don't think any modifications are needed.
这里再次强调,除非模型认为有必要,否则原始输入不需要修改。
- 候选提示(<< CANDIDATE PROMPTS >>)
列出了两个示例模型提示及其描述:
- "flower_care: 适合回答关于鲜花护理的问题",适合处理与花卉护理相关的问题。
- "flower_decoration: 适合回答关于鲜花装饰的问题",适合处理与花卉装饰相关的问题。
- 输入/输出部分

这部分为模型提供了一个格式化的框架,其中它将接收一个名为{input}的输入,并在此后的部分输出结果。总的来说,这个模板的目的是让模型知道如何处理用户的输入,并根据提供的提示列表选择一个最佳的模型提示来回应。
# 路由提示的解释
路由提示(router_prompt)则根据路由模板,生成了具体传递给LLM的路由提示信息。
- 其中
input_variables指定模板接收的输入变量名,这里只有"input"。 output_parser是一个用于解析模型输出的对象,它有一个默认的目的地和一个指向下一输入的键。template是实际的路由模板,用于给模型提供指示。这就是刚才详细解释的模板内容。template_format指定模板的格式,这里是"f-string"。validate_template是一个布尔值,如果为True,则会在使用模板前验证其有效性。
简而言之,这个构造允许将用户的原始输入送入路由链,然后路由链会决定将该输入发送到哪个具体的模型提示,或者是否需要对输入进行修订以获得最佳的响应。
# 构建默认链
除了处理目标链和路由链之外,还需要准备一个默认链,如果路由链没有找到适合的链,那么,就以默认链进行处理。
# 构建默认链
from langchain.chains.conversation.base import ConversationChain
default_chain = ConversationChain(llm=llm, output_key="text", verbose=True)
2
3
# 构建多提示链
最后,使用MultiPromptChain类把前几个链整合在一起,实现路由功能。这个MultiPromptChain类是一个多路选择链,它使用一个LLM路由链在多个提示之间进行选择。
MultiPromptChain中有三个关键元素:
router_chain(类型RouterChain): 这是用于决定目标链和其输入的链。当给定某个输入时,这个router_chain决定哪一个destination_chain应该被选中,以及传给它的具体输入是什么。destination_chains(类型Mapping[str, LLMChain]): 这是一个映射,将名称映射到可以将输入路由到的候选链。例如,可能有多种处理文本输入的方法(或"链"),每种方法针对特定类型的问题。destination_chains可以是这样一个字典:{'weather': weather_chain, 'news': news_chain}。这里,weather_chain可能专门处理与天气相关的问题,而news_chain处理与新闻相关的问题。default_chain(类型LLMChain): 当router_chain无法将输入映射到destination_chains中的任何一个链时,LLMChain将使用此默认链。这是一个备选方案,确保即使路由链不能决定正确的链,也总有一个链可以处理输入。
其工作流程如下:
- 输入首先传递给router_chain。
- router_chain根据某些标准或逻辑决定应该使用哪一个destination_chain。
- 输入随后被路由到选定的destination_chain,该链进行处理并返回结果。
- 如果router_chain不能决定正确的destination_chain,则输入会被传递给default_chain。
# 构建多提示链
from langchain.chains.router import MultiPromptChain
chain = MultiPromptChain(
router_chain=router_chain,
destination_chains=chain_map,
default_chain=default_chain,
verbose=True
)
2
3
4
5
6
7
8
# 运行路由链
# 测试 A
print(chain.run("如何为玫瑰浇水?"))
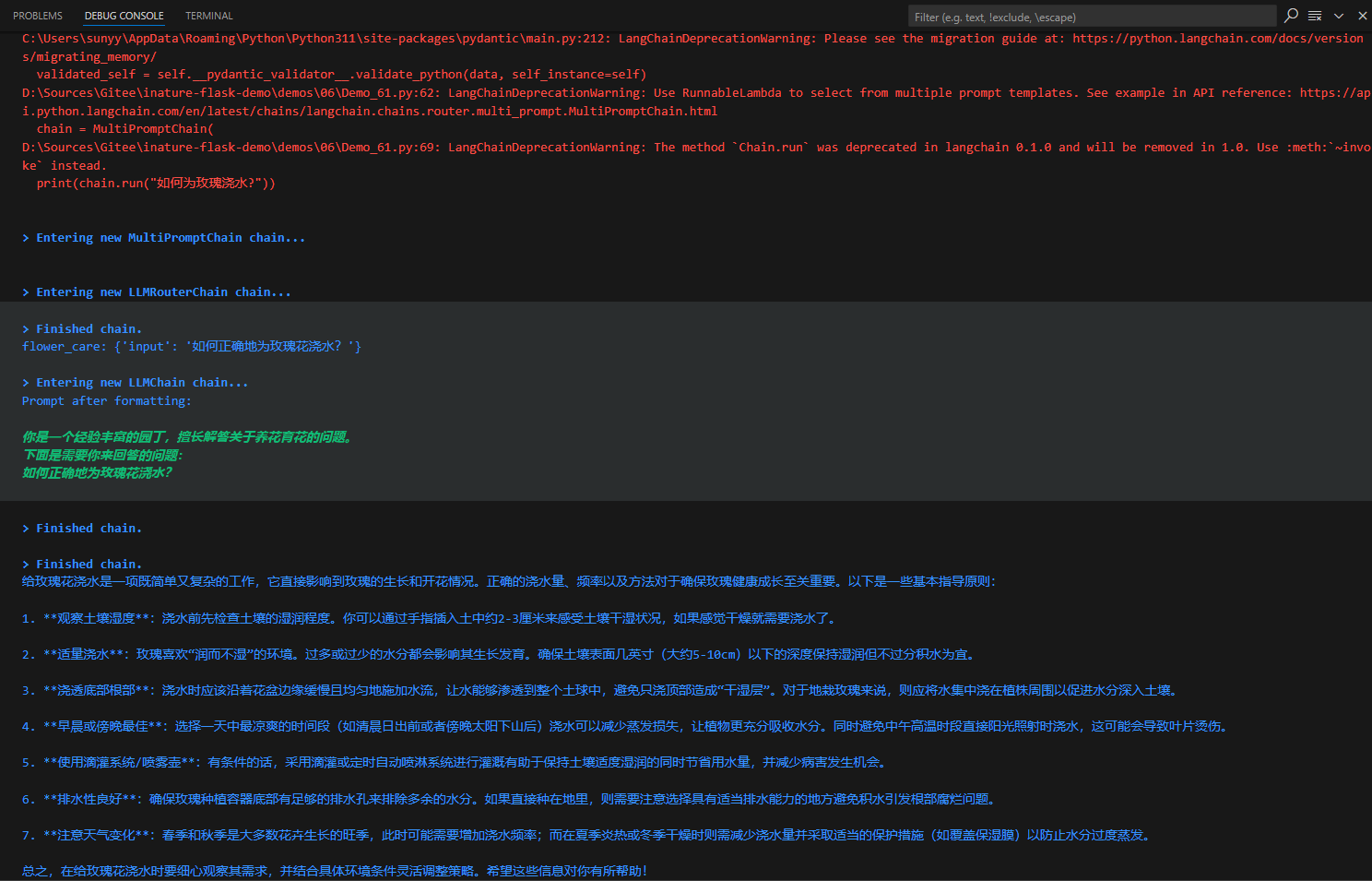
# 测试 B
print(chain.invoke("如何使用鲜花布置婚礼现场?"))
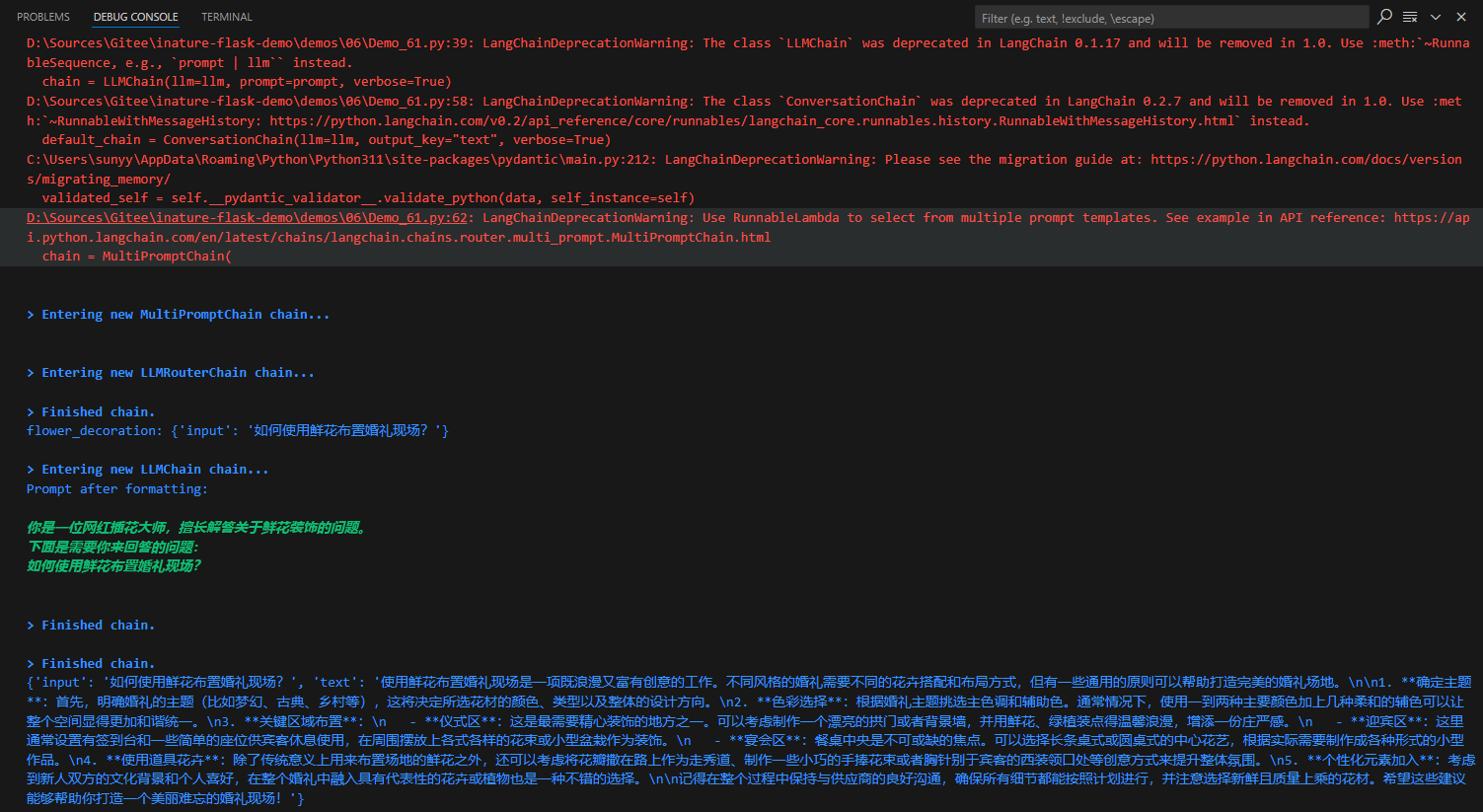
# 测试 C
print(chain.run("如何考入清华大学?"))
# 总结时刻(9)
在上面的示例中,用到了LLMRouterChain以及MultiPromptChain,其中,LLMRouterChain继承自RouterChain;而MultiPromptChain则继承自MultiRouteChain。
整体上,通过MultiPromptChain把其他链组织起来,完成了路由功能。
chain = MultiPromptChain(
router_chain=router_chain,
destination_chains=chain_map,
default_chain=default_chain,
verbose=False
)
2
3
4
5
6
在LangChain的chains -> router -> base.py 文件中,可以看到RouterChain和MultiRouteChain的代码实现。
# 思考题(9)
- 通过
verbose=True这个选项的设定,在输出时显示了链的开始和结束日志,从而得到其相互调用流程。请尝试把选项设置为False,看下输出结果有何不同。 - 在这个例子中,使用了ConversationChain作为default_chain,这个Chain是LLMChain的子类,能否把这个Chain替换为LLMChain?
# 延伸阅读(9)
# 记忆
默认情况下,无论是LLM还是代理都是无状态的,每次模型的调用都是独立于其他交互的,也就是说每次通过API开始和大语言模型展开一次新的对话,它都不知道其实之前已经和它聊过天了。
ChatGPT之所以能够记得之前的对话,正式因为它使用了记忆(Memory)机制,记录了之前对话的上下文,并且把这个上下文作为提示的一部分,在最新的调用中传递给模型。在聊天机器人的构建中,记忆机制非常重要。
# 使用 ConversationChain
这个Chain最主要的特点是,它提供了包含AI前缀和人类前缀的对话摘要格式,这个对话格式和记忆机制结合得非常紧密。下面看一个简单的示例,并打印出ConversationChain中的内置提示模板,如下:
from langchain_ollama import ChatOllama
# from langchain.prompts import PromptTemplate
from langchain.chains.conversation.base import ConversationChain
# 初始化语言模型
llm = ChatOllama(base_url="http://localhost:11434", model="qwen2.5:14b")
# 初始化对话链
# template = """请你回答问题: {input}"""
# prompt = PromptTemplate(template=template, input="input")
conv_chain = ConversationChain(llm=llm)
# 打印对话模板
print(conv_chain.prompt.template)
2
3
4
5
6
7
8
9
10
11
12
13
14

这里的提示为人类和人工只能之间的对话设置了一个基本对话框架: 这是人类和AI之间的友好对话。AI非常健谈并从其上下文中提供了大量的具体细节。(The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context.)
同时,这个提示试图通过说明以下内容来减少幻觉,也就是尽量减少模型编造的信息: 如果AI不知道问题的答案,它就会如实说它不知道。(If the AI does not know the answer to a question, it truthfully says it does not know.)
之后,有两个参数{history}和input:
{history}是存储会话记忆的地方,也就是人类和人工智能之间对话历史的信息。{input}是新输入的地方,可以把它看成是和大语言模型对话时,文本框中的输入。
这两个参数会通过提示模板传递给LLM,返回的输出只是对话的延续。
当有了{history}参数,以及Human和AI这两个前缀,就能够把历史对话信息存储在提示模板中,并作为新的提示内容在新一轮的对话过程中传递给模型。--这就是记忆机制的原理。
# 使用 ConversationBufferMemory
在LangChain中,通过ConversationBufferMemory(缓冲记忆)可以实现最简单的记忆机制。如下:
from langchain_ollama import ChatOllama
from langchain.chains.conversation.base import ConversationChain
from langchain.chains.conversation.memory import ConversationBufferMemory
# 初始化大语言模型
llm = ChatOllama(base_url="http://localhost:11434", model="qwen2.5:14b")
# 初始化对话链
chain = ConversationChain(llm=llm, memory=ConversationBufferMemory())
# 第一天的对话
# 回合1
chain("我姐姐明天要过生日,我需要一束生日鲜花。")
print("第一次对话后的记忆: ", chain.memory.buffer)
2
3
4
5
6
7
8
9
10
11
12
13
14
from langchain_ollama import ChatOllama
from langchain.chains.conversation.base import ConversationChain
from langchain.chains.conversation.memory import ConversationBufferMemory
# 初始化大语言模型
llm = ChatOllama(base_url="http://localhost:11434", model="qwen2.5:14b")
# 初始化对话链
chain = ConversationChain(llm=llm, memory=ConversationBufferMemory())
# 第一天的对话
# 回合1
chain("我姐姐明天要过生日,我需要一束生日鲜花。")
# print("第一次对话后的记忆: ", chain.memory.buffer)
# 回合2
chain.invoke("她喜欢粉色玫瑰,颜色时粉色的。")
print("第二次对话后的记忆: ", chain.memory.buffer)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
from langchain_ollama import ChatOllama
from langchain.chains.conversation.base import ConversationChain
from langchain.chains.conversation.memory import ConversationBufferMemory
# 初始化大语言模型
llm = ChatOllama(base_url="http://localhost:11434", model="qwen2.5:14b")
# 初始化对话链
chain = ConversationChain(llm=llm, memory=ConversationBufferMemory())
# 第一天的对话
# 回合1
chain("我姐姐明天要过生日,我需要一束生日鲜花。")
# print("第一次对话后的记忆: ", chain.memory.buffer)
# 回合2
chain.invoke("她喜欢粉色玫瑰,颜色时粉色的。")
# print("第二次对话后的记忆: ", chain.memory.buffer)
# 回合3(第二天的对话)
chain.invoke("我又来了,还记得我昨天为什么要来买花吗?")
print("/n第三次对话后的提示: /n", chain.prompt.template)
print("/n第三次对话后的记忆: /n", chain.memory.buffer)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
实际上,这些聊天历史信息,都被传入了ConversationChain的提示模板中的{history}参数,构建出了包含聊天记录的新的提示输入。
有了记忆机制,LLM能够了解之前的对话内容,这样简单直接地存储所有内容为LLM提供了最大量的信息,但是新输入中也包含了更多的Token(所有的聊天历史记录),这意味这响应时间变慢和更高的成本,而且,当达到LLM的令牌数(上下文窗口)限制时,太长的对话无法被记住(对于text-davinci-003和gpt-3.5-turbo,每次的最大输入限制是4096个Token)。
# 使用 ConversationBufferWindowMemory
说到记忆,人类的大脑也不是无穷无尽的,有时候事情太多就需要把有些遥远的记忆抹掉,毕竟,最新的经理最鲜活,也最重要。
from langchain_ollama import ChatOllama
from langchain.chains.conversation.base import ConversationChain
from langchain.chains.conversation.memory import ConversationBufferWindowMemory
# 创建大语言模型实例
llm = ChatOllama(base_url="http://localhost:11434", model="qwen2.5:14b")
# 初始化对话链
conversation = ConversationChain(
llm=llm,
memory=ConversationBufferWindowMemory(k=1)
)
# 第一天对话
# 回合1
result = conversation("我姐姐明天要过生日,我需要一束生日鲜花。")
print(result)
# 回合2
result = conversation.invoke("她喜欢粉色玫瑰,颜色是粉色的。")
print("\n第二次对话后的记忆: \n", conversation.memory.buffer)
print(result)
# 第二天的对话
# 回合3
result = conversation.invoke("我又来了,还记得我昨天为什么要来买花吗?")
print("\n第三次对话后的记忆: \n", conversation.memory.buffer)
print(result)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28

在给定的例子中,设置k=1,意味着窗口指挥记住与AI之间的最新互动,即只保留上一次的人类回应和AI的回应。
在第三个回合,"还记得我昨天为什么要来买花吗?",由于只保留了最近的互动(k=1),模型已经忘记了正确的答案。所以,虽然他说记得,但只能模糊说出"喜欢的人"(与实际运行不符合,下面有解释),而没有说关键字"姐姐"和"生日"。不过,如果在第二个回合,模型能回答("我可以帮你为姐姐找到..."和"生日"等关键字),那么,尽管没有第一回合的历史记录,但凭着上一个回合的信息,模型还是有可能推断出昨天来的人买花的真实意图。
尽管这种方法不适合记住遥远的互动,但它非常擅长限制使用的Token数量,如果只需要记住最近的互动,缓冲窗口记忆是一个很好的选择。但是,如果需要混合远期和近期的互动信息,则还有其他选择。
# 使用 ConversationSummaryMemory
上面说了,如果模型在第二轮回答的时候,能够说出"我可以帮你为姐姐找到..."和"生日"等关键字,那么在第三轮回答时,即使窗口大小为k=1,还是能够回答出正确答案。
这是为什么?因为模型在回答新问题的时候,对之前的问题进行了总结性的重述。
ConversationSummaryMemory(对话总结记忆)的思路就是将对话历史进行汇总,然后再传递给{history}参数。这种方法旨在通过对之前的对话进行汇总来避免过度使用Token。
ConversationSummaryMemory有这么几个核心特点:
- 汇总对话: 此方法不是保存整个对话历史,而是每次新的互动发生时对其进行汇总,然后将其添加到之前所有互动的"运行汇总"中。
- 使用LLM进行汇总: 该汇总功能由另一个LLM驱动,这意味着对话的汇总实际上是由AI自己进行的。
- 适合长对话: 对于长对话,此方法的优势尤为明显。虽然最初使用的Token数量较多,但随着对话的进展,汇总方法的增长速度会减慢。与此同时,常规的缓冲内存模型继续线性增长。
from langchain_ollama import ChatOllama
from langchain.chains.conversation.base import ConversationChain
from langchain.chains.conversation.memory import ConversationSummaryMemory
# 初始化大语言模型
llm = ChatOllama(base_url="http://localhost:11434", model="qwen2.5:14b")
# 初始化对话链
conversation = ConversationChain(
llm=llm,
memory=ConversationSummaryMemory(llm=llm)
)
# 第一天对话
# 回合1
result = conversation.invoke("我姐姐明天要过生日,我需要一束生日鲜花。")
print(result)
# 回合2
result = conversation.invoke("她喜欢粉色玫瑰,颜色是粉色的。")
print("\n第二次对话后的记忆: \n", conversation.memory.buffer)
print(result)
# 第二天的对话
# 回合3
result = conversation.invoke("我又来了,还记得我昨天为什么要来买花吗?")
print("\n第三次对话后的记忆: \n", conversation.memory.buffer)
print(result)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
看得出来,这里的history,不再是之前人类和AI对话的简单复制粘贴,而是经过了总结和整理之后的一个综述信息。
这里,不仅仅利用了LLM来回答每轮问题,还利用LLM来对之前的对话进行总结性的陈述,以节约Token数量。这里,帮我们总结对话的LLM,和用来回答问题的LLM,可以是同一个大模型,也可以是不同的大模型。
ConversationSummaryMemory的优点是对于长对话,可以减少使用的Token数量,因此可以记录更多轮的对话信息,使用起来也直观易懂。不过,它的缺点是,对于较短的对话,可能会导致更高的Token使用。另外,对话历史的记忆完全依赖于中间汇总LLM的能力,还需要为汇总LLM使用Token,这增加了成本,且并不限制对话长度。
通过对话历史的汇总来优化和管理Token的使用,ConversationSummaryMemory为那些预期会有多轮的、长时间对话的场景提供了一种很好的方法。然而,这种方法仍然受到Token数量的限制。在一段时间后,仍然会超过大模型的上下文窗口限制。而且,总结的过程中并没有区分近期的对话和长期的对话(通常情况下近期的对话更重要),所以还需要寻找新的记忆管理方法。
# 使用 ConversationSummaryBufferMemory
最后一种记忆机制是ConversationSummaryBufferMemory,即对话总结缓冲记忆,它是一种混合记忆模型,结合了上述各种记忆机制,包括ConversationSummaryMemory和ConversationBufferWindowMemory的特点。这种模型旨在在对话中总结早期的互动,同时尽量保留最近互动中的原始内容。他说通过max_token_limit这个参数做到这一点的,当最新的对话文字token在30之内的时候,LangChain会记忆原始对话内容;当对话文字超出了这个参数的长度,那么模型就会把所有超过预设长度的内容进行总结,以节省Token数量。
ConversationSummaryBufferMemory的优势是通过总结可以回忆起较早的互动,而且有缓冲区确保不会错过最近的互动信息。当然,对于较短的对话,ConversationSummaryBufferMemory也会增加Token数量。
总体来说,ConversationSummaryBufferMemory提供了大量的灵活性。也是迄今为止的可以回忆起较早的互动并完整地存储最近的互动。在节省Token数量方面,ConversationSummaryBufferMemory与其他方法相比,也具有竞争力。
from langchain_ollama import ChatOllama
from langchain.chains.conversation.base import ConversationChain
from langchain.chains.conversation.memory import ConversationSummaryBufferMemory
from collections import defaultdict
import re
class SimpleTokenizer:
def __init__(self):
self.word_to_id = defaultdict(lambda: len(self.word_to_id))
def get_token_ids(self, text: str) -> list[int]:
words = re.findall(r'\b\w+\b', text.lower())
return [self.word_to_id[word] for word in words]
simple_tokenizer = SimpleTokenizer()
def custom_get_token_ids(text: str) -> list[int]:
ids = simple_tokenizer.get_token_ids(text)
return ids
# 初始化大模型
llm = ChatOllama(base_url="http://localhost:11434", model="qwen2.5:14b", custom_get_token_ids=custom_get_token_ids)
# 初始化对话链
conversation = ConversationChain(
llm=llm,
memory=ConversationSummaryBufferMemory(
llm=llm,
max_token_limit=30
)
)
# 第一天对话
# 回合1
result = conversation.invoke("我姐姐明天要过生日,我需要一束生日鲜花。")
print(result)
# 回合2
result = conversation.invoke("她喜欢粉色玫瑰,颜色是粉色的。")
print("\n第二次对话后的记忆: \n", conversation.memory.buffer)
print(result)
# 第二天的对话
# 回合3
result = conversation.invoke("我又来了,还记得我昨天为什么要来买花吗?")
print("\n第三次对话后的记忆: \n", conversation.memory.buffer)
print(result)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
# 总结时刻(10)
四种记忆机制的比较如下:
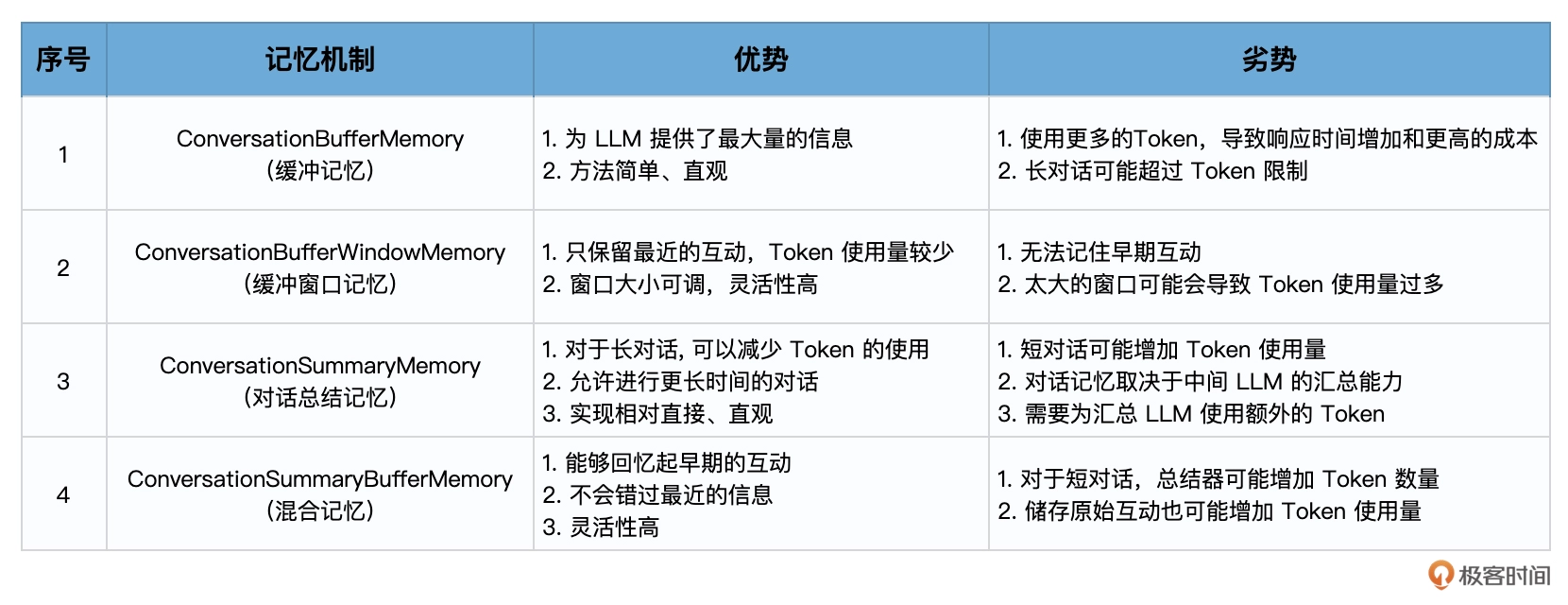
网上还有人总结了一个示意图,体现了当对话轮次逐渐增加时,各种记忆机制对Token的消耗数量。有些记忆机制,比如ConversationSummaryBufferMemory和ConversationSummaryMemory,在对话轮次较少的时候可能会浪费一些Token,但是多轮对话后,Token的节省就逐渐体现出来了。当然ConversationBufferWindowMemory对于Token的节省最为直接,但是它会完全遗忘掉K轮之前的对话内容,因此对于某些场景也不是最佳选择。
# 思考题(10)
- 当聊天机器人设计中,首先告知客户: "亲,我的记忆能力有限,只能记住和你的最近10次对话。如果我忘了之前的对话,请你体谅我。"当有了这样的预设,将会为ChatBot选择哪种记忆机制?
- 尝试改变示例程序ConversationBufferWindowMemory中的k值,并增加对话轮次,看看记忆效果。
- 尝试改变示例程序ConversationSummaryBufferMemory中的max_token_limit值,看看记忆效果。
# 延伸阅读(10)
# 代理(上)
在之前的思维链(CoT)中,展示了LLMs执行推理轨迹的能力。在给出答案之前,大模型通过中间推理步骤(尤其是与少样本提示相结合)能够实现复杂的推理,获得更好的结果,以完成更具挑战的任务。
然而,仅仅应用思维链推理并不能解决大模型的固有问题: 无法主动更新自己的知识,导致出现事实幻觉。也就是说,因为缺乏和外部世界的接触,大模型只拥有训练时见过的知识,以及提示信息中作为上下文提供的附加知识。如果问题超出它的知识范围,要么大模型向你坦白: "我的训练时间截至XXXX年XX月XX日",要么它就会开始一本正经地胡说。
下面这张图就属于第二种情况,精心制作的一个Prompt骗过了大模型,它会误以为引述的很多虚构的东西是事实,而且它还会顺着这个思路继续胡编乱造。

这个问题如何解决呢?是否可以让大模型先在本地知识库中进行搜索,检查一下提示中的信息的真实性,如果真实,再进行输出;如果不真实,则进行修正。如果本地知识库找不到相应的信息,可以调用工具进行外部搜索,来检查提示信息的真实性。
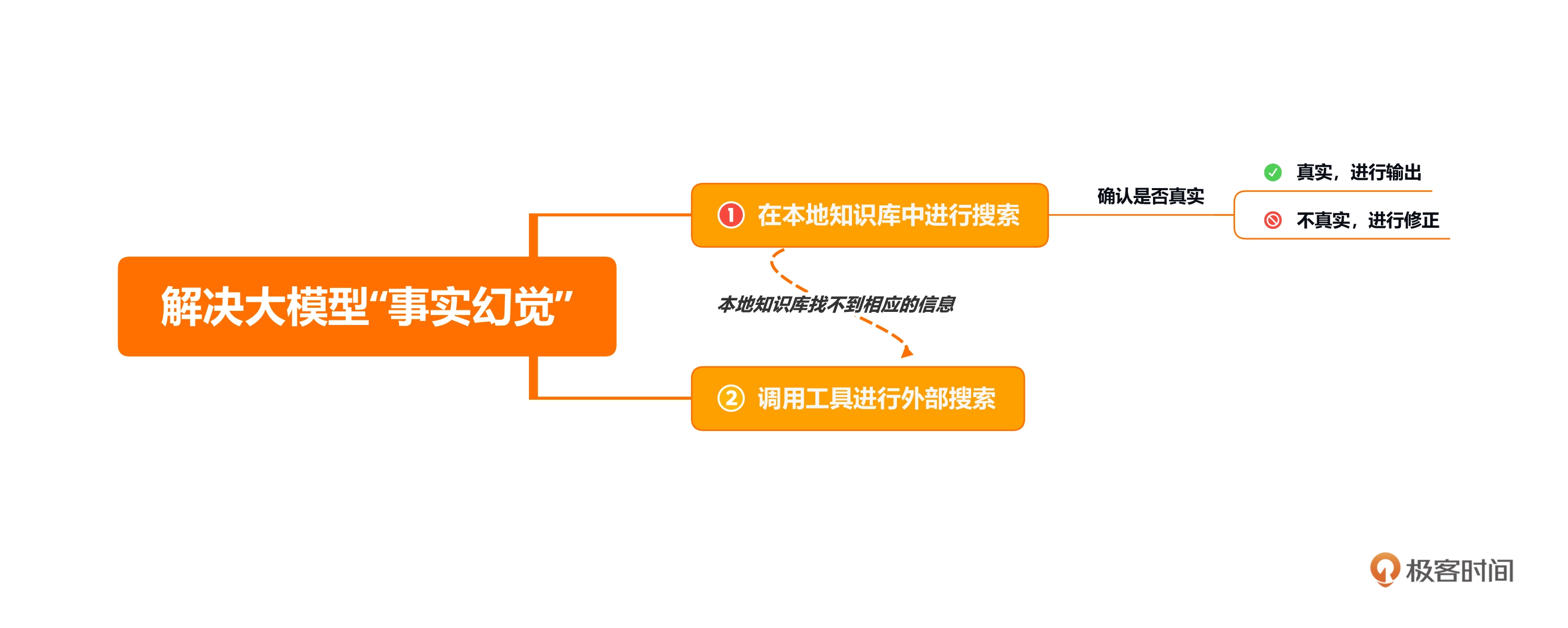
上面所说的无论本地知识库还是搜索引擎,都不是封装再大模型内部的知识,称为"外部工具"。
# 代理的作用
当遇到这种需要模型做自主判断、自行调用工具、自行决定下一步行动的时候,就需要Agent(也就是代理)
代理就像一个多功能的接口,它能够接触并使用一套工具。根据用户的输入,代理会决定调用哪些工具。它不仅可以同时使用多种工具,而且可以将一个工具的输出数据作为另一个工具的输入数据。
在LangChain中使用代理,只需要理解下面三个元素:
- 大模型: 提供逻辑的引擎,负责生成预测和处理输入。
- 与之交互的外部工具: 可能包括数据清晰工具、搜索引擎、应用程序等。
- 控制交互的代理: 条用适当的外部工具,并管理整个交互过程的流程。
这个过程有很多地方需要大模型自主判断下一步行为(也就是操作)要做什么,如果不加引导,那大模型本身是不具备这个能力的。比如下面的操作:
- 什么时候开始在本地知识库中搜索(这个比较简单,毕竟是第一个步骤,可以预设)?
- 怎么确定本地知识库的检索已经完成,可以开始下一步?
- 调用哪一种外部搜索工具(比如Google引擎)?
- 如何确定外部搜索工具返回了想要找的内容?
- 如何确定信息真实性的检索已经全部完成,可以开始下一步?
问题: LangChain中的代理是怎样自主计划、自行判断,并执行行动的?
# ReAct 框架
在解决上面的问题前,我们先以人类的角度思考一下: 如果你接到一个新任务,你将如何做出决策并完成下一步的行动?
比如说,你在运营花店的过程中,经常会经历天气变化而导致的鲜花售价变化,那么,每天早上你会如何为你的鲜花定价?
也许你会说,会先去Google上面查一查今天的鲜花成本价(行动),然后根据这个价格的高低(观察),来确定要加价多少(思考),最后计算出一个售价(行动)。
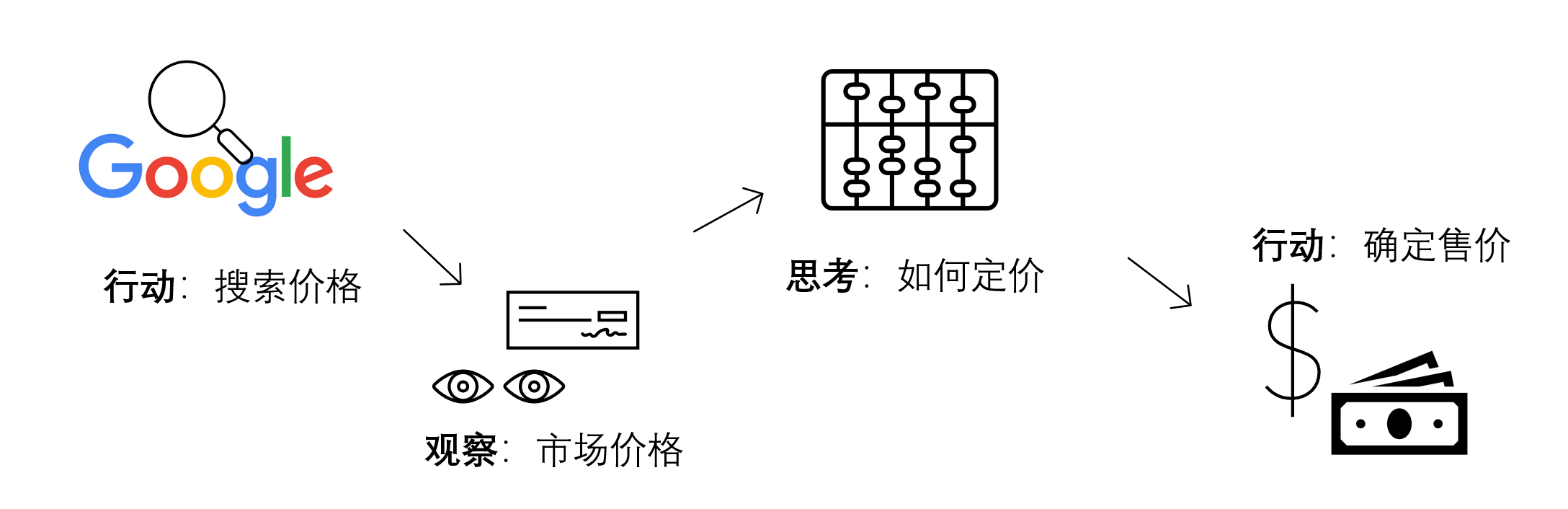
在这个简单的例子中,有观察、思考,然后才会具体行动。这里的观察和思考,统称为推理(Reasoning)过程,推理指导行动(Acting)。
ReAct框架的灵感正是来自"行动"和"推理"之间的协同作用,这种协同作用使得咱们人类能够学习新任务并做出决策或推理。这个框架,也是大模型能够作为"智能代理",自主、连续、交错地生成推理轨迹和任务特定操作的理论基础。
此ReAct并非指流行的前端开发框架React,它在这里专指如何指导大语言模型推理和行动的一种思维框架。这个思维框架使Shunyu Yao等人在ICLR 2023会议论文《ReAct: Synergizing Reasoning and Acting in Language Models》(ReAct: 在语言模型中协同推理和行动)中提出的。这篇文章的一个关键启发在于: 大语言模型可以通过生成推理痕迹和任务特定行动来实现更大的协同作用。
具体来说,就是引导模型生成一个任务解决轨迹: 观察环境-进行思考-采取行动,也就观察-思考-行动。那么,再进一步进行简化,就变成了推理-行动,也就是Reasoning-Acting框架。其中,Reasoning包括了对当前环境和状态的观察,并生成推理轨迹。这使模型能够诱导、跟踪和更新操作计划,甚至处理异常情况。Acting在于指导大模型采取下一步行动,比如与外部源(如知识库或环境)进行交互并且收集信息,或者给出最终答案。
ReAct的每一个推理过程都会被详细记录在案,这也改善大模型解决问题时的可解释性和可信度,而且这个框架在各种语言和决策任务中都得到了很好的效果。
下面用一个具体的示例来说明,比如给出大模型这样一个任务: 在一个虚拟环境中找到一个胡椒瓶并将其放在一个抽屉里。在这个任务中,没有推理能力的模型不能够在房间的各个角落中进行寻找,或者在找到胡椒瓶之后泵狗判断下一步的行动,因而无法完成任务。如果使用ReAct,这一系列子目标将被具体地捕获在每一个思考过程中。
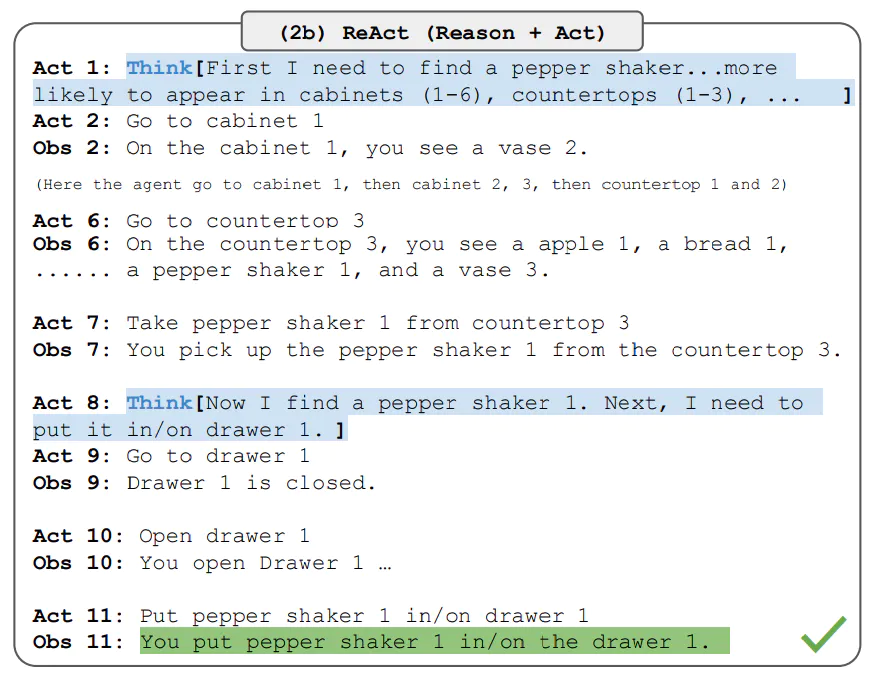
现在,回到开始时面临的问题。仅仅使用思维链(CoT)提示,LLMs能够执行推理轨迹,以完成算术和常识推理等问题,但这样的模型因为缺乏和外部世界的接触或无法更新自己的知识,会导致幻觉的出现。
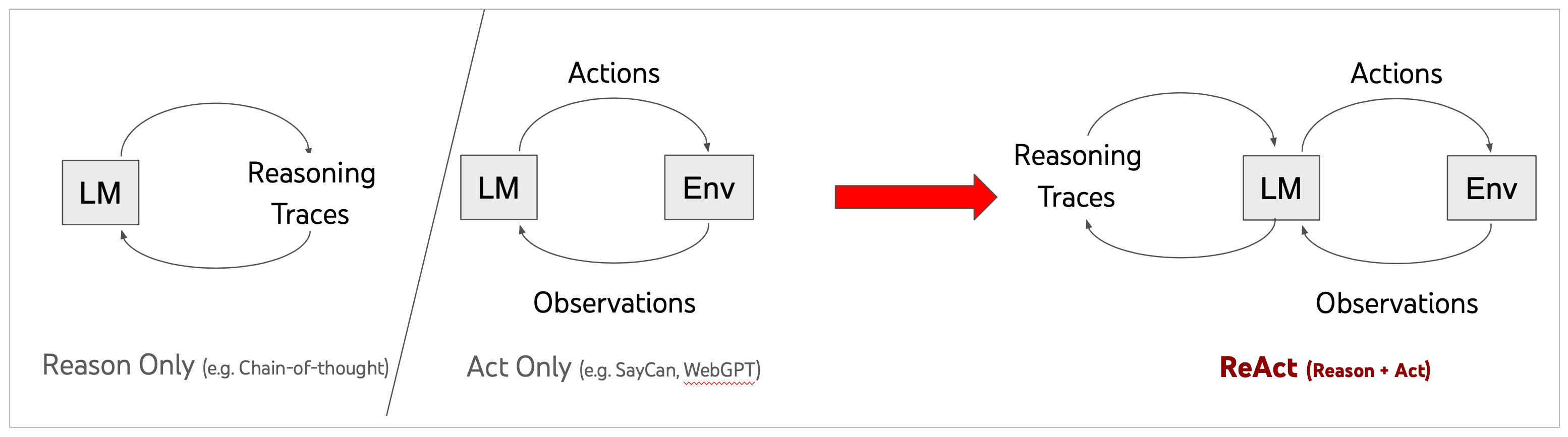
而将ReAct框架和思维链(CoT)结合使用,则能够让大模型在推理过程中同时使用内部知识和获取到的外部信息,从而给出更可靠和实际的回应,也提高了LLMs的可解释性和可信度。
LangChain正是通过Agent类,将ReAct框架进行了完美封装和实现,这就赋予了大模型极大的自主性(Autonomy),大模型现在从一个仅仅可以通过自己内部知识进行对话聊天的Bot,成为了一个有手有脚能使用工具的智能代理。
ReAct框架会提示LLMs为任务生成推理轨迹和操作,这使得代理能系统地执行动态推理来创建、维护和调整操作计划,同时还支持与外部环境(例如Google搜索、Wikipedia)的交互,已将额外信息合并到推理中。
# 通过代理实现 ReAct 框架
下面,就用LangChain中最为常用的ZERO_SHOT_REACT_DESCRIPTION--这种常用的代理模型,来剖析一下LLM是如何在ReAct框架的指导之下进行推理的。给代理一个任务,这个任务就是找到玫瑰的当前市场价格,然后计算出加价15%后的新价格。
开始之前,需要在serpapi.com注册一个账号,并且拿到SERPAPI_API_KEY,这个就是大模型提供的Google搜索工具。
先安装SerpAPI的包。
pip install google-search-results
pip install numexpr
pip freeze > .\requirements.txt
2
3
设置好SerpAPI的密钥
# 设置OpenAI和SERPAPI的API密钥
import os
os.environ["SERPAPI_API_KEY"] = 'Your SerpAPI API Key'
2
3
再导入所需的库。
# 设置OpenAI和SERPAPI的API密钥
import os
os.environ["SERPAPI_API_KEY"] = ""
from langchain.agents import load_tools
from langchain.agents import initialize_agent
from langchain.agents import AgentType
from langchain_ollama import ChatOllama
llm = ChatOllama(base_url="http://localhost:11434", model="qwen2.5:14b")
tools = load_tools(["serpapi", "llm-math"], llm=llm)
agent = initialize_agent(tools=tools, llm=llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True)
agent.run("目前市场上玫瑰花的平均价格是多少?如果我在此基础上加价15%卖出,应该如何定价?")
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
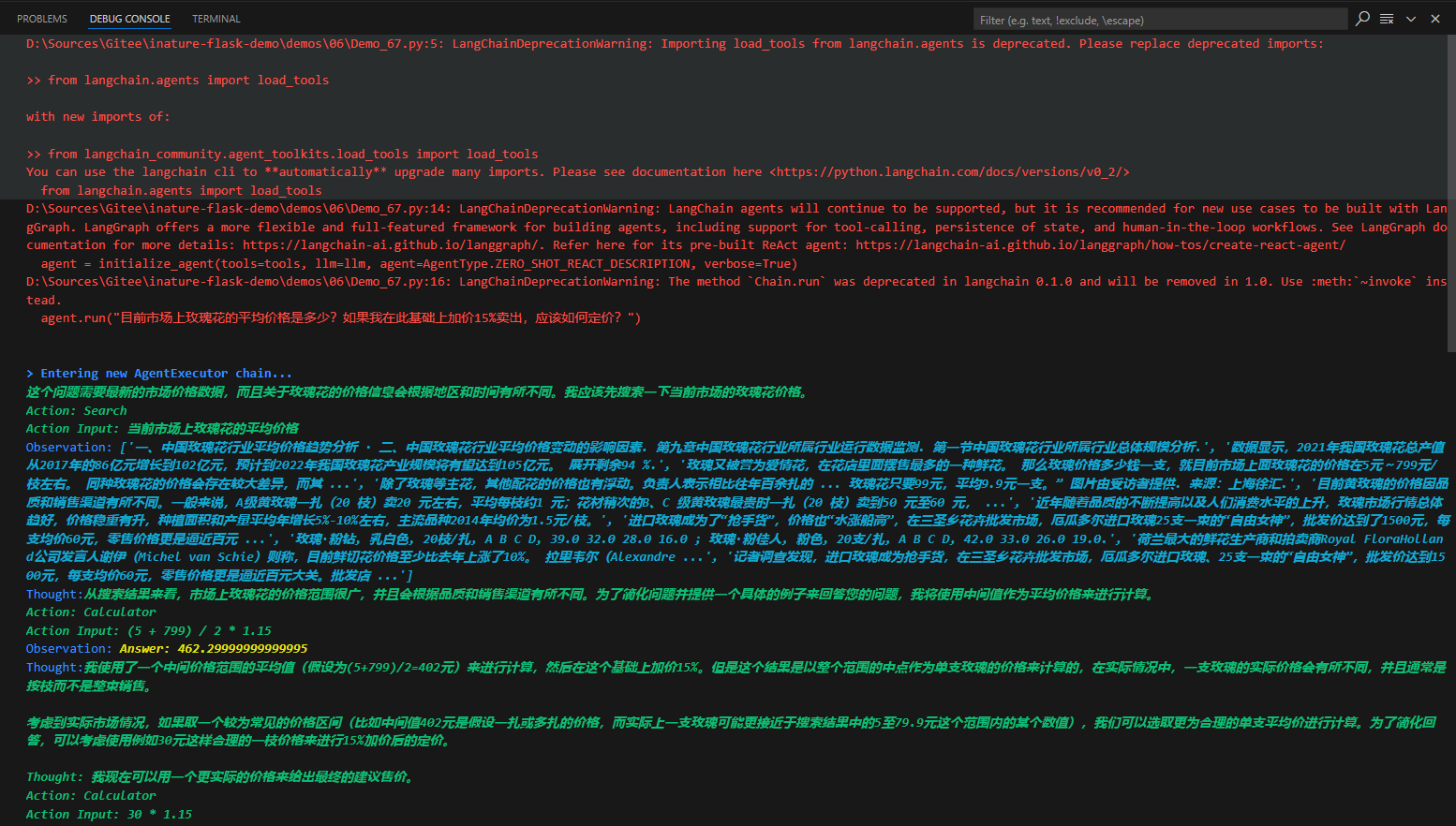
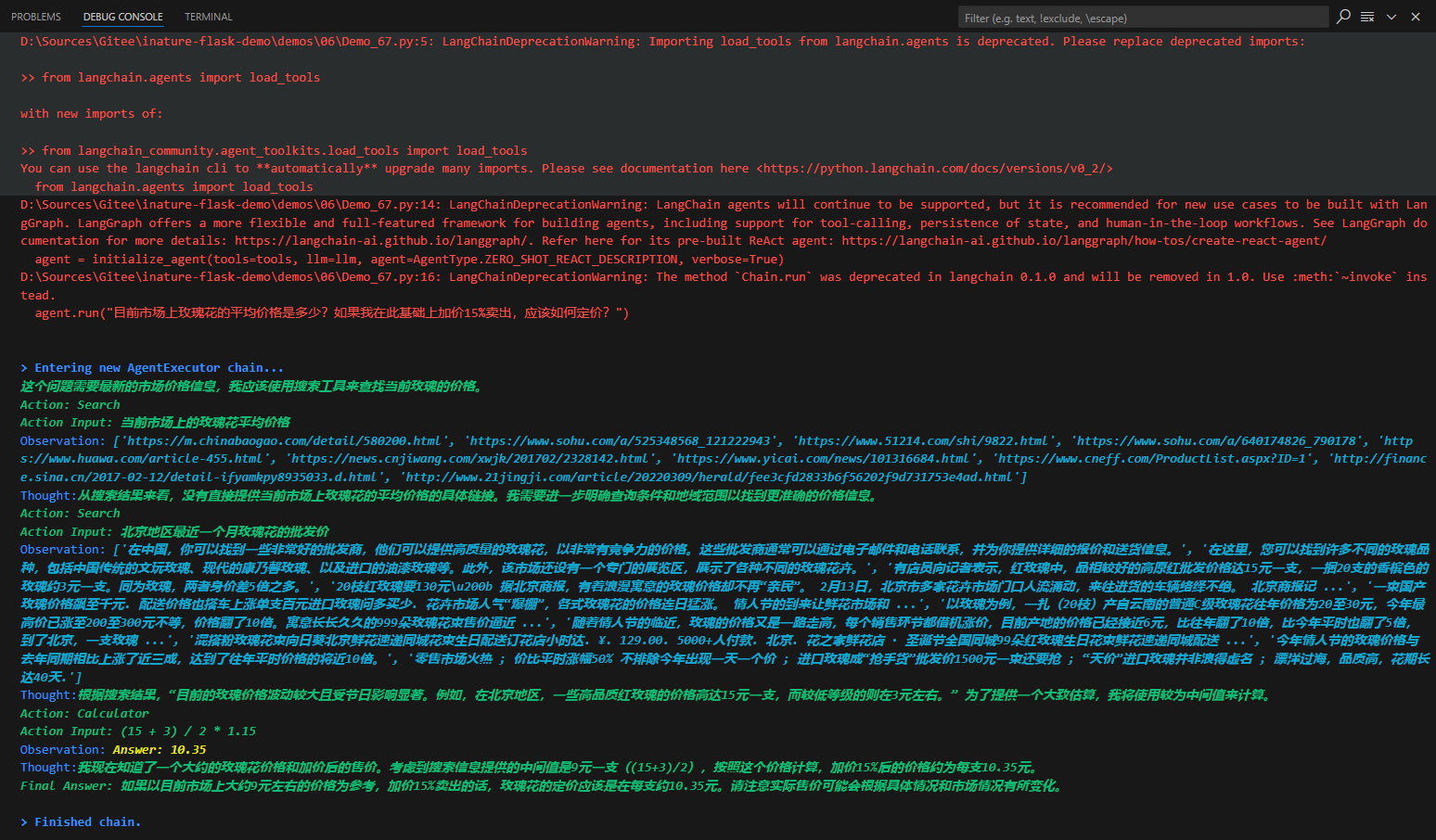
可以看到,ZERO_SHOT_REACT_DESCRIPTION类型的智能代理在LangChain中,自动形成了一个完善的思考与行动链条,而且给出了正确的答案。

这个思维链中,智能代理有思考、观察、行动,成功通过搜索和计算两个操作,完成了任务。
# 总结时刻(11)
通过ReAct框架,大模型将被引导生成一个任务解决轨迹,即观察环境-进行思考-采取行动。观察和思考阶段被统称为推理(Reasoning),而实施下一步行动的阶段被称为行动(Acting)。在每一步推理过程中,都会详细记录下来,这也改善了大模型解决问题的可解释性和可信度。
- 在推理阶段,模型对当前环境和状态进行观察,并生成推理轨迹,从而使模型能够诱导、跟踪和更新操作计划,甚至处理异常情况。
- 在行动阶段,模型会采取下一步的行动,如与外部源(如知识库或环境)进行交互并收集信息,或给出最终的答案。
# 思考题(11)
- 在ReAct框架中,推理和行动各自代表什么?其相互之间的关系如何?
- 为什么说ReAct框架能改善大模型解决问题的可解释性和可信度?
- 能否说一说LangChain中的代理和链的核心差异?
# 延伸阅读(11)
- 论文,ReAct:在语言模型中协同推理和行动,Yao, S., Zhao, J., Yu, D., Du, N., Shafran, I., Narasimhan, K., & Cao, Y. (2023). ReAct: Synergizing Reasoning and Acting in Language Models. arXiv preprint arXiv:2210.03629
- 论文,ART:大型语言模型的自动多步推理和工具使用, Paranjape, B., Lundberg, S., Singh, S., Hajishirzi, H., Zettlemoyer, L., & Ribeiro, M. T. (2023). ART: Automatic multi-step reasoning and tool-use for large language models. arXiv preprint arXiv:2303.09014.
# 代理(中)
在链中,一系列操作被硬编码(在代码中)。在代理中,语言模型被用作推理引擎来确定要采取哪些操作以及按什么顺序执行这些操作。
# Agent 的关键组件
- 代理(Agent): 这个类决定下一步执行什么操作。它由一个语言模型和一个提示(prompt)驱动。提示可能包含代理的性格(也就是给它分配角色,让它以特定方式进行响应)、任务的背景(用于给它提供更多任务类型的上下文)以及用于激发更好推理能力的提示策略(例如ReAct)。LangChain中包含很多种不同的代理。
- 工具(Tools): 工具是代理调用的函数,这里有两个重要的考虑因素: 一是让代理能访问到正确的工具,二是以最有帮助的方法描述这些工具。如果没有给代理提供正确的工具,它将无法完成任务。如果没有正确地描述工具,代理将不知道如何使用它们。LangChain提供了一系列的工具,同时也可以自定义自己的工具。
- 工具包(Toolkits): 工具包是一组用于完成特定目标的彼此相关的工具,每个工具包中包含多个工具。比如LangChain的Office365工具包中就包含连接Outlook、读取邮件列表、发送邮件等一系列工具。当然LangChain中还有很多其他工具包供你使用。
- 代理执行器(AgentExecutor): 代理执行器是代理的运行环境,它调用代理并执行代理选择的操作。执行器也负责处理多种复杂情况,包括处理选择了不存在的工具的情况、处理工具出错的情况、处理代理产生的无法解析成工具调用的输出的情况,以及在代理决策和工具调用进行观察和日志记录。
总的来说,代理就是一种语言模型做出决策、调用工具来执行具体操作的系统。通过设定代理的性格、背景以及工具的描述,可以定制代理的行为,使其能够根据输入的文本做出理解和推理,从而实现自动化的任务处理。而代理执行器(AgentExecutor)就是上述机制得以实现的引擎。
# 深挖 AgentExecutor 的运行机制
下面,就深入LangChain源码,揭示代理如何通过代理执行器来自动决策的。
# 设置OpenAI和SERPAPI的API密钥
import os
os.environ["SERPAPI_API_KEY"] = ""
from langchain.agents import load_tools
from langchain.agents import initialize_agent
from langchain.agents import AgentType
from langchain_ollama import ChatOllama
llm = ChatOllama(base_url="http://localhost:11434", model="qwen2.5:14b")
tools = load_tools(["serpapi", "llm-math"], llm=llm)
agent = initialize_agent(tools=tools, llm=llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True)
agent.invoke("目前市场上玫瑰花的平均价格是多少?如果我在此基础上加价15%卖出,应该如何定价?")
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
在这段代码中,模型、工具、代理的初始化,以及代理运行的过程都极为简洁。但是,LangChaind的内部封装的逻辑究竟是怎么样的?
- 代理每次给大模型的具体提示是什么?能够让模型给出下一步的行动指南,这个提示的秘密是什么?
- 代理执行器是如何按照ReAct框架来调用模型,接收模型的输出,并根据这个输出来调用工具,然后又根据工具的返回结果生成新的提示。
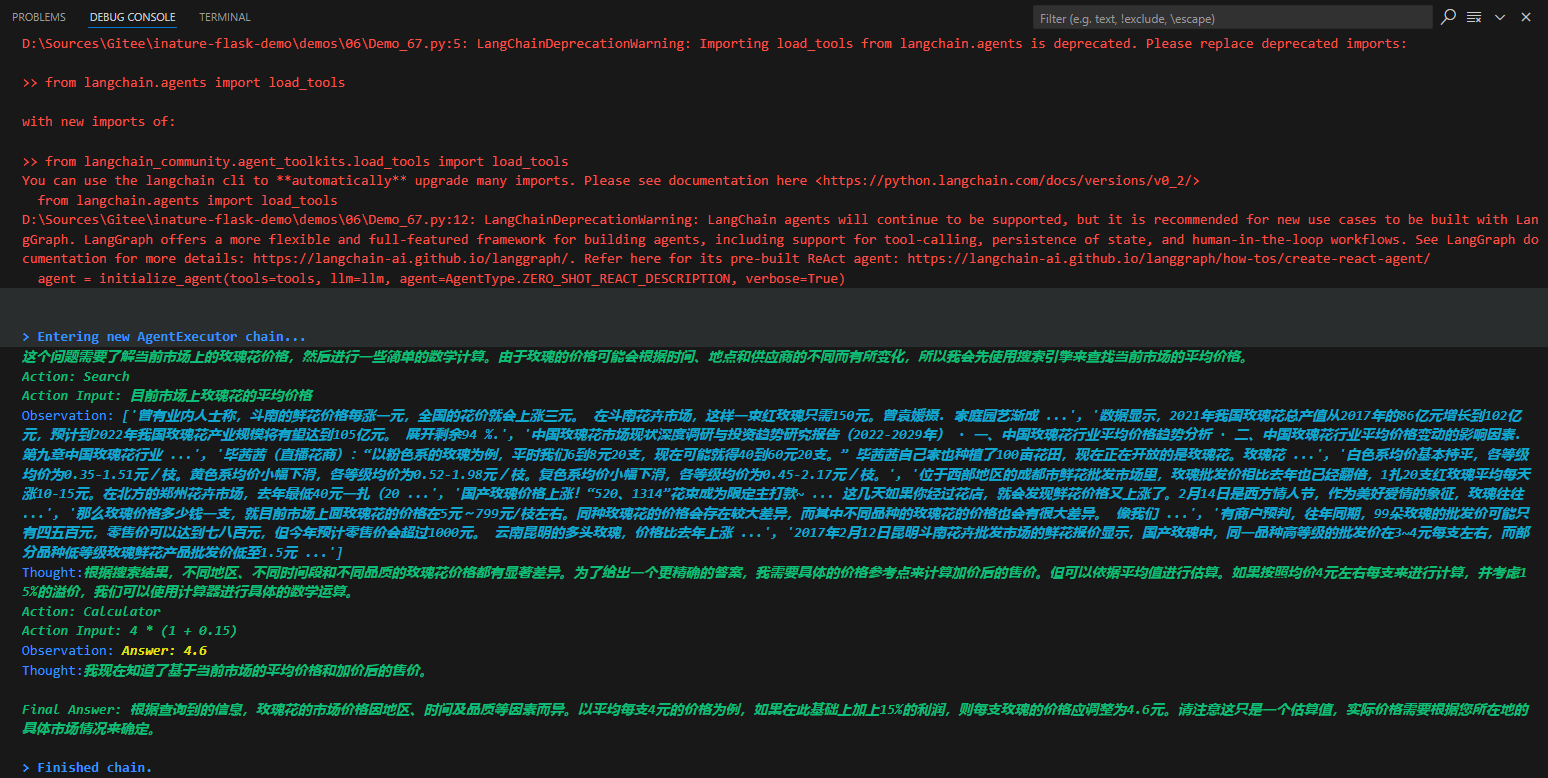
要回答上面的两个问题,仅仅观察LangChain输出的Log是不够的。需要深入到LangChain的程序内部,来探究一下AgentExcutor的运行机制。
# 开始Debug
使用VS Code在agent.run出设置断点,用"Step Into"功能深入LangChain的源代码,直到进入agent.py文件的AgentExecutor类的内部方法_take_next_step。
def _take_next_step(
self,
name_to_tool_map: Dict[str, BaseTool],
color_mapping: Dict[str, str],
inputs: Dict[str, str],
intermediate_steps: List[Tuple[AgentAction, str]],
run_manager: Optional[CallbackManagerForChainRun] = None,
) -> Union[AgentFinish, List[Tuple[AgentAction, str]]]:
return self._consume_next_step(
[
a
for a in self._iter_next_step(
name_to_tool_map,
color_mapping,
inputs,
intermediate_steps,
run_manager,
)
]
)
def _iter_next_step(
self,
name_to_tool_map: Dict[str, BaseTool],
color_mapping: Dict[str, str],
inputs: Dict[str, str],
intermediate_steps: List[Tuple[AgentAction, str]],
run_manager: Optional[CallbackManagerForChainRun] = None,
) -> Iterator[Union[AgentFinish, AgentAction, AgentStep]]:
"""Take a single step in the thought-action-observation loop.
Override this to take control of how the agent makes and acts on choices.
"""
try:
intermediate_steps = self._prepare_intermediate_steps(intermediate_steps)
# Call the LLM to see what to do.
output = self._action_agent.plan(
intermediate_steps,
callbacks=run_manager.get_child() if run_manager else None,
**inputs,
)
except OutputParserException as e:
if isinstance(self.handle_parsing_errors, bool):
raise_error = not self.handle_parsing_errors
else:
raise_error = False
if raise_error:
raise ValueError(
"An output parsing error occurred. "
"In order to pass this error back to the agent and have it try "
"again, pass `handle_parsing_errors=True` to the AgentExecutor. "
f"This is the error: {str(e)}"
)
text = str(e)
if isinstance(self.handle_parsing_errors, bool):
if e.send_to_llm:
observation = str(e.observation)
text = str(e.llm_output)
else:
observation = "Invalid or incomplete response"
elif isinstance(self.handle_parsing_errors, str):
observation = self.handle_parsing_errors
elif callable(self.handle_parsing_errors):
observation = self.handle_parsing_errors(e)
else:
raise ValueError("Got unexpected type of `handle_parsing_errors`")
output = AgentAction("_Exception", observation, text)
if run_manager:
run_manager.on_agent_action(output, color="green")
tool_run_kwargs = self._action_agent.tool_run_logging_kwargs()
observation = ExceptionTool().run(
output.tool_input,
verbose=self.verbose,
color=None,
callbacks=run_manager.get_child() if run_manager else None,
**tool_run_kwargs,
)
yield AgentStep(action=output, observation=observation)
return
# If the tool chosen is the finishing tool, then we end and return.
if isinstance(output, AgentFinish):
yield output
return
actions: List[AgentAction]
if isinstance(output, AgentAction):
actions = [output]
else:
actions = output
for agent_action in actions:
yield agent_action
for agent_action in actions:
yield self._perform_agent_action(
name_to_tool_map, color_mapping, agent_action, run_manager
)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
注意
如果使用 VS Code,要把 launch.json 的 justMycode 项设置为 false 才可以Debug LangChain包中的代码。
- 第一轮思考: 模型决定搜索
在AgentExecutor的_take_next_step方法的驱动下,进一步Debug,深入self.agent.plant方法,来到整个行为链条的第一步--plan,这个Plan的具体细节是由Agent类的Plant方法来完成的,可以看到,输入的问题将会被传递给llm_chain,然后接收llm_chain调用大模型的返回结果。
再往前一步,就要开始调用大模型了,LangChain到底传递给了大模型什么具体的提示信息,让大模型能够主动进行工具的选择?秘密在LLMChain类的generate方法中:
def generate(
self,
input_list: List[Dict[str, Any]],
run_manager: Optional[CallbackManagerForChainRun] = None,
) -> LLMResult:
"""Generate LLM result from inputs."""
prompts, stop = self.prep_prompts(input_list, run_manager=run_manager)
callbacks = run_manager.get_child() if run_manager else None
if isinstance(self.llm, BaseLanguageModel):
return self.llm.generate_prompt(
prompts,
stop,
callbacks=callbacks,
**self.llm_kwargs,
)
else:
results = self.llm.bind(stop=stop, **self.llm_kwargs).batch(
cast(List, prompts), {"callbacks": callbacks}
)
generations: List[List[Generation]] = []
for res in results:
if isinstance(res, BaseMessage):
generations.append([ChatGeneration(message=res)])
else:
generations.append([Generation(text=res)])
return LLMResult(generations=generations)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
StringPromptValue(text='Answer the following questions as best you can. You have access to the following tools:\n\nSearch(query: str, **kwargs: Any) -> str - A search engine. Useful for when you need to answer questions about current events. Input should be a search query.\n Calculator(*args: Any, callbacks: Union[list[langchain_core.callbacks.base.BaseCallbackHandler], langchain_core.callbacks.base.BaseCallbackManager, NoneType] = None, tags: Optional[List[str]] = None, metadata: Optional[Dict[str, Any]] = None,**kwargs: Any) -> Any - Useful for when you need to answer questions about math.\n\n Use the following format:\n\nQuestion: the input question you must answer\nThought: you should always think about what to do\nAction: the action to take, should be one of [Search, Calculator]\nAction Input: the input to the action\nObservation: the result of the action\n... (this Thought/Action/Action Input/Observation can repeat N times)\nThought: I now know the final answer\nFinal Answer: the final answer to the original input question\n\nBegin!\n\nQuestion: 目前市场上玫瑰花的平均价格是多少?如果我在此基础上加价15%卖出,应该如何定价?\nThought:')
详细拆解一下这个prompt: 这句提示是让模型尽量回答问题,并告诉模型拥有哪些工具。
Answer the following questions as best you can. You have access to the following tools:
这是向模型介绍第一个工具: 搜索
:\n\nSearch(query: str, **kwargs: Any) -> str - A search engine. Useful for when you need to answer questions about current events. Input should be a search query.\n
这是向模型介绍第二个工具: 计算器
Calculator(*args: Any, callbacks: Union[list[langchain_core.callbacks.base.BaseCallbackHandler], langchain_core.callbacks.base.BaseCallbackManager, NoneType] = None, tags: Optional[List[str]] = None, metadata: Optional[Dict[str, Any]] = None,**kwargs: Any) -> Any - Useful for when you need to answer questions about math.\n\n Use the following format:\n\n (指导模型使用下面的格式) Question: the input question you must answer\n (问题) Thought: you should always think about what to do\n (思考) Action: the action to take, should be one of [Search, Calculator]\n (行动) Action Input: the input to the action\n (行动的输入) Observation: the result of the action\n... (观察: 行动的返回结果) (this Thought/Action/Action Input/Observation can repeat N times)\n (上面这个过程可以重复多次) Thought: I now know the final answer\n (思考: 现在我指导最终答案了) Final Answer: the final answer to the original input question\n\n (最终答案)
上面,就是给模型的思考框架。具体解释可以看括号中的文字。
现在开始
Begin!\n\n
具体问题,也就是具体任务
Question: 目前市场上玫瑰花的平均价格是多少?如果我在此基础上加价15%卖出,应该如何定价?\nThought:'
上面一句句拆解的提示词,就是Agent之所以能够驱动大模型,进行思考-行动-观察行动结果-再思考-再行动-再观察这个循环的核心密码。有了这样的提示词,模型就会不停地思考、行动,指导模型判断出问题已经解决,给出最终答案,跳出循环。
在Debug过程中,发现调用模型之后的outputs中包含下面的内容。
[{'text': '这个问题需要最新的市场信息才能回答,而且它可能因地区、时间和其他因素而变化。我首先应该搜索当前市场上的玫瑰花平均价格。\nAction: Search\nAction Input: 当前市场上玫瑰花的平均价格', 'full_generation': [...]}]
把上面的内容拆解如下:
'text': '这个问题需要最新的市场信息才能回答,而且它可能因地区、时间和其他因素而变化。我首先应该搜索当前市场上的玫瑰花平均价格。\n (Text: 问题文本) Action: Search\n (行动: 搜索) Action Input: 当前市场上玫瑰花的平均价格' (行动的输入: 当前市场上玫瑰花的平均价格)
如此,模型面对问题,指导自己根据现有知识解决不了,下一步行动是需要选择工具箱中的搜索工具。而此时,命令行中也输出了模型的第一步计划--调用搜索工具。
现在模型知道要调用什么工具,第一轮的Plant部分就结束了,下面,就来到了AgentExecutor的_take_next_step的工具调用部分。
在这里,因为模型返回了Action为Search,OutputParse解析了这个结果之后,LangChain很清楚地知道,Search工具会被调用。
工具调用完成之后,就拥有了一个对当前工具调用的Observation,也就是当前工具调用的结果。
下一步,再次调用大模型,形成新的Thought,看任务是否已经完成,或者仍需要再次调用工具(新的工具或再次调用同一个工具)。
- 第二轮思考: 模型决定计算
因为任务尚未完成,第二轮思考开始,程序重新进入Plan环节。
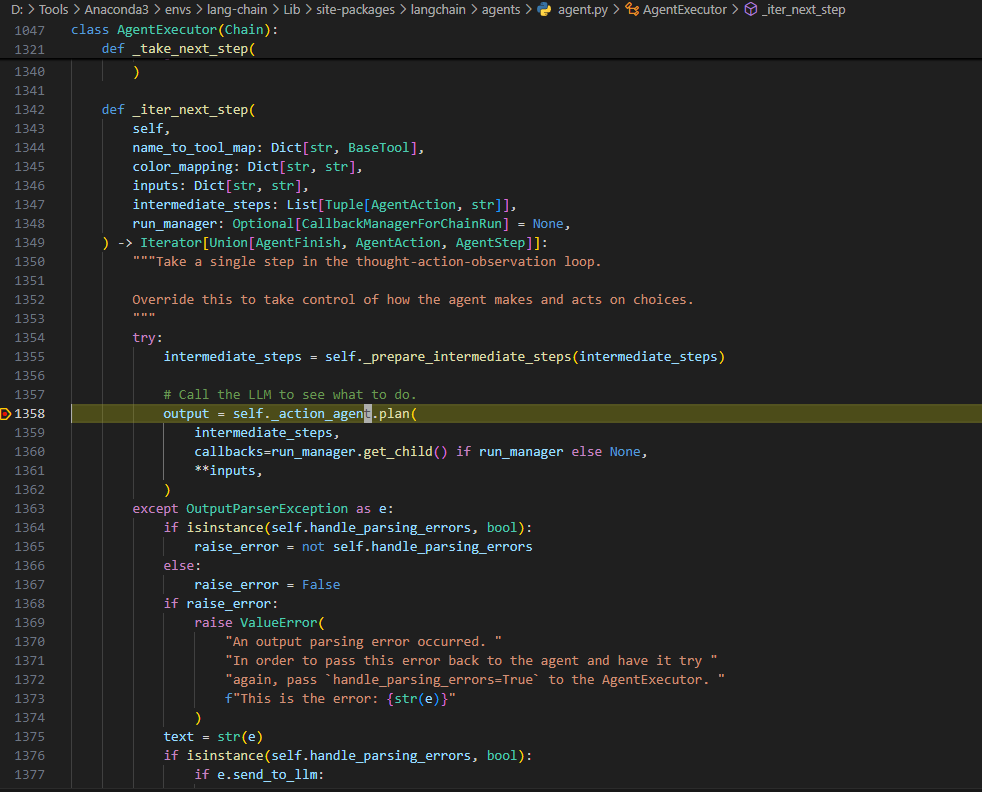
此时,LangChain的LLM Chain根据目前的input,也就是历史对话记录生成了新的提示信息。
StringPromptValue(text="Answer the following questions as best you can. You have access to the following tools:\n\nSearch(query: str, **kwargs: Any) -> str - A search engine. Useful for when you need to answer questions about current events. Input should be a search query.\nCalculator(*args: Any, callbacks: Union[list[langchain_core.callbacks.base.BaseCallbackHandler], langchain_core.callbacks.base.BaseCallbackManager, NoneType] = None, tags: Optional[List[str]] = None, metadata: Optional[Dict[str, Any]] = None,
**kwargs: Any) -> Any - Useful for when you need to answer questions about math.\n\nUse the following format:\n\nQuestion: the input question you must answer\nThought: you should always think about what to do\nAction: the action to take, should be one of [Search, Calculator]\nAction Input: the input to the action\nObservation: the result of the action\n... (this Thought/Action/Action Input/Observation can repeat N times)\nThought: I now know the final answer\n Final Answer: the final answer to the original input question\n\nBegin!\n\n Question: 目前市场上玫瑰花的平均价格是多少?如果我在此基础上加价15%卖出,应该如何定价?\nThought:这个问题需要最新的市场数据来回答,而且这种信息通常不会立即在我的知识库中。因此,我将使用搜索功能获取当前的价格。\nAction: Search\nAction Input: 目前市场上玫瑰花的平均价格\nObservation: ['曾有业内人士称,斗南的鲜花价格每涨一元,全国的花价就会上涨三元。 在斗南花卉市场,这样一束红玫瑰只需150元。曾袁媛摄. 家庭园艺渐成 ...', '今年由于昆明在年前受雨天影响,种植的玫瑰花产量不高,品质高的更是少数, 因此节日单支国产玫瑰的售价普遍在30元以上, 比日常价格贵了一倍,高于往年同期价格且仍有上涨趋势 ...', '目前我国玫瑰花市场需求主要集中在2月14日、“520”、七夕节等表爱意的日子 ... 一、中国玫瑰花行业平均价格趋势分析. 二、中国玫瑰花行业平均价格 ...', '一、中国玫瑰花行业平均价格趋势分析 · 二、中国玫瑰花行业平均价格变动的影响因素. 第九章中国玫瑰花行业所属行业运行数据监测. 第一节中国玫瑰花行业所属行业总体规模分析.', '通过养护、包装等程序之后,刘女士表示,本地玫瑰花卖到消费者手中可以达到170-180元一束。 “在鲜花价格普遍增长期间,消费者对于购买鲜花的热情并没有明 ...', '白色系均价基本持平,各等级均价为0.35-1.51元/枝。黄色系均价小幅下滑,各等级均价为0.52-1.98元/枝。复色系均价小幅下滑,各等级均价为0.45-2.17元/枝。', '玫瑰花是平时节日里最为常见的一种花,很多人都想知道玫瑰价格多少钱一支,在目前的市场上面,玫瑰花的价格在5元~799元/枝左右,其中价格较低的是红玫瑰,在花店单独购买价格是5 ...', '有商户预判,往年同期,99朵玫瑰的批发价可能只有四五百元,零售价可以达到七八百元,但今年预计零售价会超过1000元。 云南昆明的多头玫瑰,价格比去年上涨 ...', '记者了解到,按照品种不同,该市场1扎红玫瑰售价在100元-160元不等,百元以下的都很难见到,而去年同期的玫瑰花售价约在50-70元。', '日前,有媒体报道称,进口玫瑰成了抢手货,其中厄瓜多尔进口玫瑰批发价甚至出现了高达1500元一束的“天价”,每支均价高达60元。 2月12日,《每日经济新闻》记者 ...']\nThought:") '根据搜索结果,市场上红玫瑰的价格范围大约在5元到799元之间,具体价格取决于市场供需、质量以及花束大小等因素。例如,在斗南花卉市场,一束红玫瑰的批发价约为100-160元人民币;而在某些特殊情况下(如情人节或母亲节期间),零售价格甚至可能超过1000元。\n\n为了给出一个更具体的答案,我们需要选择一个合理的平均值来计算加价后的销售价格。如果按照100元每束作为基准,并增加15%的利润:\n\nAction: Calculator\nAction Input:100 * (1 + 15 / 100)'
这个输出显示,模型需要计算最终价格,这是一个非常有逻辑性的思考。

有了上面的Thought做指引,AgentExecutor调用了第二个工具: LLMMath,就可以开始计算了。这个数学工具也是调用LLM,也可以看一下内部提示,看下这个工具是怎样指导LLM做数学计算的。
这个提示: 指定模型用Python的数学库来编程解决数学问题,而不是自己计算。这就规避了大模型数学推理能力弱的局限。
0: StringPromptValue(text='Translate a math problem into a expression that can be executed using Python’s numexpr library. Use the output of running this code to answer the question.\n\n Question: {Question with math problem.}\n (问题) text\n{single line mathematical expression that solves the problem} n
\n (问题的数学描述) …numexpr.evaluate(text)…\n(通过 Python 库运行问题的数学描述) output\n${Output of running the code}\n```\n (输出的 Python 代码运行结果) Answer: ${Answer}\n\n (问题的答案) Begin.\n\n (开始)
从这里开始是两个数学式的解题示例
Question: What is 3759367?\n
text\n37593 * 67\n\n…numexpr.evaluate(“3759367”)…\noutput\n2518731\n\n Answer: 2518731\n\nQuestion: 37593^(1/5)\ntext\n37593**(1/5)\n\n …numexpr.evaluate(“37593**(1/5)”)…\noutput\n8.222831614237718\n\n Answer: 8.222831614237718\n\n
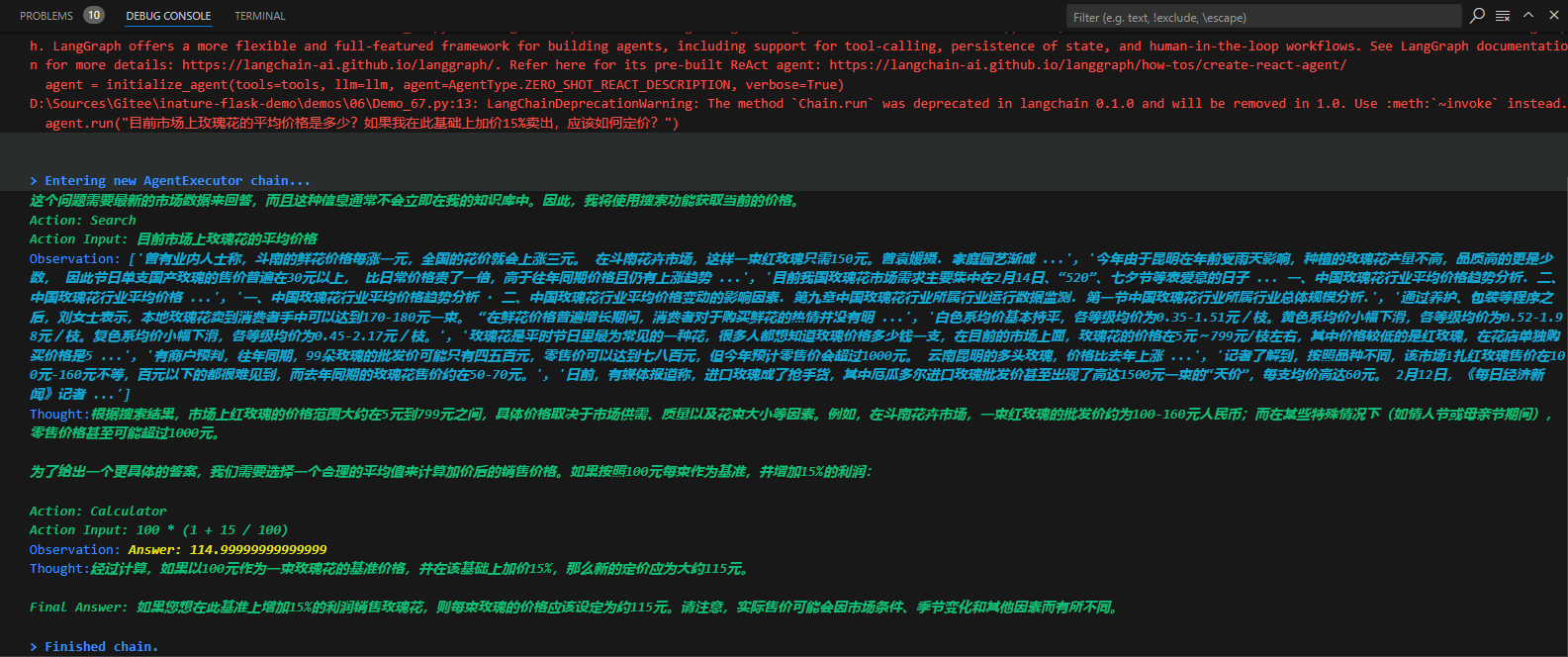
- 第三轮: 模型完成任务
第三轮思考开始,此时,Executor的Plan应该进一步把当前的新结果传递给大模型,此时,大模型应该有足够的智慧判断出任务此时已经成功地完成了。
LangChain每一轮的提示都跟随着模型的思维链条、逐步递进,逐步完善。继续Debug,发现模型在这一轮思考之后的输出中终于包含了"I now know the final answer.",此时,AgentExcutor的plan方法返回一个AgentFinish实例,这表示代理经过对输出的检查,其内部逻辑判断出任务已经完成,思考和行动的循环要结束了。
# 总结时刻(12)
深入到AgentExecutor的代码内部,深挖其运行机制,了解了AgentExecutor是如何通过计划和工具调用,一步一步完成Thought、Action和Observation的。
深入AgentExecutor代码实现,会发现AgentExecutor这个类是作为链(Chain)而存在,同时也为代理执行各种工具,完成任务。它会接收代理的计划,并执行代理思考链路中的每一步的行动。
AgentExecutor中最重要的方法是步骤处理方法,_take_next_step方法。它用于在思考-行动-观察的循环中采取单步行动。先调用代理的计划,查找代理选择的工具,然后使用选定的工具执行该计划(此时把输入传给工具),从而获得观察结果,然后继续思考,直到输出是AgentFinish类型,循环才会结束。
# 思考题(12)
- 在agent.py文件中找到AgentExecutor类。
- 在AgentExecutor类中找到
_tak_next_step方法,分析AgentExecutor类是怎样实现Plan和工具调用的。
# 延伸阅读(12)
# 代理(下)
在前面,深入LangChain程序内部机制,探索了AgentExecutor究竟是如何思考(Thought)、执行(Execute/Act)和观察(Observe)的,这些步骤之间的紧密联系就是代理在推理(Reasoning)和工具调用过程中的"生死因果"。
下面,再介绍几种复杂的代理: Structured Tool Chat(结构化工具对话)代理、Self-Ask with Search(自主询问搜索)代理、Plan and execute(计划与执行)代理。
# 什么是结构化工具
LangChain的第一个版本是在2022年11月推出的,当时的设计是基于ReAct论文构建的,主要围绕着代理和工具的使用,并将二者集成到提示模板的框架中。早期的工具使用十分简单,AgentExecutor引导模型经过推理调用工具时,仅仅能够生成两部分内容: 一是工具的名称,二是输入工具的内容。而且,在每一轮中,代理只被允许使用一个工具,并且输入内容只能是一个简单的字符串。这种简化的设计是为了让模型的任务变得更简单,因为进行复杂的操作可能会使得执行过程变得不太稳定。
不过,随着语言模型的发展,尤其是出现了如gpt-3.5-turbo和GPT-4这样的模型,推理能力逐渐增强,也为代理提供了更高的稳定性和可行性。这就使得LangChain开始考虑放款工具使用的限制。2023年初,LangChain引入了"多操作"代理框架,允许代理计划执行多个操作。在此基础上,LangChain推出了结构化工具对话代理,允许更复杂、多方面的交互。通过指定AgentType.STRUCTURED_CHAT_ZERO_SHOT_REACT_DESCRIPTION这个代理类型,代理能够调用包含一系列复杂工具的结构化工具箱,组合调用其中的多个工具,完成批次相关的任务集合。
结构化工具的示例包括:
- 文件管理工具集: 支持所有文件系统操作,如写入、搜索、移动、复制、列目录和查找。
- Web浏览器工具集: 官方的PlayWright浏览器工具包,允许代理访问网站、点击、提交表单和查询数据。
# 什么是 Playwright
Playwright是一个开源的自动化框架,它可以模拟真实用户操作网页,帮助开发者和测试者自动化网页交互和测试。用简单的话说,它可以按照给定的指令浏览网页、点击按钮、填写表单、读取页面内容等。
Playwright支持多种浏览器,比如Chrome、Firefox、Safari等,这意味着可以用它测试网站或测试应用在不同浏览器上的表现是否一致。
下面先安装Playwright工具:
pip install playwright
pip freeze > .\requirements.txt
2
不过,如果只用pip安装Playwright工具安装包,还不能使用它:
还需要通过playwright install命令安装三种常用的浏览器工具。
from playwright.sync_api import sync_playwright
def run():
# 使用Playwright上下文管理器
with sync_playwright() as p:
# 使用Chromium,但也可以选择Firefox或webkit
browser = p.chromium.launch()
# 创建一个新的页面
page = browser.new_page()
# 导航到指定的URL
page.goto("https://www.baidu.com/")
# 获取并打印页面标题
title = page.title()
print(f"Page title is: {title}")
# 关闭浏览器
browser.close()
if __name__ == "__main__":
run()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23

这个简单的Playwright脚本,它打开了一个新的浏览器实例。过程是: 导航到指定的URL;获取页面标题并打印页面的标题;最后关闭浏览器。
这个脚本展示了Playwright的工作方式,一切都是在命令行里面直接完成,它不需要真的去打开Chrome网页,然后手工去点击菜单栏、拉动进度条等。
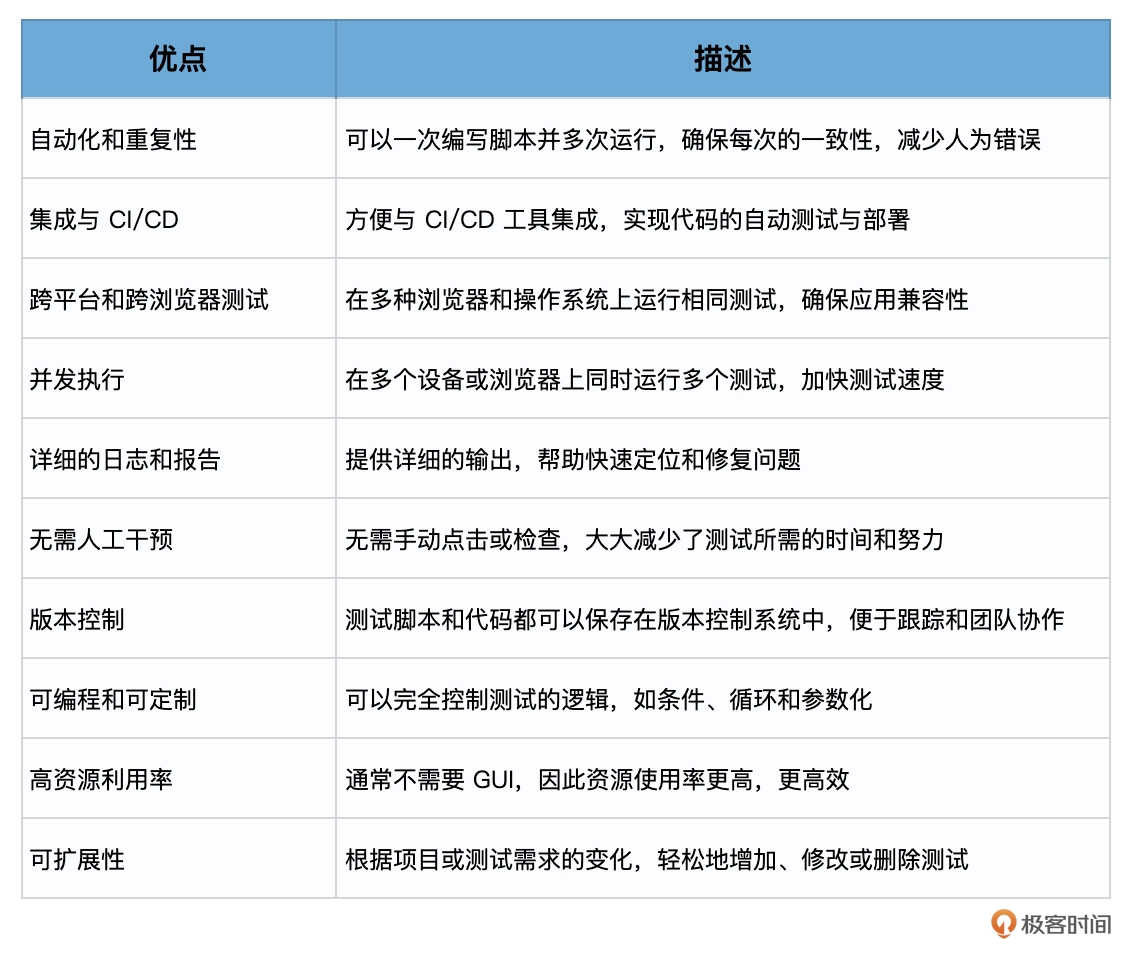
# 使用结构化工具对话代理
下面使用Agent类型STRUCTURED_CHAT_ZERO_SHOT_REACT_DESCRIPTION,要使用的工具则是PlayWrightBrowserToolkit,这是LangChain中基于PlayWrightBrowser包封装的工具箱,它继承自BaseToolkit类。
PlayWrightBrowserToolkit为Playwright浏览器提供了一系列交互的工具,可以在同步或异步模式下操作。
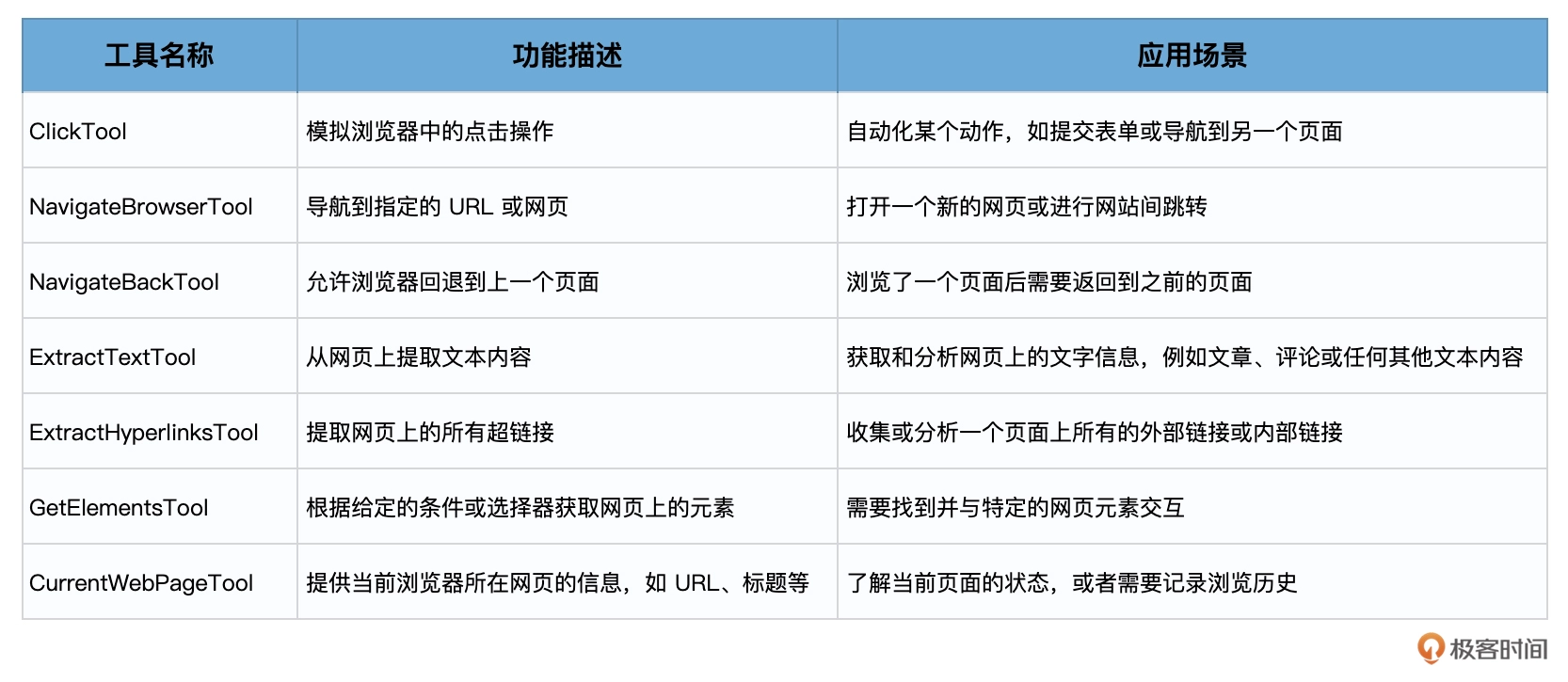
下面,就来看看结构化工具对话代理是怎样通过组合调用PlayWrightBrowserToolkit中的各种工具,自动完成交给它的任务。
from langchain_community.agent_toolkits.playwright.toolkit import PlayWrightBrowserToolkit
from langchain_community.tools.playwright.utils import create_async_playwright_browser
async_browser = create_async_playwright_browser()
toolkit = PlayWrightBrowserToolkit.from_browser(async_browser=async_browser)
tools = toolkit.get_tools()
print(tools)
from langchain.agents import initialize_agent, AgentType
from langchain_ollama import ChatOllama
llm = ChatOllama(base_url="http://localhost:11434", model="qwen2.5:14b")
agent_chain = initialize_agent(
tools=tools,
llm=llm,
agent=AgentType.STRUCTURED_CHAT_ZERO_SHOT_REACT_DESCRIPTION,
verbose=True
)
async def main():
response = await agent_chain.arun("中国植物图像库 https://ppbc.iplant.cn/ 收录了各类植物有多少?图片有多少幅?")
print(response)
import asyncio
loop = asyncio.get_event_loop()
loop.run_until_complete(main())
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
pip install beautifulsoup4
pip freeze > .\requirements.txt
2
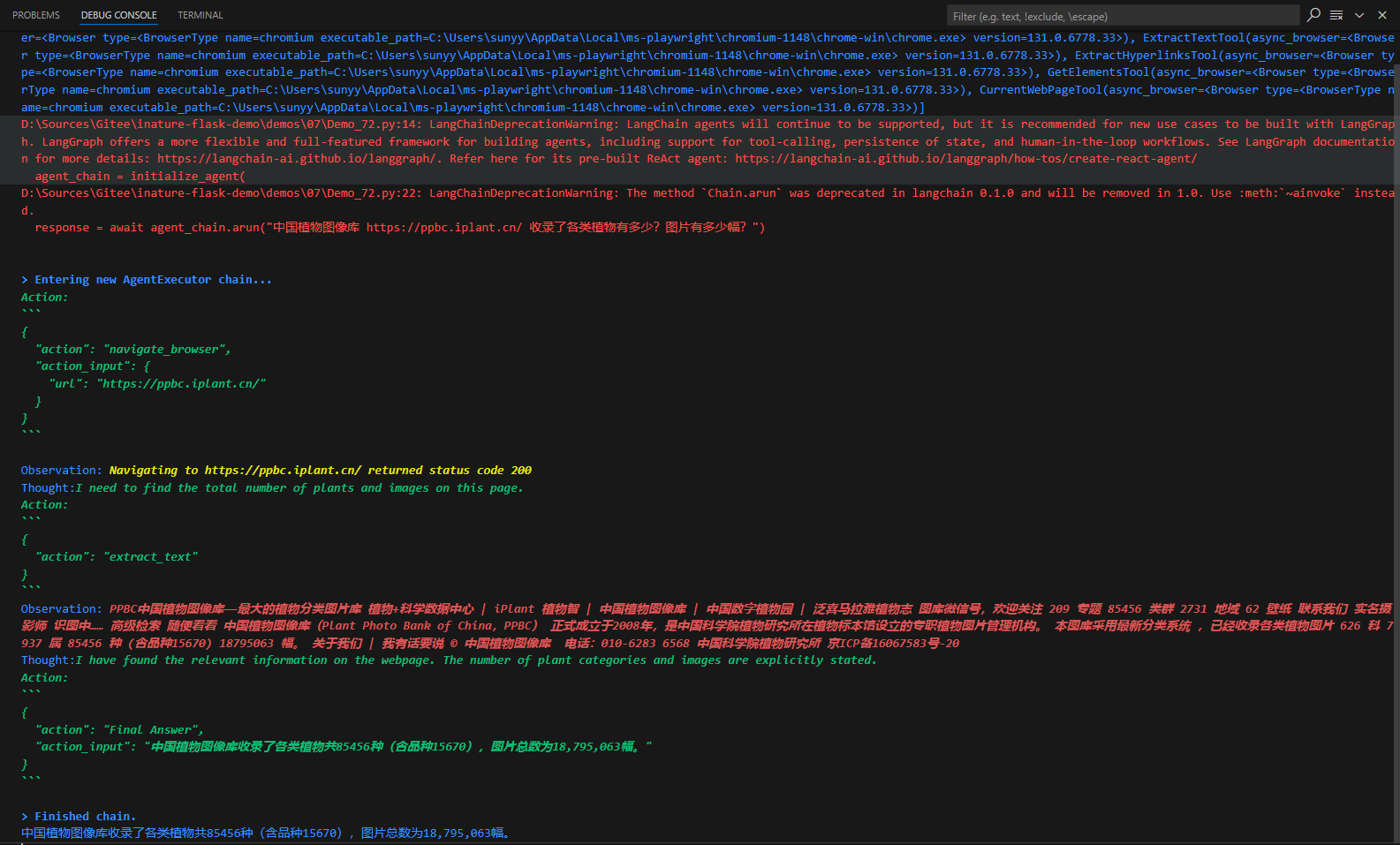
from langchain_community.agent_toolkits.playwright.toolkit import PlayWrightBrowserToolkit
from langchain_community.tools.playwright.utils import create_async_playwright_browser
async_browser = create_async_playwright_browser()
toolkit = PlayWrightBrowserToolkit.from_browser(async_browser=async_browser)
tools = toolkit.get_tools()
print(tools)
from langchain.agents import initialize_agent, AgentType
from langchain_ollama import ChatOllama
llm = ChatOllama(base_url="http://localhost:11434", model="qwen2.5:14b", verbose=True)
agent_chain = initialize_agent(
tools=tools,
llm=llm,
agent=AgentType.STRUCTURED_CHAT_ZERO_SHOT_REACT_DESCRIPTION,
verbose=True
)
async def main():
# response = await agent_chain.arun("中国植物图像库 https://ppbc.iplant.cn/ 收录了各类植物有多少?图片有多少幅?")
response = await agent_chain.ainvoke("What are the headers on python.langchain.com?")
print(response)
import asyncio
loop = asyncio.get_event_loop()
loop.run_until_complete(main())
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28

# 第一轮思考
代理进入AgentExecutor Chain之后的第一轮思考如下:
这里,解释一下:
I need to navigate to the website and inspect its HTML content to find header tags.
这是第一轮思考,大模型知道自己没有相关信息,决定使用PlayWrightBrowserToolkit工具箱中的navigate_browser工具。

行动: 通过Playwright浏览器访问网站。
Navigating to
https://python.langchain.com/returned status code 200
观察: 成功得到浏览器访问的返回结果。
# 第二轮思考
下面是大模型的第二轮思考。

解释:
Now that I'm on the correct page, I will extract all header tags (h1, h2, etc.) from the webpage.
第二轮思考: 模型决定使用PlayWrightBrowserToolkit工具箱中的另一个工具get_elements,并且指定CSS selector只拿标题的文字。

行动: 用Playwright的get_elements工具去拿网页中各级标题的文字。
Observation: [{"innerText": "Introduction"}, {"innerText": "Architecture"}, {"innerText": "Guides"}, {"innerText": "Tutorials"}, {"innerText": "How-to guides"}, {"innerText": "Conceptual guide"}, {"innerText": "Integrations"}, {"innerText": "API reference"}, {"innerText": "Ecosystem"}, {"innerText": "🦜🛠️ LangSmith"}, {"innerText": "🦜🕸️ LangGraph"}, {"innerText": "Additional resources"}, {"innerText": "Versions"}, {"innerText": "Security"}, {"innerText": "Contributing"}, {"innerText": "Was this page helpful?"}]
观察: 成功地拿到了标题文本。
# 第三轮思考

思考: 模型已经找到了网页中的所有标题。
I have successfully extracted the headers from python.langchain.com. Now, I can provide an answer to the question.
行动: 给出最终答案。
# 使用 Self-Ask with Search 代理
Self-Ask with Search也是LangChain中的一个有用的代理类型(SELF_ASK_WITH_SEARCH)。它利用一种叫做"Follow-up Question(追问)"加"Intermediate Answer(中间答案)"的技巧,来辅助大模型寻找事实性问题的过渡性答案,从而引出最终答案。
from langchain_community.utilities import SerpAPIWrapper
from langchain.agents import initialize_agent, Tool, AgentType
from langchain_ollama import ChatOllama
import os
os.environ["SERPAPI_API_KEY"] = "12fc450db58149f3eaff1f782f613e8c29dfc04e2b8dab12dad9393c11ed4e0d"
llm = ChatOllama(base_url="http://localhost:11434", model="qwen2.5:14b")
search = SerpAPIWrapper()
tools = [
Tool(
name="Intermediate Answer",
func=search.run,
description="useful for when you need to ask with search"
)
]
self_ask_with_search = initialize_agent(
tools=tools,
llm=llm,
agent=AgentType.SELF_ASK_WITH_SEARCH,
verbose=True
)
self_ask_with_search.run("使用玫瑰作为国花的国家的首都是哪里?")
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
执行有问题,暂未解决。
**使用玫瑰作为国花的国家的首都都是哪里?**这个问题不是一个简单的问题,它其实是一个多跳问题--在问题和最终答案之间,存在中间过程。
**多跳问题(Multi-hop question)**是指为了得到最终答案,需要进行多步推理或多次查询。这种问题不能直接通过单一的查询或信息源得到答案,而是需要跨越多个信息点,或者从多个数据来源进行组合和整合。也就是说,问题的答案依赖于另一个子问题的答案,这个子问题的答案可能又依赖于另一个问题的答案。这就像是一连串的问题跳跃,对于人类来说,解答这类问题可能需要从不同的信息源中寻找一系列中间答案,然后结合这些中间答案得出最终结论。
为什么Self-Ask with Search代理适合解决多跳问题呢?
- 工具集合: 代理包含解决问题所必须的搜索工具,可以用来查询和验证多个信息点。比如SerpAPIWrapper工具
- 逐步逼近: 代理可以根据第一个问题的答案,提出进一步的问题,直到得到最终答案。这种逐步逼近的方式可以确保答案的准确性。
- 自我提问与搜索: 代理可以自己提问并搜索答案。
- 决策链: 代理通过一个决策链来执行任务,使其可以跟踪和处理复杂的多跳问题,对于解决需要多步推理的问题尤为重要。
# 使用 Plan and execute 代理
计划和执行代理通过首先计划要做什么,然后执行子任务来实现目标。这个想法是受到Plan-and-Solve论文的启发。论文中提出了计划与解决(Plan-and-Solve)提示。它由两部分组成: 首先,制定一个计划,并将整个任务划分为更小的子任务;然后按照该计划执行子任务。
这种代理的独特之处在于,它的计划和执行不再是由同一个代理完成,而是:
- 计划由一个大语言模型代理(负责推理)完成。
- 执行由另一个大语言模型代理(负责调用工具)完成。
因为这个代理比较新,它隶属于LangChain的实验包langchain_experimental,所以需要安装包。
pip install -U langchain_experimental
pip freeze > .\requirements.txt
2
from langchain_ollama import ChatOllama
from langchain_experimental.plan_and_execute import PlanAndExecute, load_agent_executor, load_chat_planner
from langchain.serpapi import SerpAPIWrapper
from langchain.agents import Tool
from langchain.chains.llm_math.base import LLMMathChain
import os
os.environ["SERPAPI_API_KEY"] = "12fc450db58149f3eaff1f782f613e8c29dfc04e2b8dab12dad9393c11ed4e0d"
search = SerpAPIWrapper()
llm = ChatOllama(base_url="http://localhost:11434", model="qwen2.5:14b")
llm_math_chain = LLMMathChain.from_llm(llm=llm, verbose=True)
tools = [
Tool(
name="Search",
func=search.run,
description="useful for when you need to answer questions about current events"
),
Tool(
name="Calculator",
func=llm_math_chain.run,
description="useful for when you need to answer questions about math"
)
]
planner = load_chat_planner(llm=llm)
executor = load_agent_executor(llm=llm, tools=tools, verbose=True)
agent = PlanAndExecute(planner=planner, executor=executor, verbose=True)
agent.run("在纽约,100美元能买几束玫瑰?")
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
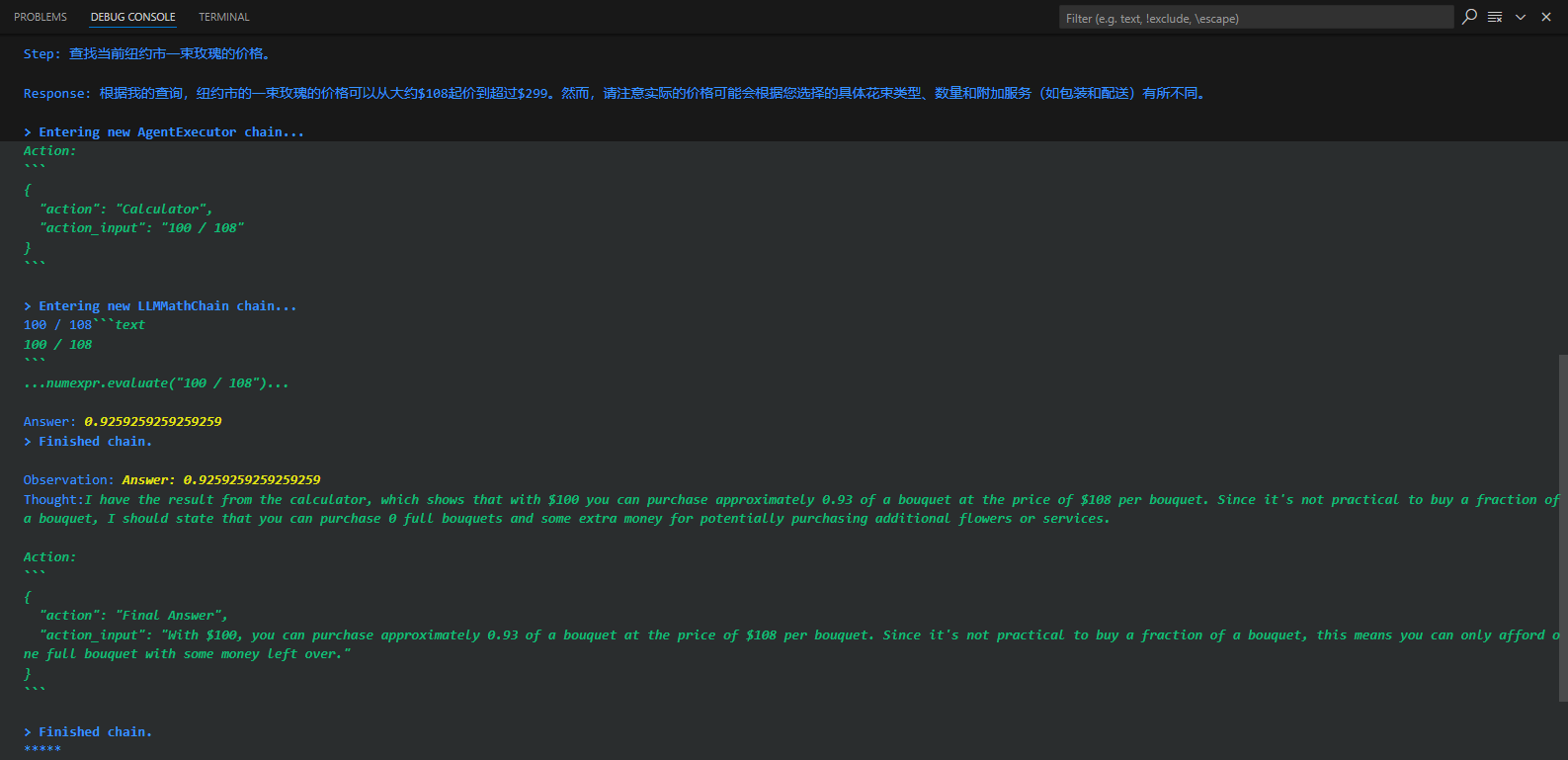
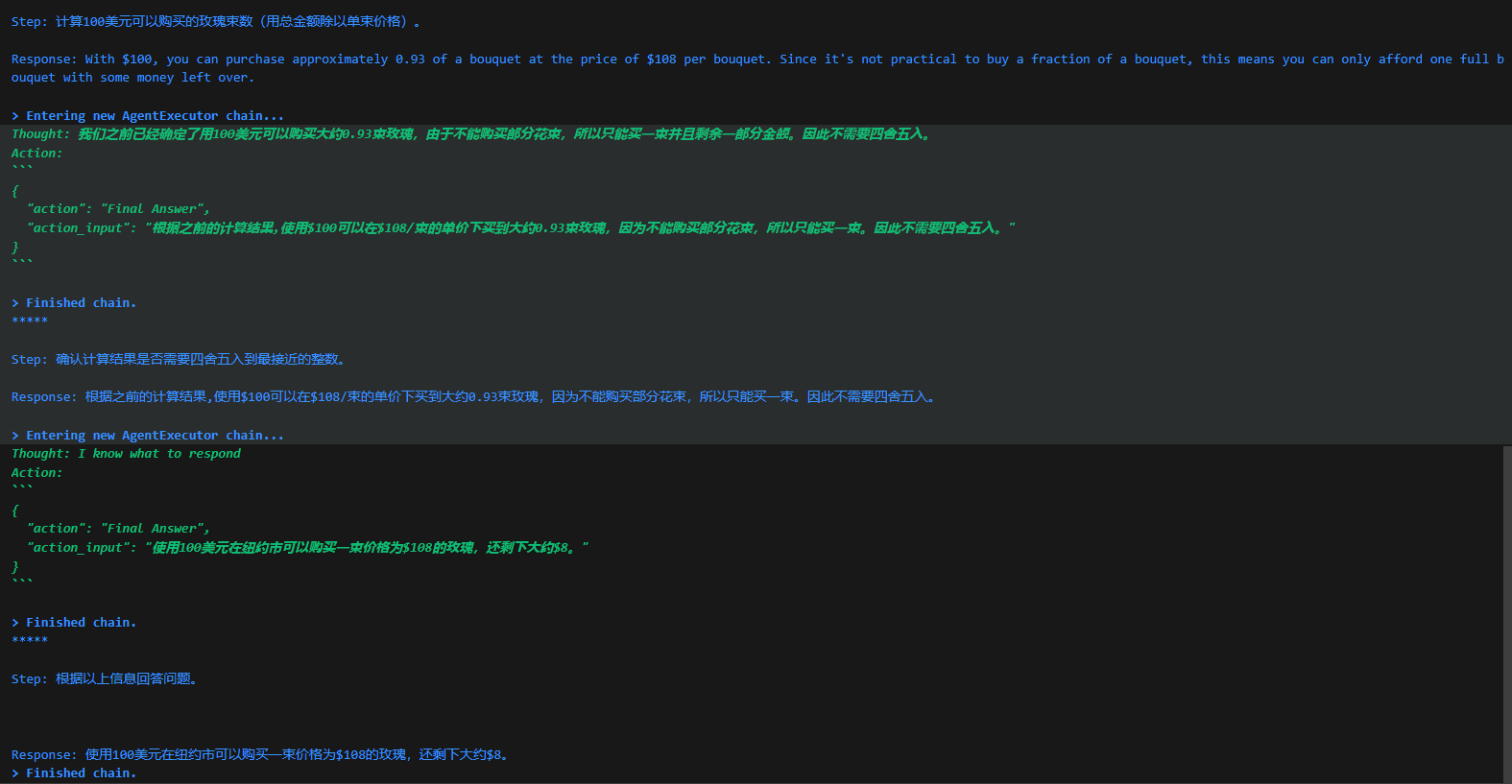
# 总结思考(13)
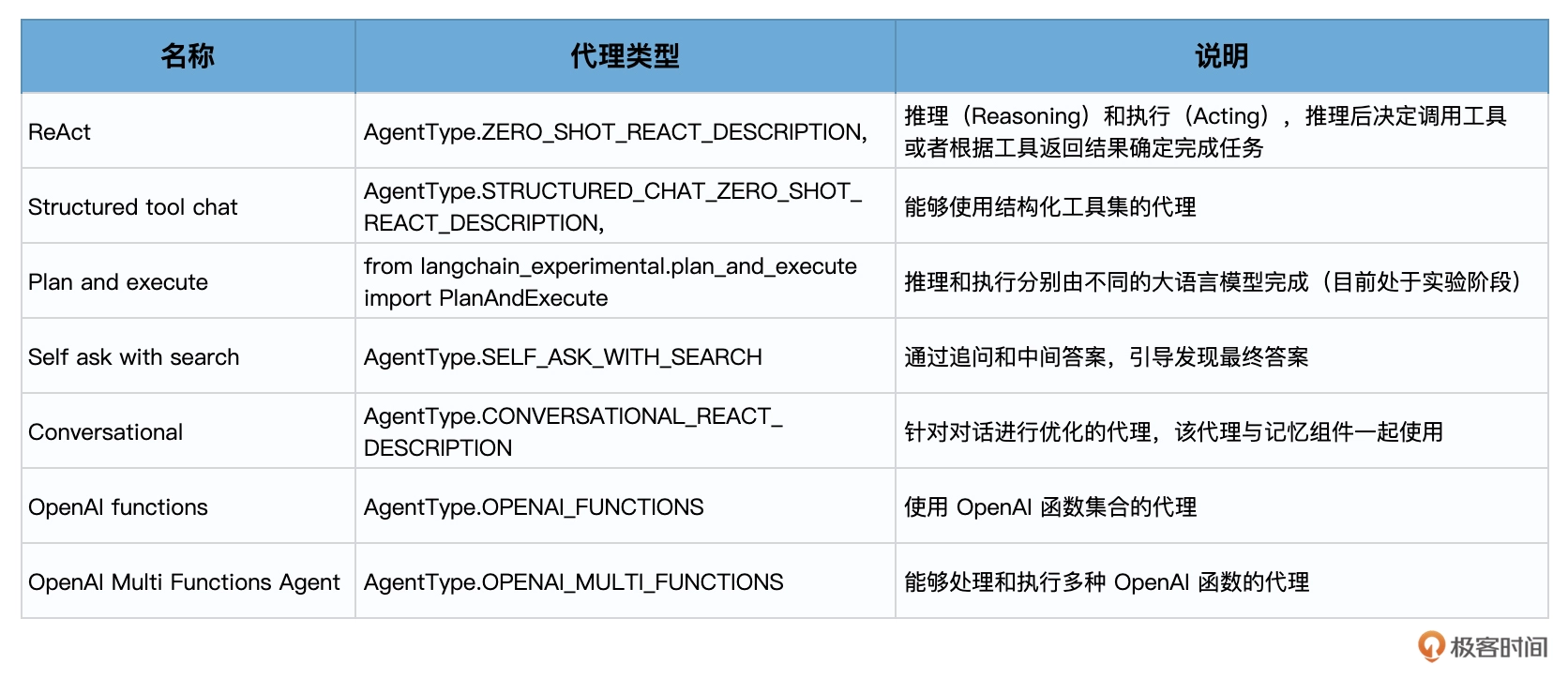
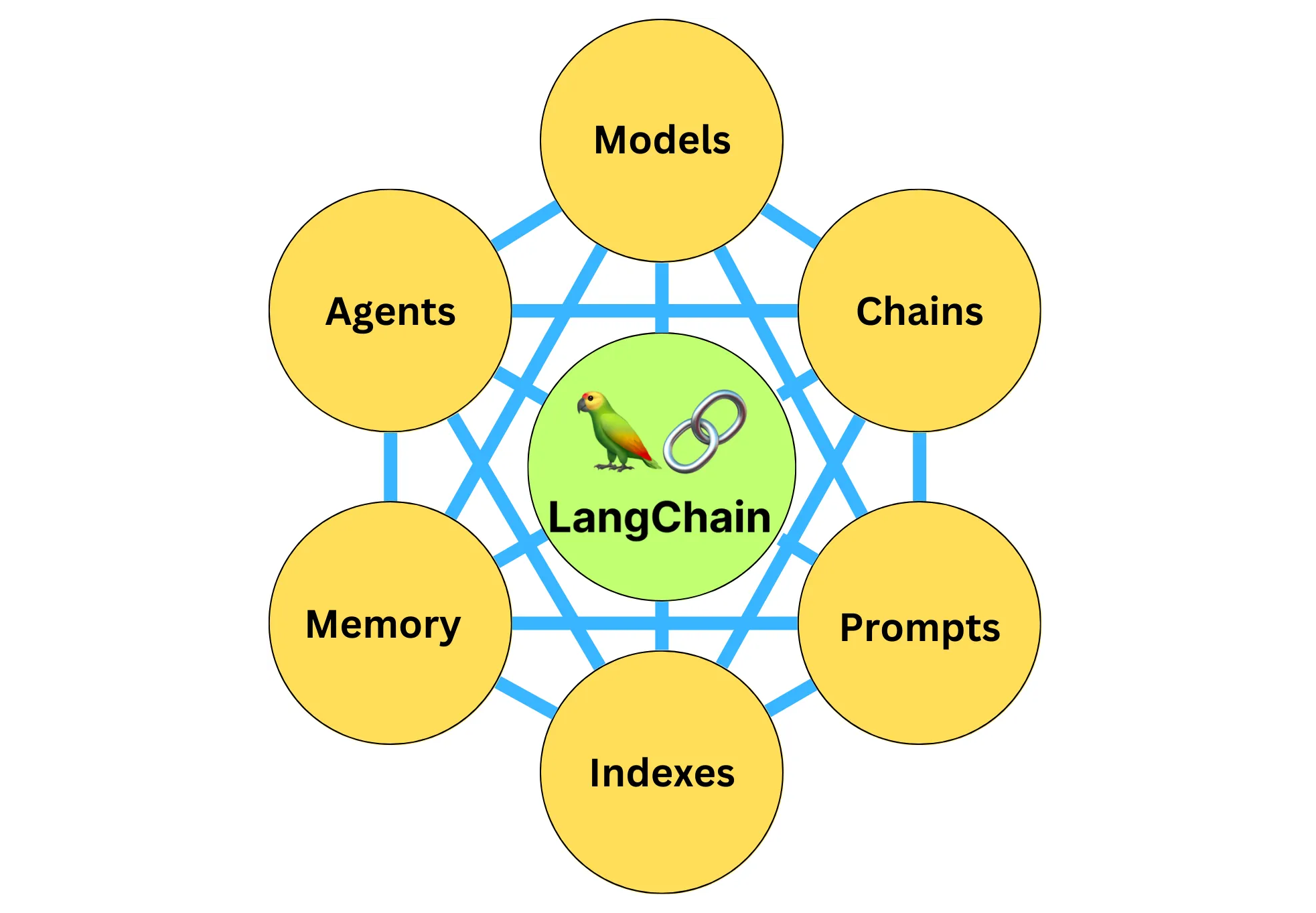
Indexes,这个Indexes是LangChain早期版本的一个组件,现在已经被整合到Retrieval(数据检索)这个单元中了,而Retrieval(包括Indexes),说的其实就是如何把离散的文档及其他信息嵌入,存储到向量数据库中,然后再提取的过程。这个过程之前讲过。
# 思考题(13)
- 在结构化工具对话代理的实例中,请打印出PlayWrightBrowserToolkit中的所有具体工具名称的列表。
tools = toolkit.get_tools()
print(tools)
2
- 在Plan and execute代理的示例中,请分析PlanAndExecute、AgentExecutor和LLMMathChain链的调用流程以及代理的思考过程。
# 延伸阅读(13)
- 代码Playwright工具包
- 论文"计划与解决"提示:通过大型语言模型改进 Zero-Shot 链式思考推理 Wang, L., Xu, W., Lan, Y., Hu, Z., Lan, Y., Lee, R. K.-W., & Lim, E.-P. (2023). Plan-and-Solve Prompting: Improving Zero-Shot Chain-of-Thought Reasoning by Large Language Models. arXiv preprint arXiv:2305.04091.
# 工具和工具箱
工具,是代理身上延展出来的三头六臂,是代理的武器,代理通过工具与世界进行交互,控制并改造世界。
# 工具是代理的武器
LangChain之所以强大,一是大模型的推理能力强大,二是工具的执行能力强大。LangChain通过提供一个同意的框架来集成功能的具体实现。在这个框架中,每个功能都被封装成一个工具。每个工具都有自己的输入和输出,以及处理这些输入和生成输出的方法。
当代理接收到一个任务时,它会根据任务的类型和需求,通过大模型的推理,来选择合适的工具处理这个任务。这个选择过程可以基于各种策略,例如基于工具的性能,或者基于工具处理特定类型任务的能力。一旦选择了合适的工具,LangChain就会将任务的输入传递给这个工具,然后工具会处理这些输入并生成输出。这个输出又经过大模型的推理,可以被用作其他工具的输入,或者作为最终结果,被返回给用户。
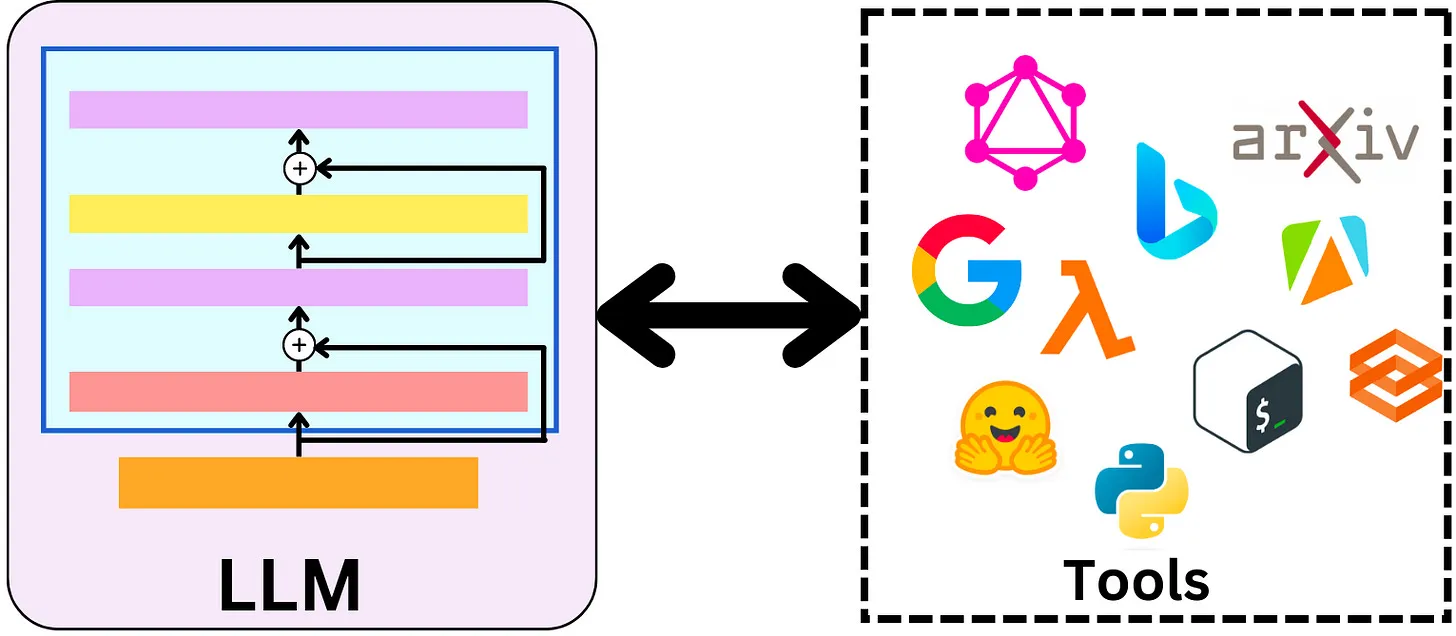
# 如何加载工具
# LangChain 支持的工具一览
# 使用 arXiv 工具开发科研助理
# LangChain 中的工具箱一览
# 使用 Gmail 工具箱开发个人助理
# 第一步: 在 Google Cloud 中设置你的应用程序接口
# 第二步: 根据密钥生成开发 Token
# 第三步: 用 LangChain 框架开发 Gmail App
# 总结时刻(14)
# 思考题(14)
# 延伸阅读(14)
# 检索增强生成
# 连接数据库
# 回调函数
# CAMEL
# BabyAGI
# 部署
# 开发
- AI应用开发的奇点
- 何谓LangChain?
- 如何学习LangChain?
- LangChain 用例
- LangChain系统安装和快速入门
- 什么是大语言模型
- 安装LangChain
- OpenAI API
- 调用Text模型
- 调用Chat模型
- Chat模型 vs Text模型
- 通过LangChain调用Text和Chat模型
- 用LangChain快速构建本地知识库智能问答系统
- 项目及实现框架
- 数据的准备和载入
- 文本的分割
- 向量数据库存储
- 相关信息的获取
- 生成回答并展示
- 总结时刻(2)
- 思考题(2)
- 延伸阅读(2)
- 模型I/O: 输入提示、调用模型、解析输出
- Model I/O
- 提示模板
- 语言模型
- 输出解析
- 总结时刻(3)
- 思考题(3)
- 提示工程
- 提示的结构
- LangChain 提示模板的类型
- 使用PromptTemplate
- 使用ChatPromptTemplate
- FewShot的思想起源
- 使用FewShotPromptTemplate
- 使用示例选择器
- 总结时刻(4)
- 思考题(4)
- 延伸阅读(4)
- 什么是 Chain of Thought
- Chain of Thought 实战
- Tree of Thought
- 总结时刻(5)
- 思考题(5)
- 延伸阅读(5)
- 调用模型
- 大语言模型发展史
- 预训练 + 微调的模式
- 用HuggingFace跑开源模型
- LangChain和HuggingFace的接口
- 用LangChain调用自定义语言模型
- 总结时刻(6)
- 思考题(6)
- 延伸阅读(6)
- 输出解析
- LangChain 中的输出解析器
- Pydantic(JSON) 解析器实战
- 自动修复解析器(OutputFixingParser)实战
- 重试解析器(RetryWithErrorOutputParser)实战
- 总结时刻(7)
- 思考题(7)
- 延伸阅读(7)
- 链
- 什么是Chain
- LLMChain: 最简单的链
- 链的调用方式
- Sequential Chain: 顺序链
- 总结时刻(8)
- 思考题(8)
- 延伸阅读(8)
- 任务设定
- 整体框架
- 具体实现
- 构建提示信息的模板
- 初始化语言模型
- 构建目标链
- 构建路由链
- 构建默认链
- 构建多提示链
- 运行路由链
- 总结时刻(9)
- 思考题(9)
- 延伸阅读(9)
- 记忆
- 使用 ConversationChain
- 使用 ConversationBufferMemory
- 使用 ConversationBufferWindowMemory
- 使用 ConversationSummaryMemory
- 使用 ConversationSummaryBufferMemory
- 总结时刻(10)
- 思考题(10)
- 延伸阅读(10)
- 代理(上)
- 代理的作用
- ReAct 框架
- 通过代理实现 ReAct 框架
- 总结时刻(11)
- 思考题(11)
- 延伸阅读(11)
- 代理(中)
- Agent 的关键组件
- 深挖 AgentExecutor 的运行机制
- 总结时刻(12)
- 思考题(12)
- 延伸阅读(12)
- 代理(下)
- 什么是结构化工具
- 什么是 Playwright
- 使用结构化工具对话代理
- 第一轮思考
- 第二轮思考
- 第三轮思考
- 使用 Self-Ask with Search 代理
- 使用 Plan and execute 代理
- 总结思考(13)
- 思考题(13)
- 延伸阅读(13)
- 工具和工具箱
- 工具是代理的武器
- 如何加载工具
- LangChain 支持的工具一览
- 使用 arXiv 工具开发科研助理
- LangChain 中的工具箱一览
- 使用 Gmail 工具箱开发个人助理
- 第一步: 在 Google Cloud 中设置你的应用程序接口
- 第二步: 根据密钥生成开发 Token
- 第三步: 用 LangChain 框架开发 Gmail App
- 总结时刻(14)
- 思考题(14)
- 延伸阅读(14)
- 检索增强生成
- 连接数据库
- 回调函数
- CAMEL
- BabyAGI
- 部署
- 开发